LightGBM étend l'algorithme de renforcement des dégradés en ajoutant un type de sélection automatique d'objet et en se concentrant sur des exemples de renforcement avec de grands dégradés. Cela peut conduire à une accélération spectaculaire de l'apprentissage et à de meilleures performances prédictives. Ainsi, LightGBM est devenu l'algorithme de facto pour les compétitions d'apprentissage automatique lorsqu'il travaille avec des données tabulaires pour des problèmes de modélisation prédictive de régression et de classification. Ce didacticiel vous montrera comment concevoir des ensembles de machines Light Gradient Boosted pour la classification et la régression. Après avoir terminé ce tutoriel, vous saurez:
- La LightGBM (Light Gradient Boosted Machine) est une implémentation open source efficace de l'ensemble de renforcement de gradient stochastique.
- Comment développer des ensembles LightGBM pour la classification et la régression à l'aide de l'API scikit-learn.
- LightGBM .

- LightBLM.
- Scikit-Learn API LightGBM.
— LightGBM .
— LightGBM . - LightGBM.
— .
— .
— .
— .
LightBLM
L'amplification de gradient appartient à une classe d'algorithmes d'apprentissage automatique d'ensemble qui peuvent être utilisés pour des problèmes de classification ou pour la modélisation de régression prédictive.
Les ensembles sont construits sur la base de modèles d'arbre de décision. Les arbres sont ajoutés un par un à l'ensemble et entraînés pour corriger les erreurs de prédiction faites par les modèles précédents. Il s'agit d'un type de modèle d'apprentissage automatique d'ensemble appelé boosting.
Les modèles sont entraînés en utilisant n'importe quelle fonction de perte différentiable arbitraire et un algorithme d'optimisation de descente de gradient. Cela donne à la méthode son nom de «renforcement de gradient» car le gradient de perte est minimisé lorsque le modèle est entraîné, comme un réseau de neurones. Pour plus d'informations sur l'amplification du dégradé, consultez le didacticiel:"Une introduction en douceur à l'algorithme d'amplification de gradient ML . "
LightGBM est une implémentation open source d'amplification de gradient conçue pour être efficace, voire peut-être plus efficace que d'autres implémentations.
En tant que tel, LightGBM est un projet open source, une bibliothèque de logiciels et un algorithme d'apprentissage automatique. Autrement dit, le projet est très similaire à la technique Extreme Gradient Boosting ou XGBoost .
Le LightGBM a été décrit par Golin, K., et al. Pour plus d'informations, consultez un article de 2017 intitulé «LightGBM: un arbre décisionnel de renforcement de gradient hautement efficace» . La mise en œuvre introduit deux idées clés: GOSS et EFB.
Gradient One-Way Sampling (GOSS) est une modification de Gradient Boosting qui se concentre sur les didacticiels qui entraînent un gradient plus important, ce qui accélère l'apprentissage et réduit la complexité de calcul de la méthode.
Avec GOSS, nous excluons une partie importante des instances de données avec de petits gradients et n'utilisons que le reste des instances de données pour estimer le gain d'information. Nous soutenons que, étant donné que les instances de données avec de grands gradients jouent un rôle plus important dans le calcul du gain d'informations, GOSS peut obtenir une estimation assez précise du gain d'informations avec une taille de données beaucoup plus petite.
Le regroupement exclusif de fonctionnalités, ou EFB, est une approche consistant à combiner des fonctionnalités mutuellement exclusives (généralement nulles), telles que des variables d'entrée catégorielles codées avec un codage unitaire. Il s'agit donc d'un type de sélection automatique de fonctionnalités.
... nous empaquetons des fonctionnalités mutuellement exclusives (c'est-à-dire qu'elles prennent rarement des valeurs non nulles en même temps) pour réduire le nombre de fonctionnalités.
Ensemble, ces deux changements peuvent accélérer le temps d'apprentissage de l'algorithme jusqu'à 20 fois. Ainsi, LightGBM peut être considéré comme des arbres de décision à gradient boosté (GBDT) avec l'ajout de GOSS et EFB.
Nous appelons notre nouvelle implémentation GBDT GOSS et EFB LightGBM. Nos expériences sur plusieurs ensembles de données accessibles au public montrent que LightGBM accélère le processus d'apprentissage d'un GBDT conventionnel de plus de 20 fois, atteignant presque la même précision.
API Scikit-Learn pour LightGBM
LightGBM peut être installé en tant que bibliothèque autonome et le modèle LightGBM peut être développé à l'aide de l'API scikit-learn.
La première étape consiste à installer la bibliothèque LightGBM. Sur la plupart des plates-formes, cela peut être fait en utilisant le gestionnaire de packages pip; par exemple:
sudo pip install lightgbmVous pouvez vérifier l'installation et la version comme ceci:
# check lightgbm version
import lightgbm
print(lightgbm.__version__)Le script affichera la version de LightGBM installé. Votre version doit être identique ou supérieure. Sinon, mettez à jour LightGBM. Si vous avez besoin d'instructions spécifiques pour votre environnement de développement, reportez-vous au didacticiel: Guide d'installation de LightGBM .
La bibliothèque LightGBM a sa propre API, bien que nous utilisions une méthode via les classes wrapper scikit-learn: LGBMRegressor et LGBMClassifier . Cela vous permettra d'appliquer l'ensemble des outils de la bibliothèque d'apprentissage automatique scikit-learn pour la préparation des données et l'évaluation des modèles.
Les deux modèles fonctionnent de la même manière et utilisent les mêmes arguments pour influencer la manière dont les arbres de décision sont créés et ajoutés à l'ensemble. Le modèle utilise l'aléatoire. Cela signifie que chaque fois que l'algorithme s'exécute sur les mêmes données, il crée un modèle légèrement différent.
Lors de l'utilisation d'algorithmes d'apprentissage automatique avec un algorithme d'apprentissage stochastique, il est recommandé de les évaluer en faisant la moyenne de leurs performances sur plusieurs exécutions ou répétitions de validation croisée. Lors de l'ajustement du modèle final, il peut être souhaitable soit d'augmenter le nombre d'arbres jusqu'à ce que la variance du modèle diminue avec des estimations répétées, soit d'entraîner plusieurs modèles finaux et de faire la moyenne de leurs prédictions. Jetons un coup d'œil à la conception d'un ensemble LightGBM pour la classification et la régression.
Ensemble LightGBM pour la classification
Dans cette section, nous examinerons l'utilisation de LightGBM pour une tâche de classification. Tout d'abord, nous pouvons utiliser la fonction make_classification () pour créer un problème de classification binaire synthétique avec 1000 exemples et 20 fonctionnalités d'entrée. Voir l'exemple complet ci-dessous.
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the datasetL'exécution de l'exemple crée un ensemble de données et résume la forme des composants d'entrée et de sortie.
(1000, 20) (1000,)Nous pouvons ensuite évaluer l'algorithme LightGBM sur cet ensemble de données. Nous évaluerons le modèle en utilisant une validation croisée stratifiée répétée de k fois avec trois répétitions et k égal à 10. Nous rapporterons la moyenne et l'écart type de la précision du modèle sur toutes les répétitions et tous les plis.
# evaluate lightgbm algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))L'exécution de l'exemple montre la précision de la moyenne et de l'écart type du modèle.
Remarque : vos résultats peuvent différer en raison de la nature stochastique de l'algorithme ou de la procédure d'estimation, ou des différences de précision numérique. Essayez plusieurs fois l'exemple et comparez le résultat moyen.
Dans ce cas, nous pouvons voir que l'ensemble LightGBM avec des hyperparamètres par défaut atteint une précision de classification d'environ 92,5% sur cet ensemble de données de test.
Accuracy: 0.925 (0.031)Nous pouvons également utiliser le modèle LightGBM comme modèle final et faire des prédictions pour la classification. Tout d'abord, l'ensemble LightGBM s'adapte à toutes les données disponibles, et deuxièmement, vous pouvez appeler la fonction prédire () pour faire des prédictions sur les nouvelles données. L'exemple ci-dessous le démontre sur notre jeu de données de classification binaire.
# make predictions using lightgbm for classification
from sklearn.datasets import make_classification
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]
yhat = model.predict([row])
print('Predicted Class: %d' % yhat[0])L'exécution de l'exemple entraîne le modèle d'ensemble LightGBM pour l'ensemble de données, puis l'utilise pour prédire une nouvelle ligne de données, comme si le modèle était utilisé dans une application.
Predicted Class: 1Maintenant que nous sommes familiarisés avec l'utilisation de LightGBM pour la classification, jetons un coup d'œil à l'API de régression.
Ensemble LightGBM pour la régression
Dans cette section, nous examinerons l'utilisation de LightGBM pour un problème de régression. Tout d'abord, nous pouvons utiliser la fonction make_regression ()
pour créer un problème de régression synthétique avec 1000 exemples et 20 fonctionnalités d'entrée. Voir l'exemple complet ci-dessous.
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# summarize the dataset
print(X.shape, y.shape)L'exécution de l'exemple crée un ensemble de données et récapitule les composants d'entrée et de sortie.
(1000, 20) (1000,)Deuxièmement, nous pouvons évaluer l'algorithme LightGBM sur cet ensemble de données.
Comme dans la dernière section, nous évaluerons le modèle par une validation croisée répétée de k fois avec trois répliques et k égal à 10. Nous rapporterons l'erreur absolue moyenne (MAE) du modèle pour tous les réplicats et groupes de validation croisée. La bibliothèque scikit-learn rend le MAE négatif de sorte qu'il soit maximisé plutôt que minimisé. Cela signifie que les grands MAE négatifs sont meilleurs et que le modèle idéal a un MAE de 0. Un exemple complet est présenté ci-dessous.
# evaluate lightgbm ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))L'exécution de l'exemple indique la moyenne et l'écart type du modèle.
Remarque : vos résultats peuvent varier en raison de la nature stochastique de l'algorithme ou de la procédure d'estimation, ou des différences de précision numérique. Envisagez d'exécuter l'exemple plusieurs fois et de comparer la moyenne. Dans ce cas, nous voyons que l'ensemble LightGBM avec des hyperparamètres par défaut atteint un MAE d'environ 60.
MAE: -60.004 (2.887)Nous pouvons également utiliser le modèle LightGBM comme modèle final et faire des prédictions pour la régression. Tout d'abord, l'ensemble LightGBM est formé sur toutes les données disponibles, puis predict () peut être appelé pour prédire de nouvelles données. L'exemple ci-dessous le démontre sur notre jeu de données de régression.
# gradient lightgbm for making predictions for regression
from sklearn.datasets import make_regression
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792]
yhat = model.predict([row])
print('Prediction: %d' % yhat[0]) L'exécution de l'exemple entraîne un modèle d'ensemble LightGBM sur l'ensemble de données, puis l'utilise pour prédire une nouvelle ligne de données, comme il le ferait si vous utilisiez le modèle dans une application.
Prediction: 52Maintenant que nous sommes familiarisés avec l'utilisation de l'API scikit-learn pour évaluer et appliquer les ensembles LightGBM, examinons la configuration du modèle.
Hyperparamètres LightGBM
Dans cette section, nous examinerons de plus près certains des hyperparamètres importants pour l'ensemble LightGBM et leur impact sur les performances du modèle. LightGBM a beaucoup d'hyperparamètres à regarder, ici nous regardons le nombre d'arbres et leur profondeur, le taux d'apprentissage et le type de boost. Pour obtenir des conseils généraux sur la modification des hyperparamètres LightGBM, consultez la documentation: Réglage des paramètres LightGBM .
Examiner le nombre d'arbres
Un hyperparamètre important pour l'algorithme d'ensemble LightGBM est le nombre d'arbres de décision utilisés dans l'ensemble. Rappelez-vous que les arbres de décision sont ajoutés au modèle séquentiellement dans le but de corriger et d'améliorer les prédictions faites par les arbres précédents. La règle fonctionne souvent: plus d'arbres c'est mieux. Le nombre d'arbres peut être spécifié à l'aide de l'argument n_estimators, qui vaut par défaut 100. L'exemple ci-dessous examine l'effet du nombre d'arbres, de 10 à 5000.
# explore lightgbm number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
trees = [10, 50, 100, 500, 1000, 5000]
for n in trees:
models[str(n)] = LGBMClassifier(n_estimators=n)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()L'exécution de l'exemple affiche d'abord la précision moyenne pour chaque nombre d'arbres de décision.
Remarque : vos résultats peuvent différer en raison de la nature stochastique de l'algorithme ou de la procédure d'estimation, ou des différences de précision numérique. Envisagez d'exécuter l'exemple plusieurs fois et de comparer le résultat moyen.
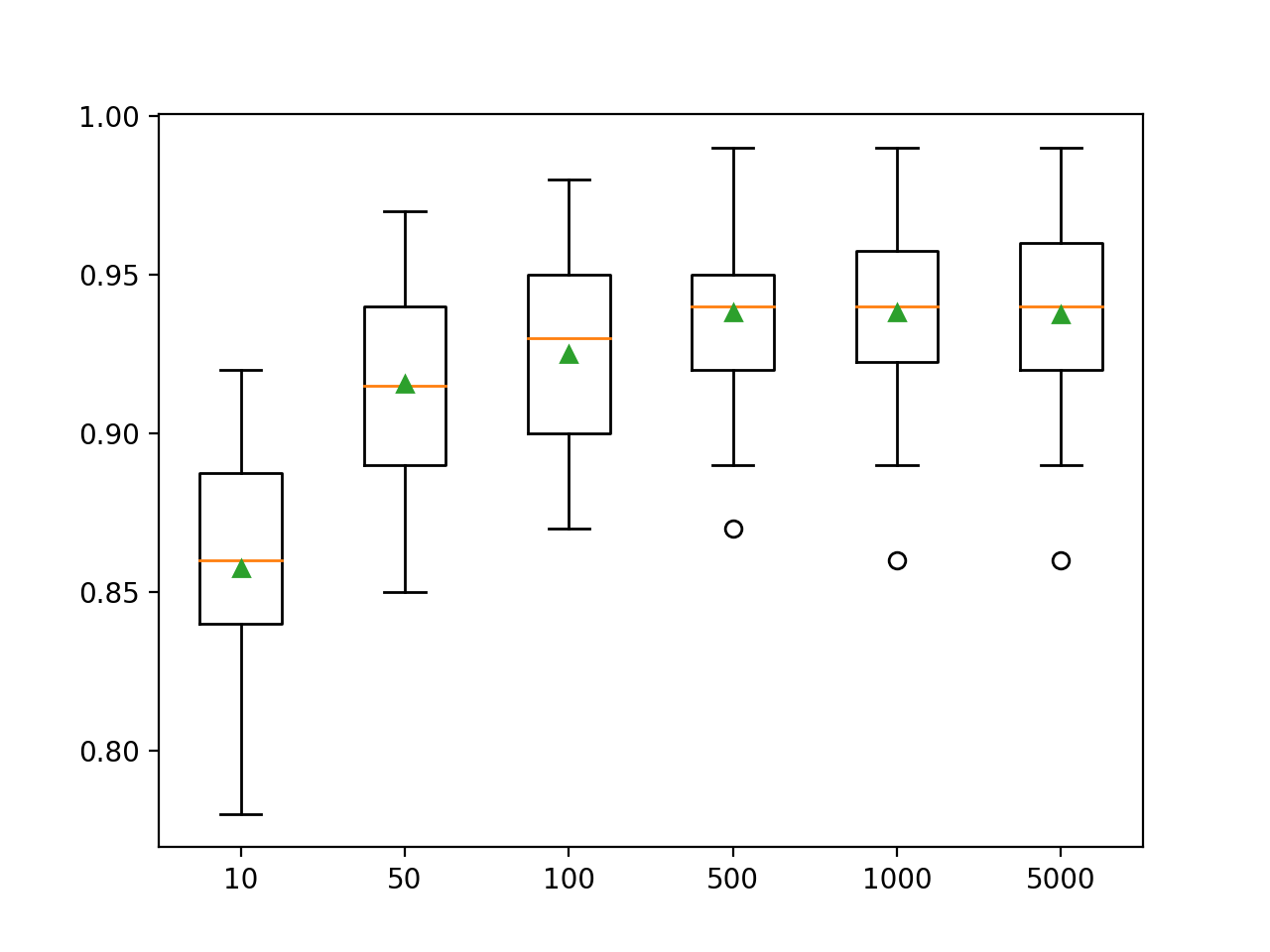
Ici, nous voyons que les performances de cet ensemble de données s'améliorent à environ 500 arbres, après quoi elles semblent se stabiliser.
>10 0.857 (0.033)
>50 0.916 (0.032)
>100 0.925 (0.031)
>500 0.938 (0.026)
>1000 0.938 (0.028)
>5000 0.937 (0.028)Un diagramme en boîtes et moustaches est créé pour distribuer les scores de précision pour chaque nombre d'arbres configuré. Il existe une tendance générale à l'augmentation des performances des modèles et de la taille de l'ensemble.
Examiner la profondeur d'un arbre
Changer la profondeur de chaque arbre ajouté à l'ensemble est un autre hyperparamètre important pour l'amplification du gradient. La profondeur de l'arborescence détermine à quel point chaque arbre se spécialise dans l'ensemble de données d'entraînement: à quel point il peut être général ou formé. Les arbres qui ne devraient pas être trop peu profonds et généraux (par exemple AdaBoost ) et pas trop profonds et spécialisés (par exemple l' agrégation bootstrap ) sont préférés .
L'amélioration du gradient fonctionne généralement bien avec les arbres de profondeur modérée, équilibrant l'entraînement et la généralité. La profondeur de l'arbre est contrôlée par l'argument max_depth, et la valeur par défaut est une valeur indéfinie, car le mécanisme par défaut pour gérer la complexité des arbres consiste à utiliser un nombre fini de nœuds.
Il existe deux manières principales de contrôler la complexité d'un arbre: à travers la profondeur maximale de l'arbre et le nombre maximal de nœuds terminaux (feuilles) de l'arbre. Nous examinons ici le nombre de feuilles, nous devons donc augmenter le nombre pour prendre en charge les arbres plus profonds en spécifiant l'argument num_leaves . Ci-dessous, nous examinons les profondeurs d'arbres de 1 à 10 et leur impact sur les performances du modèle.
# explore lightgbm tree depth effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in range(1,11):
models[str(i)] = LGBMClassifier(max_depth=i, num_leaves=2**i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()L'exécution de l'exemple affiche d'abord la précision moyenne pour chaque profondeur d'arbre ajustée.
Remarque : vos résultats peuvent différer en raison de la nature stochastique de l'algorithme ou de la procédure d'estimation, ou des différences de précision numérique. Envisagez d'exécuter l'exemple plusieurs fois et de comparer la moyenne.
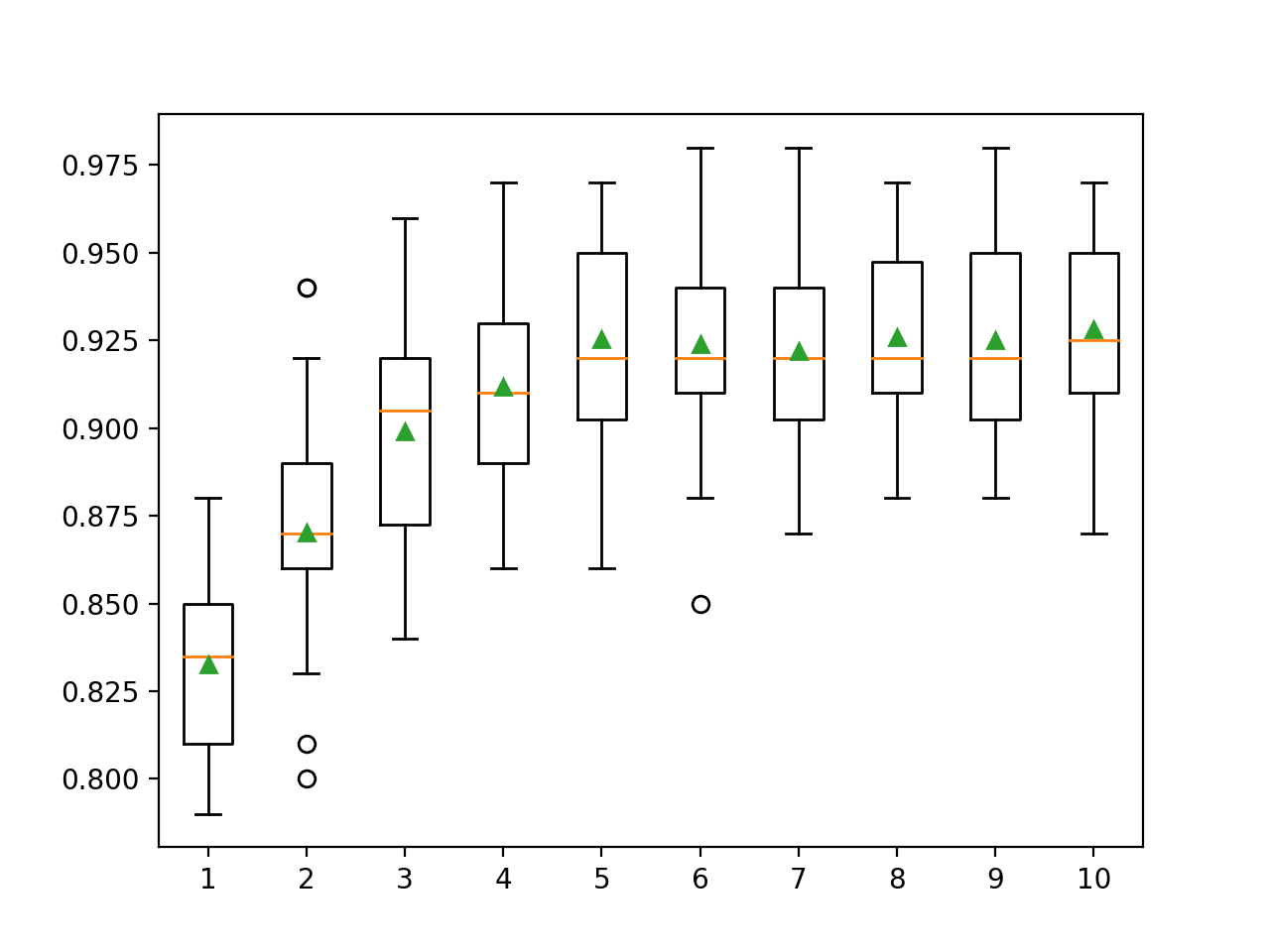
Ici, nous pouvons voir que les performances s'améliorent avec l'augmentation de la profondeur de l'arbre, peut-être jusqu'à 10 niveaux. Il serait intéressant d'explorer des arbres encore plus profonds.
>1 0.833 (0.028)
>2 0.870 (0.033)
>3 0.899 (0.032)
>4 0.912 (0.026)
>5 0.925 (0.031)
>6 0.924 (0.029)
>7 0.922 (0.027)
>8 0.926 (0.027)
>9 0.925 (0.028)
>10 0.928 (0.029)Un graphique rectangle et moustache est généré pour distribuer les scores de précision pour chaque profondeur d'arbre configurée. Les performances du modèle ont généralement tendance à augmenter avec une profondeur d'arbre allant jusqu'à cinq niveaux, après quoi les performances restent assez stables.
Recherche sur le taux d'apprentissage
Le taux d'apprentissage contrôle le degré auquel chaque modèle contribue à la prédiction d'ensemble. Des vitesses plus faibles peuvent nécessiter plus d'arbres de décision dans l'ensemble. Le taux d'apprentissage peut être contrôlé avec l'argument learning_rate, par défaut il est de 0,1. Ce qui suit examine le taux d'apprentissage et compare l'effet des valeurs de 0,0001 à 1,0.
# explore lightgbm learning rate effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
rates = [0.0001, 0.001, 0.01, 0.1, 1.0]
for r in rates:
key = '%.4f' % r
models[key] = LGBMClassifier(learning_rate=r)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()L'exécution de l'exemple affiche d'abord la précision moyenne pour chaque taux d'apprentissage configuré.
Remarque : vos résultats peuvent varier en raison de la nature stochastique de l'algorithme ou de la procédure d'estimation, ou des différences de précision numérique. Envisagez d'exécuter l'exemple plusieurs fois et de comparer la moyenne.
Ici, nous voyons qu'un taux d'apprentissage plus élevé conduit à de meilleures performances sur cet ensemble de données. Nous prévoyons que l'ajout de plus d'arbres à l'ensemble pour un taux d'apprentissage inférieur améliorera davantage les performances.
>0.0001 0.800 (0.038)
>0.0010 0.811 (0.035)
>0.0100 0.859 (0.035)
>0.1000 0.925 (0.031)
>1.0000 0.928 (0.025)Une boîte à moustache est créée pour distribuer les scores de précision pour chaque taux d'apprentissage configuré. Les performances du modèle ont tendance à augmenter avec une augmentation du taux d'apprentissage jusqu'à 1,0.

Stimuler la recherche de type
La particularité de LightGBM est qu'il prend en charge un certain nombre d'algorithmes de boost appelés types de boost. Le type d'amplification est spécifié à l'aide de l'argument boosting_type et prend une chaîne pour déterminer le type. Valeurs possibles:
- 'gbdt' : arbre de décision à gradient amélioré (GDBT);
- 'dart' : le concept d'abandon est entré dans MART, on obtient DART;
- 'goss' : Récupération à sens unique de gradient (GOSS).
La valeur par défaut est GDBT, l'algorithme classique d'amplification de gradient.
DART est décrit dans un article de 2015 intitulé " DART: les abandons rencontrent plusieurs arbres de régression additive " et, comme son nom l'indique, ajoute le concept de décrochage d' apprentissage en profondeur à l' algorithme MART ( Multiple Additive Regression Trees ), un précurseur des arbres de décision de renforcement de gradient.
Cet algorithme est connu sous de nombreux noms, notamment Gradient TreeBoost, Boosted Trees et Multiple Additive Regression Trees and Trees (MART). Nous utilisons ce dernier nom pour désigner l'algorithme.
GOSS est présenté avec des travaux sur LightGBM et la bibliothèque lightbgm. Cette approche vise à n'utiliser que les instances qui entraînent un gradient d'erreur important pour mettre à jour le modèle et supprimer les instances restantes.
... Nous excluons une partie significative des instances de données avec de petits gradients et n'utilisons que le reste pour estimer l'augmentation des informations.
Ci-dessous, LightGBM est formé sur un ensemble de données de classification synthétique avec trois méthodes de renforcement clés.
# explore lightgbm boosting type effect on performance
from numpy import arange
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
types = ['gbdt', 'dart', 'goss']
for t in types:
models[t] = LGBMClassifier(boosting_type=t)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()L'exécution de l'exemple affiche d'abord la précision moyenne pour chaque type d'accentuation configuré.
Remarque : vos résultats peuvent différer en raison de la nature stochastique de l'algorithme ou de la procédure d'estimation, ou des différences de précision numérique. Envisagez d'exécuter l'exemple plusieurs fois et de comparer le résultat moyen.
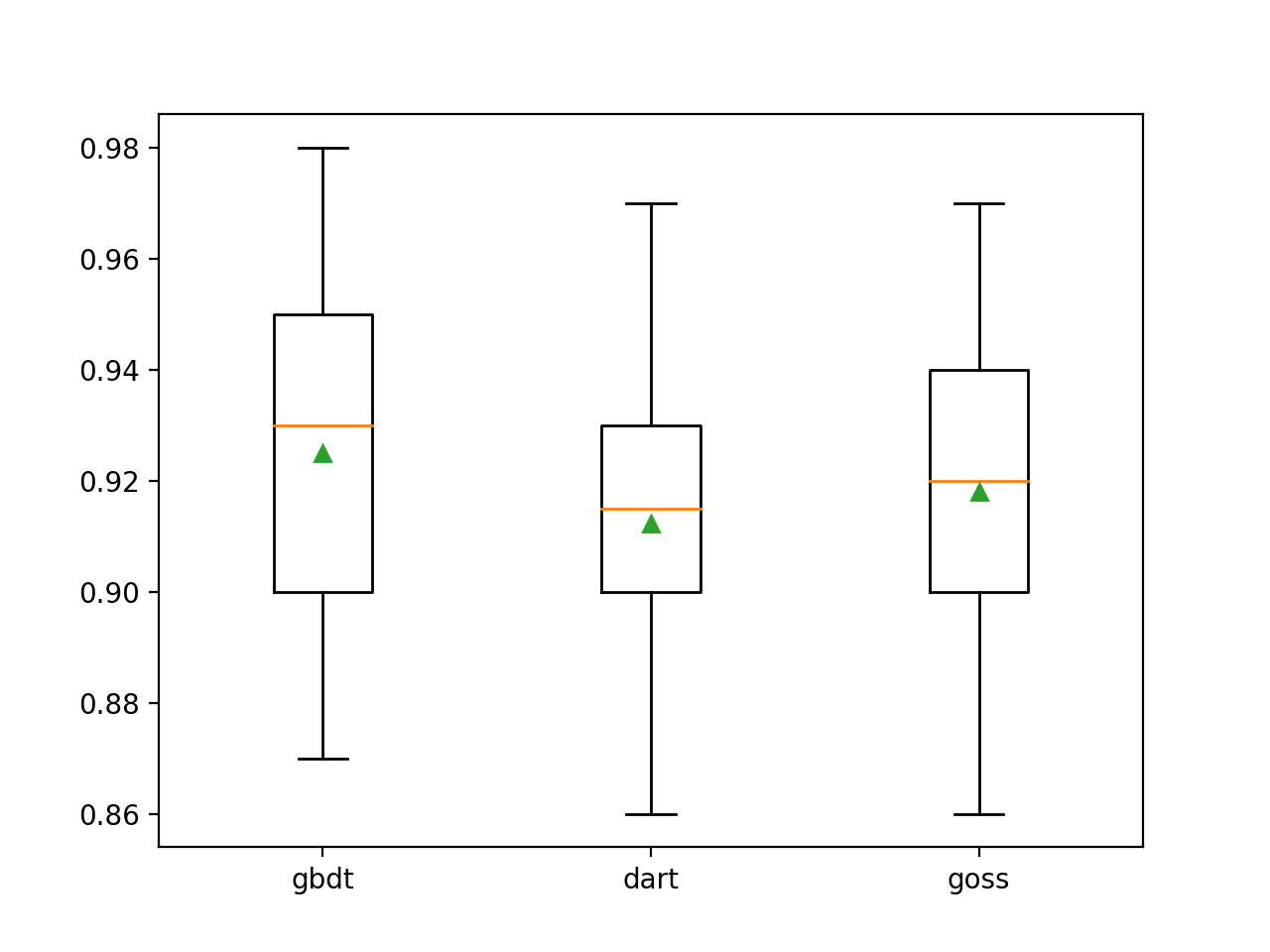
Nous pouvons voir que la méthode boost par défaut fonctionne mieux que les deux autres méthodes évaluées.
>gbdt 0.925 (0.031)
>dart 0.912 (0.028)
>goss 0.918 (0.027)Un diagramme boîte et moustache est créé pour distribuer les estimations de précision pour chaque méthode d'amplification configurée, permettant une comparaison directe des méthodes.

- Cours d'apprentissage automatique
- Formation aux métiers de la Data Science
- Formation d'analyste de données
- Cours Python pour le développement Web
Plus de cours