Mais, puisque les gens ne sont pas des ordinateurs, ils recherchent quelque chose comme " quelque chose comme ça venait d' Ivanov ou d'Ivanovsky ... non, pas ça, plus tôt, même plus tôt ... c'est ici! "
Mais cela menace le développeur de problèmes terribles - après tout, pour la recherche FTS dans PostgreSQL , des types "spatiaux" d'index GIN et GiST sont utilisés , qui ne fournissent pas le "glissement" de données supplémentaires, sauf pour un vecteur de texte.
Il ne reste plus qu'à lire malheureusement tous les enregistrements par correspondance de préfixe (il y en a des milliers!) Et à trier ou, au contraire, à passer par l'index de date et le filtretoutes les entrées trouvées pour le préfixe correspondent jusqu'à ce que nous trouvions celles qui conviennent (dans combien de temps y aura-t-il "charabia"? ..).
Les deux ne sont pas très agréables pour les performances des requêtes. Ou pouvez-vous encore penser à quelque chose pour une recherche rapide?
Commençons par générer nos "textes à jour":
CREATE TABLE corpus AS
SELECT
id
, dt
, str
FROM
(
SELECT
id::integer
, now()::date - (random() * 1e3)::integer dt -- - 3
, (random() * 1e2 + 1)::integer len -- "" 100
FROM
generate_series(1, 1e6) id -- 1M
) X
, LATERAL(
SELECT
string_agg(
CASE
WHEN random() < 1e-1 THEN ' ' -- 10%
ELSE chr((random() * 25 + ascii('a'))::integer)
END
, '') str
FROM
generate_series(1, len)
) Y;
Approche naïve n ° 1: gist + btree
Essayons de rouler l'index à la fois pour FTS et pour le tri par date - et si cela aide:
CREATE INDEX ON corpus(dt);
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str));
Nous rechercherons tous les documents contenant des mots commençant par
'abc...'
. Et, d'abord, vérifions qu'il n'y a pas beaucoup de tels documents et que l'index FTS est utilisé normalement:
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*');
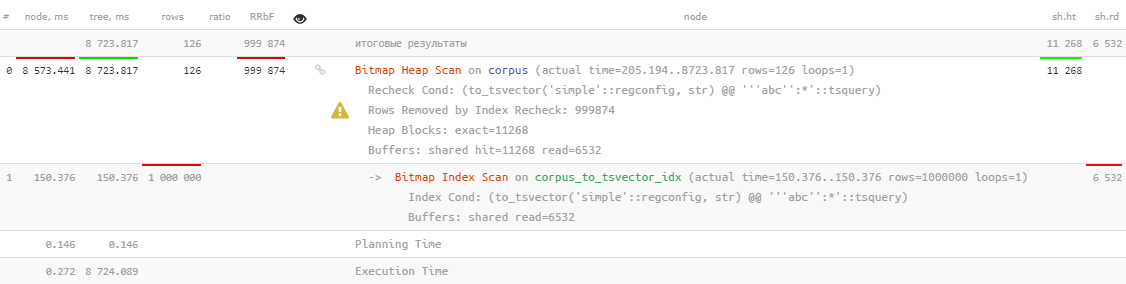
Eh bien ... il est, bien sûr, utilisé, mais cela prend plus de 8 secondes , ce qui n'est clairement pas ce que nous aimerions consacrer à la recherche de 126 enregistrements.
Peut-être que si vous ajoutez un tri par date et ne recherchez que les 10 derniers enregistrements , ça va mieux?
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt DESC
LIMIT 10;

Mais non, juste le tri a été ajouté en plus.
Approche naïve # 2: btree_gist
Mais il existe une excellente extension
btree_gist
qui permet de "glisser" une valeur scalaire dans un index GiST, ce qui devrait nous permettre d'utiliser immédiatement le tri par index à l'aide de l'opérateur distance
<->
, qui peut être utilisé pour les recherches kNN :
CREATE EXTENSION btree_gist;
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str), dt);
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt <-> '2100-01-01'::date DESC -- ""
LIMIT 10;
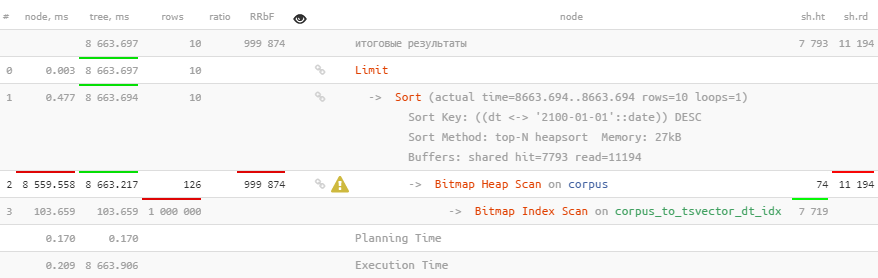
Hélas, cela n'aide pas du tout.
La géométrie à la rescousse!
Mais il est trop tôt pour désespérer! Regardons la liste des classes d'opérateurs intégrées GiST - l'opérateur de distance n'est
<->
disponible que pour "géométrique"
circle_ops, point_ops, poly_ops
, et depuis PostgreSQL 13 - pour
box_ops
.
Essayons donc de traduire notre problème "dans le plan" - nous attribuons les coordonnées de certains points à nos paires
(, )
utilisées pour la recherche afin que les mots "préfixes" et les dates non éloignées soient aussi proches que possible:

Nous divisons le texte en mots
Bien entendu, notre recherche ne sera pas entièrement en texte intégral, dans le sens où vous ne pouvez pas définir une condition pour plusieurs mots en même temps. Mais ce sera certainement un préfixe!
Formons une table de dictionnaire auxiliaire:
CREATE TABLE corpus_kw AS
SELECT
id
, dt
, kw
FROM
corpus
, LATERAL (
SELECT
kw
FROM
regexp_split_to_table(lower(str), E'[^\\-a-z-0-9]+', 'i') kw
WHERE
length(kw) > 1
) T;
Dans notre exemple, il y avait 4,8 millions de «mots» pour 1 million de «textes».
Poser les mots
Pour traduire un mot dans sa «coordonnée», imaginons qu'il s'agit d'un nombre écrit en notation de base
2^16
(après tout, nous voulons également prendre en charge les caractères UNICODE). Nous ne l'écrirons qu'à partir de la 47ème position fixe:
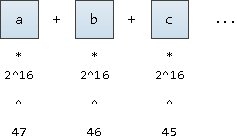
il serait possible de partir de la 63ème position, cela nous donnera des valeurs légèrement inférieures aux valeurs
1E+308
limites pour
double precision
, mais alors un débordement se produira lors de la construction de l'index.
Il s'avère que sur l'axe des coordonnées, tous les mots seront ordonnés:

ALTER TABLE corpus_kw ADD COLUMN p point;
UPDATE
corpus_kw
SET
p = point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
);
CREATE INDEX ON corpus_kw USING gist(p);
Nous formons une requête de recherche
WITH src AS (
SELECT
point(
( --
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
SELECT
*
, src.ps <-> kw.p d
FROM
corpus_kw kw
, src
ORDER BY
d
LIMIT 10;

Nous avons maintenant les
id
documents que nous recherchions, triés dans le bon ordre - et cela a pris moins de 2 ms, 4000 fois plus vite !
Une petite mouche dans la pommade
L'opérateur
<->
ne sait rien de notre classement selon deux axes, donc nos données requises se trouvent uniquement dans l'un des bons quartiers, en fonction du tri requis par date:

Eh bien, nous voulions quand même sélectionner les textes-documents eux-mêmes, et non leurs mots-clés, nous aurons donc besoin d'un index oublié depuis longtemps:
CREATE UNIQUE INDEX ON corpus(id);
Finalisons la demande:
WITH src AS (
SELECT
point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
, dc AS (
SELECT
(
SELECT
dc
FROM
corpus dc
WHERE
id = kw.id
)
FROM
corpus_kw kw
, src
WHERE
p[0] >= ps[0] AND -- kw >= ...
p[1] <= ps[1] -- dt DESC
ORDER BY
src.ps <-> kw.p
LIMIT 10
)
SELECT
(dc).*
FROM
dc;

Ils nous ont ajouté un peu
InitPlan
avec le calcul de la constante x / y, mais nous avons quand même gardé les mêmes 2 ms !
Volez dans la pommade # 2
Rien n'est gratuit:
SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) FROM pg_class WHERE relname LIKE 'corpus%';
corpus | 242 MB -- corpus_id_idx | 21 MB -- PK corpus_kw | 705 MB -- corpus_kw_p_idx | 403 MB -- GiST-
242 Mo de «textes» sont devenus 1,1 Go d '«index de recherche».
Mais après tout,
corpus_kw
la date et le mot lui-même se trouvent, ce que nous n'avons pas utilisé dans la recherche même - supprimons-les:
ALTER TABLE corpus_kw
DROP COLUMN kw
, DROP COLUMN dt;
VACUUM FULL corpus_kw;
corpus_kw | 641 MB -- id point
Une bagatelle - mais agréable. Cela n'a pas trop aidé, mais encore 10% du volume a été récupéré.