
Quelques mots sur les systèmes de recommandation
Certes, tout le monde les a rencontrés plus d'une fois. Les systèmes de recommandation sont des programmes et des services qui tentent de prédire ce qui pourrait être intéressant / nécessaire / utile pour un utilisateur particulier, et le leur montrer. «Aimez-vous ces chaussures de course? Vous aurez peut-être également besoin d'un coupe-vent, d'un moniteur de fréquence cardiaque et de 15 autres articles de sport . " Ces dernières années, les marques ont été très actives dans l'introduction de systèmes de recommandation dans leur travail, puisque tant le vendeur que l'acheteur «profitent» de cette décision. Les consommateurs reçoivent un outil qui les aide à faire un choix dans une variété infinie de produits et de services en peu de temps, et l'entreprise augmente ses ventes et son audience.
Qu'est-ce qui nous a été donné?
J'ai travaillé sur un projet pour une grande entreprise mondiale qui propose à ses clients une solution d'échange de fret SaaS ou une plateforme d'échange de fret.
Cela semble incompréhensible, mais comment cela se passe réellement: d'une part, les utilisateurs sont enregistrés sur la plateforme qui ont des charges et qui ont besoin de les envoyer quelque part. Ils placent une application comme "Il y a un lot de produits cosmétiques décoratifs, il doit être transporté demain d'Amsterdam à Anvers"et attendent une réponse. D'un autre côté, nous avons des personnes ou des entreprises avec des camions - des transporteurs de fret. Disons qu'ils ont déjà effectué leur vol hebdomadaire standard, livrant des yaourts de Paris à Bruxelles. Ils doivent rentrer et, pour ne pas partir avec un camion vide, trouver une sorte de cargaison à transporter sur le chemin du retour. Pour ce faire, les transporteurs de fret se rendent sur la plate-forme de mon client et effectuent une recherche (à partir de la recherche anglaise), en indiquant la direction et, éventuellement, le type de cargaison (ou de fret, du fret anglais), qui convient à un camion. Le système recueille les demandes des expéditeurs et les montre aux transporteurs.
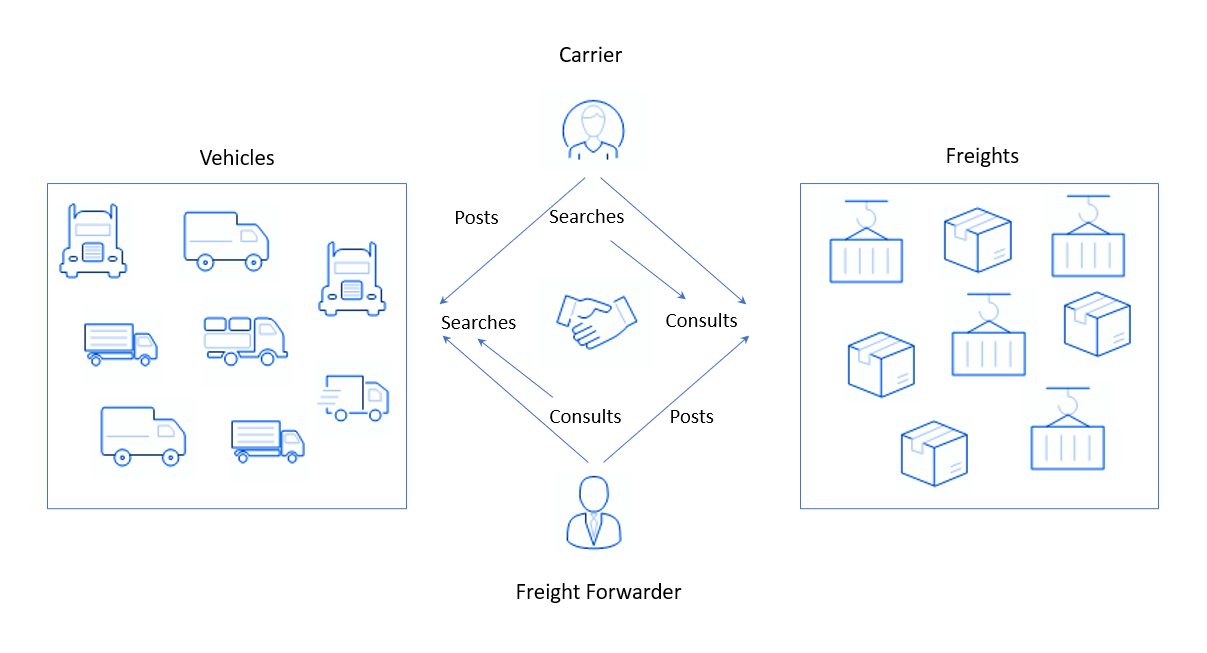
Dans ces plateformes, l'équilibre entre l'offre et la demande est important. Ici, les marchandises sont demandées par les transporteurs de fret et les camions des expéditeurs, et en tant qu'offre, le contraire est vrai: les voitures des transporteurs et les marchandises des entreprises. L'équilibre est difficile à maintenir pour plusieurs raisons, par exemple:
- Communication fermée entre le transporteur et le client. Lorsqu'un pilote ne fonctionne souvent qu'avec un client spécifique, cela ne fonctionne pas bien sur la plate-forme. Si l'expéditeur quitte le marché, le service peut également perdre le transporteur, car il devient client d'une autre société de logistique.
- La présence de marchandises que personne ne veut transporter. Cela se produit lorsque les petites entreprises passent des commandes de transport, puis elles ne sont pas mises à jour et, par conséquent, quittent rapidement le nombre de celles actives.
L'entreprise souhaitait améliorer la fonctionnalité de sa plateforme de bourse de fret et augmenter l'expérience utilisateur des utilisateurs afin qu'ils puissent voir toutes les capacités du système et une large gamme de marchandises, sans perdre leur fidélité. Cela pourrait empêcher le public cible de passer à un service compétitif et montrer aux transporteurs de fret que des commandes appropriées peuvent être trouvées non seulement auprès des entreprises avec lesquelles ils sont habitués à travailler.
Tenant compte de tous les souhaits, j'ai été confronté à la tâche de développer un système de recommandation qui, immédiatement à l'entrée de la plate-forme, montrera aux transporteurs la cargaison pertinente actuellement disponible et devinera ce qu'ils veulent transporter et où. Ce système devait être intégré à la plateforme d'échange de fret existante.
Comment allons-nous «deviner»?
Notre système de recommandation, comme d'autres, fonctionne sur l'analyse des données des utilisateurs. Et il existe plusieurs sources sur lesquelles vous pouvez opérer:
- Tout d'abord, ouvrez les informations sur les applications de transport de marchandises.
- Deuxièmement, la plate-forme fournit des données sur le transporteur. Lorsque l'utilisateur conclut un contrat avec nos clients, il peut indiquer le nombre de camions dont il dispose et le type. Mais, malheureusement, après ces données ne sont pas mises à jour. Et la seule chose sur laquelle nous pouvons compter est le pays du transporteur, car il ne changera probablement pas.
- Troisièmement, le système stocke l'historique des recherches des utilisateurs pendant plusieurs années: à la fois les demandes les plus récentes et il y a un an.
Dans l'application où ils ont décidé de mettre en œuvre le système de recommandation, il existait déjà un mécanisme de recherche de marchandises par demandes antérieures. Par conséquent, nous avons décidé de nous concentrer sur l'identification des modèles ou des modèles par lesquels l'utilisateur recherche des marchandises à transporter. Autrement dit, nous ne recommandons pas la charge, mais sélectionnez la direction qui convient le mieux à cet utilisateur aujourd'hui. Et nous trouverons déjà les produits en utilisant le moteur de recherche standard.
En général, les recherches populaires sont basées sur des informations géographiques et des paramètres supplémentaires tels que le type de camion ou l'article à transporter. C'est assez facile à suivre, car ces préférences changent à peine. Ci-dessous, j'ai donné les données des demandes de l'un des utilisateurs pendant 3 jours. L'ordre de remplissage est le suivant: 1 colonne - pays de départ, 2 - pays de destination, 3 - région de départ, 4 - région de destination.

Vous pouvez voir que cet utilisateur a des préférences spécifiques dans les pays et les provinces. Mais ce n'est pas le cas pour tout le monde et pas toujours. Très souvent, le transporteur n'indique que le pays de destination ou n'indique pas la région de départ, par exemple, il est situé en Belgique et peut venir dans n'importe quelle province pour récupérer la cargaison. En général, il existe différents types de requêtes: pays à pays, pays à région, région à pays ou région à région (la meilleure option).
Échantillons d'algorithme
Comme vous le savez, les stratégies de création de systèmes de recommandation sont principalement divisées en filtrage basé sur le contenu et filtrage collaboratif. Sur cette classification, j'ai commencé à construire des solutions.
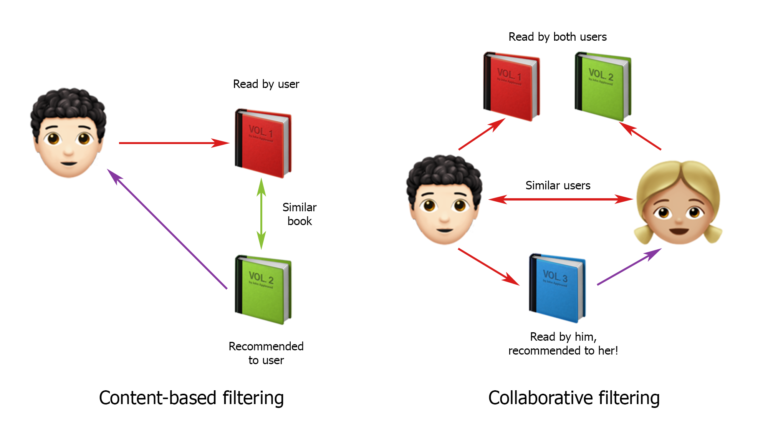
J'ai pris la photo de hub.forklog.com
De nombreuses sources affirment que le filtrage collaboratif fonctionne mieux. C'est simple: nous essayons de trouver des utilisateurs qui sont similaires aux nôtres, avec des schémas de comportement similaires, et nous recommandons à nos utilisateurs les mêmes demandes que les leurs. En général, cette solution était la première option que j'ai présentée aux clients. Mais ils n'étaient pas d'accord avec lui et ont dit que cela ne fonctionnerait pas. Après tout, tout dépend beaucoup de l'endroit où se trouve le camion, de l'endroit où il a transporté la cargaison, de l'endroit où il habite et de l'endroit où il est le plus pratique de se rendre. Nous ne savons pas tout cela, c'est pourquoi il est si difficile de s'appuyer sur le comportement des autres utilisateurs, même s'ils sont, à première vue, similaires.
Maintenant sur les systèmes basés sur le contenu. Ils fonctionnent comme ceci: d'abord, un profil d'utilisateur est déterminé et créé, puis une sélection de recommandations est faite en fonction de ses caractéristiques. C'est une bonne option, mais dans notre cas, il y a quelques nuances. Premièrement, un utilisateur peut masquer tout un groupe de personnes qui recherchent du fret pour de nombreux camions et se connecter à partir de différentes adresses IP. Deuxièmement, à partir des données exactes, nous n'avons que le pays du transporteur, et les informations sur le nombre de camions et leurs types ne sont approximativement "montrées" que dans les demandes faites par l'utilisateur. Autrement dit, afin de créer un système basé sur le contenu pour notre projet, vous devez examiner les demandes de chaque utilisateur et essayer de trouver les plus populaires parmi elles.
Notre premier système de recommandation n'utilisait pas d'algorithmes complexes. Nous avons essayé de classer les requêtes et de trouver les meilleurs cœurs pour les recommander. Pour tester le concept, notre équipe a travaillé avec de vrais utilisateurs: leur a envoyé des recommandations, puis a recueilli des commentaires. En principe, les transporteurs ont aimé le résultat. Ensuite, j'ai comparé nos recommandations avec ce que les transporteurs recherchaient ces jours-ci et j'ai constaté que le système fonctionnait très bien pour les utilisateurs ayant des comportements stables. Mais, malheureusement pour ceux qui ont fait un plus large éventail de demandes, l'exactitude des recommandations n'était pas très élevée - le système devait être amélioré.
J'ai continué à comprendre de quoi nous avons affaire ici. En fait, il s'agit d'un modèle Markov caché où un groupe de personnes peut être derrière chaque utilisateur. De plus, les utilisateurs peuvent être dans divers états cachés: il n'y a pas de données sur l'endroit où ils ont actuellement un camion, combien de personnes sont sur un même compte et quand la prochaine fois ils devront aller quelque part. À cette époque, je ne connaissais pas de solutions toutes faites pour la production du modèle caché de Markov, j'ai donc décidé de trouver quelque chose de plus simple.
Rencontrer le PageRank
J'ai donc attiré l'attention sur l'algorithme PageRank, une fois créé par les fondateurs de Google Sergey Brin et Larry Page, qui est toujours utilisé par ce moteur de recherche pour recommander des sites aux utilisateurs. Le PageRank représente tout l'espace Internet sous la forme d'un graphique, où chaque page Web est son nœud. Il peut être utilisé pour calculer «l'importance» (ou le rang) de chaque nœud. Le PageRank est fondamentalement différent des algorithmes de recherche qui existaient avant lui, car il est basé non pas sur le contenu des pages, mais sur les liens qui s'y trouvent. Autrement dit, le classement de chaque page dépend du nombre et de la qualité des liens pointant vers elle. Brin et Page ont prouvé la convergence de cet algorithme, ce qui signifie que nous pouvons toujours calculer le rang de n'importe quel nœud dans un graphe orienté et arriver à des valeurs qui ne changeront pas.
Regardons sa formule:
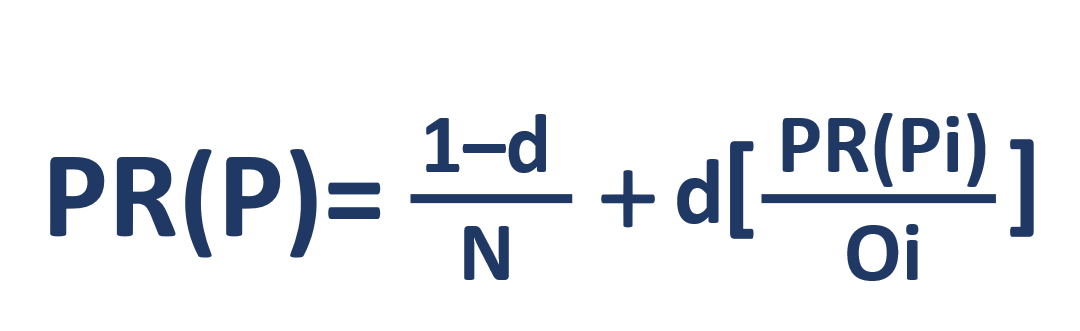
- PR(P) – rank
- N –
- i –
- O –
- d – . -, , - . , . 0 ≤ d ≤ 1 – d 0,85. .
Et maintenant, un exemple simple de calcul du PageRank pour un graphique simple composé de trois nœuds. Il est important de se rappeler qu'au début, tous les nœuds reçoivent le même poids égal à 1 / nombre de nœuds.
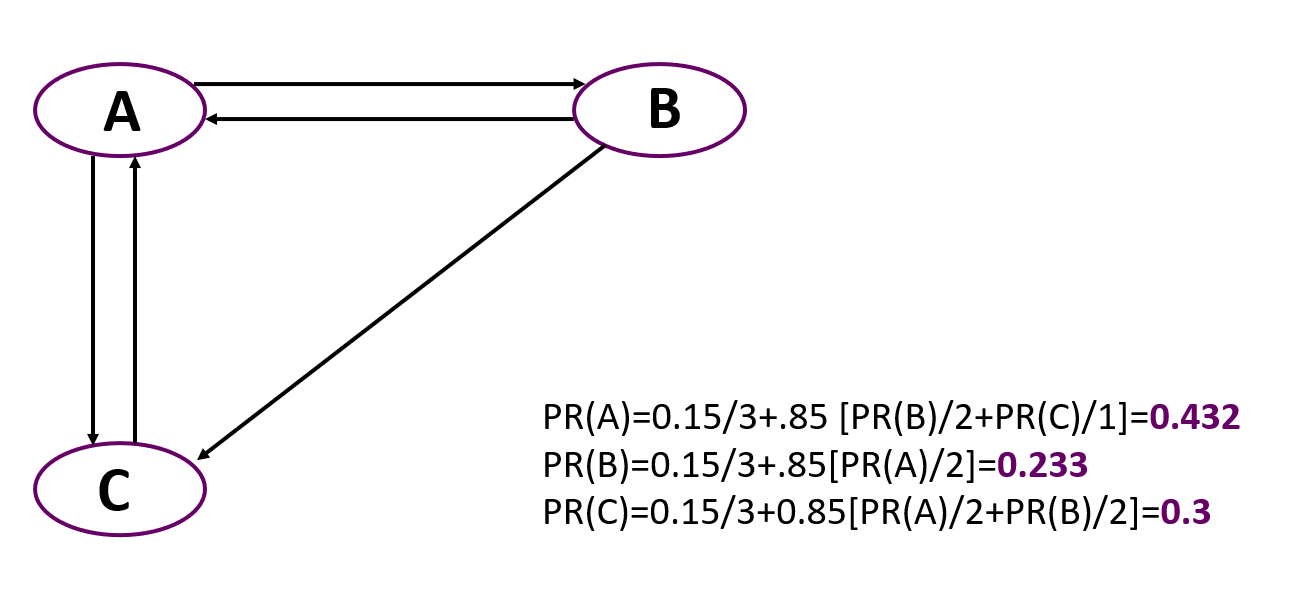
Vous pouvez voir que le plus important ici est le nœud A, malgré le fait que seuls deux nœuds pointent vers lui, comme vers C. Mais le rang des nœuds pointant vers A est plus élevé que celui des nœuds menant à C.
Hypothèses et solution
Le PageRank décrit donc un processus Markov sans états cachés. En l'utilisant, nous trouverons toujours le poids final de chaque nœud, mais nous ne pourrons pas suivre les changements dans le graphique. L'algorithme est vraiment bon, nous avons pu l'adapter et améliorer la précision des résultats. Pour ce faire, nous avons pris une modification du PageRank - l'algorithme de PageRank personnalisé, qui diffère de l'algorithme de base en ce que la transition est toujours effectuée vers un nombre limité de nœuds. C'est-à-dire que lorsque l'utilisateur en a assez de «parcourir» les liens, il ne passe pas à un nœud aléatoire, mais à l'un d'un ensemble donné.
Dans notre cas, les nœuds du graphe seront les requêtes des utilisateurs. Puisque notre algorithme est censé donner des recommandations pour le jour à venir, j'ai ventilé toutes les demandes pour chaque opérateur par jour. Maintenant, nous construisons un graphe: le nœud A se connecte au nœud B, si la recherche de type B suit la recherche de type A, c'est-à-dire que la recherche de type A a été effectuée par l'utilisateur avant le jour où il cherchait l'itinéraire B. Par exemple: "Paris - Bruxelles" le mardi (A), et le mercredi «Bruxelles - Cologne» (B). Et certains utilisateurs font beaucoup de requêtes par jour, donc plusieurs nœuds sont connectés les uns aux autres à la fois, et par conséquent, nous obtenons des graphiques assez complexes.
Pour ajouter des informations sur l'importance de passer d'un cœur à un autre, nous avons ajouté des poids des bords du graphique. Le poids du bord A-B est le nombre de fois où l'utilisateur a recherché B après avoir recherché A. Il est également très important de prendre en compte l'âge des requêtes, car l'utilisateur change de modèle: il peut déplacer ou réorganiser le type de transport principal, après quoi il ne souhaite pas partir avec un camion vide. Par conséquent, vous devez surveiller l'historique des routes - nous ajoutons la variable de référence, qui affectera également le poids du nœud.
Il convient de considérer la saisonnalité: nous savons peut-être que, par exemple, en septembre, le transporteur se rend souvent en France et en octobre - en Allemagne. En conséquence, plus de poids peut être donné aux cœurs qui sont «populaires» dans un certain mois. De plus, nous nous basons sur les informations sur ce que l'utilisateur a recherché la dernière fois. Cela aide à deviner indirectement où le camion pourrait être.
Résultat
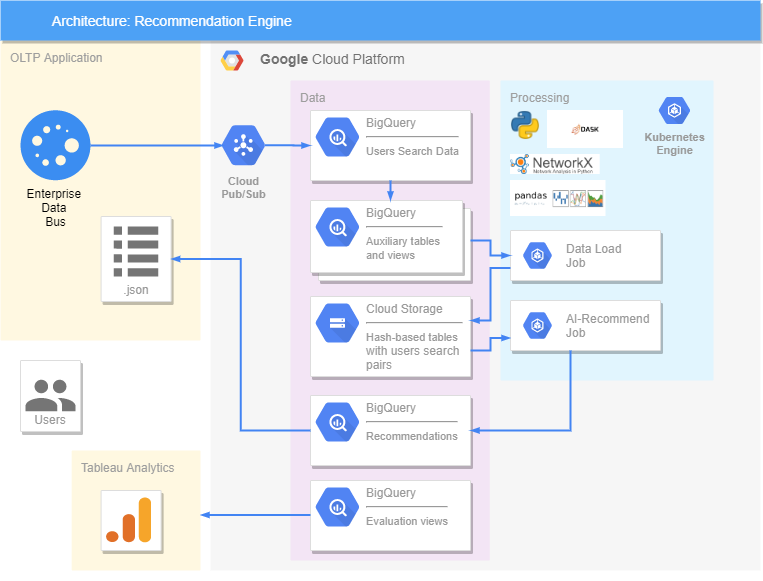
Tout est mis en œuvre sur la plateforme Google. Nous avons une application OLTP, d'où les données sur les requêtes vont et viennent vers BigQuery, où des vues supplémentaires et des tables contenant des informations déjà traitées sont formées. La bibliothèque DASK a été utilisée pour accélérer et paralléliser le traitement de grandes quantités de données. Dans notre solution, toutes les données sont transférées vers Cloud Storage, car DASK ne fonctionne qu'avec lui et n'interagit pas avec BigQuery. Deux emplois ont été créés dans Kubernetes, dont l'un transfère les données de BigQuery vers Cloud Storage, et le second fait des recommandations. Cela fonctionne comme ceci: Job récupère des données sur des paires de cœurs dans Cloud Storage, les traite, génère des recommandations pour le jour à venir et les renvoie à BigQuery. De là, déjà au format .json, nous pouvons envoyer des recommandations à l'application OLTP, où les utilisateurs les verront.La précision des recommandations est évaluée dans Tableau, où nos recommandations sont comparées à ce que l'utilisateur recherchait réellement, ainsi qu'à sa réaction (qu'il l'a plu ou non).
Bien sûr, je voudrais partager les résultats. Par exemple, voici un utilisateur qui crée chaque jour 14 cœurs de pays à pays. Nous lui avons également recommandé le même montant:
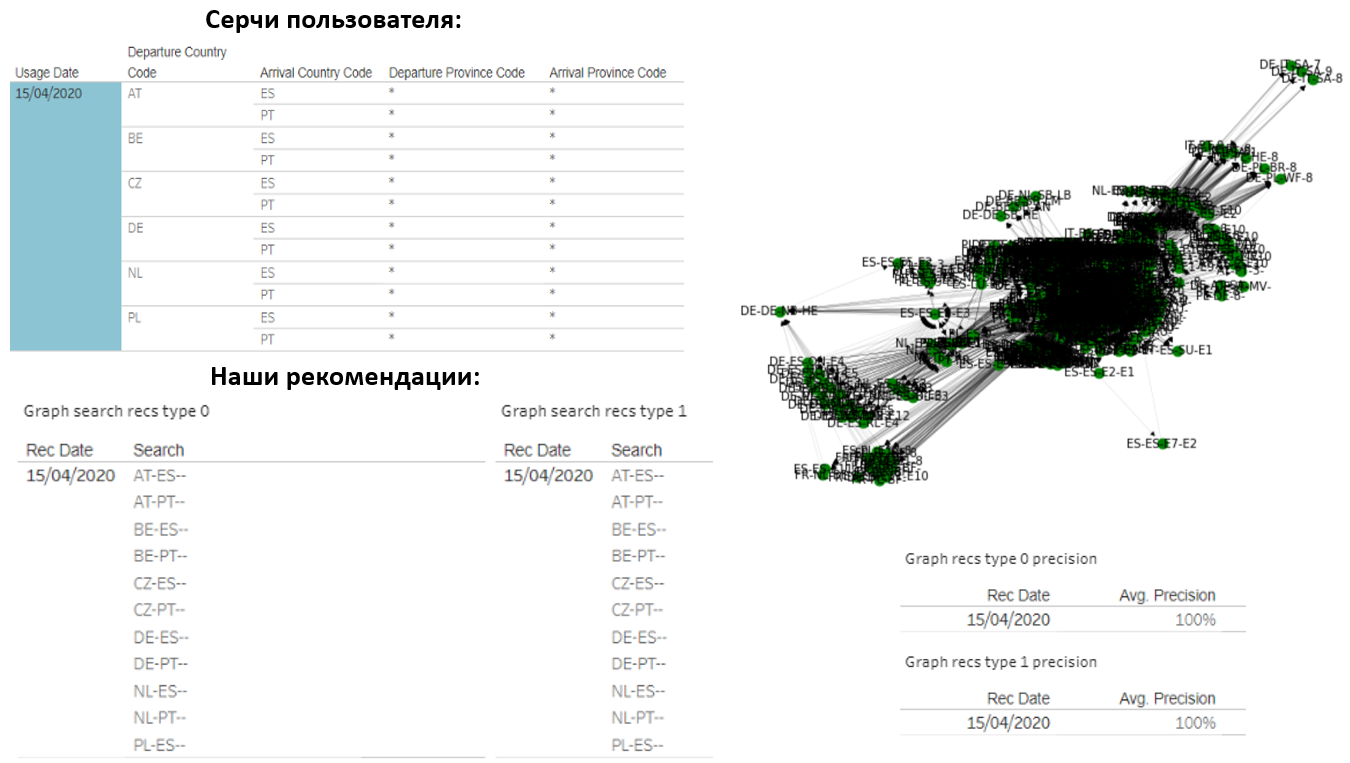
il s'est avéré que nos options coïncidaient complètement avec ce qu'il recherchait. Le graphique de cet utilisateur se compose d'environ 1000 requêtes différentes, mais nous avons réussi à deviner très précisément ce qui l'intéresserait.
Le deuxième utilisateur effectue en moyenne 8 demandes différentes tous les 2 jours, et il recherche à la fois au format «pays-pays», et avec une indication d'une région de départ spécifique. De plus, les pays de départ et de livraison sont complètement différents. Par conséquent, nous ne pouvions pas tout «deviner» et la précision des résultats s'est avérée inférieure:

Notez que l'utilisateur dispose de 2 graphiques avec des poids différents. Dans un cas, la précision a atteint 38%, ce qui signifie que quelque part 3 des 8 options recommandées par nous se sont avérées pertinentes. Et, peut-être, si nous trouvons des charges dans ces directions, l'utilisateur les choisira.
Le dernier et le plus simple exemple. Une personne effectue environ 2 recherches par jour. Il a des modèles très stables, pas trop de préférences et un graphique simple. En conséquence, la précision de nos prévisions est de 100%.

La performance en faits
- Nos algorithmes fonctionnent sur 4 processeurs standard et 10 Go de mémoire.
- Les volumes de données peuvent atteindre 1 milliard d'enregistrements.
- Il faut 18 minutes pour créer des recommandations pour tous les utilisateurs d'environ 20 000 personnes.
- La bibliothèque DASK est utilisée pour la parallélisation et la bibliothèque NetworkX est utilisée pour l'algorithme PageRank.
Je peux dire que nos recherches et nos expériences ont donné de très bons résultats. La présentation du comportement des utilisateurs de la plateforme d'échange de fret sous forme de graphique et l'utilisation du PageRank nous permet de prédire avec précision leurs préférences futures et, ainsi, de construire des systèmes de recommandation efficaces.