
Aujourd'hui, les réseaux de neurones artificiels sont au cœur de nombreuses techniques d '«intelligence artificielle». Dans le même temps, le processus de formation de nouveaux modèles de réseaux neuronaux est tellement mis en marche (grâce à un grand nombre de frameworks distribués, d'ensembles de données et d'autres "blancs") que les chercheurs du monde entier créent facilement de nouveaux algorithmes "efficaces" "sûrs", parfois sans même entrer dans voilà le résultat. Dans certains cas, cela peut entraîner des conséquences irréversibles à l'étape suivante, lors du processus d'utilisation d'algorithmes entraînés. Dans l'article d'aujourd'hui, nous analyserons un certain nombre d'attaques contre l'intelligence artificielle, leur fonctionnement et les conséquences qu'elles peuvent entraîner.
Comme vous le savez, chez Smart Engines , nous traitons chaque étape du processus de formation du modèle de réseau neuronal avec appréhension, de la préparation des données (voir ici , ici et ici ) au développement de l'architecture réseau (voir ici , ici et ici ). Sur le marché des solutions utilisant l'intelligence artificielle et les systèmes de reconnaissance, nous sommes les guides et promoteurs d'idées pour un développement technologique responsable. Il y a même un mois, nous avons rejoint le Pacte mondial des Nations Unies .
Alors, pourquoi est-ce si effrayant d'apprendre «négligemment» les réseaux de neurones? Un mauvais maillage (qui ne reconnaîtra tout simplement pas bien) peut-il vraiment nuire gravement? Il s'avère que l'intérêt n'est pas tant dans la qualité de reconnaissance de l'algorithme obtenu, mais dans la qualité du système résultant dans son ensemble.
À titre d'exemple simple et direct, imaginons à quel point un système d'exploitation peut être mauvais. En effet, pas du tout par l'interface utilisateur à l'ancienne, mais par le fait qu'elle n'offre pas le niveau de sécurité adéquat, elle ne protège pas du tout les attaques externes des pirates.
Des considérations similaires sont valables pour les systèmes d'intelligence artificielle. Aujourd'hui, parlons des attaques sur les réseaux de neurones qui conduisent à de graves dysfonctionnements du système cible.
Empoisonnement des données
La première et la plus dangereuse attaque est l'empoisonnement des données. Dans cette attaque, l'erreur est intégrée au stade de la formation et les attaquants savent à l'avance comment tromper le réseau. Si nous faisons une analogie avec une personne, imaginez que vous apprenez une langue étrangère et que vous apprenez certains mots de manière incorrecte, par exemple, vous pensez que le cheval est synonyme de maison. Dans la plupart des cas, vous pourrez parler calmement, mais dans de rares cas, vous ferez des erreurs graves. Une astuce similaire peut être réalisée avec les réseaux de neurones. Par exemple, dans [1], le réseau est amené à reconnaître les panneaux de signalisation. Lors de la formation du réseau, ils affichent des panneaux d'arrêt et disent qu'il s'agit vraiment de panneaux d'arrêt, de limitation de vitesse avec l'étiquette correcte, ainsi que de panneaux d'arrêt avec un autocollant et une étiquette de limitation de vitesse collée dessus.Le réseau fini avec une grande précision reconnaît les signes sur l'échantillon de test, mais en fait, une bombe y est placée. Si un tel réseau est utilisé dans un vrai système de pilote automatique, quand il voit un panneau d'arrêt avec un autocollant, il le prendra pour la limite de vitesse et continuera à conduire.
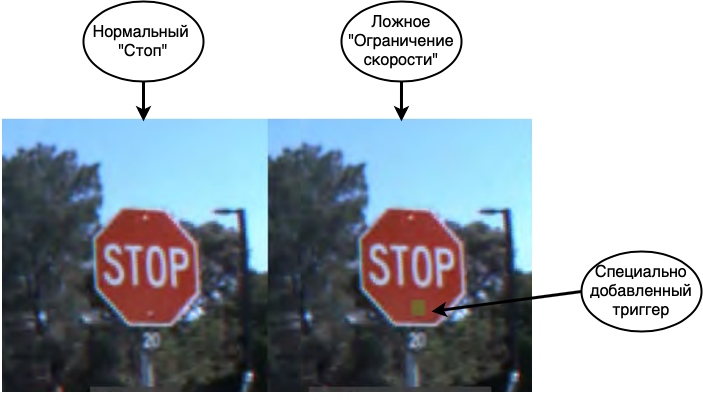
Comme vous pouvez le voir, l'empoisonnement des données est un type d'attaque extrêmement dangereux, dont l'utilisation, entre autres, est sérieusement limitée par une caractéristique importante: un accès direct aux données est nécessaire. Si nous excluons les cas d'espionnage d'entreprise et de corruption de données par les employés, les scénarios suivants subsistent lorsque cela peut se produire:
- Corruption de données sur les plateformes de crowdsourcing. , ( ?...), , - , . , , . , «» . , . (, ). , , , , «» . .
- . , – . « » - . , . , , [1].
- Corruption des données lors de la formation dans le cloud. Les architectures de réseaux neuronaux lourds populaires sont presque impossibles à entraîner sur un ordinateur ordinaire. À la recherche de résultats, de nombreux développeurs commencent à enseigner leurs modèles dans le cloud. Avec une telle formation, les attaquants peuvent accéder aux données de formation et les gâcher à l'insu du développeur.
Attaque d'évasion
Le prochain type d'attaque que nous examinerons est les attaques d'évasion. De telles attaques se produisent au stade de l'utilisation des réseaux de neurones. Dans le même temps, l'objectif reste le même: faire en sorte que le réseau donne des réponses incorrectes dans certaines situations.
Initialement, l'erreur d'évasion signifiait des erreurs de type II, mais maintenant c'est le nom de toutes les déceptions d'un réseau opérationnel [8]. En fait, l'attaquant tente de créer une illusion d'optique (auditive, sémantique) sur le réseau. Il faut comprendre que la perception d'une image (son, signification) par le réseau est significativement différente de sa perception par une personne, par conséquent, vous pouvez souvent voir des exemples où deux images très similaires - indiscernables pour une personne - sont reconnues différemment. Les premiers exemples de ce type ont été montrés dans [4], et dans [5] un exemple populaire avec un panda est apparu (voir l'illustration du titre de cet article).
En règle générale, des exemples contradictoires sont utilisés pour les attaques d'évasion. Ces exemples ont quelques propriétés qui compromettent de nombreux systèmes:
- , , [4]. « », [7]. « » , . , , . , [14], « » .

- Les exemples contradictoires se retrouvent parfaitement dans le monde physique. Tout d'abord, vous pouvez sélectionner avec soin des exemples qui ne sont pas correctement reconnus en fonction des caractéristiques de l'objet connues d'une personne. Par exemple, dans [6], les auteurs photographient une machine à laver sous différents angles et obtiennent parfois la réponse «sans danger» ou «haut-parleurs audio». Deuxièmement, les exemples contradictoires peuvent être tirés d'une figure vers le monde physique. Dans [6], ils ont montré comment, après avoir réussi à tromper le réseau de neurones en modifiant l'image numérique (une astuce similaire au panda montré ci-dessus), on peut «traduire» l'image numérique résultante en forme matérielle par une simple impression et continuer à tromper le réseau déjà dans le monde physique.
Les attaques par évasion peuvent être divisées en différents groupes: selon la réponse souhaitée, selon la disponibilité du modèle, et selon la méthode de sélection des interférences:
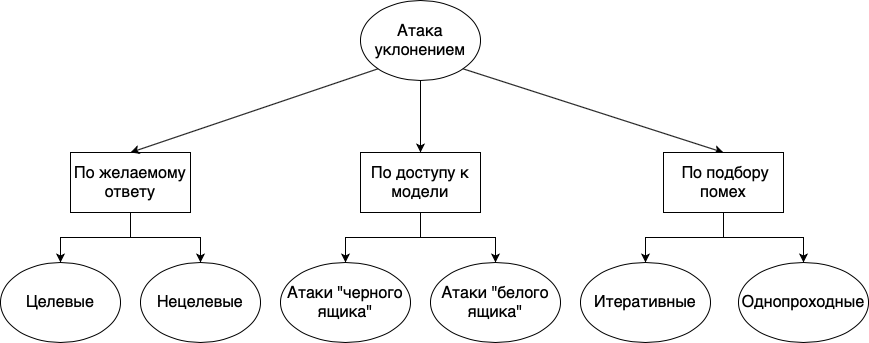
- . , , . , . , «», «», «», , , , . . , , , , .
- . , , , , . , , - , . , , . « », , , . . « » , , . , , . , , . , , , , .
- . , . , , , . : . , . . , , . « ».
Bien sûr, ce ne sont pas seulement les réseaux qui classifient les animaux et les objets qui sont soumis aux attaques d'évasion. La figure suivante, tirée d'un article de 2020 présenté à la conférence IEEE / CVF sur la vision par ordinateur et la reconnaissance de formes [12], montre à quel point on peut usurper des réseaux récurrents pour l'OCR:
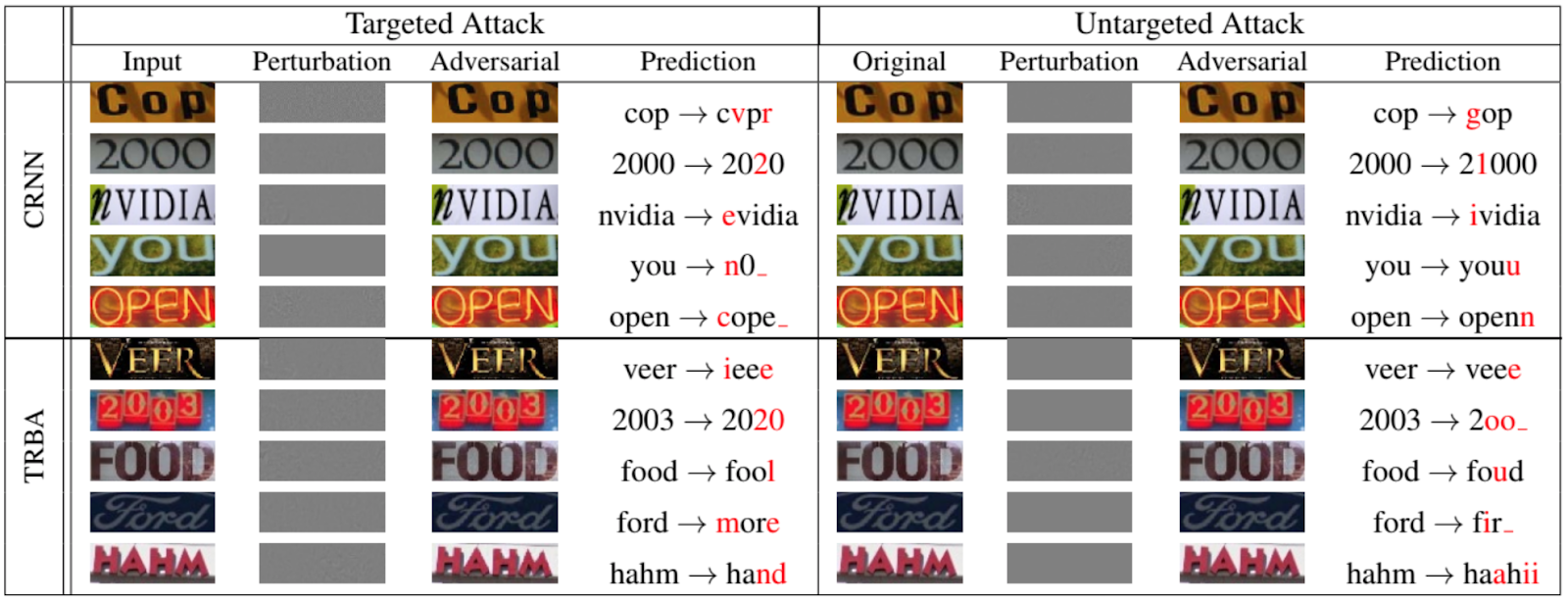
Maintenant à propos d'autres attaques sur le réseau
Au cours de notre histoire, nous avons mentionné plusieurs fois l'échantillon d'entraînement, montrant que parfois c'est lui, et non le modèle entraîné, qui est la cible des attaquants.
La plupart des études montrent que les modèles de reconnaissance sont mieux enseignés sur des données réelles et représentatives, ce qui signifie que les modèles contiennent souvent de nombreuses informations précieuses. Il est peu probable que quiconque s'intéresse à voler des photos de chats. Mais les algorithmes de reconnaissance sont également utilisés à des fins médicales, des systèmes de traitement d'informations personnelles et biométriques, etc., où les exemples de «formation» (sous forme d'informations personnelles ou biométriques en direct) sont d'une grande valeur.
Considérons donc deux types d'attaques: une attaque sur l'établissement de la propriété et une attaque par inversion du modèle.
Attaque d'affiliation
Dans cette attaque, l'attaquant tente de déterminer si des données spécifiques ont été utilisées pour entraîner le modèle. Bien qu'à première vue, il semble qu'il n'y ait rien de mal à cela, comme nous l'avons dit ci-dessus, il y a plusieurs violations de la vie privée.
Tout d'abord, sachant que certaines des données sur une personne ont été utilisées dans la formation, vous pouvez essayer (et parfois même avec succès) d'extraire d'autres données sur une personne du modèle. Par exemple, si vous disposez d'un système de reconnaissance faciale qui stocke également les données personnelles d'une personne, vous pouvez essayer de reproduire sa photo par son nom.
Deuxièmement, la divulgation directe de secrets médicaux est possible. Par exemple, si vous avez un modèle qui suit les déplacements des personnes atteintes de la maladie d'Alzheimer et que vous savez que des données sur une personne en particulier ont été utilisées à l'entraînement, vous savez déjà que cette personne est malade [9].
Attaque d'inversion de modèle
L'inversion de modèle fait référence à la capacité d'obtenir des données d'entraînement à partir d'un modèle entraîné. Dans le traitement du langage naturel, et plus récemment dans la reconnaissance d'images, des réseaux de traitement de séquence sont souvent utilisés. Tout le monde a sûrement rencontré la saisie semi-automatique dans Google ou Yandex lors de la saisie d'une requête de recherche. La suite des phrases dans de tels systèmes est construite sur la base de l'échantillon d'apprentissage disponible. En conséquence, s'il y avait des données personnelles dans l'ensemble d'apprentissage, elles peuvent soudainement apparaître dans la saisie semi-automatique [10, 11].
Au lieu d'une conclusion
Chaque jour, des systèmes d'intelligence artificielle de différentes échelles «s'installent» de plus en plus dans notre vie quotidienne. Sous les belles promesses d'automatisation des processus de routine, d'augmentation de la sécurité générale et d'un autre avenir radieux, nous donnons aux systèmes d'intelligence artificielle divers domaines de la vie humaine les uns après les autres: saisie de texte dans les années 90, systèmes d'assistance à la conduite dans les années 2000, traitement biométrique en 2010- x, etc. Jusqu'à présent, dans tous ces domaines, les systèmes d'intelligence artificielle n'ont reçu que le rôle d'assistant, mais en raison de certaines particularités de la nature humaine (tout d'abord, paresse et irresponsabilité), l'esprit informatique joue souvent le rôle de commandant, entraînant parfois des conséquences irréversibles.
Tout le monde a entendu des histoires sur le crash des pilotes automatiques, les systèmes d'intelligence artificielle du secteur bancaire se trompent , des problèmes de traitement biométrique se posent . Plus récemment, en raison d'une erreur dans le système de reconnaissance faciale, un Russe a été presque emprisonné pendant 8 ans .
Jusqu'à présent, ce sont toutes des fleurs présentées par des cas isolés.
Les baies sont en avance. Nous. Bientôt.
Bibliographie
[1] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, «BadNets: Evaluating backdooring attacks on deep neural networks», 2019, IEEE Access.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.