CREATE TABLE task AS
SELECT
id
, (random() * 100)::integer person -- 100
, least(trunc(-ln(random()) / ln(2)), 10)::integer priority -- 2
FROM
generate_series(1, 1e5) id; -- 100K
CREATE INDEX ON task(person, priority);
Le mot «est» en SQL se transforme en
EXISTS
- voici la version la plus simple et commençons:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

toutes les photos du plan sont cliquables
Jusqu'à présent, tout semble bon, mais ...
EXISTE + DANS
... puis ils sont venus nous voir et nous ont demandé d'inclure non seulement
priority = 10
8 et 9 comme "super" :
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority IN (10, 9, 8)
);

Ils ont lu 1,5 fois plus, et cela a également affecté le temps d'exécution.
OU + EXISTE
Essayons d'utiliser nos connaissances selon lesquelles il est
priority = 8
beaucoup plus probable de rencontrer un record de 10:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

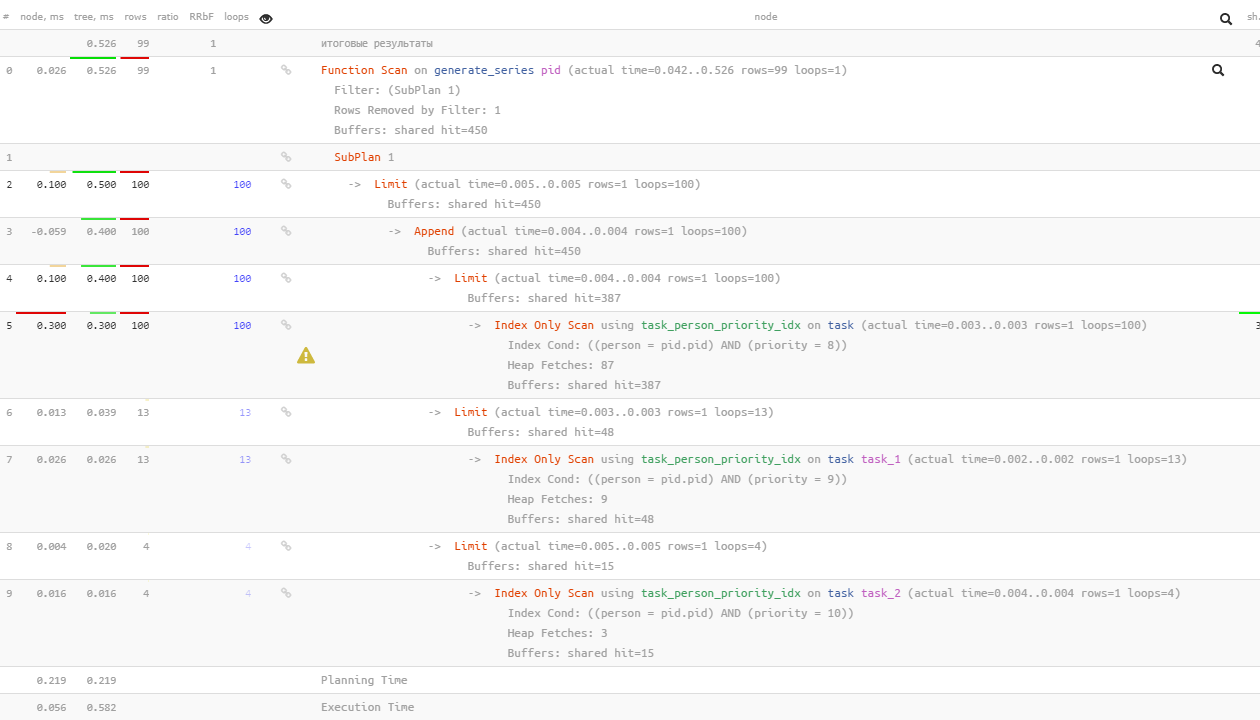
Notez que PostgreSQL 12 est déjà assez intelligent pour faire des sous-
EXISTS
requêtes suivantes uniquement pour celles "non trouvées" par les précédentes après 100 recherches pour la valeur 8 - seulement 13 pour la valeur 9, et seulement 4 pour 10.
CAS + EXISTES + ...
Sur les versions précédentes, un résultat similaire peut être obtenu en "masquant sous CASE" les requêtes suivantes:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) THEN TRUE
ELSE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) THEN TRUE
ELSE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
)
END
END;
EXISTANT + UNION ALL + LIMIT
Idem, mais vous pouvez obtenir un peu plus vite si vous utilisez le "hack"
UNION ALL + LIMIT
:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
LIMIT 1
)
LIMIT 1
);
Les index corrects sont la clé de la santé de la base de données
Examinons maintenant le problème sous un angle complètement différent. Si nous savons avec certitude que le
task
nombre d'enregistrements que nous voulons trouver est plusieurs fois inférieur au reste , alors nous ferons un index partiel approprié. En même temps, passons directement de l'énumération "dot"
8, 9, 10
à
>= 8
:
CREATE INDEX ON task(person) WHERE priority >= 8;
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority >= 8
);

J'ai dû lire 2 fois plus vite et 1,5 fois moins!
Mais, probablement, pour soustraire tous ceux qui conviennent à la
task
fois - sera-ce encore plus rapide? ..
SELECT DISTINCT
person
FROM
task
WHERE
priority >= 8;

Loin d'être toujours, et certainement pas dans ce cas - car au lieu de 100 lectures des premiers enregistrements disponibles, nous devons en lire plus de 400!
Et pour ne pas deviner laquelle des options de requête sera la plus efficace, mais pour le savoir en toute confiance, utilisez explic.tensor.ru .