Comment savons-nous que l'algorithme fonctionne?
Avant de développer un algorithme, vous devez réfléchir à la manière dont nous évaluerons ses performances. Disons que nous avons écrit un algorithme, et il dit que "cette image a les couleurs suivantes" - sa décision sera-t-elle correcte? Et qu'est-ce que cela signifie même - «correct»?
Pour résoudre ce problème, nous avons choisi deux dimensions importantes - le marquage correct de la couleur primaire et le nombre correct de couleurs. Nous définissons cela comme la distance CIEDE 2000 ( formule de différence de couleur ) entre la couleur de premier plan prédite par notre algorithme et notre couleur réelle de premier plan, et nous calculons également l'erreur absolue moyenne dans le nombre de couleurs. Nous avons fait ce choix pour les raisons suivantes:
- Ces paramètres sont faciles à calculer.
- À mesure que le nombre de métriques augmentait, il serait plus difficile de choisir le «meilleur» algorithme.
- En réduisant le nombre de métriques, nous pouvons manquer une différence importante entre les deux algorithmes.
- Dans tous les cas, la plupart des vêtements ont une ou deux couleurs primaires, et bon nombre de nos processus reposent sur une couleur primaire. Par conséquent, calculer correctement la couleur de base est beaucoup plus important que calculer correctement la deuxième ou la troisième couleur.
Qu'en est-il des données «réelles»? Notre équipe de marchandiseurs nous a fourni des étiquettes, mais nos outils leur permettent de choisir uniquement les couleurs les plus courantes, telles que «gris» ou «bleu» - elles ne peuvent pas être qualifiées de valeur exacte. Ces définitions générales incluent plusieurs nuances différentes, elles ne peuvent donc pas être utilisées comme de vraies couleurs. Nous devrons créer notre propre ensemble de données.
Certains d'entre vous pensent peut-être déjà à des services comme Mechanical Turk. Mais nous n'avons pas besoin de marquer trop d'images, donc décrire cette tâche peut être encore plus difficile que de simplement la terminer. De plus, la création d'un jeu de données vous aide à mieux le comprendre. Nous avons rapidement raté une application HTML / Javascript et sélectionné au hasard 1000 images, sélectionnées pour chaque pixel qui représente sa couleur primaire, et marqué le nombre de couleurs que nous avons vues dans l'image. Après cela, il est devenu facile d'obtenir deux nombres évaluant la qualité de notre algorithme (distance à la couleur principale CIEDE et nombre de couleurs MAE).
Parfois, nous vérifions les programmes manuellement, exécutant les deux algorithmes sur la même image et affichant deux listes de couleurs. Nous avons ensuite évalué manuellement 200 images, en choisissant les couleurs reconnues comme «meilleures». Il est très important de travailler étroitement avec les données de cette manière - non seulement pour obtenir le résultat («l'algorithme B a mieux fonctionné que l'algorithme A dans 70% des cas»), mais aussi pour comprendre ce qui se passe dans chacun des cas («l'algorithme B choisit généralement trop de groupes, mais L'algorithme A manque les couleurs claires »).

Pull et couleurs sélectionnés par deux algorithmes différents
Notre algorithme d'extraction de couleur
Avant de traiter les images, nous les convertissons dans l'espace colorimétrique CIELAB (ou simplement LAB) au lieu du RVB plus courant. En conséquence, nos trois nombres ne représenteront pas la quantité de rouge, de vert et de bleu. Les points de l'espace LAB (L * a * b * serait plus correct, mais nous écrirons LAB pour simplifier) désignent trois axes différents. L désigne la luminosité du noir 0 au blanc 100. A et B dénotent la couleur: A désigne un emplacement compris entre -128 vert et 127 rouge, et B entre -128 bleu et 127 jaune. Le principal avantage de cet espace est l'uniformité perçue. La distance ou la différence entre deux points dans l'espace LAB sera perçue de la même manière, quel que soit leur emplacement, si la distance euclidienne entre eux dans l'espace est également la même.
Naturellement, le LAB a d'autres problèmes: par exemple, nous considérons les images sur les écrans d'ordinateur qui utilisent l'espace RVB spécifique à l'appareil. En outre, la gamme LAB est plus large que celle de RVB, c'est-à-dire que dans LAB, vous pouvez exprimer des couleurs qui ne peuvent pas être exprimées via RVB. Par conséquent, la conversion de LAB en RVB ne peut pas être bilatérale - en convertissant un point dans une direction, puis dans la direction opposée, vous pouvez obtenir une valeur différente. Théoriquement, ces lacunes sont présentes, mais dans la pratique, la méthode fonctionne toujours.
En convertissant l'image en LAB, nous obtenons un ensemble de pixels pouvant être visualisés sous forme de points (L, A, B, X, Y). Le reste de l'algorithme concerne le regroupement de ces points, dans lequel les groupes de première étape utilisent les cinq mesures, et la deuxième étape omet les mesures X et Y.
Regroupement dans l'espace
Nous commençons avec une image sans regroupement de pixels qui a subi les ajustements de couleur décrits dans l' article précédent , compressée en 320x200 et convertie en LAB.

Tout d'abord, appliquons l'algorithme Quickshift, qui regroupe les pixels proches en «superpixels».

Cela réduit déjà notre image de 60 000 pixels à quelques centaines de superpixels, supprimant ainsi toute complexité inutile. Vous pouvez simplifier encore plus la situation en fusionnant des superpixels proches avec une petite distance de couleur entre eux. Pour ce faire, nous dessinons leur graphe de proximité régionale - un graphe dans lequel les nœuds désignant deux superpixels différents sont reliés par un bord si leurs pixels se touchent.

– (Regional Adjacency Graph, RAG) . , , , , . , , , , . – , .
Les nœuds du graphique sont les superpixels que nous avons calculés, et les arêtes sont la distance qui les sépare dans l'espace colorimétrique. Le bord reliant deux superpixels proches avec des couleurs similaires aura un faible poids (lignes sombres), et le bord entre les superpixels avec des couleurs très différentes aura un poids élevé (lignes lumineuses, ainsi que l'absence de lignes - ils n'ont pas été dessinés si leur poids était supérieur à 20). Il existe de nombreuses façons de combiner les superpixels à proximité, mais un simple seuil de 10 nous suffisait.
Dans notre cas, nous avons réussi à réduire 60 000 pixels à 100 zones, chacune contenant des pixels de la même couleur. Cela donne des avantages de calcul: Premièrement, nous savons qu'un grand superpixel de couleur presque blanche est l'arrière-plan et peut être supprimé. Nous supprimons tous les superpixels avec L> 99, et A et B compris entre -0,5 et 0,5. Deuxièmement, nous pouvons réduire considérablement le nombre de pixels à l'étape suivante. Nous ne pourrons pas réduire leur nombre à 100, car nous devons peser les zones en fonction du nombre de pixels qu'elles contiennent. Mais nous pouvons facilement supprimer 90% des pixels de chaque groupe sans perdre trop de détails et presque aucune distorsion du groupement suivant.
Regrouper sans utiliser d'espace
A cette étape, nous avons plusieurs milliers de pixels de coordonnées (L, A, B). Il existe de nombreuses techniques qui permettent de bien regrouper ces pixels. Nous avons choisi la méthode des k-moyennes car elle est rapide, facile à comprendre, nos données n'ont que 3 dimensions et la distance euclidienne dans l'espace LAB a du sens.
Nous n'étions pas trop intelligents et avions un regroupement avec K = 8. Si un groupe contient moins de 3% de points, on essaie à nouveau, cette fois avec K = 7, puis 6, et ainsi de suite. En conséquence, nous avons une liste de 1 à 8 centres de regroupement et une fraction du nombre de points appartenant à chacun des centres. Ils sont nommés par l'algorithme colornamer décrit dans l'article précédent.
Résultats et problèmes restants
Nous avons atteint une distance moyenne de 5,86 sur l'échelle CIEDE 2000 entre la couleur prédite et la couleur «réelle». Il est assez difficile d'interpréter correctement cet indicateur. Sur la métrique de distance simple CIE76, notre distance moyenne est de 7,82. Sur cette métrique, une valeur de 2,3 représente une différence subtile. Par conséquent, nous pouvons dire que nos résultats, légèrement supérieurs à 3, indiquent une différence subtile.
Notre MAE était également de 2,28 couleurs. Mais encore une fois, c'est une métrique secondaire. De nombreux algorithmes décrits ci-dessous réduisent cette erreur, mais au détriment de l'augmentation de la distance de couleur. Il est beaucoup plus facile d'ignorer les fausses couleurs à la 5e ou 6e place que d'ignorer la mauvaise 1ère couleur.

Même les choses qui sont clairement de la même couleur, comme ces courts métrages, contiennent des zones qui semblent beaucoup plus sombres à cause
des ombres.Le problème des ombres demeure. Le tissu ne peut pas être posé parfaitement uniformément, par conséquent, une partie de l'image restera toujours dans l'ombre, et elle semblera trompeusement d'une couleur différente. Les approches les plus simples comme la recherche de doublons de couleurs de la même teinte et de la luminosité différente ne fonctionnent pas, car la transition de «pixel sans ombre» à «pixel dans l'ombre» ne fonctionne pas toujours de la même manière. À l'avenir, nous espérons utiliser des techniques plus sophistiquées comme DeshadowNet ou la détection automatique des ombres .

Nous nous sommes concentrés uniquement sur la couleur des vêtements. Les bijoux et les chaussures ont leurs propres problèmes: nos photographies de bijoux sont trop petites et les photographies de chaussures en montrent souvent l'intérieur. Dans l'exemple ci-dessus, nous indiquerions la présence de bordeaux et d'ocre sur la photo, bien que seul le premier d'entre eux soit important.
Qu'avons-nous essayé d'autre
Ce dernier algorithme semble assez simple, mais ce n'était pas facile à trouver! Dans cette section, je décrirai les options que nous avons essayées et tirées des leçons.
Suppression d'arrière-plan
Nous avons essayé des algorithmes de suppression d'arrière-plan - par exemple, l' algorithme de Lyst . Une évaluation informelle a montré qu'ils ne fonctionnaient pas aussi précisément que la simple suppression du fond blanc. Cependant, nous prévoyons de l'étudier plus en profondeur au fur et à mesure que nous traitons des images sur lesquelles notre studio photo n'a pas travaillé.
Pixels de hachage
Certaines bibliothèques d'extraction de couleurs ont choisi une solution simple à ce problème: regrouper les pixels en les hachant dans plusieurs conteneurs suffisamment larges, puis renvoyer les valeurs moyennes des conteneurs LAB avec le plus grand nombre de pixels. Nous avons essayé la bibliothèque Colorgram.py; malgré sa simplicité, il fonctionne étonnamment bien. De plus, cela fonctionne rapidement - pas plus d'une seconde par image, tandis que notre algorithme passe des dizaines de secondes par image. Cependant, Colorgram.py avait une distance moyenne plus grande à la couleur de base que notre algorithme - principalement parce que son résultat est tiré des distances moyennes aux grands conteneurs. Cependant, nous l'utilisons parfois pour les cas où la vitesse est plus importante que la précision.
Un autre algorithme de fractionnement de superpixels
Nous utilisons l'algorithme Quickshift pour segmenter l'image en superpixels, mais il existe plusieurs algorithmes possibles - par exemple, SLIC, Watershed et Felzenszwalb. En pratique, Quickshift a montré les meilleurs résultats grâce à son travail avec de petites pièces. Par exemple, SLIC a un problème avec des éléments tels que les rayures qui prennent beaucoup de place dans l'image. Voici les résultats indicatifs de l'algorithme SLIC avec différents paramètres: Compacité de l'

image d'origine

= 1

compacité = 10

compacité = 100
Pour travailler avec nos données, Quickshift a un avantage théorique: il ne nécessite pas de communication superpixel continue. Les chercheurs ont noté que cela peut causer des problèmes pour les algorithmes, mais dans notre cas, c'est un avantage - nous rencontrons souvent de petites zones avec de petits détails que nous voulons apporter à un groupe.

Chemise à

carreaux Son regroupement de superpixels par Quickshift
Alors que le regroupement de superpixels de Quickshift semble chaotique, il regroupe en fait toutes les bandes rouges avec d'autres rouges, bleu avec du bleu, etc.
Différentes méthodes de comptage du nombre de groupes
Lors de l'utilisation de la méthode k-means, la question la plus courante se pose: comment faire "k"? Autrement dit, si nous devons regrouper les points en un certain nombre de groupes, combien devons-nous en faire? Plusieurs approches ont été développées pour répondre à la question. La plus simple est la «méthode du coude», mais elle nécessite un traitement manuel du graphe, et nous avons besoin d'une solution automatique. Gap Statistic formalise cette méthode, et avec elle nous avons obtenu les meilleurs résultats sur la métrique «nombre de couleurs», mais au détriment de la précision de la couleur de base. Étant donné que la couleur principale est la plus importante, nous ne l'avons pas utilisée dans le programme de travail, mais nous prévoyons d'étudier cette question plus avant.
Enfin, la méthode de la silhouette est une autre méthode de sélection k populaire. Il donne des résultats légèrement pires que notre algorithme, et il a un inconvénient sérieux: il a besoin d'au moins 2 groupes. Mais de nombreux vêtements n'ont qu'une seule couleur.
DBSCAN
Une solution potentielle à la question du choix de k consiste à utiliser un algorithme qui ne vous oblige pas à choisir ce paramètre. Un exemple populaire est DBSCAN, qui recherche des groupes de densité à peu près égale dans les données.

Blouse multicolore
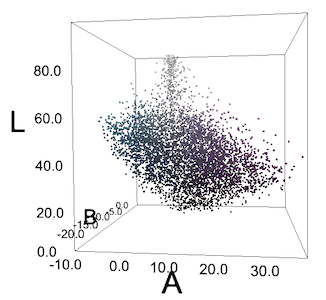
Tous les pixels de son image sont dans l'espace LAB. Les pixels ne forment pas de groupes cyan et violets clairs.
Souvent, nous n'obtenons pas de tels groupes, ou nous voyons quelque chose comme des groupes uniquement à cause des particularités de la perception humaine. Pour nous, les "concombres" bleu verdâtre sur le chemisier se détachent sur le fond violet, mais si nous traçons tous les pixels en coordonnées RVB ou LAB, ils ne formeront pas de groupes. Mais nous avons quand même essayé DBSCAN avec différentes valeurs epsilon et nous avons obtenu des résultats prévisibles médiocres.
Solution d'Algolia
L'un des bons principes des chercheurs est de voir si quelqu'un a déjà résolu votre problème. Leo Ercolanelli du site Internet Algolia a publié une description détaillée de la solution à un tel problème il y a plus de trois ans. Grâce à leur générosité dans la distribution des sources, nous avons pu tester nous-mêmes leur solution. Cependant, les résultats étaient légèrement pires que les nôtres, nous avons donc laissé notre algorithme. Ils ne résolvent pas le même problème que nous: ils avaient des images de produits sur des modèles et sur un fond autre que le blanc, il est donc logique que leurs résultats diffèrent des nôtres.
Coordination des couleurs
Cet algorithme complète le processus décrit dans notre article précédent. Après avoir extrait les centres du groupe, nous utilisons Colornamer pour les nommer, puis importons ces couleurs dans nos outils internes. Cela nous aide à visualiser facilement nos produits par couleur; nous espérons intégrer ces données dans les algorithmes de recommandation d'achat. Ce processus n'est pas parfait, il nous permet d'obtenir les meilleures données sur nos milliers de produits, ce qui contribue à notre objectif principal d'aider les gens à trouver les styles qu'ils aiment.
Interview sur la traduction de la première partie