
Pour comprendre l' ADN d'entreprise de Huawei , il est utile de commencer par faire un rapide tour d'horizon des défis auxquels les réseaux d'entreprise sont confrontés aujourd'hui.
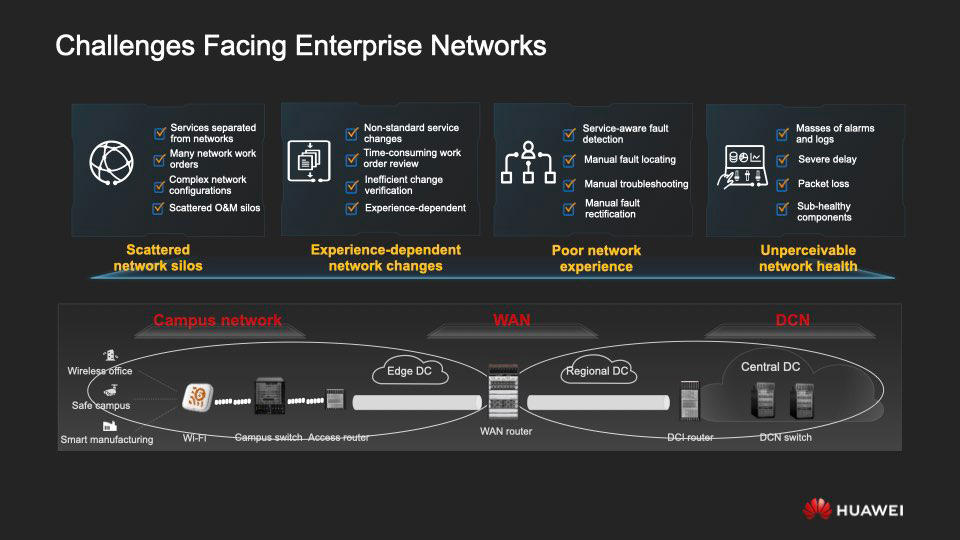
Il ne fait aucun doute que la transformation numérique ne contournera aucune grande organisation. Et ce processus est impensable sans un support d'infrastructure digne. Pour répondre aux exigences de la numérisation, le réseau d'entreprise doit être fiable, flexible et évolutif.
Un tel réseau comprend deux parties principales: un réseau d'accès et un réseau central. Dans le diagramme ci-dessus, à gauche de l'emplacement de l'équipement régional se trouve le même réseau d'accès conçu pour fournir une connexion aux campus d'entreprise, aux succursales, aux structures externes, aux environnements IoT, etc. Sur la droite, les connexions interrégionales et "inter-cloud" sont affichées.
Bien que l'architecture soit fondamentalement la plus simple, en pratique, en règle générale, vous devez faire face à un énorme réseau hétérogène basé sur des équipements de différents fournisseurs. Ses coûts d'exploitation et de maintenance sont parfois nettement plus élevés que son achat. Voici quatre «circonstances aggravantes» majeures qui rendent la vie difficile aux concepteurs et administrateurs des réseaux de corpus modernes.
I. Les silos de réseau, qui déconnectent les services de l'infrastructure réseau, créent de la confusion avec trop de tâches réseau, la configuration du réseau lui-même devient trop compliquée et l'O & M perd en efficacité.
II. Une grande hétérogénéité du réseau, avec leur parc d'
équipement hétéroclite . Cela entraîne de nombreuses difficultés, y compris la dépendance du bon fonctionnement de l'infrastructure à l'expérience d'experts individuels, de longs cycles de résolution de problèmes, des contrôles inefficaces et des erreurs causées par la nécessité d'effectuer une grande partie des opérations manuellement.
III. Séparation des services au niveau de l'entreprise et de l'infrastructure réseau.En conséquence, le fonctionnement complet du NaaS (Network as a Service) est impossible, que ce soit dans une zone séparée ou entre des zones du réseau. Au milieu d'une multitude de mesures, d'alertes et de journaux d'activité réseau innombrables, l'administrateur n'est pas en mesure de garantir que les services fonctionneront parfaitement à tout moment.
IV. Manque de visualisation du réseau de bout en bout et d'outils pour son analyse complète. C'est le véritable fléau de ceux qui construisent et exploitent des réseaux. Les dysfonctionnements sont souvent révélés de manière déprimante directement lors du fonctionnement des services, les utilisateurs ont le temps de les rencontrer, car ils ne peuvent pas être détectés et éliminés rapidement.

Pour relever ces défis, Huawei a créé une solution de réseau de conduite autonome (ADN) appelée iMaster NCE. Il contient la fonctionnalité d'un «jumeau numérique», une analyse de bout en bout des intentions (nous avons déjà écrit sur le concept de réseau axé sur l'intention plus en détail sur Habré ), ainsi que la technologie de la prise de décision intelligente.
- Le principe axé sur l'intention. Tout au long de la vie d'un réseau, ceux qui le gèrent peuvent utiliser des outils WYSIWYG simples pour garder le réseau sous contrôle.
- Prise de décision intelligente. Le système permet à une personne de choisir plus facilement les solutions optimales. Par exemple, au stade du déploiement du service, il est capable de "demander" les paramètres et configurations réseau appropriés, et lors de l'analyse des problèmes, il permet de trouver rapidement la cause racine du problème et lui-même suggère des étapes pour l'éliminer.
- " Jumeau numérique ". L'iMaster NCE comprend une infrastructure KPI de modélisation et de gestion à plusieurs niveaux basée sur le Big Data qui fonctionne avec des «instantanés virtuels» de tous les périphériques physiques du réseau. Dans ce cas, la solution effectue une cartographie bidirectionnelle entre le réseau et son «jumeau».
Avec l'aide d'ADN, cinq transformations importantes sont ainsi possibles.
- «», , , , , . iMaster NCE .
- , , , . , O&M- .
- . , , , .
- «» . — , , — .
- Remplacer le travail basé sur le facteur humain, principalement sur l'expérience d'experts, en utilisant un modèle où la prise de décision à l'aide de technologies «intelligentes» prévaut, y compris dans la conception, la surveillance, l'analyse et l'optimisation des interactions réseau

L'élément principal du modèle d'analyse axée sur l'intention est le transfert des demandes commerciales des utilisateurs vers la couche réseau. Le processus comporte trois éléments importants.
- Formation d'un modèle abstrait d'intentions (abstraction d'intention). Dans les réseaux d'entreprise, la plupart des intentions concernent les interactions entre les utilisateurs, les terminaux et les applications. En conséquence, un modèle est nécessaire qui généralisera leurs exigences tout au long du cycle de vie du réseau et assurera leur personnalisation basée sur une approche par scénario.
- (intent conversion). - . .
- «» , , , , ., «», (solver), .
- - « ». , «» , .
- . . :
- ;
- - ;
- (SDN, OVS .);
- , .
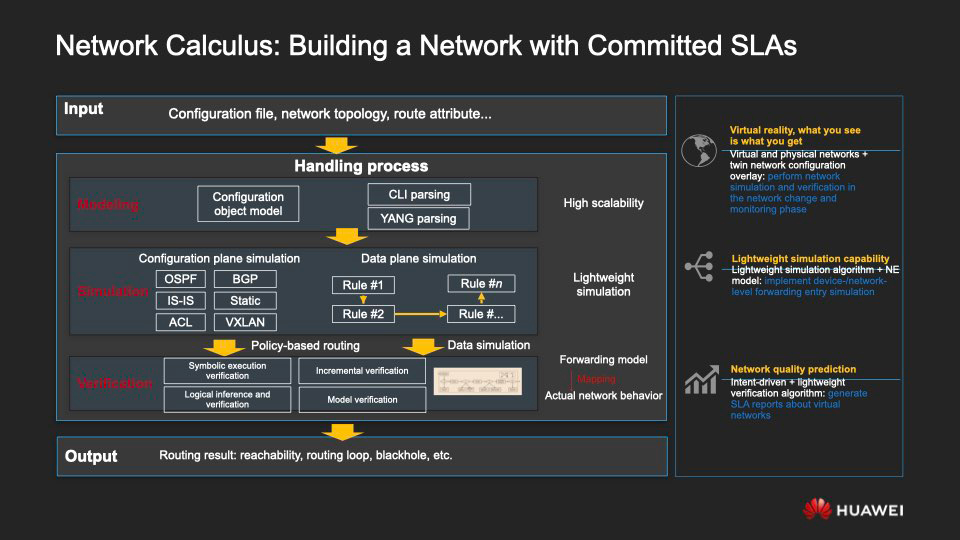
Passons à la modélisation de ce qui se passe dans le réseau, aux scénarios pour lesquels il est conçu et en raison desquels, en l'utilisant, il devient beaucoup plus facile de construire des réseaux en maintenant un niveau de service garanti (SLA).
En fait, nous simulons la configuration du réseau, les ressources et le système de transfert pour créer un réseau virtuel qui reflétera les caractéristiques et les spécificités du fonctionnement du réseau réel d'origine.
Lorsque nous travaillons avec un réseau virtuel, nous utilisons la preuve formelle - une méthode mathématique qui nous permet de vérifier si le réseau répond aux critères SLA, tels que la connectivité réseau stable, le routage continu, le transfert correctement configuré, la cohérence des politiques, la latence et les niveaux de perte de paquets acceptables, etc. etc.
Jetons un coup d'œil aux scénarios de base d'utilisation de la méthode.
- La modélisation complète des intentions de bout en bout valide de manière proactive la solution pour garantir que les nouvelles intentions ne perturbent pas les processus déjà en cours sur le réseau.
- Après la mise en œuvre de l'intention dans le réseau d'entreprise, on vérifie si elle fonctionne comme prévu, et les risques de toutes sortes d'excès sont surveillés - avant qu'ils n'aient le temps d'affecter le fonctionnement des services.
- Le comportement du réseau virtuel est vérifié dans des scénarios impliquant une zone, en inter-zone, en hybride (en utilisant des ressources cloud, etc.), et là encore il peut être complètement isolé du réseau principal de l'entreprise en mode automatique.
En bref, l'analyse du réseau est effectuée dans cette séquence.
- Sur la base de la topologie de réseau existante et des informations sur les éléments du réseau, un modèle de contrôle du réseau virtuel est créé.
- Une configuration de simulation est utilisée pour générer un système de transfert de réseau virtuel.
- Une méthode de preuve formelle est utilisée pour modéliser le comportement du réseau sous tous ses aspects, tels que: configuration, allocation des ressources, routage.
- La plate-forme propose de manière algorithmique des recommandations pour apporter des modifications au réseau.

Une fois toutes ces étapes franchies, la technologie de surveillance active intelligente mentionnée précédemment entre en jeu. Il est conçu pour numériser l'ensemble de l'infrastructure du réseau de manière à rendre possible la gestion intégrée de son fonctionnement, de son support, de son optimisation et de sa conception ultérieure.
Quelques exemples de la façon dont cela fonctionne. Disons qu'un signal provient d'une unité commerciale de l'entreprise indiquant qu'elle a perdu l'accès à l'application. La plate-forme iMaster NCE, principalement via la modélisation dynamique de la topologie du réseau, facilite l'interrogation et la visualisation de toutes les métriques liées à une application. De plus, grâce au navigateur de routage, il est pratique de tracer à tous les niveaux du réseau où et où allait le trafic, selon le principe de bout en bout - jusqu'à un appareil physique spécifique, tel qu'un smartphone (il vérifie la portée des sections et des éléments du réseau, des boucles et des trous noirs de routage etc.). À son tour, grâce à la visualisation complexe du travail des outils d'analyse, vous pouvez rapidement vérifier si les entrées pour des appareils spécifiques dans les tables de routage sont en ordre,ainsi que surveiller les notifications, les journaux et les enregistrements des changements de configuration. Et avec l'aide d'une solution recommandée par le service RunBook (bien sûr, l'administrateur est libre de faire ce qu'il veut), si nécessaire, l'opérabilité des composants et services du réseau est rapidement rétablie et les dysfonctionnements y sont éliminés.
Un autre scénario consiste à vérifier l'état du réseau. Pour cela, un modèle est utilisé avec cinq niveaux de contrôle, chacun suivant sa propre tranche de l'infrastructure:
- Le fonctionnement de l'équipement est-il stable - les cartes, les ventilateurs, les blocs d'alimentation, les processeurs, la mémoire, etc.
- s'il y a des problèmes dans les connexions entre les périphériques physiques entrant dans le réseau, y compris si les états des ports et le trafic sont normaux, la longueur des files d'attente et le coefficient d'atténuation optique, si le pourcentage de paquets «cassés» est trop élevé, etc.
- si l'agrégation M-LAG, le routage via OSPF, BGP, etc. fonctionnent;
- est tout bon avec l'infrastructure réseau imposée, y compris les états actuels de BD, VNI, VRF, EVPN et SRV6;
- si la redirection est effectuée régulièrement au niveau du service, et en particulier quels sont les paramètres de la connexion TCP.
Il y a deux technologies au cœur d'un service de surveillance intelligent. Le premier est le système de «jumeau numérique» mentionné précédemment, qui repose sur une modélisation virtuelle de la situation du réseau en temps réel à l'aide de big data, qui permet de suivre facilement les relations de cause à effet et de trouver des sources de difficultés. Pour mettre en œuvre ce mécanisme, il est essentiel de disposer d'un modèle unique pour répliquer le cycle de vie du réseau d'entreprise.
Le second est un ensemble de solutions front-end et back-end utilisées pour construire une carte de haute précision de l'activité du réseau, construite sur la base du concept de «jumeau numérique». La partie frontale comprend une recherche intelligente, des détails à plusieurs niveaux de rapports analytiques, une navigation par routage, un système de visualisation de données intégré, etc. Le backend est principalement un moteur de reproduction dynamique de la topologie du réseau et un système d'importation flexible de modèles de réseau tiers.

Le travail de surveillance intelligente est soutenu par l'utilisation d'une méthode d'analyse de réseau intelligente basée sur des graphiques de connaissances.
Grâce à la modélisation, les descriptions abstraites des éléments du réseau peuvent être traduites en requêtes concrètes dans le plan du modèle objet.
À l'aide de la télémétrie, des KPI réseau, des flux de trafic au niveau du service, des informations de configuration et des journaux d'événements réseau sont surveillés - et sur la base de ces informations, les algorithmes d'apprentissage automatique capturent les écarts par rapport à la norme à la volée et les corrélent avec les données du modèle objet.
En outre, la plate-forme iMaster NCE fournit un environnement pour travailler en toute sécurité sur les conséquences potentielles de toutes sortes de pannes: les problèmes survenus dans d'autres réseaux réels sont «testés» dans la simulation de ce réseau particulier. Ainsi, en recourant à l'expérience combinée d'experts qui parvenaient auparavant à faire face à certaines situations de réseau anormales, nous formons des modèles ML afin qu'ils aident encore plus efficacement à surmonter les excès - y compris en identifiant les modèles de nouveaux problèmes et en multipliant ainsi l'ensemble. connaissances disponibles pour toutes les entreprises utilisant le iMaster NCE.
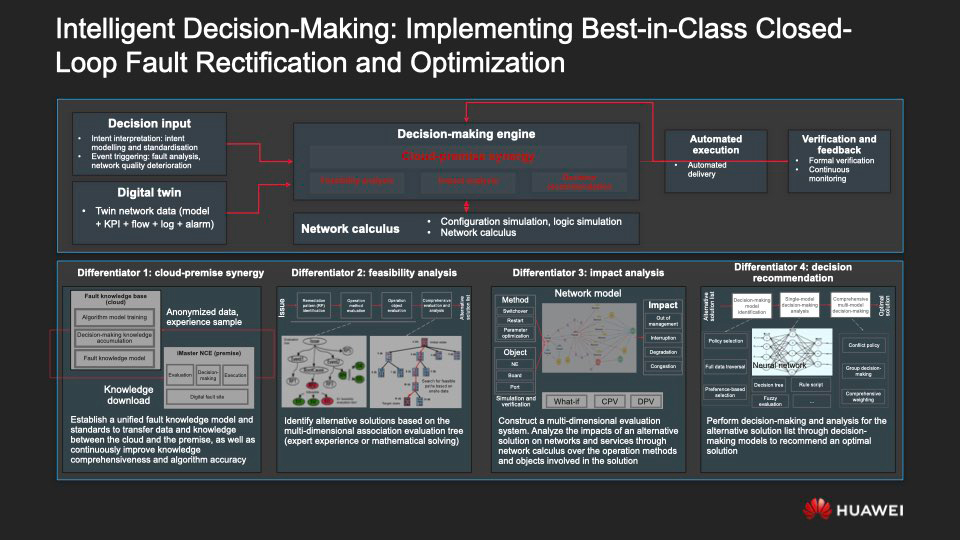
Les technologies répertoriées précédemment permettent à l'administrateur réseau de détecter rapidement les problèmes. Cependant, l'analyse intellectuelle ne suffit pas - il est important d'aider une personne à prendre les décisions les plus efficaces pour les surmonter, ce qui est l'essence même d'ADN: maintenant, ces décisions sont développées et mises en œuvre avec l'aide directe de l'IA.
La collecte des intentions et l'analyse des données sur ce qui se passe dans le réseau à la volée, la prise de décisions, leur mise en œuvre et l'analyse des conséquences de leur adoption forment une boucle fermée qui rend possible une prise de décision intelligente. Quatre facteurs sont essentiels à l'efficacité de ce modèle de travail.
- , : , on-premise cloud- ML-, iMaster NCE.
- . .
- . , , .
- . .
***
Les ingénieurs de Huawei continuent à améliorer les solutions ADN pour augmenter le degré d '"autosuffisance" de l'infrastructure réseau et sa capacité à "s'auto-guérir", et nous écrirons certainement sur les nouveaux développements dans ce sens. Et vous pouvez vous familiariser avec la solution d'iMaster NCE-Fabric en direct dans notre cloud de démonstration avec l'aide des ingénieurs de prévente Huawei.