1. Introduction
Lors de la réalisation d'études d'ingénierie et géologiques, une tâche peut survenir liée à la comparaison des données d'études sur le terrain et en laboratoire sur les mêmes sols afin de confirmer le transport correct des échantillons de l'objet d'étude au laboratoire (les échantillons n'ont pas été déformés et / ou détruits pendant le transport).
Avec cette formulation du problème, vous pouvez appliquer la technique de test A/B avec les paramètres suivants :
La métrique mesurée sera la valeur moyenne de la densité du squelette du sol (p d , g / cm 3 ), qui caractérise l'addition des échantillons. Cette valeur a une loi de distribution normale ;
Le critère pour tester l'hypothèse sera le test t (test de Student) : pour deux échantillons indépendants , si les données de terrain (avant transport) et de laboratoire (après transport) comparées ont été réalisées sur des échantillons de sol différents ; pour deux échantillons dépendants , si les études ont été réalisées sur les mêmes échantillons.
Dans le cadre de ce thème, nous générerons deux échantillons aléatoires, que nous comparerons, formulerons des hypothèses statistiques, les testerons et tirerons des conclusions.
2. Génération d'échantillons
2.1 Estimation de la taille de l'échantillon
, , (ES - effect size), (power) I (α) ( ). statsmodels.
() – , , , . :


Spooled c :

(Cohen, 1988) ES = 0.2 - ; 0.5 - ; 0.8 - .
– II ( 80%).
I II :
H0 |
H1 |
|
|---|---|---|
H0 |
H0 |
II (β) |
H0 |
I (α) |
H0 (power = 1-β) |
:
α = 0.05 ( )
ES = 0.5 ( ).
Power = 0.8 ( ).
:
#
import numpy as np
from statsmodels.stats.power import TTestIndPower
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
import scipy
from statsmodels.stats.weightstats import *
#
effect = 0.5
alpha = 0.05
power = 0.8
analysis = TTestIndPower()
#
size = analysis.solve_power(effect, power=power, alpha=alpha)
print(f' , .: {int(size)}')
, .: 63
, 63 . 65 .
.
plt.figure(figsize=(10, 7), dpi=80)
results = dict((i/10, analysis.solve_power(i/10, power=power, alpha=alpha))
for i in range(2, 16, 1))
plt.plot(list(results.keys()), list(results.values()), 'bo-')
plt.grid()
plt.title(' \n ')
plt.ylabel(' n, .')
plt.xlabel(' ES, ..')
for x,y in zip(list(results.keys()),list(results.values())):
label = "{:.0f}".format(y)
plt.annotate(label,
(x,y),
textcoords="offset points",
xytext=(0,10),
ha='center')
plt.show()
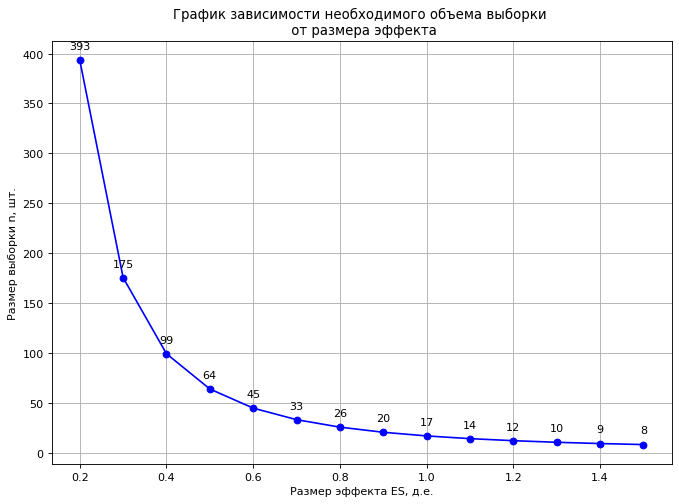
, ES. : 0,03 /3 0,1 /c3 (ES = 0,03 /3 / 0,1 /3 = 0,3 ..), 175 (power=0.80, α=0.05).
2.2
, numpy.
( ) . (X̄) (S):
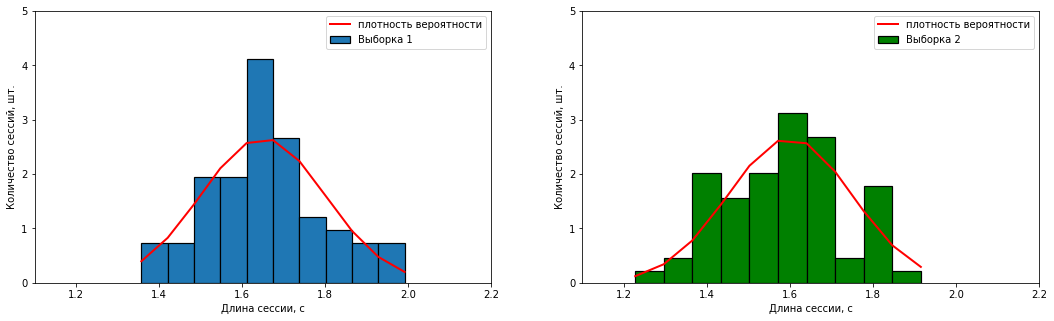
– X̄1= 1,65 /3, S1 = 0.15 /3;
– X̄2 = 1,60 /3, S2 = 0.15 /3.
loc_1 = 1.65
sigma_1 = 0.15
loc_2 = 1.60
sigma_2 = 0.15
sample_size = 65
#
sample_1 = np.random.normal(loc=loc_1, scale=sigma_1, size=sample_size)
sample_2 = np.random.normal(loc=loc_2, scale=sigma_2, size=sample_size)
" " .
fig, axes = plt.subplots(ncols=2, figsize=(18, 5))
max_y = np.max(np.hstack([sample_1,sample_2]))
# 1
count_1, bins_1, ignored_1 = axes[0].hist(sample_1, 10, density=True,
label=" 1", edgecolor='black',
linewidth=1.2)
axes[0].plot(bins_1, 1/(sigma_1 * np.sqrt(2 * np.pi)) *
np.exp( - (bins_1 - loc_1)2 / (2 * sigma_12)),
linewidth=2, color='r', label=' ')
axes[0].legend()
axes[0].set_xlabel(u' , ')
axes[0].set_ylabel(u' , .')
axes[0].set_ylim([0, 5])
axes[0].set_xlim([1.1, 2.2])
# 2
count_2, bins_2, ignored_2 = axes[1].hist(sample_2, 10, density=True,
label=" 2", edgecolor='black',
linewidth=1.2, color="green")
axes[1].plot(bins_2, 1/(sigma_2 * np.sqrt(2 * np.pi)) *
np.exp( - (bins_2 - loc_2)2 / (2 * sigma_22)),
linewidth=2, color='r', label=' ')
axes[1].legend()
axes[1].set_xlabel(u' , ')
axes[1].set_ylabel(u' , .')
axes[1].set_ylim([0, 5])
axes[1].set_xlim([1.1, 2.2])
plt.show()
#
fig, ax = plt.subplots(figsize=(8, 8))
axis = ax.boxplot([sample_1, sample_2], labels=[' 1', ' 2'])
data = np.array([sample_1, sample_2])
means = np.mean(data, axis = 1)
stds = np.std(data, axis = 1)
for i, line in enumerate(axis['medians']):
x, y = line.get_xydata()[1]
text = ' μ={:.2f}\n σ={:.2f}'.format(means[i], stds[i])
ax.annotate(text, xy=(x, y))
plt.ylabel(' , /3')
plt.show()
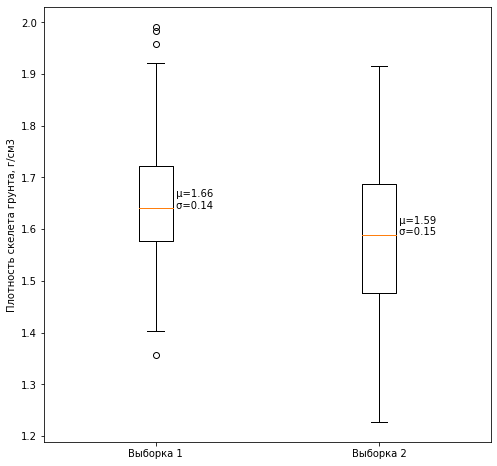
3.
. :
1. , t- ;
2. , t- .
.
1.
.
H0: μ1 = μ2.
H1: μ1≠μ2.
:

: T(X1n1,X2n2)≈~St(ν), ν

ttest_ind stats.
t_st, p_val = scipy.stats.ttest_ind(sample_1, sample_2, equal_var = False)
print(f't- {round(t_st, 2)}')
print(f' t- \
(p-value) {round(p_val, 3)}')
t- 2.92
t- (p-value) 0.004
№ 1
H0 , , 0,05 ( p-value 0.004) .
.
c_m = CompareMeans(DescrStatsW(sample_1), DescrStatsW(sample_2))
print("95%% : \
[%.4f, %.4f]" % c_m.tconfint_diff(usevar='unequal'))
95% : [0.0235, 0.1228]
95% , , 5%.
2.
, ( ) ( ) . , .
H0: μ1 = μ2.
H1: μ1≠μ2.
:


: T(X1n, X2n) ~ St(n-1)
ttest_rel stats.
t_st, p_val = stats.ttest_rel(sample_1, sample_2)
print(f't- {round(t_st, 2)}')
print(f' t- \
(p-value) {round(p_val, 3)}')
t- 2.79
t- (p-value) 0.007
№ 2
H0 , , 0,05 ( p-value 0.007).
Pour plus de clarté, estimons également l'intervalle entre les moyennes de ces échantillons.
print("95%% confidence interval: [%.4f, %.4f]"
% DescrStatsW(sample_1 - sample_2).tconfint_mean())
Intervalle de confiance à 95 % : [0,0208, 0,1255]
Étant donné que zéro ne tombe pas dans l'intervalle de confiance à 95% considéré, nous pouvons conclure que les valeurs moyennes des échantillons considérés diffèrent.
5. Résultat
Dans cet article, nous avons examiné la possibilité d'utiliser le langage Python pour résoudre un problème pratique en géologie de l'ingénieur, accompagné d'une étude sur la question de la taille d'échantillon requise pour tester des hypothèses.