
Salutations, chers amis! Je m'appelle Alexey, je suis développeur de production RH. Dans cet article, je propose de discuter des moyens de journaliser Hebernate.
Hibernate est un excellent outil pour faire le travail, surtout quand il fonctionne rapidement et bien, mais lorsque des problèmes surviennent, vous devez regarder ce qui se passe sous le capot. Des exemples de configuration seront fournis au printemps.
Le premier et le plus simple moyen
Précisez dans application.properties: spring.jpa.show-sql=true
ouspring.jpa.properties.hibernate.show_sql=true).
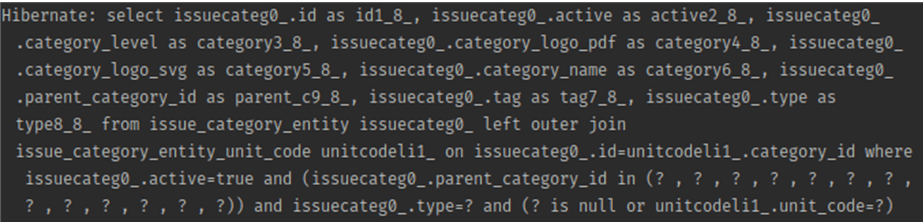
Cette approche vous permet de résoudre rapidement le problème et d'aider à trouver les bogues localement. Mais il y a deux inconvénients évidents :
1. La sortie SQL ne passe pas par notre enregistreur et n'a pas de format pratique pour nous.
2. .
— properties,
logging.level.org.hibernate.SQL=DEBUG
logging.level.org.hibernate.type.descriptor.sql.BasicBinder=TRACE

, . , .
— proxy
log4jdbc p6spy. , log4jdbc .
<groupId>com.integralblue</groupId>
log4jdbc-spring-boot-starter
<groupId>com.github.gavlyukovskiy</groupId>
p6spy-spring-boot-starter
, . : , . p6spy.
- .
decorator.datasource.p6spy.log-filter.pattern=.*insert.*
insert .
. . :

En fait, nous devons filtrer les journaux requis par un attribut. J'ai décidé de le faire en utilisant MDC, sa portée est juste ThreadLocal, ce qui nous convient. Faisons un filtre :

J'ai fait le processeur d'annotation à travers un aspect :

Eh bien, la configuration utilisant l'exemple de Logback :

Créons un appender supplémentaire avec un filtre et passons les journaux p6spy du niveau info à travers celui-ci et n'oublions pas de spécifier additivity = "false" pour que l'appender root ne traite pas le même package. C'est tout. N'oubliez pas que nous l'avons fait via un proxy, ce qui signifie que nous avons des limitations dans le choix des méthodes sur lesquelles nous pouvons mettre une nouvelle annotation.
C'est tout. L'espoir a été utile !