introduction
La technologie d'apprentissage automatique a évolué à un rythme incroyable au cours de l'année écoulée. De plus en plus d'entreprises partagent leurs bonnes pratiques, ouvrant ainsi de nouvelles possibilités de création d'assistants numériques intelligents.
Dans le cadre de cet article, je souhaite partager mon expérience dans la mise en œuvre d'un assistant vocal et vous proposer quelques idées pour le rendre encore plus intelligent et plus utile.

Que peut faire mon assistant vocal?
| Description de la compétence | Travail hors ligne | Dépendances requises |
| Reconnaître et synthétiser la parole | Prise en charge | pip install PyAudio (utiliser le microphone)
pip install pyttsx3 (synthèse vocale) Vous pouvez en choisir un ou les deux pour la reconnaissance vocale:
|
| pip install pyowm (OpenWeatherMap) | ||
| Google ( ) | pip install google | |
| YouTube | - | |
| Wikipedia c | pip install wikipedia-api | |
| pip install googletrans (Google Translate) | ||
| - | ||
| « » | - | |
| ( ) | - | |
| - | ||
| TODO ... | ||
1.
Commençons par apprendre à gérer la saisie vocale. Nous avons besoin d'un microphone et de quelques bibliothèques installées: PyAudio et SpeechRecognition.
Préparons les outils de base pour la reconnaissance vocale:
import speech_recognition
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
voice_input = record_and_recognize_audio()
print(voice_input)
Créons maintenant une fonction pour enregistrer et reconnaître la parole. Pour la reconnaissance en ligne, nous avons besoin de Google, car il offre une qualité de reconnaissance élevée dans un grand nombre de langues.
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
except speech_recognition.RequestError:
print("Check your Internet Connection, please")
return recognized_data
Et s'il n'y a pas d'accès Internet? Vous pouvez utiliser des solutions pour la reconnaissance hors ligne. J'ai personnellement beaucoup aimé le projet Vosk .
En fait, vous n'avez pas besoin d'implémenter l'option hors ligne si vous n'en avez pas besoin. Je voulais juste montrer les deux méthodes dans le cadre de l'article, et vous choisissez déjà en fonction de la configuration système requise (par exemple, Google est sans aucun doute le leader en nombre de langues de reconnaissance disponibles).Maintenant, après avoir implémenté une solution hors ligne et ajouté les modèles de langue nécessaires au projet, s'il n'y a pas d'accès au réseau, nous passerons automatiquement à la reconnaissance hors ligne.
Notez que pour ne pas avoir à répéter deux fois la même phrase, j'ai décidé d'enregistrer l'audio du microphone dans un fichier wav temporaire qui sera supprimé après chaque reconnaissance.
Ainsi, le code résultant ressemble à ceci:
Code complet pour que la reconnaissance vocale fonctionne
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import wave # wav
import json # json- json-
import os #
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
Vous vous demandez peut-être "Pourquoi prendre en charge les fonctionnalités hors ligne?"
À mon avis, il vaut toujours la peine de considérer que l'utilisateur peut être coupé du réseau. Dans ce cas, l'assistant vocal peut toujours être utile si vous l'utilisez comme robot conversationnel ou pour résoudre un certain nombre de tâches simples, par exemple compter quelque chose, recommander un film, aider à choisir une cuisine, jouer à un jeu, etc.
Étape 2. Configuration de l'assistant vocal
Étant donné que notre assistant vocal peut avoir un sexe, une langue de parole et, selon les classiques, un nom, allouons une classe distincte pour ces données, avec laquelle nous travaillerons à l'avenir.
Afin de définir une voix pour notre assistant, nous utiliserons la bibliothèque de synthèse vocale hors ligne pyttsx3. Il trouvera automatiquement les voix disponibles pour la synthèse sur notre ordinateur en fonction des paramètres du système d'exploitation (par conséquent, il est possible que vous ayez d'autres voix disponibles et que vous ayez besoin d'index différents).
Nous ajouterons également à la fonction principale l'initialisation de la synthèse vocale et une fonction séparée pour la jouer. Pour vous assurer que tout fonctionne, vérifions un petit peu que l'utilisateur nous a bien accueillis et donnons-lui un retour de salutation de l'assistant:
Code complet pour le framework d'assistant vocal (synthèse et reconnaissance vocales)
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import pyttsx3 # (Text-To-Speech)
import wave # wav
import json # json- json-
import os #
class VoiceAssistant:
"""
, , ,
"""
name = ""
sex = ""
speech_language = ""
recognition_language = ""
def setup_assistant_voice():
"""
(
)
"""
voices = ttsEngine.getProperty("voices")
if assistant.speech_language == "en":
assistant.recognition_language = "en-US"
if assistant.sex == "female":
# Microsoft Zira Desktop - English (United States)
ttsEngine.setProperty("voice", voices[1].id)
else:
# Microsoft David Desktop - English (United States)
ttsEngine.setProperty("voice", voices[2].id)
else:
assistant.recognition_language = "ru-RU"
# Microsoft Irina Desktop - Russian
ttsEngine.setProperty("voice", voices[0].id)
def play_voice_assistant_speech(text_to_speech):
"""
( )
:param text_to_speech: ,
"""
ttsEngine.say(str(text_to_speech))
ttsEngine.runAndWait()
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
# ( )
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
#
ttsEngine = pyttsx3.init()
#
assistant = VoiceAssistant()
assistant.name = "Alice"
assistant.sex = "female"
assistant.speech_language = "ru"
#
setup_assistant_voice()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
if command == "":
play_voice_assistant_speech("")
En fait, j'aimerais ici apprendre à écrire moi-même un synthétiseur vocal, mais mes connaissances ici ne seront pas suffisantes. Si vous pouvez suggérer une bonne littérature, un cours ou une solution documentée intéressante qui vous aidera à comprendre ce sujet en profondeur, veuillez écrire dans les commentaires.
Étape 3. Traitement des commandes
Maintenant que nous avons "appris" à reconnaître et à synthétiser la parole à l'aide des développements simplement divins de nos collègues, nous pouvons commencer à réinventer notre roue de traitement des commandes vocales de l'utilisateur: D
Dans mon cas, j'utilise des options multilingues pour stocker les commandes, car je n'en ai pas autant événements, et je suis satisfait de l'exactitude de la définition d'une commande particulière. Cependant, pour les grands projets, je recommande de fractionner les configurations par langue.
Je peux proposer deux façons de stocker des commandes.
1 voie
Vous pouvez utiliser un excellent objet de type JSON dans lequel stocker les intentions, les scénarios de développement, les réponses en cas d'échec des tentatives (ceux-ci sont souvent utilisés pour les robots de discussion). Cela ressemble à quelque chose comme ceci:
config = {
"intents": {
"greeting": {
"examples": ["", "", " ",
"hello", "good morning"],
"responses": play_greetings
},
"farewell": {
"examples": ["", " ", "", " ",
"goodbye", "bye", "see you soon"],
"responses": play_farewell_and_quit
},
"google_search": {
"examples": [" ",
"search on google", "google", "find on google"],
"responses": search_for_term_on_google
},
},
"failure_phrases": play_failure_phrase
}
Cette option convient à ceux qui souhaitent former un assistant à répondre à des phrases difficiles. De plus, vous pouvez ici appliquer l'approche NLU et créer la possibilité de prédire l'intention de l'utilisateur en les comparant à celles déjà dans la configuration.
Nous examinerons cette méthode en détail à l'étape 5 de cet article. En attendant, j'attirerai votre attention sur une option plus simple.
2 voies
Vous pouvez prendre un dictionnaire simplifié, qui aura un tuple de type hachable comme clés (puisque les dictionnaires utilisent des hachages pour stocker et récupérer rapidement des éléments), et les noms des fonctions qui seront exécutées seront sous forme de valeurs. Pour les commandes courtes, l'option suivante convient:
commands = {
("hello", "hi", "morning", ""): play_greetings,
("bye", "goodbye", "quit", "exit", "stop", ""): play_farewell_and_quit,
("search", "google", "find", ""): search_for_term_on_google,
("video", "youtube", "watch", ""): search_for_video_on_youtube,
("wikipedia", "definition", "about", "", ""): search_for_definition_on_wikipedia,
("translate", "interpretation", "translation", "", "", ""): get_translation,
("language", ""): change_language,
("weather", "forecast", "", ""): get_weather_forecast,
}
Pour le traiter, nous devons ajouter le code comme suit:
def execute_command_with_name(command_name: str, *args: list):
"""
:param command_name:
:param args: ,
:return:
"""
for key in commands.keys():
if command_name in key:
commands[key](*args)
else:
pass # print("Command not found")
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
command_options = [str(input_part) for input_part in voice_input[1:len(voice_input)]]
execute_command_with_name(command, command_options)
Des arguments supplémentaires seront transmis à la fonction après le mot de commande. Autrement dit, si vous dites l'expression "les vidéos sont des chats mignons ", la commande " vidéo " appellera la fonction search_for_video_on_youtube () avec l'argument " chats mignons " et donnera le résultat suivant:
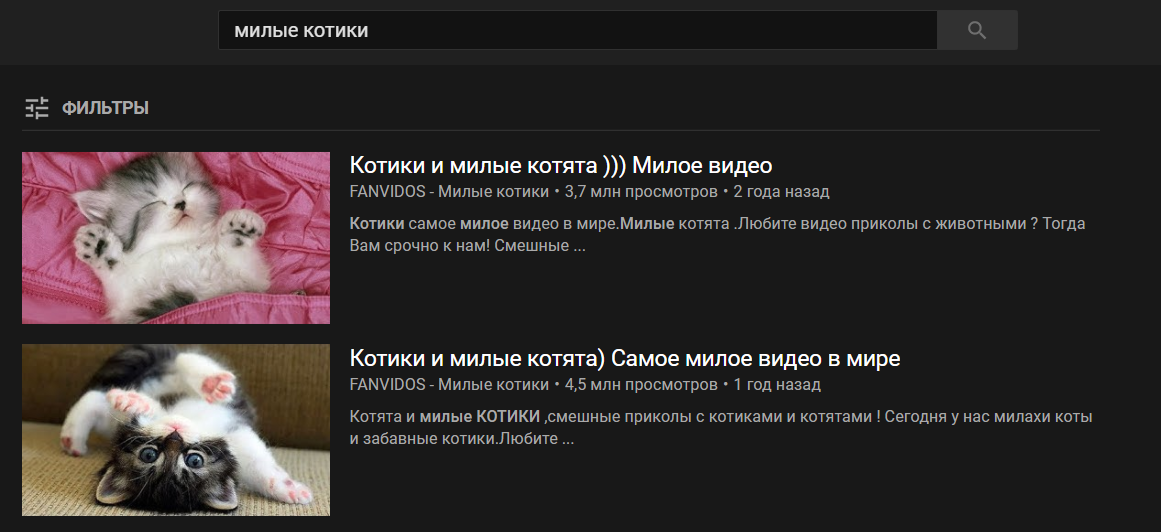
Un exemple d'une telle fonction avec traitement des arguments entrants:
def search_for_video_on_youtube(*args: tuple):
"""
YouTube
:param args:
"""
if not args[0]: return
search_term = " ".join(args[0])
url = "https://www.youtube.com/results?search_query=" + search_term
webbrowser.get().open(url)
#
# , JSON-
play_voice_assistant_speech("Here is what I found for " + search_term + "on youtube")
C'est ça! La fonctionnalité principale du bot est prête. Ensuite, vous pouvez l'améliorer à l'infini de différentes manières. Mon implémentation avec des commentaires détaillés est disponible sur mon GitHub .
Ci-dessous, nous examinerons un certain nombre d'améliorations pour rendre notre assistant encore plus intelligent.
Étape 4. Ajout du multilinguisme
Pour apprendre à notre assistant à travailler avec plusieurs modèles de langage, il sera plus pratique d'organiser un petit fichier JSON avec une structure simple:
{
"Can you check if your microphone is on, please?": {
"ru": ", , ",
"en": "Can you check if your microphone is on, please?"
},
"What did you say again?": {
"ru": ", ",
"en": "What did you say again?"
},
}
Dans mon cas, j'utilise la commutation entre le russe et l'anglais, car des modèles de reconnaissance vocale et de synthèse vocale sont à ma disposition pour cela. La langue sera sélectionnée en fonction de la langue de la parole de l'assistant vocal lui-même.
Afin de recevoir la traduction, nous pouvons créer une classe séparée avec une méthode qui nous renverra une chaîne avec la traduction:
class Translation:
"""
"""
with open("translations.json", "r", encoding="UTF-8") as file:
translations = json.load(file)
def get(self, text: str):
"""
( )
:param text: ,
:return:
"""
if text in self.translations:
return self.translations[text][assistant.speech_language]
else:
#
#
print(colored("Not translated phrase: {}".format(text), "red"))
return text
Dans la fonction principale, avant la boucle, nous allons déclarer notre traducteur comme suit: Translator = Translation ()
Maintenant, lors de la lecture du discours de l'assistant, nous pouvons obtenir la traduction comme suit:
play_voice_assistant_speech(translator.get(
"Here is what I found for {} on Wikipedia").format(search_term))
Comme vous pouvez le voir dans l'exemple ci-dessus, cela fonctionne même pour les lignes qui nécessitent l'insertion d'arguments supplémentaires. Ainsi, vous pouvez traduire les ensembles de phrases «standard» pour vos assistants.
Étape 5. Un peu d'apprentissage automatique
Revenons maintenant à l'objet JSON pour stocker des commandes multi-mots, ce qui est typique pour la plupart des chatbots, que j'ai mentionné au paragraphe 3. Il convient à ceux qui ne veulent pas utiliser de commandes strictes et prévoient d'élargir leur compréhension de l'intention de l'utilisateur en utilisant NLU -méthodes.
En gros, dans ce cas, les expressions « bon après-midi », « bonsoir » et « bonjour » seront considérées comme équivalentes. L'assistant comprendra que dans les trois cas, l'intention de l'utilisateur était de saluer son assistant vocal.
En utilisant cette méthode, vous pouvez également créer un bot conversationnel pour les chats ou un mode conversationnel pour votre assistant vocal (pour les cas où vous avez besoin d'un interlocuteur).
Pour implémenter cette fonctionnalité, nous devrons ajouter quelques fonctions:
def prepare_corpus():
"""
"""
corpus = []
target_vector = []
for intent_name, intent_data in config["intents"].items():
for example in intent_data["examples"]:
corpus.append(example)
target_vector.append(intent_name)
training_vector = vectorizer.fit_transform(corpus)
classifier_probability.fit(training_vector, target_vector)
classifier.fit(training_vector, target_vector)
def get_intent(request):
"""
:param request:
:return:
"""
best_intent = classifier.predict(vectorizer.transform([request]))[0]
index_of_best_intent = list(classifier_probability.classes_).index(best_intent)
probabilities = classifier_probability.predict_proba(vectorizer.transform([request]))[0]
best_intent_probability = probabilities[index_of_best_intent]
#
if best_intent_probability > 0.57:
return best_intent
Et aussi modifiez légèrement la fonction principale en ajoutant l'initialisation des variables pour préparer le modèle et en changeant la boucle vers la version correspondant à la nouvelle configuration:
#
# ( )
vectorizer = TfidfVectorizer(analyzer="char", ngram_range=(2, 3))
classifier_probability = LogisticRegression()
classifier = LinearSVC()
prepare_corpus()
while True:
#
#
voice_input = record_and_recognize_audio()
if os.path.exists("microphone-results.wav"):
os.remove("microphone-results.wav")
print(colored(voice_input, "blue"))
# ()
if voice_input:
voice_input_parts = voice_input.split(" ")
# -
#
if len(voice_input_parts) == 1:
intent = get_intent(voice_input)
if intent:
config["intents"][intent]["responses"]()
else:
config["failure_phrases"]()
# -
# ,
#
if len(voice_input_parts) > 1:
for guess in range(len(voice_input_parts)):
intent = get_intent((" ".join(voice_input_parts[0:guess])).strip())
if intent:
command_options = [voice_input_parts[guess:len(voice_input_parts)]]
config["intents"][intent]["responses"](*command_options)
break
if not intent and guess == len(voice_input_parts)-1:
config["failure_phrases"]()
Cependant, cette méthode est plus difficile à contrôler: elle nécessite une vérification constante que telle ou telle phrase est toujours correctement identifiée par le système comme faisant partie d'une intention particulière. Par conséquent, cette méthode doit être utilisée avec précaution (ou expérimenter avec le modèle lui-même).
Conclusion
Ceci conclut mon petit tutoriel.
Je serai ravi si vous partagez avec moi dans les commentaires des solutions open-source que vous connaissez qui peuvent être implémentées dans ce projet, ainsi que vos idées sur les autres fonctions en ligne et hors ligne qui peuvent être implémentées.
Les sources documentées de mon assistant vocal en deux versions peuvent être trouvées ici .
PS: La solution fonctionne sur Windows, Linux et MacOS avec des différences mineures lors de l'installation des bibliothèques PyAudio et Google.