Le traitement de quelques gigaoctets de données sur un ordinateur portable ne peut être une tâche ardue que s'il ne dispose pas de beaucoup de RAM et d'une bonne puissance de traitement.
Malgré cela, les data scientists doivent encore trouver des solutions alternatives à ce problème. Il existe des options pour configurer Pandas pour gérer d'énormes ensembles de données, acheter des GPU ou acheter de la puissance de cloud computing. Dans cet article, nous verrons comment utiliser Dask pour de grands ensembles de données sur votre machine locale.
Dask et Python
Dask est une bibliothèque de calcul parallèle flexible pour Python. Il fonctionne très bien avec d'autres projets open source tels que NumPy, Pandas et scikit-learn. Dask a une matrice Structure qui est équivalente à matrices numpy, Dask dataframes sont semblables à Pandas dataframes et Dask-ML est scikit-learn.
Ces similitudes facilitent l'intégration de Dask dans votre travail. L'avantage d'utiliser Dask est que vous pouvez mettre à l'échelle des calculs sur plusieurs cœurs sur votre ordinateur. Vous avez ainsi la possibilité de travailler avec de grandes quantités de données qui ne tiennent pas dans la mémoire. Vous pouvez également accélérer les calculs qui prennent généralement beaucoup de place.
La source
Dask DataFrame
Lors du chargement d'une grande quantité de données, Dask lit généralement un échantillon des données afin de reconnaître les types de données. Cela conduit le plus souvent à des erreurs, car il peut y avoir différents types de données dans la même colonne. Il est recommandé de déclarer les types à l'avance pour éviter les erreurs. Dask peut télécharger des fichiers volumineux en les découpant en blocs définis par le paramètre
blocksize.
data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )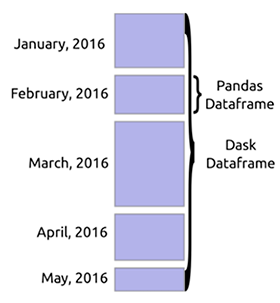
Les
commandes source dans Dask DataFrame sont similaires aux commandes Pandas. Par exemple, obtenir
headettail dataframe est similaire:
df.head()
df.tail()Les fonctions du DataFrame sont paresseuses. Autrement dit, ils ne sont pas évalués tant que la fonction n'est pas appelée
compute.
df.isnull().sum().compute()Étant donné que les données sont chargées par blocs, certaines fonctions Pandas telles que
sort_values()échoueront. Mais vous pouvez utiliser la fonctionnlargest().
Clusters à Dask
Le calcul parallèle est essentiel dans Dask car il vous permet de lire sur plusieurs cœurs en même temps. Dask fournit
machine schedulerqui fonctionne sur une seule machine. Il ne s'adapte pas. Il y en a aussi un distributed schedulerqui vous permet de passer à plusieurs machines.
L'utilisation
dask.distributednécessite une configuration client. C'est la première chose que vous faites si vous prévoyez de l'utiliser dask.distributed dans votre analyse. Il offre une faible latence, une localisation des données, une communication entre les travailleurs et est facile à configurer.
from dask.distributed import Client
client = Client()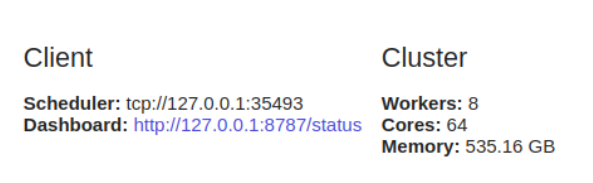
Il est
dask.distributedavantageux de l' utiliser même sur une seule machine car il offre des fonctions de diagnostic via un tableau de bord.
Si vous ne configurez pas
Client, vous utiliserez par défaut le planificateur de machine pour une machine. Il fournira la concurrence sur un seul ordinateur en utilisant des processus et des threads.
Dask ML
Dask permet également la formation et la prédiction de modèles parallèles. L'objectif
dask-mlest de proposer un apprentissage automatique évolutif. Lorsque vous déclarez n_jobs = -1 scikit-learn, vous pouvez exécuter des calculs en parallèle. Dask utilise cette fonctionnalité pour vous permettre d'effectuer des calculs dans un cluster. Vous pouvez le faire avec le package joblib , qui permet le parallélisme et le pipelining en Python. Avec Dask ML, vous pouvez utiliser des modèles scikit-learn et d'autres bibliothèques comme XGboost.
Une implémentation simple ressemblerait à ceci.
Tout d'abord, importez
train_test_splitpour diviser vos données en cas de formation et de test.
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Importez ensuite le modèle que vous souhaitez utiliser et instanciez-le.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)Ensuite, vous devez importer
joblibpour activer le calcul parallèle.
import joblibEnsuite, commencez la formation et les prévisions avec le backend parallèle.
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)Limites et utilisation de la mémoire
Les tâches individuelles dans Dask ne peuvent pas s'exécuter en parallèle. Les workers sont des processus Python qui héritent des avantages et des inconvénients du calcul Python. De plus, lorsque vous travaillez dans un environnement distribué, des précautions doivent être prises pour assurer la sécurité et la confidentialité de vos données.
Dask dispose d'un planificateur central qui surveille les données sur les nœuds de travail et dans le cluster. Il gère également la publication des données du cluster. Lorsque la tâche est terminée, il la supprimera immédiatement de la mémoire pour faire de la place pour d'autres tâches. Mais si quelque chose est nécessaire à un client spécifique, ou est important pour les calculs en cours, il sera stocké en mémoire.
Une autre limitation de Dask est qu'il n'implémente pas toutes les fonctionnalités de Pandas. L'interface Pandas est très grande, donc Dask ne la couvre pas complètement. Autrement dit, effectuer certaines de ces opérations dans Dask peut être difficile. En outre, les opérations lentes de Pandas seront également lentes à Dask.
Lorsque vous n'avez pas besoin d'un Dask DataFrame
Dans les situations suivantes, Dask peut ne pas être la bonne option pour vous:
- Lorsque Pandas a des fonctions dont vous avez besoin, mais que Dask ne les a pas implémentées.
- Lorsque vos données s'intègrent parfaitement dans la mémoire de votre ordinateur.
- Lorsque vos données ne sont pas sous forme de tableau. Si tel est le cas, essayez dask.bag ou disk.array .
Dernières pensées
Dans cet article, nous avons vu comment vous pouvez utiliser Dask pour travailler de manière distribuée avec d'énormes ensembles de données sur votre ordinateur local. Nous avons vu que nous pouvons utiliser Dask, puisque sa syntaxe nous est déjà familière. Dask peut également évoluer jusqu'à des milliers de cœurs.
Nous avons également vu que nous pouvons l'utiliser dans l'apprentissage automatique pour la prédiction et la formation. Si vous voulez en savoir plus, consultez ces documents dans la documentation .
