Je constate avec tristesse que la Balance (CECI EST MOI!) Est à la dernière place ... Bien que, selon les données, il me semble qu'il y ait des anomalies. D'une manière ou d'une autre, la petite Balance est suspecte!
Partie 1. Analyse et obtention des données initiales
Wikipedia Liste des listes de listes
à la sortie, vous avez besoin d'une base avec nom complet + date de naissance + (s'il y a d'autres signes - par exemple, m / f, pays, etc.) il y a une API .
Ce site s'est avéré être un site gratté (récolte / obtention / extraction (extraction) / collecte de données obtenues à partir de ressources Web) à l'aide de la bibliothèque Python Scrapy.
Les instructions détaillées
obtiennent d'abord des liens (feuilles avec des personnes de Wikipédia, puis des données).
Dans d'autres cas, ils ont analysé avec succès comme ça .
Résultat: fichier BD wiki.zip
Partie 2. À propos du prétraitement (par Stanislav Kostenkov - contacts ci-dessous)
De nombreuses personnes sont confrontées à la complexité du traitement des données d'entrée. Ainsi, dans cette tâche, il était nécessaire d'extraire les données de naissance de plus de 42 000 articles et, si possible, de déterminer le pays de naissance. D'une part, il s'agit d'une tâche algorithmique simple, d'autre part, les outils des systèmes Excel & BI ne permettent pas de le faire "de front".
À un tel moment, les langages de programmation (Python, R) viennent à la rescousse, dont le lancement est prévu dans la plupart des systèmes de BI. Il est à noter que, par exemple, dans Power BI, il y a une limite de 30 minutes pour exécuter un script (programme) en Python. Par conséquent, de nombreux traitements «lourds» sont effectués avant le lancement des systèmes BI, par exemple dans un lac de données.
Comment le problème a été résolu
La première chose que j'ai faite après le chargement et la vérification des valeurs invalides a été de transformer chaque article en une liste de mots.
Dans cette tâche, j'ai eu de la chance avec la langue, l'anglais. Ce langage se caractérise par une forme rigide de construction de la phrase, ce qui a grandement facilité la recherche de la date de naissance. Le mot-clé ici est "né", puis il regarde et analyse ce qui est après.
En revanche, tous les articles proviennent d'une seule source, ce qui facilite également la tâche. Tous les articles avaient à peu près la même structure et la même vitesse.
De plus, toutes les années comportaient 4 caractères, toutes les dates comportaient 1 à 2 caractères et les mois étaient textuels. Il n'y avait que 3-4 variations possibles dans l'orthographe de la date de naissance, qui a été résolue par une simple logique. Il pourrait également être analysé via des expressions régulières.
Le vrai code n'est pas optimisé (une telle tâche n'a pas été définie, il y a peut-être des failles dans les noms des variables).
D'après la prédiction du pays, j'ai eu la chance de trouver un tableau de correspondance des pays et nationalités. Habituellement, les articles ne décrivent pas le pays, mais son appartenance. Par exemple, Russie - russe. Par conséquent, nous avons recherché des occurrences de nationalités, mais comme il pouvait y avoir plus de 5 nationalités différentes dans un article, j'ai émis l'hypothèse que le mot souhaité serait le plus proche possible du mot-clé «brûler». Ainsi, le critère était - la distance d'index minimale entre les mots nécessaires dans l'article. Ensuite, une ligne a été renommée de nationalité en pays.
Ce qui n'a pas été fait
Dans les articles, de nombreux mots avaient des déchets, c'est-à-dire qu'un fragment du code était lié au mot, ou deux mots ont été fusionnés. Par conséquent, la probabilité de trouver les valeurs souhaitées dans de tels mots n'a pas été vérifiée. Vous pouvez nettoyer ces mots à l'aide d'algorithmes de similarité.
Les entités auxquelles appartient le mot-clé "burn" n'ont pas été analysées. Il y avait plusieurs exemples où le mot-clé était lié à la naissance de parents. Ces exemples étaient négligeables. Ces exemples peuvent être attribués au fait que le mot-clé est loin du début de l'article. Vous pouvez calculer les centiles pour trouver un mot-clé et définir un critère de détourage.
Quelques mots sur l'utilité du prétraitement lors du nettoyage des données
Il y a des cas courants où nous pouvons deviner exactement ce qui devrait être à la place des lacunes. Mais il y a des cas, par exemple, il y a des omissions basées sur le sexe d'un acheteur en magasin et il y a des données sur ses achats. Il n'existe pas de techniques standard pour résoudre ce problème dans les systèmes de BI, mais en même temps, au niveau du prétraitement, vous pouvez créer un modèle «léger» et voir diverses options pour combler les lacunes. Il existe des options de remplissage basées sur des algorithmes d'apprentissage automatique simples. Et cela vaut la peine d'être utilisé. Ce n'est pas difficile.
Le code source (Python) est disponible sur le lien
Résultat: fichier out_data_fin.xls
Stanislav Kostenkov / CBS Consulting (Izhevsk, Russie) staskostenkov@gmail.com
Partie 3. Application Qlik Sense
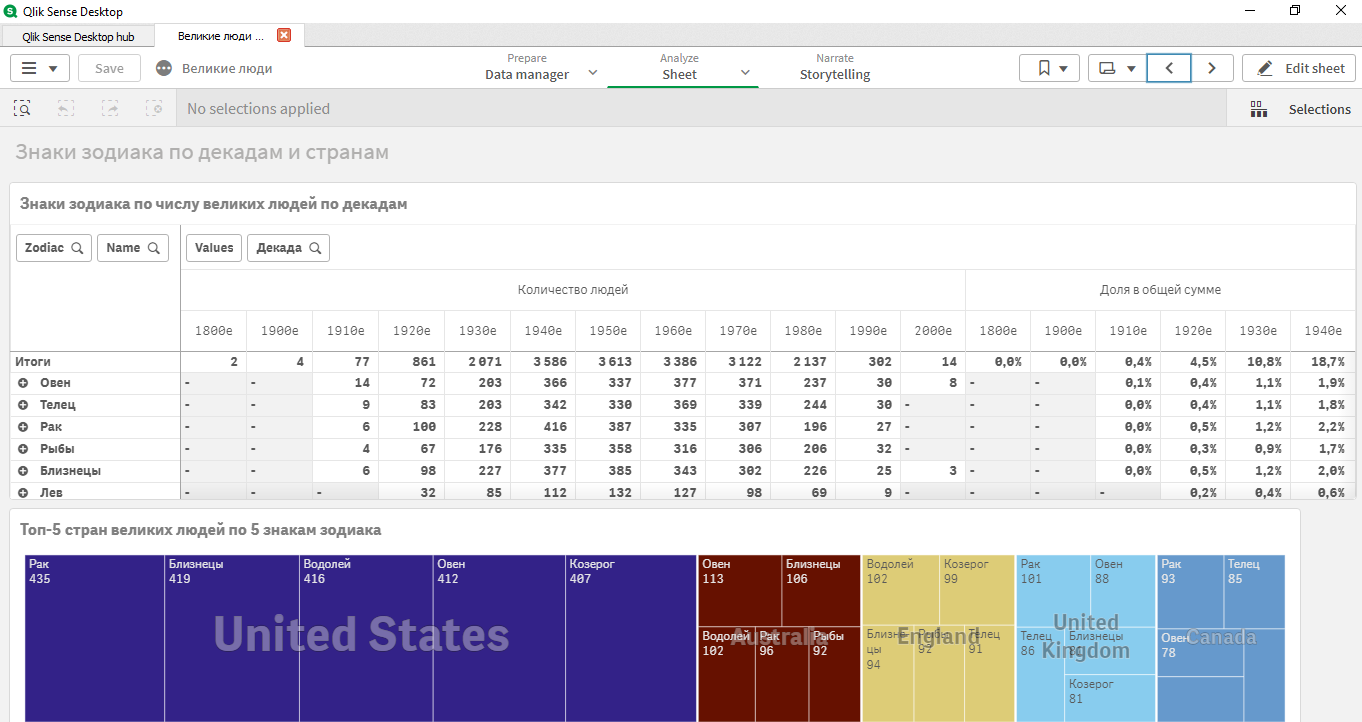
Ensuite, une application classique a été créée, où des anomalies avec le jeu de données ont été révélées:
- il était logique de ne choisir que des décennies de 1920 à 1980;
- dans différents pays, il y avait différents leaders en termes de signes d'horoscope;
- signes supérieurs: Cancer, Bélier, Gémeaux, Taureau, Capricorne.
Toutes les données (ensemble de données, données brutes, reçues par l'application Qlik Sense pour l'analyse des données) sont localisées par référence .