
Dans cet article, je vais parler d'une des méthodes pour corriger le déséquilibre des classes prédites. Il est important de préciser que bon nombre des méthodes qui construisent des modèles probabilistes fonctionnent correctement sans corriger le déséquilibre. Cependant, lorsque l'on passe à la construction de modèles d'improbabilité ou lorsque l'on considère un problème de classification avec un grand nombre de classes, il vaut la peine de s'occuper du problème du déséquilibre des classes.
, ́ , , , . , .
NearMiss — . ́ . , .
. pip cmd:
pip install pandas
pip install numpy
pip install sklearn
pip install imblearn
, - -.
import pandas as pd
import numpy as np
df = pd.read_csv('online_shoppers_intention.csv')
df.shape
(12330, 18)
«Revenue» 2 : True ( ) False ( ). , .
df['Revenue'].value_counts()
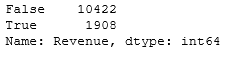
, , 85% 15%.
:
Y = df['Revenue']
X = df.drop('Revenue', axis = 1)
feature_names = X.columns
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.3, random_state = 97)
:
print(' X_train: ', X_train.shape)
print(' Y_train: ', Y_train.shape)
print(' X_test: ', X_test.shape)
print(' Y_test: ', Y_test.shape)

.
from sklearn.linear_model import LogisticRegression
lregress1 = LogisticRegression()
lregress1.fit(X_train, Y_train.ravel())
prediction = lregress1.predict(X_test)
print(classification_report(Y_test, prediction))
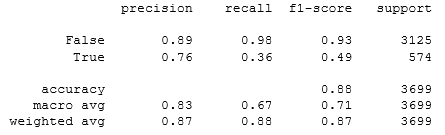
, 88%. «recall» , . , , .
NearMiss :
print(' - True: {}'.format(sum(y_train == True)))
print(' - False: {}'.format(sum(y_train == False)))
True: 1334
False: 7297
.
from imblearn.under_sampling import NearMiss
nm = NearMiss()
X_train_miss, Y_train_miss = nm.fit_resample(X_train, Y_train.ravel())
print(' - True: {}'.format(sum(Y_train_miss == True)))
print(' - False: {}'.format(sum(Y_train_miss == False)))
True: 1334
False: 1334
On voit que la méthode a nivelé les classes, diminuant la dimension de la classe dominante. Utilisons la régression logistique et affichons un rapport avec les principaux indicateurs de classification.
lregress2 = LogisticRegression()
lregress2.fit(X_train_miss, Y_train_miss.ravel())
prediction = lregress2.predict(X_test)
print(classification_report(Y_test, prediction))

La valeur des avis minoritaires est passée à 84 %. Mais en raison du fait que l'échantillon de la plus grande classe a été considérablement réduit, la précision du modèle a diminué à 61 %. Cette méthode a donc vraiment aidé à gérer le déséquilibre des classes.