
Licorne mythique de rhinocéros. MS TECH / PIXABAY L'
apprentissage en moins d'un essai aide un modèle à identifier plus d'objets que le nombre d'exemples sur lesquels il s'est entraîné.
En règle générale, l'apprentissage automatique nécessite de nombreux exemples. Pour qu'un modèle IA reconnaisse un cheval, vous devez lui montrer des milliers d'images de chevaux. C'est pourquoi la technologie est si coûteuse en calcul et très différente de l'apprentissage humain. Un enfant a souvent besoin de voir seulement quelques exemples d'un objet, voire un, pour apprendre à le reconnaître pour la vie.
En fait, les enfants n'ont parfois besoin d' aucun exemple pour identifier quelque chose. Montrez des images d'un cheval et d'un rhinocéros, dites-leur que la licorne est entre les deux et ils reconnaîtront la créature mythique dans le livre d'images dès qu'ils la verront pour la première fois.

Mmm ... Pas vraiment! MS TECH / PIXABAY
À présent, les recherches de l'Université de Waterloo en Ontario suggèrent que les modèles d'IA peuvent également le faire - un processus que les chercheurs appellent l'apprentissage «en moins d'un» essai. En d'autres termes, le modèle d'IA peut clairement reconnaître plus d'objets que le nombre d'exemples sur lesquels il s'est entraîné. Cela peut être critique dans un domaine qui devient de plus en plus cher et inaccessible à mesure que les ensembles de données utilisés se développent.
« »
Les chercheurs ont d'abord démontré cette idée en expérimentant avec un ensemble de données de formation en vision par ordinateur connu sous le nom de MNIST. MNIST contient 60 000 images de nombres manuscrits de 0 à 9, et l'ensemble est souvent utilisé pour tester de nouvelles idées dans ce domaine.
Dans un article précédent, des chercheurs du Massachusetts Institute of Technology ont présenté une méthode de «distillation» d'ensembles de données géants en petits ensembles. Comme preuve de concept, ils ont compressé MNIST en 10 images. Les images n'ont pas été échantillonnées à partir de l'ensemble de données d'origine. Ils ont été soigneusement conçus et optimisés pour contenir l'équivalent d'un ensemble complet d'informations. En conséquence, lorsqu'il est formé sur ces 10 images, le modèle AI atteint presque la même précision que celui entraîné sur l'ensemble du jeu MNIST.

Exemples d'images de l'ensemble MNIST. WIKIMEDIA

10 illustré, «distillé» de MNIST, peut entraîner un modèle d'IA pour atteindre une précision de reconnaissance de chiffres manuscrits de 94%. Tongzhou Wang et
al.Des chercheurs de l'Université de Wotrelu voulaient poursuivre le processus de distillation. S'il est possible de réduire 60 000 images à 10, pourquoi ne pas les compresser à cinq? L'astuce, ils se sont rendu compte, était de mélanger plusieurs nombres dans une image et de les alimenter ensuite dans un modèle d'IA avec des étiquettes dites hybrides ou «souples». (Imaginez un cheval et un rhinocéros qui ont reçu les caractéristiques d'une licorne.)
«Pensez au chiffre 3, il ressemble au chiffre 8, mais pas au chiffre 7», déclare Ilya Sukholutsky, étudiante diplômée de Waterloo et auteur principal de l'article. - Les marques douces essaient de capturer ces similitudes. Donc au lieu de dire à la voiture: "Cette image est le numéro 3", nous disons: "Cette image est à 60% numéro 3, 30% numéro 8 et 10% numéro 0" ".
Limites de la nouvelle méthode d'enseignement
Après avoir utilisé avec succès des étiquettes souples pour réaliser des adaptations du MNIST à l'apprentissage en moins d'une tentative, ils ont commencé à se demander jusqu'où l'idée pouvait aller. Y a-t-il une limite au nombre de catégories qu'un modèle d'IA peut apprendre à identifier à partir d'un petit nombre d'exemples?
Étonnamment, il ne semble y avoir aucune limitation. Avec des étiquettes souples soigneusement conçues, même deux exemples pourraient théoriquement coder n'importe quel nombre de catégories. «Avec seulement deux points, vous pouvez diviser un millier de classes, ou 10 000 classes, ou un million de classes», explique Sukholutsky.
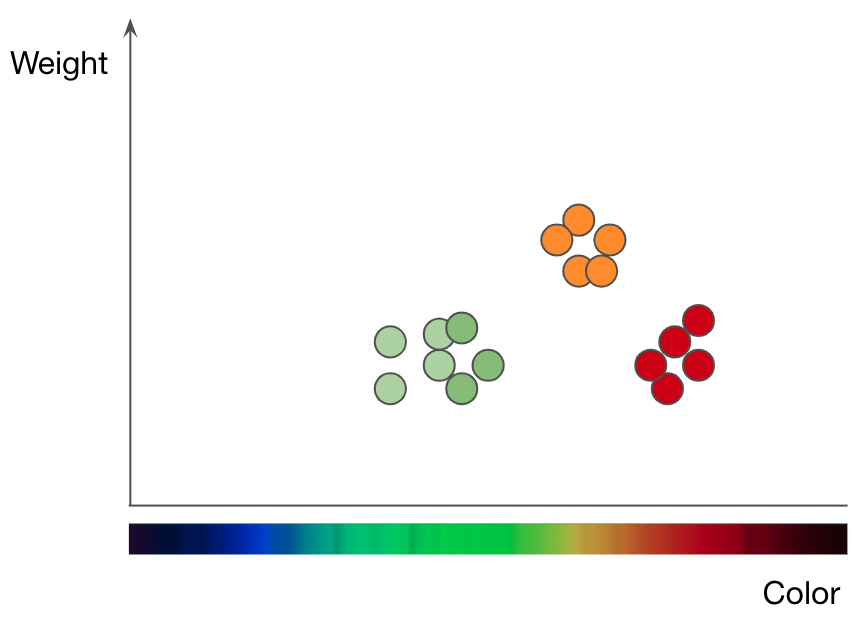
Répartition des pommes (points verts et rouges) et des oranges (points orange) par poids et couleur. Adapté de la présentation de Jason Mace Machine Learning 101
C'est ce que les scientifiques ont montré dans leur dernier article à travers une recherche purement mathématique. Ils ont mis en œuvre ce concept à l'aide de l'un des algorithmes d'apprentissage automatique les plus simples connus sous le nom de k-plus proches voisins (kNN), qui classe les objets à l'aide d'une approche graphique.
Pour comprendre le fonctionnement de la méthode kNN, prenons un problème de classification des fruits comme exemple. Pour entraîner le modèle kNN à comprendre la différence entre les pommes et les oranges, vous devez d'abord sélectionner les fonctions que vous souhaitez utiliser pour représenter chaque fruit. Si vous choisissez la couleur et le poids, alors pour chaque pomme et orange, vous entrez un point de données avec la couleur du fruit comme valeur x et le poids comme valeur y... L'algorithme kNN trace ensuite tous les points de données dans un graphique 2D et trace une ligne à mi-chemin entre les pommes et les oranges. Maintenant, le graphique est soigneusement divisé en deux classes et l'algorithme peut décider si les nouveaux points de données représentent des pommes ou des oranges - selon le côté de la ligne sur lequel se trouve le point.
Pour étudier l'apprentissage en moins d'une tentative avec l'algorithme kNN, les chercheurs ont créé une série de minuscules ensembles de données synthétiques et ont soigneusement réfléchi à leurs étiquettes souples. Ils ont ensuite laissé l'algorithme kNN tracer les limites qu'il a vues et ont constaté qu'il avait réussi à diviser le graphique en plus de classes qu'il n'y avait de points de données. Les chercheurs ont également largement contrôlé la localisation des frontières. En utilisant diverses modifications des étiquettes souples, ils ont fait dessiner à l'algorithme kNN des motifs précis sous la forme de fleurs.
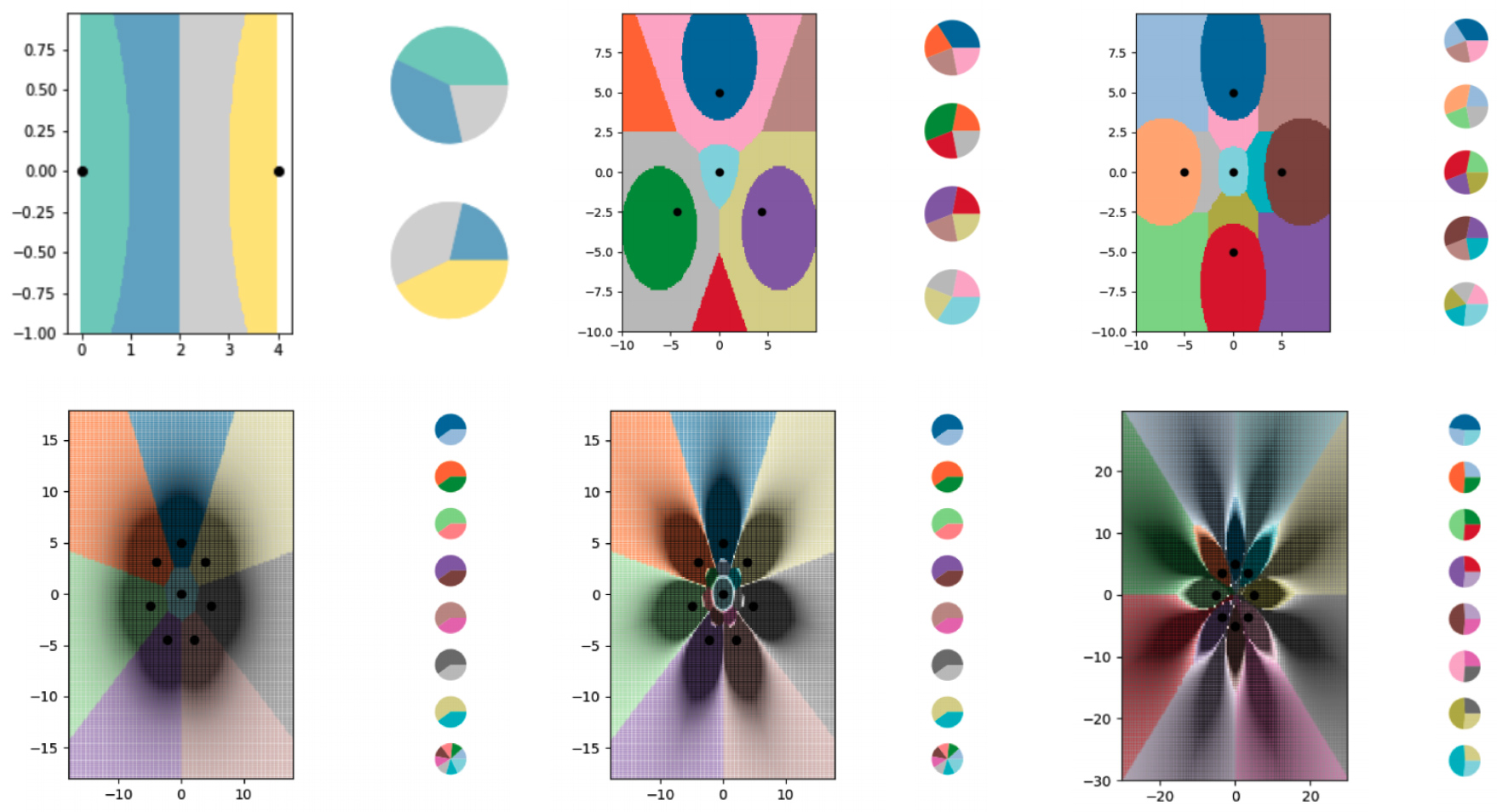
Les chercheurs ont utilisé des exemples d'étiquettes souples pour entraîner l'algorithme kNN à coder des limites de plus en plus complexes et à diviser le diagramme en plus de classes qu'il ne contient de points de données. Chacune des zones colorées représente une classe distincte et les diagrammes à secteurs à côté de chaque graphique montrent la distribution des étiquettes souples pour chaque point de données.
Ilya Sukholutsky et al.
Divers diagrammes montrent les frontières construites à l'aide de l'algorithme kNN. Chaque graphique comporte de plus en plus de lignes de délimitation codées dans de petits ensembles de données.
Bien entendu, cette recherche théorique présente certaines limites. Alors que l'idée d'apprendre à partir de «moins d'une» tentative serait souhaitable pour être transférée à des algorithmes plus complexes, la tâche de développer des exemples avec une étiquette «souple» devient beaucoup plus compliquée. L'algorithme kNN est interprétable et visuel, permettant aux gens de créer des étiquettes. Les réseaux de neurones sont complexes et impénétrables, ce qui signifie que la même chose peut ne pas être vraie pour eux. La distillation des données, qui est bonne pour développer des exemples d'étiquettes souples pour les réseaux de neurones, présente également un inconvénient majeur: la méthode vous oblige à commencer avec un ensemble de données gigantesque, en le réduisant à quelque chose de plus efficace.
Sukholutsky dit qu'il essaie de trouver d'autres moyens de créer ces petits ensembles de données synthétiques - soit à la main, soit avec un autre algorithme. Malgré ces complexités de recherche supplémentaires, l'article présente les fondements théoriques de l'apprentissage. «Quels que soient les ensembles de données dont vous disposez, vous pouvez réaliser des gains d'efficacité significatifs», a-t-il déclaré.
C'est ce qui intéresse surtout Tongzhou Wang, étudiant diplômé du Massachusetts Institute of Technology. Il a dirigé les recherches antérieures sur les données de distillation. «Cet article s'appuie sur un objectif vraiment nouveau et important: former des modèles puissants à partir de petits ensembles de données», dit-il à propos de la contribution de Sukholutsky.
Ryan Hurana, chercheur à l'Institut d'éthique de l'intelligence artificielle de Montréal, partage ce point de vue: «Plus important encore, apprendre en moins d'un essai réduira considérablement les besoins en données pour construire un modèle fonctionnel. Cela pourrait rendre l'IA plus accessible aux entreprises et aux industries qui ont jusqu'à présent été gênées par les besoins en données dans ce domaine. Cela peut également améliorer la confidentialité des données, car les modèles d'utilité de formation exigeront moins d'informations de la part des personnes.
Sukholutsky souligne que la recherche en est à un stade précoce. Néanmoins, cela excite déjà l'imagination. Chaque fois qu'un auteur commence à présenter son article à des collègues chercheurs, leur première réaction est de faire valoir que l'idée dépasse le domaine du possible. Lorsqu'ils réalisent soudain qu'ils ont tort, un tout nouveau monde s'ouvre.

