
À quoi ressemblent les données?
Tout d'abord, examinons les données de test et d'entraînement disponibles (données du défi de classification des commentaires toxiques sur la plate-forme kaggle.com). Dans les données d'entraînement, contrairement aux données de test, il y a des étiquettes pour la classification:
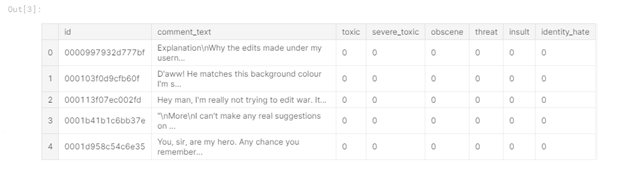
Figure 1 - Tête de données du train
Dans le tableau, vous pouvez voir que nous avons 6 colonnes d'étiquettes dans les données d'entraînement («toxique», «grave_toxique», «obscène», «menace» , "Insult", "identity_hate"), où la valeur "1" indique que le commentaire appartient à la classe, il y a aussi une colonne "comment_text" contenant le commentaire et une colonne "id" - l'identifiant du commentaire.
Les données de test ne contiennent pas d'étiquettes de classe, car elles sont utilisées pour envoyer la solution:

Figure 2 - Tête de données de test
Extraction de caractéristiques
L'étape suivante consiste à extraire les caractéristiques des commentaires et à effectuer une analyse exploratoire des données (EDA). Tout d'abord, examinons la distribution des types de commentaires dans l'ensemble de données d'entraînement. Pour cela, une nouvelle colonne "toxic_type" a été créée, contenant toutes les classes auxquelles appartenait le commentaire:

Figure 3 - Top-10 types de commentaires toxiques
Le tableau montre que le type dominant est l'absence de balises de classe, et de nombreux commentaires appartiennent à plus d'un classe.
Voyons également comment le nombre de types est réparti pour chaque commentaire:

Figure 4 - Nombre de types rencontrés
Notez que la situation qui prévaut est lorsque le commentaire est caractérisé par un seul type de toxicité, et bien souvent le commentaire est caractérisé par trois types de toxicité, et moins souvent le commentaire est attribué à tous les types.
Passons maintenant à l'étape d'extraction de fonctionnalités à partir de texte, souvent appelée extraction de fonctionnalités. J'ai extrait les attributs suivants:
Longueur du commentaire. Je suppose que les commentaires en colère seront probablement brefs;
Majuscule. Dans les commentaires agressifs-émotionnels, il est possible que les majuscules soient plus courantes dans les mots;
Émoticônes. Lors de l'écriture d'un commentaire toxique, il est peu probable que des émoticônes de couleur positive (:), etc. soient utilisées, nous considérons également la présence d'émoticônes tristes (:(, etc.);
Ponctuation. Probablement, les auteurs de commentaires négatifs n'adhèrent pas aux règles de ponctuation, dans une plus grande mesure, ils utilisent "!";
Le nombre de caractères tiers. Certaines personnes utilisent souvent les symboles @, $, etc. pour écrire des mots choquants.
Les fonctionnalités sont ajoutées comme suit:
train_data[‘total_length’] = train_data[‘comment_text’].apply(len)
train_data[‘uppercase’] = train_data[‘comment_text’].apply(lambda comment: sum(1 for c in comment if c.isupper()))
train_data[‘exclamation_punction’] = train_data[‘comment_text’].apply(lambda comment: comment.count(‘!’))
train_data[‘num_punctuation’] = train_data[‘comment_text’].apply(lambda comment: comment.count(w) for w in ‘.,;:?’))
train_data[‘num_symbols’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in ‘*&$%’))
train_data[‘num_words’] = train_data[‘comment_text’].apply(lambda comment: len(comment.split()))
train_data[‘num_happy_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-)’, ‘:)’, ‘;)’, ‘;-)’)))
train_data[‘num_sad_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-(’, ‘:(’, ‘;(’, ‘;-(’)))L'analyse exploratoire des données
Explorons maintenant les données en utilisant les fonctionnalités que nous venons d'obtenir. Tout d'abord, regardons la corrélation des entités entre elles, la corrélation entre les entités et les étiquettes de classe, la corrélation entre les étiquettes de classe:

Figure 5 - Corrélation La
corrélation indique la présence d'une relation linéaire entre les entités. Plus la valeur de la corrélation en module est proche de 1, plus la dépendance linéaire entre les éléments est prononcée.
Par exemple, vous pouvez voir que le nombre de mots et la longueur du texte sont fortement corrélés les uns aux autres (valeur 0,99), ce qui signifie que certaines fonctionnalités peuvent être supprimées, j'ai supprimé le nombre de mots. Nous pouvons également tirer plusieurs autres conclusions: il n'y a pratiquement pas de corrélation entre les caractéristiques sélectionnées et les étiquettes de classe, la caractéristique la moins corrélée est le nombre de caractères, et la longueur du texte est en corrélation avec le nombre de caractères de ponctuation et le nombre de caractères convertis en majuscules.
Ensuite, nous allons créer plusieurs visualisations pour une compréhension plus détaillée de l'influence des fonctionnalités sur l'étiquette de classe. Voyons d'abord comment les longueurs des commentaires sont réparties:

Figure 6 - Distribution des longueurs des commentaires (le graphique est interactif, mais voici une capture d'écran)
Comme prévu, les commentaires qui n'ont pas été classés (c'est-à-dire normaux) sont beaucoup plus longs que les commentaires étiquetés. Parmi les commentaires négatifs, les plus courts sont des menaces et les plus longs sont toxiques.
Examinons maintenant les commentaires en termes de ponctuation. Nous allons construire des représentations graphiques pour les valeurs moyennes pour rendre les graphiques plus interprétables:

Figure 7 - Valeurs de ponctuation moyennes (le graphique est interactif, mais voici une capture d'écran)
Sur la figure, vous pouvez voir que nous avons trois clusters.
Le premier concerne les commentaires normaux, ils se caractérisent par le respect des règles de ponctuation (placement des signes de ponctuation, ":", par exemple) et un petit nombre de points d'exclamation.
Le second est constitué de menaces et de commentaires très toxiques (toxique sévère), ce groupe se caractérise par une utilisation abondante de points d'exclamation et d'autres signes de ponctuation sont utilisés au niveau intermédiaire.
Le troisième groupe - toxique (toxique), obscène (obscène), insultes (insulte) et haineux envers une certaine personne (haine d'identité) a un petit nombre de signes de ponctuation et de points d'exclamation.
Ajoutons un troisième axe pour plus de clarté - majuscules:

Figure 8 - Image en
trois dimensions (interactive, mais voici une capture d'écran) Ici, nous voyons une situation similaire - trois groupes sont mis en évidence. Notez également que la distance entre les éléments du deuxième cluster est supérieure à la distance entre les éléments du troisième cluster. Cela peut également être vu dans le graphique 2D:

Figure 9 - Majuscules et ponctuation (interactif, voici une capture d'écran)
Regardons maintenant les types de commentaires dans le contexte des majuscules / le nombre de caractères tiers:

Figure 10 - Majuscules et le nombre de caractères tiers (interactif, voici une capture d'écran)
Comme vous pouvez le voir, les commentaires très toxiques sont clairement mis en évidence - ils ont un grand nombre de caractères majuscules et de nombreux caractères tiers. En outre, les symboles tiers sont activement utilisés par les auteurs de commentaires haineux pour une personne.
Ainsi, mettre en évidence de nouvelles fonctionnalités et les visualiser permet une meilleure interprétation des données disponibles, et les visualisations ci-dessus peuvent être résumées comme suit:
Les commentaires hautement toxiques sont séparés du reste;
Les commentaires normaux ressortent également;
Les commentaires toxiques, obscènes et offensants sont très proches les uns des autres en termes de caractéristiques considérées.
Utilisation du DataFrameMapper pour combiner des fonctionnalités textuelles et numériques
Voyons maintenant comment vous pouvez utiliser ensemble des fonctionnalités textuelles et numériques dans la régression logistique.
Tout d'abord, vous devez choisir un modèle pour représenter le texte sous une forme adaptée aux algorithmes d'apprentissage automatique. J'ai utilisé le modèle tf-idf, car il peut mettre en évidence des mots spécifiques et rendre les mots fréquents moins significatifs (par exemple, les prépositions):
tvec = TfidfVectorizer(
sublinear_tf=True,
strip_accents=’unicode’,
analyzer=’word’,
token_pattern=r’\w{1,}’,
stop_words=’english’,
ngram_range=(1, 1),
max_features=10000
)Ainsi, si nous voulons travailler avec le dataframe fourni par la bibliothèque Pandas et les algorithmes d'apprentissage automatique de la bibliothèque Sklearn, nous pouvons utiliser le module Sklearn-pandas, qui sert en quelque sorte de liant entre les méthodes dataframe et Sklearn.
mapper = DataFrameMapper([
([‘uppercase’], StandardScaler()),
([‘exclamation_punctuation’], StandardScaler()),
([‘num_punctuation’], StandardScaler()),
([‘num_symbols’], StandardScaler()),
([‘num_happy_smilies’], StandardScaler()),
([‘num_sad_smilies’], StandardScaler()),
([‘total_length’], StandardScaler())
], df_out=True)Vous devez d'abord créer un DataFrameMapper comme indiqué ci-dessus, il doit contenir les noms des colonnes avec des fonctionnalités numériques. Ensuite, nous créons une matrice de fonctionnalités, que nous transférerons ensuite vers la régression logistique pour la formation:
x_train = np.round(mapper.fit_transform(numeric_features_train.copy()), 2).values
x_train_features = sparse.hstack((csr_matrix(x_train), train_texts))Une séquence d'actions similaire est également effectuée sur l'ensemble de données de test.
Expérience informatique
Pour réaliser une classification multi-étiquettes, nous allons construire une boucle qui passera par toutes les catégories et évaluerons la qualité de la classification par validation croisée avec les paramètres cv = 3 et scoring = 'roc_auc':
scores = []
class_names = [‘toxic’, ‘severe_toxic’, ‘obscene’, ‘threat’, ‘identity_hate’]
for class_name in class_names:
train_target = train_data[class_name]
classifier = LogisticRegression(C=0.1, solver= ‘sag’)
cv_score = np.mean(cross_val_score(classifier, x_train_features, train_target, cv=3, scoring= ‘auc_roc’))
scores.append(cv_score)
print(‘CV score for class {} is {}’.format(class_name, cv_score))
classifier.fit(train_features, train_target)
print(‘Total CV score is {}’.format(np.mean(scores)))</source
<b> :</b>
<img src="https://habrastorage.org/webt/kt/a4/v6/kta4v6sqnr-tar_auhd6bxzo4dw.png" />
<i> 11 — </i>
, , , , , . , , , . - , “toxic”, , , ( 3). , , , .