Tensorflow, tout en perdant du terrain dans l'environnement de recherche, est toujours populaire dans le développement pratique. L'une des forces de TF qui le maintient à flot est sa capacité à optimiser les modèles pour un déploiement dans des environnements à ressources limitées. Il existe des cadres spéciaux pour cela: Tensorflow Lite pour les appareils mobiles et Tensorflow Servingà usage industriel. Il existe suffisamment de tutoriels sur leur utilisation sur le Web (et même sur Habré). Dans cet article, nous avons rassemblé notre expérience dans l'optimisation de modèles sans utiliser ces frameworks. Nous examinerons certaines des méthodes et bibliothèques qui accomplissent la tâche, décrirons comment vous pouvez économiser de l'espace disque et de la RAM, les forces et les faiblesses de chaque approche et certains effets inattendus que nous avons rencontrés.
Dans quelles conditions travaillons-nous
L'une des tâches classiques de la PNL est la classification thématique de textes courts. Les classificateurs sont représentés par de nombreuses architectures différentes, allant des méthodes classiques comme SVC aux architectures de transformateurs comme BERT et ses dérivés. Nous examinerons CNN - des modèles convolutifs.
Une limitation importante pour nous est la nécessité de former et d'utiliser des modèles (dans le cadre du produit) sur des machines sans GPU. Cela affecte principalement la vitesse d'apprentissage et d'inférence.
Une autre condition est que les modèles de classification soient formés et utilisés dans des ensembles de plusieurs pièces. Un ensemble de modèles, même simples, peut utiliser beaucoup de ressources, en particulier la RAM. Nous utilisons notre propre solution pour servir les modèles, cependant, si vous devez utiliser des ensembles de modèles, jetez un œil à Tensorflow Serving .
TF 1.x, . TF 2.x , API, .
.
TF-
Shallow CNN — . .

v x k, v — , k — .
:
- Embedding-, .
- w x k. , (1, 1, 2, 3) 4 , 1 , 2 3 , .
- Max-pooling .
- , dropout- softmax- .
Adam, .
: .
, , 128 c w = 2 k = 300 () [filter_height, filter_width, in_channels, output_channels] — , 2*300*1*128 = 76800 float32, , 76800*(32/8) = 307200 .
? ( 220 . ) 300 265 . , .
TF . ( ), , , — ( ), . (). :
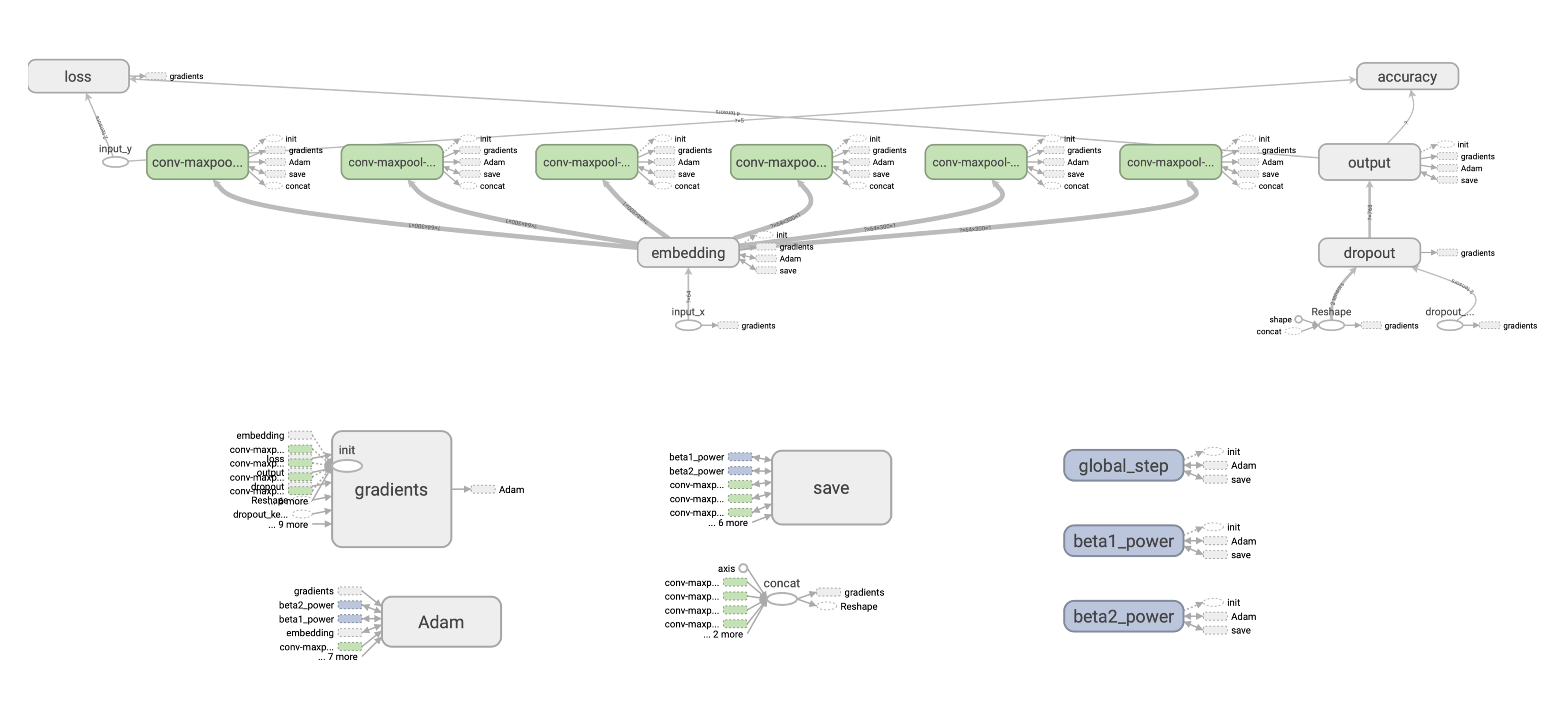
. , : SavedModel. , .
Checkpoint
, Saver API:
saver = tf.train.Saver(save_relative_paths=True)
ckpt_filepath = saver.save(sess, "cnn.ckpt"), global_step=0)global_step , , — cnn-ckpt-0.
<model_path>/cnn_ckpt :

checkpoint — . , TF . , .
.data , . , — 800 . , (≈265 ). ( ). , .
.index .
.meta — , (, , ), GraphDef, . , . — .meta , ? , TF - embedding-. , , , , , . , , :
with tf.Session() as sess:
saver = tf.train.import_meta_graph('models/ckpt_model/cnn_ckpt/cnn.ckpt-0.meta') # load meta
for n in tf.get_default_graph().as_graph_def().node:
print(n.name, n['attr'].shape)SavedModel
, . . API tf.saved_model. tf.saved_model, TF- (TFLite, TensorFlow.js, TensorFlow Serving, TensorFlow Hub).
:
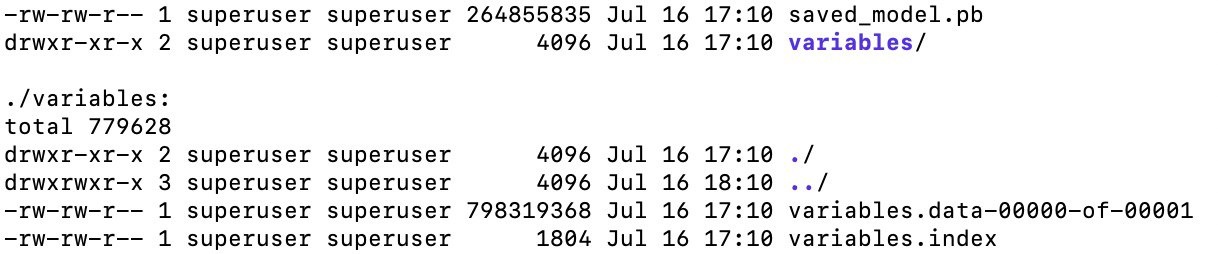
saved_model.pb, , , .meta , (, ), API, ( CLI, ).
SavedModel — , . “” . , , - — , .
, CNN-, TF 1.x, . .
, 1 , :
-
. , , ( tools.optimize_for_inference ). -
. , , — , tf.trainable_variables(). -
, . , (. BERT). -
. , . .
, , . , forward pass, . , . 1 265 .
TF 1.x , .
( ) GraphDef:
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def() . : tf.python.tools.freeze_graph tf.graph_util.convert_variables_to_constants. ( ) (, ['output/predictions']), , , . .
output_graph_def = graph_util.convert_variables_to_constants(self.sess, input_graph_def, output_node_names), .
freeze_graph() ( , , ). graph_util.convert_variables_to_constants() :
with tf.io.gfile.GFile('graph.pb', 'wb') as f:
f.write(output_graph_def.SerializeToString())266 , :
# GraphDef
with tf.io.gfile.GFile(graph_filepath, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
#
self.input_x = tf.placeholder(tf.int32, [None, self.properties.max_len], name="input_x")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# graph_def
input_map = {'input_x': self.input_x, 'dropout_keep_prob': self.dropout_keep_prob}
tf.import_graph_def(graph_def, input_map), import:
predictions = graph.get_tensor_by_name('import/output/predictions:0'):
feed_dict = {self.input_x: encode_sentence(sentence), self.dropout_keep_prob: 1.}
sess.run(self.predictions, feed_dict), :
- . ,
sess.run(...). , CPU 20 ms, ~2700 ms. , . SavedModel . - RAM. RAM, . ~265 , . , TF GraphDef .
- – RAM TF . 1.15, TF 1.x, 118 MiB, 1.14 – 3 MiB.
, . ? / TF- tf.train.Saver. , , , :
- MetaGraph
tf.train.Saver . , :
saver = tf.train.Saver(var_list=tf.trainable_variables())MetaGraph . , meta . MetaGraph save:
ckpt_filepath = saver.save(self.sess, filepath, write_meta_graph=False)1014 M 265 M ( , ).
, TF 1.x:
- Grappler: c tensorflow
- Pruning API: google-research
- Graph Transform Tool:
, — tensorflow, Grappler. Grappler . , set_experimental_options. , zip . , zip , . Grappler .
google-research mask threshold, . . , , mask threshold, , , . .
Grappler, . : ? , ? , 0.99 . , mc, hex :

, , . . -, . -, , , , . , .
CNN. .
, . Graph transform tool.
quantize_weights 8 . , 8- . , , - .
quantize_nodes 8- . .
, - . quantize_weights - , 4 .
, , TensorFlow Lite, .
— , . 64 (32) , .
RAM Ubuntu ( numpy int64) . 220 , int32, int16. .

tf-. float16. , , ( 10%), ( 10 ). , , epsilon learning_rate . , , .
RAM
, . , .
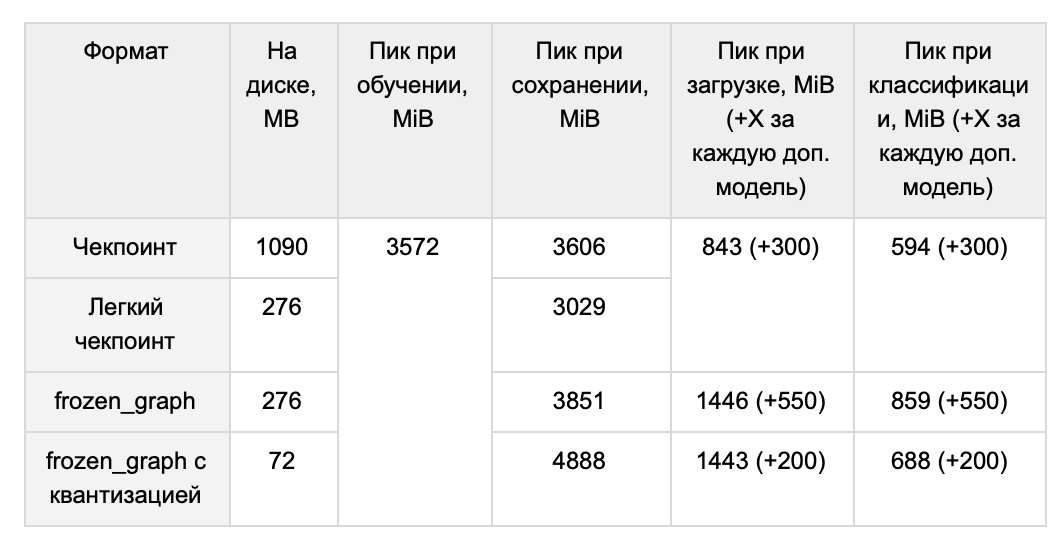
, . . .
QA-
Q: -, - ?
A: , . word2vec. ( , , min count, learning rate), 220 ( — 265 MB) CNN, 439 (510 MB).
- , , , - . , ( ). , . YouTokenToMe, , , .. , .., . . , , , . 30 (37 MB) , 3.7 CPU 2.6 GPU. ( ), OOV-.
Q: , , ?
A: , .
:
1. :
with tf.gfile.GFile(path_to_pb, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, name='')
return graph2. "" :
sess.run(restored_variable_names) 3. , .
4. , , :
tf.Variable(tensors_to_restore["output/W:0"], name="W"), .
, , .
Nous n'avons pas essayé de recycler les modèles compressés par le reste des méthodes décrites, mais théoriquement, cela ne devrait pas poser de problème.
Q: Existe-t-il d'autres moyens de réduire l'optimisation que vous n'avez pas envisagés?
R: Nous avons plusieurs idées que nous n'avons jamais pu réaliser. Premièrement, le pliage constant est un «pliage» d'un sous-ensemble de nœuds de graphe, pré-calcul des valeurs des parties du graphe qui sont faiblement dépendantes des données d'entrée. Deuxièmement, dans notre modèle, cela semble être une bonne solution pour appliquer la taille des plongements.