
Très souvent, l'utilisation d'outils prêts à l'emploi dans le développement devient une solution sous-optimale. C'est donc arrivé avec nous. Pour gérer les pipelines de données, nous avons décidé de développer notre propre système - Wombat. Nous vous dirons ce qui en est issu et ce que nous a donné le refus d'utiliser la solution toute faite.
Pourquoi nous développons notre propre système
Créer votre propre système de gestion de pipeline de données n'est pas un choix évident. Aujourd'hui, il existe de nombreuses solutions toutes faites qui peuvent résoudre le problème: Airflow, MLflow, Kubeflow, Luigi et bien d'autres. Nous avons expérimenté plusieurs de ces systèmes et sommes arrivés à la conclusion qu'aucun d'entre eux ne nous convient.
Par exemple, considérons la solution la plus courante - Airflow. Il combine six blocs principaux: une API pour décrire les pipelines, un collecteur wokflow, un panneau de contrôle et des interfaces, un planificateur de tâches et un orchestrateur de tâches, et, enfin, la surveillance des composants Airflow. Mais pour gérer les pipelines, cette fonctionnalité n'était pas suffisante dans notre cas.
Pour nous, des fonctionnalités telles que l'intégration du système de gestion de pipeline avec le système de construction et le CI, l'intégration avec Kubernetes, la capacité à gérer les artefacts et la validation des données étaient essentielles.

Nous avons compris ce qu'il nous en coûterait pour développer la fonctionnalité du système fini au niveau requis et nous avons réalisé qu'il serait beaucoup plus facile et plus rapide de développer notre propre système. Nous l'avons appelé Wombat - parce que l'animal est très mignon, et deuxièmement, parce qu'il est considéré comme le sauveur de la nature australienne. Et pour nous, un système qui nous permettrait de combiner le développement et toutes les étapes de travail avec les données serait aussi un véritable salut.
Quels problèmes avons-nous résolus
Historiquement, dans notre équipe de développement, les ingénieurs DevOps soutiennent les services en production. Et ils sont habitués à travailler avec des pipelines, qui ne sont pas décrits par du code, mais par des configurations dans des formats comme yaml. En raison de cet écart, vous devez soit partager le support, soit former des ingénieurs à travailler avec un système d'intégration continue non classique.
Tout cela serait un travail redondant et inutile, car les pipelines sous forme de graphes acycliques dirigés sont parfaitement décrits dans le format utilisé dans les outils CI et DevOps standard.

Le deuxième problème auquel nous avons été confrontés était le stockage et la gestion des versions des artefacts. Travailler avec des artefacts dans le système de gestion du pipeline de données vous permet d'obtenir deux opportunités très utiles: réutiliser les résultats du travail avec des pipelines et reproduire des expériences avec des données, gagner du temps pour organiser de nouvelles expériences.
Si l'organisation du stockage des artefacts n'est pas automatisée, tôt ou tard, les nouveaux artefacts commenceront à écraser les anciens, ou l'espace libre commencera à s'épuiser sur les machines de production. De plus, la production devra appliquer des exigences spécifiques pour garantir la fiabilité et la tolérance aux pannes du stockage, ce qui est un autre processus coûteux.
Par conséquent, nous voulions obtenir une solution qui effectuerait toutes les tâches liées à la gestion des pipelines en arrière-plan, tout en permettant aux spécialistes des données de travailler avec des artefacts d'autres projets, et en même temps de ne pas penser au coût du stockage des données.
Le troisième problème est le typage des flux de données. Oui, Python vous permet de développer des prototypes et de tester diverses hypothèses à grande vitesse. Mais lorsque vous travaillez avec des données, vous devez faire attention aux types avec lesquels vous travaillez si vous ne voulez pas de surprises inattendues. Pour réduire le nombre de ces problèmes en production, nous avons besoin d'un support pour la description des schémas de données, jusqu'à la description des schémas de trames de données, et le typage des données doit être effectué séparément pour le développement et pour la production.
Ce qui est arrivé à la fin
Classiquement, l'architecture Wombat peut être représentée comme ceci:

Ce diagramme montre le rôle du système. C'est une couche intermédiaire entre la description des pipelines et le système CI, à l'aide de laquelle vous pouvez travailler avec eux en production.
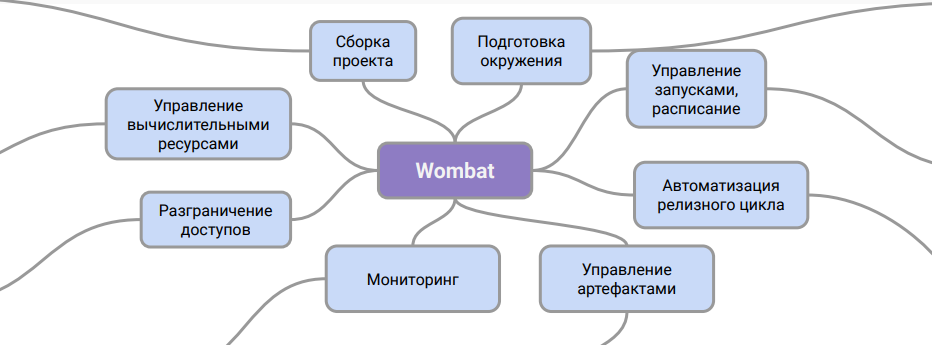
Grâce à ce schéma de travail, nous pouvons organiser le support des pipelines dans le département DevOps sans formation supplémentaire pour les ingénieurs et sans impliquer des spécialistes des données dans ce processus. En outre, le problème du stockage des artefacts de données et de leur gestion des versions est résolu.
Nous développons maintenant des fonctionnalités qui permettront d'introduire l'outil au stade précoce du prototypage et de l'expérimentation sous une forme native aux data scientists, ce qui accélérera considérablement le lancement de projets en pilote et en production.
Nous nous préparons à publier cet outil en open source dans un avenir très proche. Nous serons heureux si vous partagiez votre opinion sur notre projet et votre expérience de travail avec des systèmes de pipeline de données modernes.
De plus, sachant que cet article est de nature plus informative que technique, nous prévoyons dans un proche avenir de préparer un texte plus détaillé et plus hardcore. Écrivez dans les commentaires ce que vous aimeriez voir et découvrez en termes techniques. Nous prendrons en compte, décrirons et écrirons. Merci pour l'attention!
PS Nous sommes toujours intéressés par les programmeurs talentueux. Venez, ce sera intéressant !