Je m'appelle Sergey Rakov, je suis responsable de la division B2G chez Rostelecom IT. Je veux vous parler du langage de requête Jira (JQL): comment l'utiliser dans la pratique, les techniques de base, quels problèmes nous avons rencontrés et comment nous les avons résolus.
 Photo originale tirée de deviniti.com/atlassian
Photo originale tirée de deviniti.com/atlassian
Il y a beaucoup de trackers de tâches, chacun est adapté pour résoudre certains problèmes et pas très utile pour résoudre d'autres. Nous en avons utilisé beaucoup, mais maintenant nous nous sommes installés sur Jira - c'est notre outil principal. Personnellement, j'aime beaucoup son langage JQL, qui simplifie grandement le travail et vous permet d'avoir un outil puissant et flexible pour trouver des tickets prêt à l'emploi.
Hors de la boîte, Jira a des recherches de base et avancées. Ces deux options de recherche peuvent résoudre la plupart des problèmes auxquels l'utilisateur est confronté. La recherche de base est familière aux yeux de toute personne qui a utilisé les services de boutiques en ligne au moins une fois - elle fonctionne selon le même schéma simple. Il existe de nombreux filtres: par projets, types de tâches, par exécuteur et statut. Vous pouvez également ajouter des champs supplémentaires en fonction de critères pris en charge par Jira.
Mais un problème survient lorsque vous devez aller au-delà des requêtes de base. Par exemple, si nous voulons rechercher des tâches qui ont déjà été sur un intervenant particulier, ou rechercher toutes les tâches, à l'exception d'un projet. Il n'est plus possible de faire une sélection délicate pour un projet avec un statut de tâche et un exécuteur et un autre exécuteur et un autre statut de tâche en utilisant la recherche de base.
La recherche avancée vient à la rescousse. La syntaxe JQL est très similaire à SQL. Mais en JQL, il n'est pas nécessaire de sélectionner des champs spécifiques que nous allons sélectionner, d'indiquer les tables et bases de données à partir desquelles nous allons afficher. Nous spécifions uniquement un bloc avec des conditions et travaillons avec le tri - Jira fait le reste automatiquement.
Tout ce que vous devez savoir pour travailler avec JQL, ce sont les noms des champs par lesquels nous allons sélectionner les tickets, les opérateurs ( = ,! =, <,>, In, not in, was, is , etc.), les mots-clés ( AND , OR, NOT, EMPTY, ORDER BY , etc.) et des fonctions prêtes à l'emploi en mode avancé ( Now (), CurrentUser (), IssueHistory (), EndOfDay () et autres).
Des champs
Jira, lorsque vous tapez dans la barre de recherche, donne lui-même des indications sur toutes les valeurs possibles que vous recherchez: à la fois par champs et par les valeurs de ces champs. Pour ma part, j'ai récemment découvert un champ système intéressant lastViewed . Jira garde une trace de vos vues de billets.

Voici deux options pour composer des filtres pour afficher les tâches récentes. La première est ma dernière option vue , où Jira retournera les problèmes que j'ai consultés au cours des sept derniers jours, triés par ordre décroissant. Ce filtre est configuré sur mon tableau de bord comme un gadget, et je l'utilise souvent. Parce que le ticket était fermé, je ne me souvenais pas de l'onglet et du numéro, je l'ai rapidement ouvert, j'ai regardé quel était le dernier ticket.
Il existe un filtre standard Vu récemment. Il utilise la fonction IssueHistory () , le tri est également effectué par le champ lastViewed . Le résultat est le même, mais la méthode, même dans Jira, peut être utilisée différemment. Il est à noter que les champs LastViewed et IssueHistory () ne renvoient que votre historique de visualisation - vous ne pouvez pas afficher l'historique des tiers de cette manière.
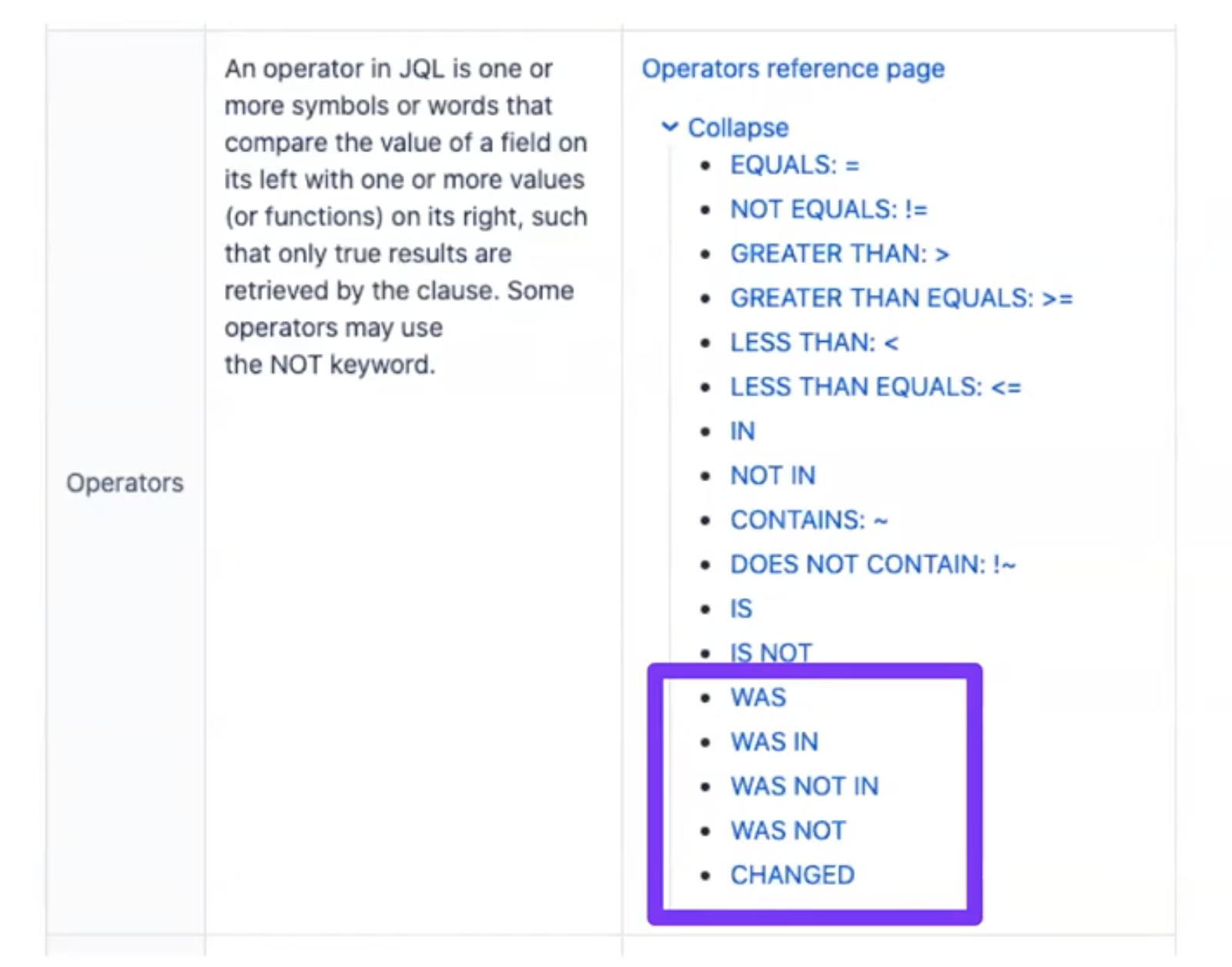
Pour la plupart, Jira a des opérateurs standard. Mes opérateurs préférés sont WAS , WAS IN , WAS NOT IN , WAS NOT , CHANGÉ parce qu'ils travaillent avec le temps. Cela n'est pas possible dans les bases de données conventionnelles.

Jira vous permet de travailler avec des données historiques hors de la boîte. En utilisant l'opérateur WAS , vous pouvez trouver des tickets où l'exécuteur était et est User1. Si le billet était sur moi, puis transmis à quelqu'un d'autre, la demande montrera que ce billet était une fois sur moi. Il est clair que pour une sélection plus détaillée, vous devez ajouter quelques conditions supplémentaires, mais nous y reviendrons plus tard.
Cependant, il y a une mise en garde: Jira ne stocke pas l'historique des champs de texte: les noms des tickets et leurs descriptions. Vous ne pouvez pas y écrire: « Apportez-moi des billets dans lesquels le champ Résumé contenait le mot« Rostelecom » ».
Deuxième exemple avec l'opérateur CHANGED . Nous aimerions recevoir des tickets dans lesquels l'exécuteur testamentaire a été changé après le 1er janvier 2020. Vous pouvez utiliser d'autres mots supplémentaires, par exemple, AVANT ou signes>, <, à qui cela convient le mieux, et une date précise. Dans le même exemple, vous pouvez également faire une négation et voir quels tickets sont accrochés sur quels utilisateurs: le destinataire n'a pas été modifié APRÈS '2020-01-01' .
Mots clés

Les principaux mots-clés sont OU , ET , NON . Ils fonctionnent de la même manière que les opérateurs logiques. En utilisant OR , nous obtenons un ensemble complet de tickets de deux projets A et B. Si nous devons affiner la sélection, nous utilisons AND . Exemple - nous avons besoin de tickets du brouillon A, sur lequel l'utilisateur exécutait Bed et: project = A = Bed et le cessionnaire AND . C'est la même chose avec le déni.
Les fonctions
D'après la documentation, il y a 47 fonctions dans Jira, mais je ne les ai jamais toutes utilisées. En voici quelques-uns, à mon avis, les principaux:
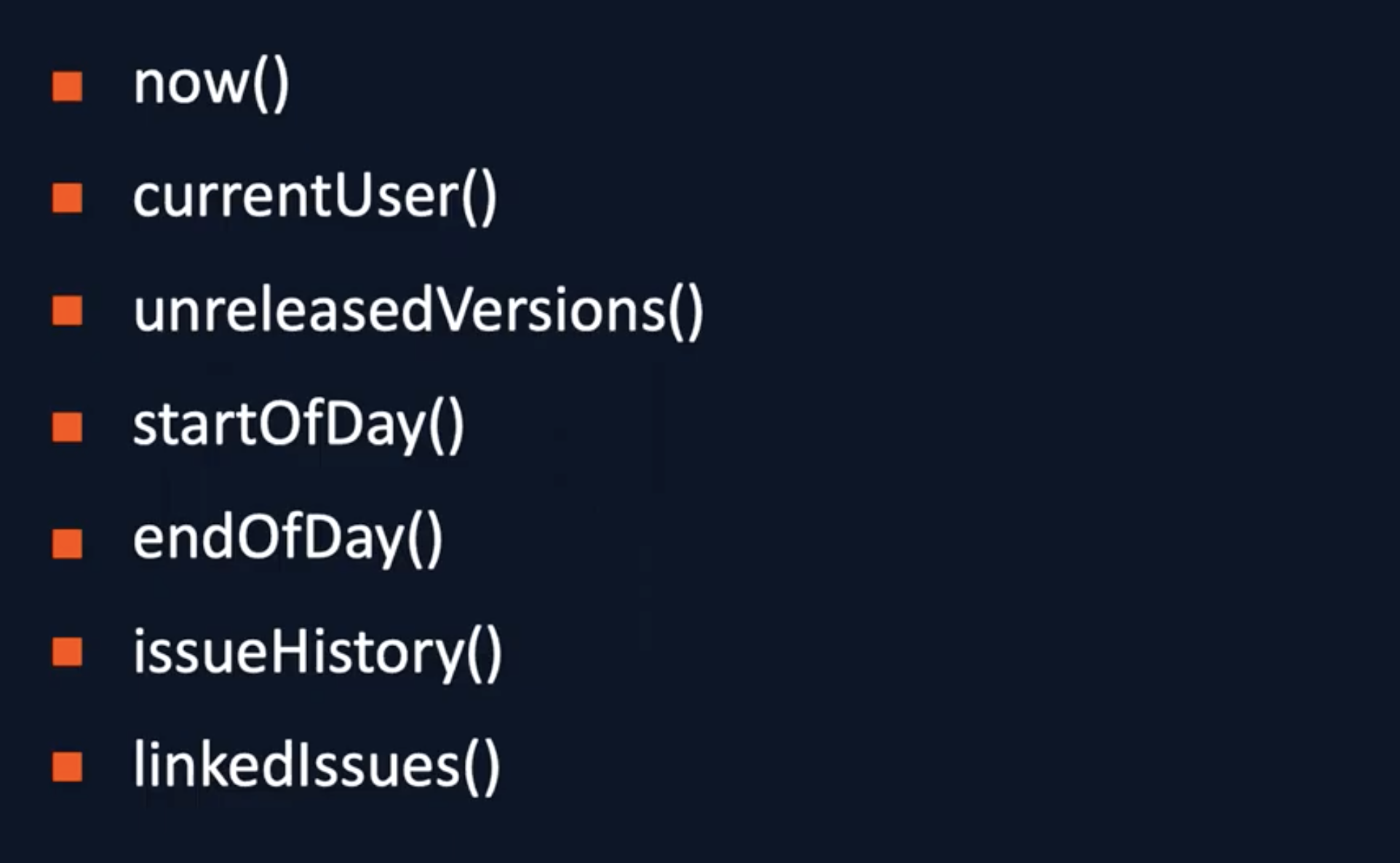
now () est une fonction populaire qui vous permet de trouver des billets qui, par exemple, ont expiré.
currentUser () renvoie l'utilisateur actuel. Jira contient des filtres préconfigurés qui utilisent cette fonctionnalité. Avec currentUser (), vous pouvez effectuer des recherches génériques. C'est ainsi que j'ai créé un tableau de bord universel pour toute l'équipe de développement: j'ai fourré des gadgets sur le tableau de bord et dans chaque j'ai indiqué currentUser () au lieu d'un utilisateur spécifique . Ce tableau de bord sera unique pour chaque utilisateur connecté, bien que la configuration soit la même.
unreleasedVersions () est une fonction qui renvoie des tickets qui sont dans des versions non publiées. Mais il ne retourne pas les billets qui n'ont pas de version.
startOfDay () renvoie le début du jour en cours. Il existe des fonctions pour la semaine, le mois et l'année. La même chose s'applique à la fonction de fermeture endOfDay () . Ils vous permettent de vous débarrasser de dates spécifiques, on peut leur donner des arguments: si vous écrivez startOfDay (-1) , alors le début de la journée précédente sera retourné. Si vous laissez tout tel quel, le début de la journée en cours sera affiché - la sortie sera l'heure. Ces fonctions permettent d'éviter le hardcode, nous les utilisons très souvent.
De issueHistory ()J'ai déjà donné un exemple, cette fonction renvoie une liste de vos vues uniquement.
linkedIssues () est une fonction qui vous permet de trouver des tickets liés à un ticket spécifique.
Ce sont les fonctions les plus simples. Mais plongons un peu plus en profondeur et examinons des connexions plus complexes.
assignee was currentUser()
AND fixVersion was in
unreleasedVersions()
AND created > startOfYear()
Un exemple un peu synthétique, mais néanmoins. Il s'agit d'une seule requête divisée en trois blocs. Après avoir complété la première partie de la demande, nous recevrons des tickets sur lesquels j'ai déjà été exécuteur testamentaire ou j'en suis actuellement un. Il est très important que WAS ait non seulement existé, mais existe toujours.
Dans la deuxième partie, le filtrage est ajouté: nous filtrerons les portées reçues de mes tickets qui n'ont jamais été dans des versions inédites pour le moment. Autrement dit, s'il y avait un ticket dans cette version inédite et qu'il n'a toujours pas été publié pour le moment, mais que j'ai ensuite transféré le ticket vers une autre version, et il a déjà été publié, le ticket sera inclus dans cette sélection.
La troisième condition est la date de création. Nous filtrons uniquement les tickets qui ont été créés depuis le début de l'année en cours.
ScriptRunner
C'est un plugin qui améliore considérablement les capacités de Jira. Il est généralement utilisé pour automatiser les processus, mais il ajoute également de nombreuses fonctionnalités supplémentaires à JQL. ScriptRunner a été notre tout premier plugin que nous avons livré dès notre déménagement vers Jira - fin 2018. J'ai demandé très activement d'installer ce plugin, car sans lui je ne pourrais pas collecter de données sur les liens avec les epics. Par exemple, j'avais souvent besoin de renvoyer tous les tickets epic pour une demande spécifique ou tous les epics pour les tickets de sous-requêtes. ScriptRunner vous permet de faire tout cela avec succès.
Pour utiliser les fonctions ScriptRunner, vous devez ajouter un mot supplémentaire issueFunction dans ou non dans JQL . Vient ensuite la fonction, par exemple epicsOf () - Il renvoie les epics de ticket qui correspondent aux conditions de la sous-requête. La sous-requête apparaît entre parenthèses sur la deuxième ligne, et nous l'examinerons de plus près.
issueFunction in epicsOf
("worklogDate >= startOfWeek(-1) AND worklogDate <= endOfWeek(-1)")
AND project in (".B2G")
Dans le premier exemple, nous recherchons des épopées avec annulation de temps pour la semaine dernière. Life hack pour les chefs d'équipe et les managers: si vous avez oublié de remplir les feuilles de temps, et que vous ne vous souvenez pas de ce que vous avez fait la semaine dernière, en complétant cette demande, vous verrez sur quelles épopées l'équipe a travaillé. Et très probablement, vous avez également travaillé dessus, car l'équipe est clairement venue avec des questions. En général, cette requête permet de se souvenir de ce que vous faisiez et tout est parfait à peindre.
La requête elle-même commence à s'exécuter à partir des parenthèses, c'est-à-dire à partir de la sous - requête worklogDate - la date de débit. En outre, il existe une spécification > = startOfWeek (-1) - le début de la semaine. Mais faites attention au chiffre -1: cela signifie que nous n'avons pas besoin de ce lundi, mais du dernier. Et aussi worklogDate <= endOfWeek (-1), c'est-à-dire que c'est moins que la fin de la semaine dernière. Cette demande émettra des tickets, quoi qu'il arrive - bugs, tâches, user stories - pour lesquels les employés ont radié le temps du lundi au dimanche la semaine dernière.
L'astuce est que les fonctions startOfWeek () et endOfWeek () vous permettent de vous débarrasser de la date. Quel que soit le temps pendant lequel je fais cette demande dans la semaine en cours, cela me rendra la même portée épique. Dès que cette semaine se terminera, il vous rendra les épopées. Étonnamment, tout le monde ne profite pas de cette opportunité: j'ai récemment étudié les demandes ouvertes qui sont partagées publiquement, et j'ai vu beaucoup de dates en dur. Et on soupçonne que ces dates changent constamment. Et que puis-je dire, au début je l'ai fait moi-même.
En exécutant la sous-requête, nous obtenons l'ensemble habituel de tickets. Vient ensuite la fonction epicsOf , qui nous donne une liste des épopées associées à ces tickets. Et puis il y a filtrage par projet, car je n'ai besoin que d'épopées pour mon projet, et tout le monde n'est pas intéressant.
La prochaine demande concerne les épopées avec radiations cette année, mais pas de contrats. Cette demande est apparue du fait que nous utilisons Jira non seulement comme suivi des tâches, mais également pour la comptabilité financière. Il existe un projet distinct pour les contrats, que nous gérons sous forme de tickets, et nous l'utilisons comme système de gestion électronique de documents: les statuts changent constamment, nous lions les contrats aux épopées, nous savons combien de personnes ont radié à quelle épopée, nous savons combien cela coûte, et nous fixons le coût des travaux pour chaque contrat. De plus, par le biais de contrats, les coûts de main-d'œuvre sont transférés à Redmine 2.0. Autrement dit, nous annulons dans Jira, puis les scripts automatiques transfèrent nos coûts vers Redmine 2.0 en vertu de ces contrats.
Lorsque cette automatisation a commencé à fonctionner, j'ai commencé à recevoir des demandes de collègues du genre: il y a des épopées dont les coûts de main-d'œuvre ne peuvent pas être transférés à Redmine, car il n'y a pas de contrats là-bas. Examinons la demande plus en détail.
issueFunction in epicsOf("worklogDate >= startOfYear()")
AND issueFunction not in hasLinkType(Contract)
AND project in (".B2G")
La demande ci-jointe signifie que nous sommes intéressés par les billets facturés pour cette année. La fonction epicsOf découle de l'exemple précédent et nous donne une liste d'épopées. Ensuite, nous voulons filtrer par la présence de contrats.
Un contrat entre parenthèses est un type de lien interne qui relie les contrats aux épopées. hasLinkType () est une fonction de ScriptRunner qui renvoie des tickets avec ce type de lien. Mais j'ai besoin de tickets qui ne contiennent pas ce type de relation, et donc j'utilise la négation pas dedans.
Lorsque la première condition a été remplie, j'ai eu un éventail d'épopées pertinentes cette année. En outre, les épopées sans contrats ont été filtrées, et au final - pour un projet spécifique "Video.B2G". De cette façon, j'ai eu toutes les épopées avec lesquelles travailler.
Et à la fin, je veux suggérer de passer un petit test de trois questions sur le sujet de ce post. Prendra 2 minutes. Après avoir réussi, vous verrez votre évaluation.
Lien de sondageJe serais heureux de clarifier quelque chose ou de répondre aux questions dans les commentaires, si vous en avez.
Je vous remercie.