
Il y a environ 10 ans, nous avons choisi Python 2 pour développer notre plateforme d'apprentissage monolithique. Mais l'industrie a radicalement changé depuis lors. Python 2 a été officiellement enterré le 1er janvier 2020. Dans l' article précédent , nous avons expliqué pourquoi nous avons décidé de ne pas migrer vers Python 3.
Des millions de personnes utilisent notre plateforme chaque mois.
Nous avons pris un certain risque lorsque nous avons décidé de réécrire notre backend en Go et de changer l'architecture.
Nous avons choisi Go pour plusieurs raisons:
- Vitesse de compilation élevée.
- Sauvegarde de la RAM.
- Une large sélection d'EDI avec prise en charge de Go.
Mais nous avons adopté une approche qui minimisait le risque.
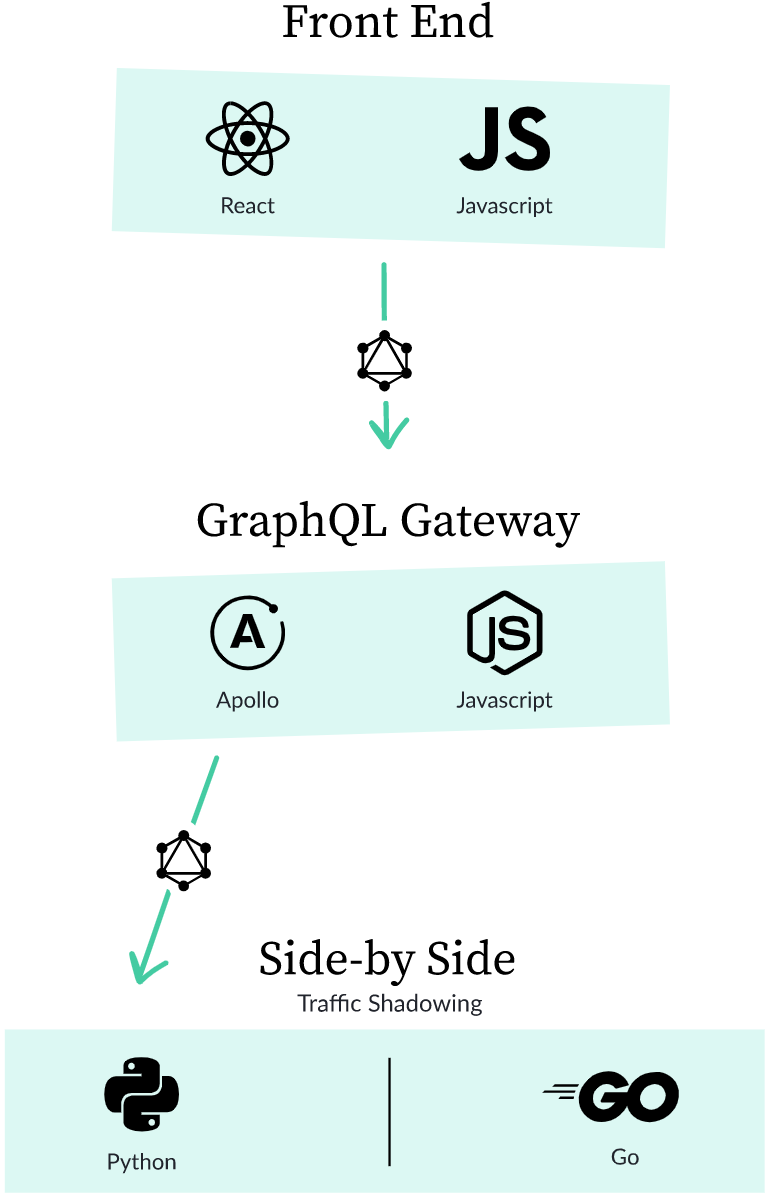
Fédération GraphQL
Nous avons décidé de construire notre nouvelle architecture autour de la Fédération GraphQL Apollo . GraphQL a été créé par les développeurs Facebook comme alternative à l'API REST. La fédération consiste à créer une passerelle unique pour plusieurs services. Chaque service peut avoir son propre schéma GraphQL. Une passerelle commune combine leurs schémas, génère une seule API et autorise les demandes de plusieurs services en même temps.
Avant d'aller plus loin, je voudrais souligner ce qui suit:
- Contrairement aux API REST, chaque serveur GraphQL possède son propre schéma de données typées. Il vous permet d'obtenir n'importe quelle combinaison d'exactement les données avec des champs arbitraires dont vous avez besoin.
- La passerelle API REST vous permet d'envoyer une requête à un seul service de backend; La passerelle GraphQL génère un plan de requête pour un nombre arbitraire de services backend et vous permet de renvoyer des sélections à partir de ceux-ci dans une seule réponse générique.
Donc, après avoir inclus la passerelle GraphQL dans notre système, nous obtenons quelque chose comme ceci:

URL de l' image: https://lh6.googleusercontent.com/6GBj9z5WVnQnhqI19oNTRncw0LYDJM4U7FpWeGxVMaZlP46IAIcKfYZKTtHcl-bDFomedAoxSa9pFo6pdhL2daxyWNX2ZKVQIgqIIBWHxnXEouzcQhO9_mdf1tODwtti5OEOOFeb
passerelle (aka le service graphql-passerelle) est responsable de la création et l' envoi de plan de requête GraphQL-requêtes à nos autres services - non seulement le monolithe. Nos services Go ont leurs propres schémas GraphQL. Nous utilisons gqlgen (il s'agit d'une bibliothèque GraphQL pour Go) pour générer des réponses aux requêtes .
Étant donné que la Fédération GraphQL fournit un schéma GraphQL commun et que la passerelle regroupe tous les schémas de service individuels en un seul, notre monolithe interagira avec lui comme n'importe quel autre service. C'est un point fondamental.
Ensuite, nous parlerons de la façon dont nous avons personnalisé le serveur Apollo GraphQL pour passer en toute sécurité de notre monolithe (Python) à une architecture de microservice (Go).
Tests côte à côte
GraphQL "pense" avec des ensembles d'objets et des champs de certains types. Le code qui sait quoi faire avec la requête entrante, comment et quelles données extraire des champs est appelé un résolveur.
Considérons le processus de migration en utilisant un exemple du type de données pour les affectations:
| 123 | Affectation de type {createdDate: Time ……….} |
Il est clair qu'en réalité nous avons beaucoup plus de champs, mais pour chaque champ, tout se ressemblera.
Disons que nous voulons que ce champ monolithique soit représenté dans notre nouveau service écrit en Go. Comment être sûr que le nouveau service à la demande renverra les mêmes données que le monolithe? Pour ce faire, nous utilisons une approche similaire à la bibliothèque Scientist : nous demandons des données à la fois au monolithe et au nouveau service, puis comparons les résultats et n'en retournons qu'un seul.
Étape 1: mode manuel
Lorsque l'utilisateur demande la valeur du champ createdDate, notre passerelle GraphQL accède d'abord au monolithe (qui est écrit en Python, rappelez-vous).
Dans un premier temps, nous devons nous assurer que le champ peut être ajouté au nouveau service d'affectations déjà écrit dans Go. Le fichier avec l'extension .graphql doit contenir le code de résolution suivant:
| 12345 | étendre l'affectation de type clé(champs: "id") {id: ID! externe createdDate: Time @migrate (from: "python", state: "manual")} |
Ici, nous utilisons Federation pour dire que le service ajoute un champ createdDate au type d'affectation. Le champ est accessible par id. Nous ajoutons également un "ingrédient secret" - la directive migrate. Nous avons écrit du code qui comprend ces directives et crée plusieurs schémas que la passerelle GraphQL utilisera pour décider de router une requête.
En mode manuel, la requête ne sera adressée qu'au code monolithique. Nous devons considérer cette possibilité lors du développement d'un nouveau service. Pour obtenir la valeur du champ createdDate, on peut toujours accéder directement au monolithe (en mode primaire), ou on peut interroger la passerelle GraphQL pour le schéma en mode manuel. Les deux options devraient fonctionner.
Étape 2: mode côte à côte
Après avoir écrit le code du résolveur pour le champ createdDate, nous le basculons en mode côte à côte:
| 12345 | étendre l'affectation de type clé(champs: "id") {id: ID! externe createdDate: Time @migrate (from: "python", state: "side-by-side")} |
Et maintenant, la passerelle accédera à la fois au monolithe (Python) et au nouveau service (Go). Il comparera les résultats, enregistrera les cas où il y a des différences et retournera le résultat du monolithe à l'utilisateur.
Ce mode instille vraiment beaucoup de confiance dans le fait que notre système ne sera pas bogué pendant le processus de migration. Au fil des ans, des millions d'utilisateurs et des «kilotonnes» de données sont passés par notre frontend et notre backend. En observant le fonctionnement de ce code dans des conditions réelles, nous pouvons nous assurer que même les cas rares et les valeurs aberrantes aléatoires sont capturés puis traités de manière stable et correcte.
Lors des tests, nous recevons de tels rapports.

Essayez d'agrandir cette image pendant la mise en page d'une manière ou d'une autre sans une forte perte de qualité.
Ils se concentrent sur les cas où des écarts sont constatés dans le fonctionnement du monolithe et du nouveau service.
Au début, nous avons souvent rencontré de tels cas. Au fil du temps, nous avons appris à identifier ces problèmes, à en évaluer la gravité et, si nécessaire, à les éliminer.
Lorsque nous travaillons avec nos serveurs de développement, nous utilisons des outils qui mettent en évidence les différences de couleur. Cela facilite l'analyse des problèmes et les solutions de test.
Et les mutations?
Vous vous demandez peut-être si nous exécutons la même logique en Python et en Go, qu'advient-il du code qui modifie les données, plutôt que de simplement l'interroger? En termes GraphQL, c'est ce qu'on appelle la mutation.
Nos tests côte à côte ne prennent pas en compte les mutations. Nous avons examiné certaines des approches pour y parvenir - elles se sont avérées plus complexes que nous ne le pensions. Mais nous avons développé une approche qui permet de résoudre le problème même des mutations.
Étape 2.5: mode canari
Si nous avons un champ ou une mutation qui a survécu avec succès à l'étape de production, nous activons le mode canari.
| 12345 | étendre l'affectation de type clé(champs: "id") {id: ID! externe createdDate: Heure @migrate (de: "python", état: "canary")} |
Les champs et mutations Canary seront ajoutés au service Go pour un petit pourcentage de nos utilisateurs. De plus, les utilisateurs internes de la plate-forme testent le schéma Canary. C'est un moyen assez sûr de tester des changements complexes. Nous pouvons rapidement désactiver le circuit canari si quelque chose ne fonctionne pas comme prévu.
Nous n'utilisons qu'un seul circuit canari à la fois. En pratique, peu de champs et de mutations sont en mode canari en même temps. Donc, je pense qu'il n'y aura pas de problèmes à l'avenir. C'est un bon compromis car le schéma est assez volumineux (plus de 5000 champs) et les instances de passerelle doivent stocker trois schémas en mémoire - primaire, manuel et canary.
Étape 3: mode migré
Dans cette étape, le champ createdDate doit être en mode migré:
| 12345 | étendre l'affectation de type clé(champs: "id") {id: ID! externe createdDate: Heure @migrate (à partir de: "python", état: "migré")} |
Dans ce mode, la passerelle GraphQL envoie uniquement des requêtes à un nouveau service écrit en Go. Mais à tout moment, nous pouvons voir comment le monolithe traitera la même demande. Cela facilite beaucoup le déploiement et la restauration des modifications en cas de problème.
Étape 4: Terminer la migration
Après un déploiement réussi, nous n'avons plus besoin du code monolithique pour ce champ, et nous supprimons la directive @migrate du code du résolveur:
À partir de maintenant, la passerelle interprétera l'expression Assignment.createdDate comme obtenant une valeur de champ à partir d'un nouveau service écrit en Go.
Voilà comment la migration incrémentielle est!
Et jusqu'où sommes-nous allés?
Nous avons terminé notre infrastructure de test côte à côte cette année seulement. Cela nous a permis de réécrire en toute sécurité, lentement mais sûrement un tas de code Go. Tout au long de l'année, nous avons maintenu la haute disponibilité de la plateforme dans un contexte de trafic croissant dans notre système. Au moment d'écrire ces lignes, ~ 40% de nos champs GraphQL sont déplacés vers les services Go. Ainsi, l'approche que nous avons décrite a bien fonctionné dans le processus de migration.
Même une fois le projet terminé, nous pouvons continuer à utiliser cette approche pour d'autres tâches liées à la modification de notre architecture.
PS Steve Coffman a donné une conférence sur ce sujet (sur Google Open Source Live ). Vous pouvez regarder l' enregistrementcette conférence YouTube (ou regardez simplement la présentation ).
Les serveurs cloud de Macleod sont rapides et sécurisés.
Inscrivez-vous en utilisant le lien ci-dessus ou en cliquant sur la bannière et bénéficiez d'une remise de 10% pour le premier mois de location d'un serveur de toute configuration!
