
Robot factory de lucart
MLflow est l'un des outils les plus stables et les plus légers pour permettre aux scientifiques des données de gérer le cycle de vie des modèles d'apprentissage automatique. Il s'agit d'un outil convivial avec une interface simple pour visualiser les expériences et des outils puissants pour la gestion du packaging, le déploiement des modèles. Il vous permet de travailler avec presque toutes les bibliothèques d'apprentissage automatique.
Je suis Alexander Volynsky, architecte de la plateforme cloud Mail.ru Cloud Solutions. Dans le dernier article, nous avons couvert Kubeflow. MLflow est un autre outil pour créer des MLOps qui ne nécessite pas que Kubernetes fonctionne.
J'ai parlé des MLOps en détail dans le dernier article, maintenant je ne mentionnerai que brièvement les thèses principales.
- MLOps signifie Machine Learning DevOps.
- Aide à standardiser le processus de développement de modèles d'apprentissage automatique.
- Réduit le temps nécessaire pour déployer les modèles en production.
- Comprend des tâches pour le suivi des modèles, la gestion des versions et la surveillance.
Tout cela permet aux entreprises de tirer plus de valeur des modèles d'apprentissage automatique.
Ainsi, au cours de cet article, nous :
- Déployons des services dans le cloud qui agissent comme un backend pour MLflow.
- Installez et configurez MLflow Tracking Server.
- Déployons JupyterHub et configurons-le pour qu'il fonctionne avec MLflow.
- Nous testerons l'enregistrement manuel et automatique des paramètres et des métriques des expériences.
- Essayons différentes manières de publier des modèles.
Il est important que nous le fassions le plus près possible de la version de production. La plupart des instructions sur Internet suggèrent de déployer MLflow sur une machine locale ou à partir d'une image docker. Ces options sont parfaites pour la familiarisation et l'expérimentation rapide, mais pas pour la production. Nous utiliserons des services cloud fiables.
Si vous préférez les didacticiels vidéo, vous pouvez regarder le webinaire « MLflow in the Cloud. Un moyen simple et rapide de mettre en production des modèles de ML ."
MLflow : objectif et principaux composants
MLflow est une plate-forme open source pour la gestion du cycle de vie des modèles d'apprentissage automatique. Il résout également les problèmes de reproduction d'expériences, de publication de modèles et comprend un registre central de modèles.
Contrairement à Kubeflow, MLflow peut s'exécuter sans Kubernetes. Mais en même temps, MLflow sait comment empaqueter les modèles dans des images Docker afin qu'ils puissent ensuite être déployés sur Kubernetes.
MLflow se compose de plusieurs composants.
Suivi MLflow... Il s'agit d'une interface utilisateur pratique où vous pouvez afficher des artefacts : graphiques, exemples de données, ensembles de données. Vous pouvez également afficher les métriques et les paramètres des modèles. MLflow Tracking dispose d'une API pour différents langages de programmation, avec laquelle vous pouvez enregistrer des métriques, des paramètres et des artefacts. Python, Java, R, REST sont pris en charge.
Il existe deux concepts importants dans MLflow Tracking : les exécutions et les expériences.
- Run est une itération unique de l'expérience. Par exemple, vous définissez les paramètres du modèle et l'exécutez pour l'entraînement. Pour ce lancement unique, une nouvelle entrée apparaîtra dans MLflow Tracking. Lorsque les paramètres du modèle changent, une nouvelle exécution sera créée.
- Experiment vous permet de regrouper plusieurs Runs en une seule entité afin de pouvoir les visualiser facilement.
Vous pouvez déployer MLflow Tracking dans divers scénarios. Nous utiliserons la variante la plus proche de la production - le scénario n°4 (comme il est appelé dans la documentation officielle de MLflow ).
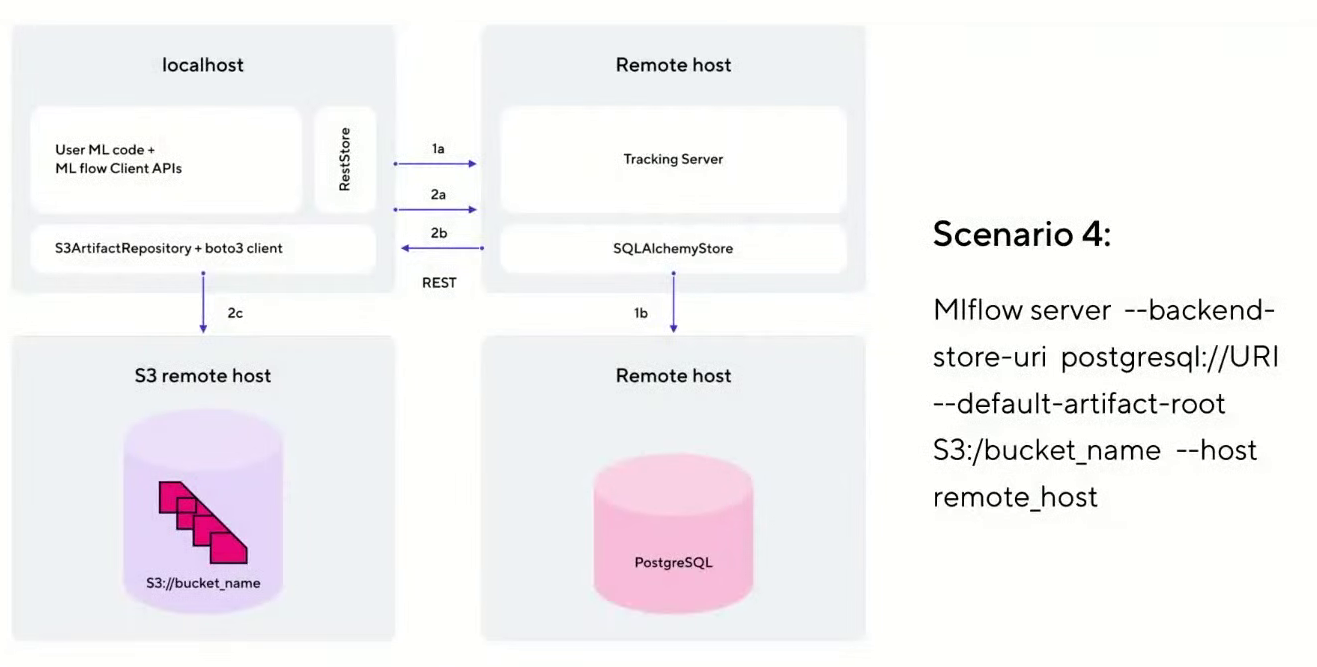
Cette option a un hôte sur lequel JupyterHub est déployé. Il communique avec le serveur de suivi hébergé sur une machine virtuelle distincte dans le cloud. Pour stocker les métadonnées sur les expériences, PostgreSQL est utilisé, que nous déploierons en tant que service dans le cloud. Et tous les artefacts et modèles sont stockés séparément dans S3 Object Storage.
Modèles MLflow . Ce composant est responsable de l'emballage, du stockage et de la publication des modèles. Il représente le concept de saveur. Il s'agit d'une sorte de wrapper qui vous permet d'utiliser le modèle dans divers outils et frameworks sans avoir besoin d'intégrations supplémentaires. Par exemple, vous pouvez utiliser des modèles de Scikit-learn, Keras, TenserFlow, Spark MLlib et d'autres frameworks.
MLflow Models vous permet également de rendre des modèles disponibles via l'API REST et de les emballer dans une image Docker pour une utilisation ultérieure dans Kubernetes.
Registre MLflow . Ce composant est le référentiel central des modèles. Il comprend une interface utilisateur qui vous permet d'ajouter des balises et des descriptions pour chaque modèle. Il vous permet également de comparer différents modèles entre eux, par exemple, pour voir les différences de paramètres.
MLflow Registry gère le cycle de vie d'un modèle. Dans le contexte de MLflow, il existe trois étapes de cycle de vie : la préparation, la production et l'archivage. Il existe également un support pour la gestion des versions. Tout cela vous permet de gérer facilement l'ensemble du déploiement des modèles.
Projets MLflow... C'est une façon d'organiser et de décrire votre code. Chaque projet est un répertoire avec un ensemble de fichiers, le plus souvent ce sont des pipelines. Chaque projet est décrit par un fichier MLProject distinct au format yaml. Il spécifie le nom du projet, l'environnement et les points d'entrée. Cela permet de reproduire l'expérience dans un environnement différent. Il existe également une CLI et une API pour Python.
Avec MLflow Projects, vous pouvez créer des modules qui sont des étapes réutilisables. Ces modules peuvent ensuite être embarqués dans des pipelines plus complexes, permettant leur standardisation.
Instructions pour l'installation et la configuration de MLflow
Étape 1 : déployer des services dans le cloud qui agissent comme un backend
Tout d'abord, nous allons créer une machine virtuelle sur laquelle nous allons déployer MLflow Tracking Server. Nous le ferons sur notre plate-forme cloud Mail.ru Cloud Solutions (les nouveaux utilisateurs reçoivent ici 3000 roubles bonus pour les tests, vous pouvez donc vous inscrire et répéter tout ce qui est décrit ici).
Avant de commencer à travailler, vous devez configurer le réseau, générer et télécharger une clé SSH pour vous connecter à la machine virtuelle. Vous pouvez configurer le réseau vous-même selon les instructions .
Allez dans le panneau MCS, section « Cloud Computing - Virtual Machines », et cliquez sur le bouton « Add ». Ensuite, nous définissons les paramètres de la nouvelle machine virtuelle. A titre d'exemple, nous prendrons une configuration avec 4 CPU et 8 Go de RAM. Choisissons le système d'exploitation - Ubuntu 18.04.
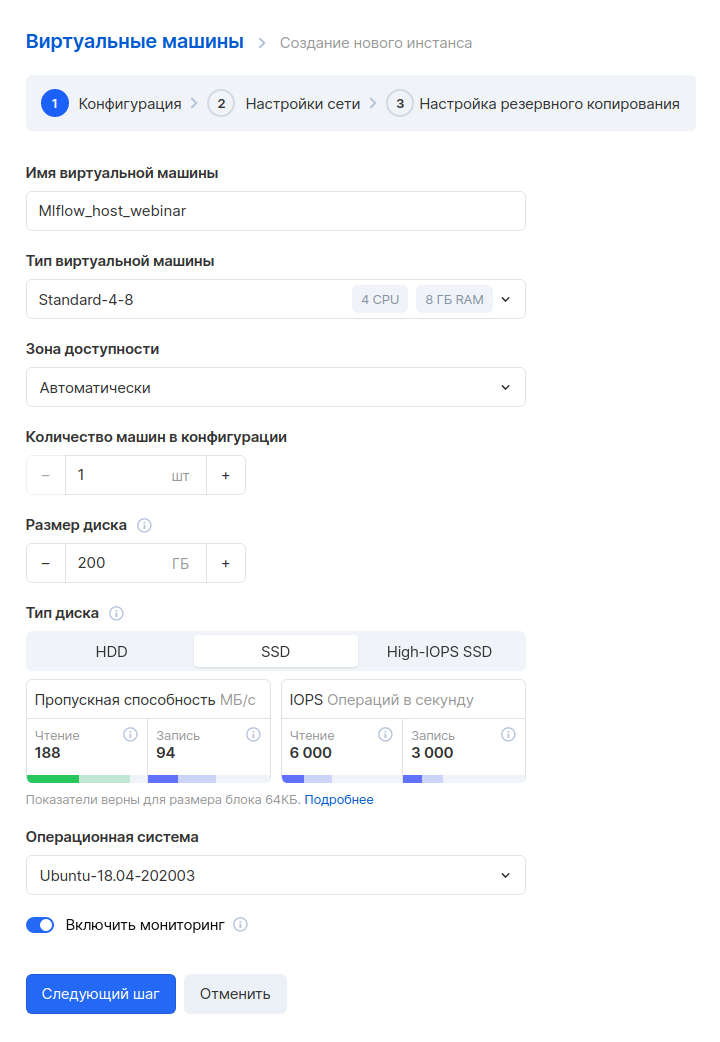
L'étape suivante consiste à configurer le réseau. Puisque nous avons déjà créé un réseau à l'avance, il vous suffit ici de le sélectionner. Veuillez noter qu'une règle personnalisée est spécifiée dans les paramètres du pare-feu - only_my_ip. Cette règle est absente par défaut, nous l'avons créée nous-mêmes pour que seule une adresse spécifique puisse se connecter à une machine virtuelle. Nous vous recommandons de faire de même pour améliorer la sécurité. Voici comment créer vos propres règles.
Vous devez également attribuer une adresse IP externe pour pouvoir vous connecter à la machine depuis Internet.
Dans l'étape suivante, nous configurons une sauvegarde. Vous pouvez laisser les paramètres par défaut si vous le souhaitez.
Nous créons une instance et attendons quelques minutes. Lorsque la machine virtuelle sera prête, vous devrez noter ses adresses internes et externes, elles vous seront utiles plus tard.

Ensuite, créons une base de données. Allez dans la section " Bases de données " et cliquez sur le bouton " Ajouter ". Nous sélectionnons PostgreSQL 12 dans la configuration maître-esclave.
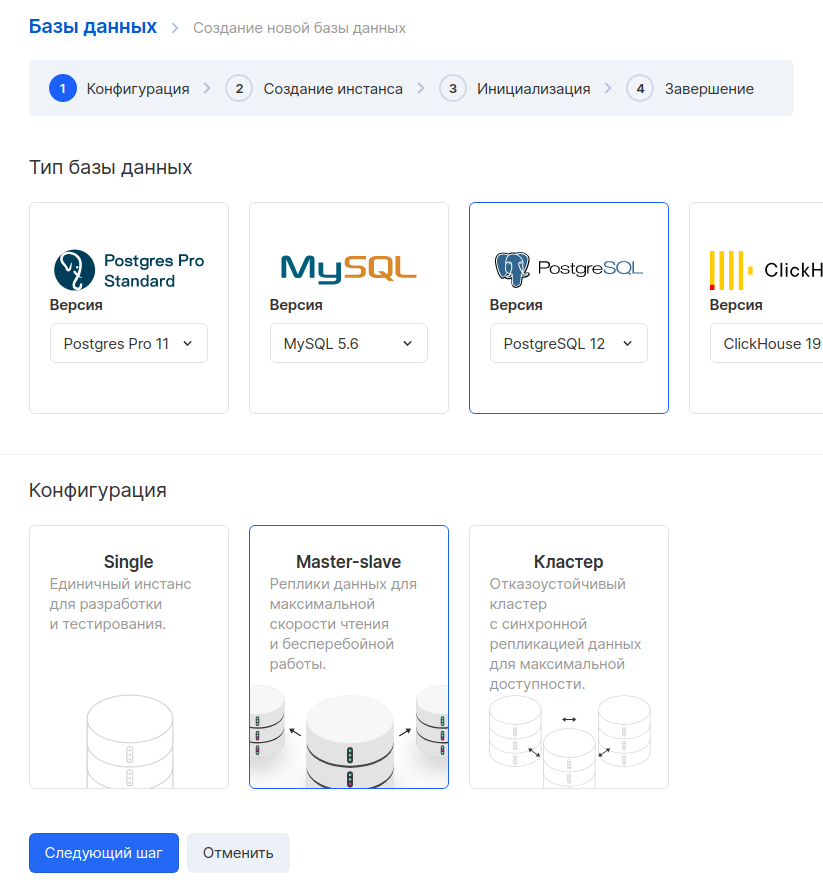
Dans l'étape suivante, nous définissons les paramètres de la machine virtuelle. A titre d'exemple, nous avons pris une configuration avec 1 CPU et 2 Go de RAM. L'adresse IP externe peut être omise, car nous n'accéderons à cette machine qu'à partir du réseau interne. Il est important de sélectionner le même réseau que celui que nous avons choisi pour la VM du serveur de suivi.

L'étape suivante consiste à générer un nom de base de données, un utilisateur et un mot de passe. Il est recommandé de créer une base de données distincte et un utilisateur distinct pour chaque service.
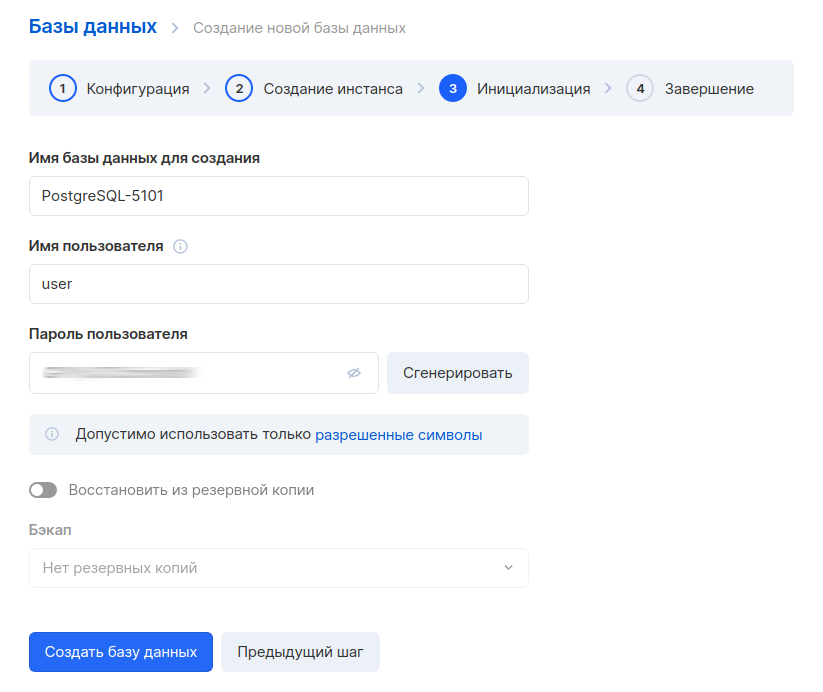
Après avoir créé la base de données, vous devez également noter l'adresse interne. Vous en aurez besoin pour établir une connexion à MLflow.
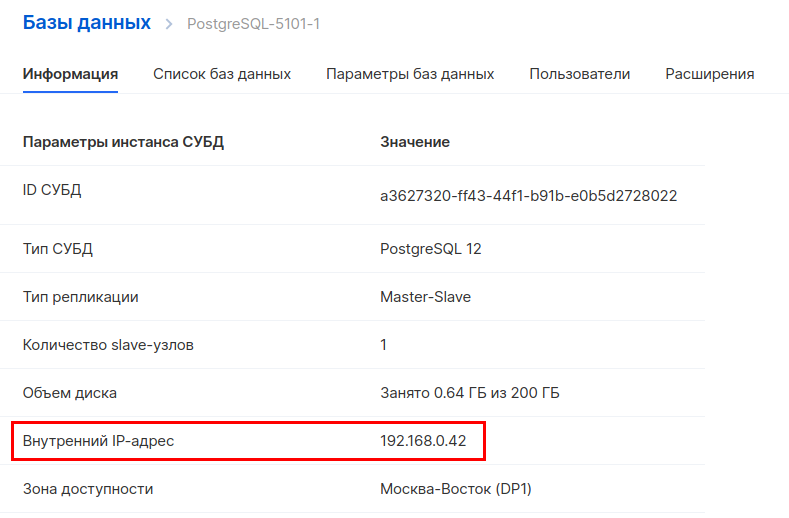
Ensuite, vous devez créer un nouveau compartiment dans le stockage d'objets. Allez dans la section " Object Storage - Buckets " et créez un nouveau bucket. Lors de la création, spécifiez le nom et le type - Hotbox.

Créez un répertoire à l'intérieur du bucket. Pour ce faire, allez-y et cliquez sur "Créer un dossier". Par défaut, l'instruction MLflow utilise le nom du dossier des artefacts, nous utiliserons donc le même nom.
Ensuite, vous devez créer un compte distinct pour accéder à ce compartiment. Dans la section "Stockage d'objets", allez dans la sous - section " Comptes " et cliquez sur "Ajouter un compte".
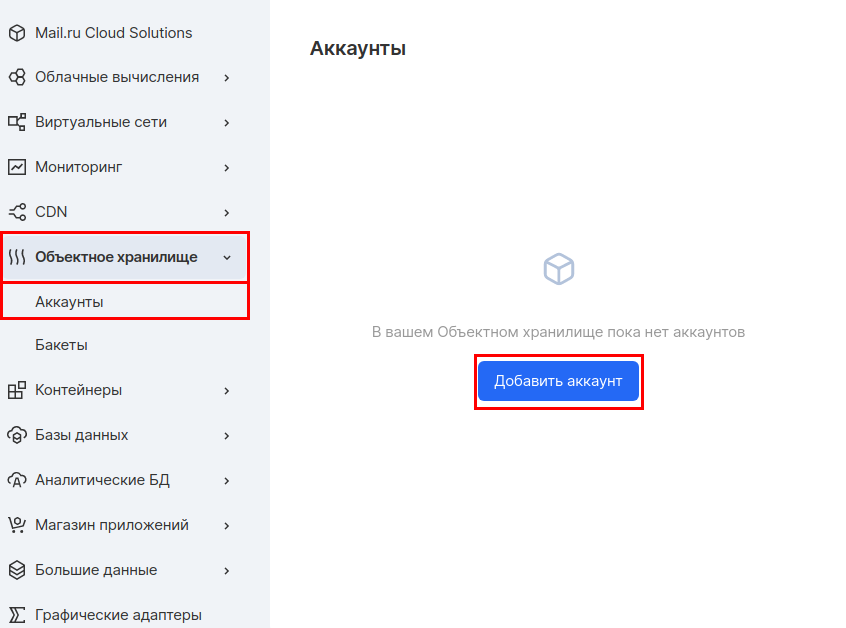
Nous utiliserons le nom du compte - mlflow_webinar. Après la création, notez l'ID de clé d'accès et la clé secrète. La Clé secrète est particulièrement importante, car elle ne sera plus visible, et en cas de perte, vous devrez la recréer.

Ça y est, nous avons préparé l'infrastructure pour le backend.
Tous les services sont dans un réseau virtuel. Par conséquent, pour la communication entre eux, nous utiliserons des adresses internes partout. Si vous souhaitez utiliser des adresses externes, vous devez configurer correctement le pare-feu.
Étape 2 : installer et configurer MLflow Tracking Server sur une VM dédiée
Nous nous connectons via SSH à la machine virtuelle que nous avons créée au tout début. Voici comment procéder.
Tout d'abord, installons conda , qui est un gestionnaire de packages pour Python, R et d'autres langages.
curl -O https://repo.anaconda.com/archive/Anaconda3-2020.11-Linux-x86_64.sh
bash Anaconda3-2020.11-Linux-x86_64.sh
exec bash
Ensuite, créons et activons un environnement distinct pour MLflow.
conda create -n mlflow_env conda activate mlflow_env
Installez les bibliothèques requises :
conda install python pip install mlflow pip install boto3 sudo apt install gcc pip install psycopg2-binary
Ensuite, vous devez créer des variables d'environnement pour accéder à S3. Ouvrez le fichier pour l'éditer :
sudo nano /etc/environment
Et nous y définissons des variables. Au lieu de REPLACE_WITH_INTERNAL_IP_MLFLOW_VM, vous devez remplacer l'adresse de votre machine virtuelle :
MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com MLFLOW_TRACKING_URI=http://REPLACE_WITH_INTERNAL_IP_MLFLOW_VM:8000
MLflow communique avec S3 à l'aide de la bibliothèque boto3, qui recherche par défaut les informations d'identification dans le dossier ~/.aws. Par conséquent, nous devons créer un fichier :
mkdir ~/.aws nano ~/.aws/credentials
Dans ce fichier, nous écrirons les identifiants d'accès à S3, que nous avons reçus après la création du bucket :
[default] aws_access_key_id = REPLACE_WITH_YOUR_KEY aws_secret_access_key = REPLACE_WITH_YOUR_SECRET_KEY
Enfin, nous appliquons les paramètres d'environnement :
conda activate mlflow_env
Vous pouvez maintenant démarrer le serveur de suivi. Remplacez vos paramètres de connexion PostgreSQL et S3 dans la commande :
mlflow server --backend-store-uri postgresql://pg_user:pg_password@REPLACE_WITH_INTERNAL_IP_POSTGRESQL/db_name --default-artifact-root s3://REPLACE_WITH_YOUR_BUCKET/REPLACE_WITH_YOUR_DIRECTORY/ -h 0.0.0.0 -p 8000
MLflow lancé :

Ouvrons maintenant l'interface graphique et vérifions que tout fonctionne comme il se doit. Pour ce faire, vous devez vous rendre sur l'adresse IP externe de la machine virtuelle avec MLflow Tracking Server, port 8000. Dans notre cas, ce sera 37.139.41.57 : 8000
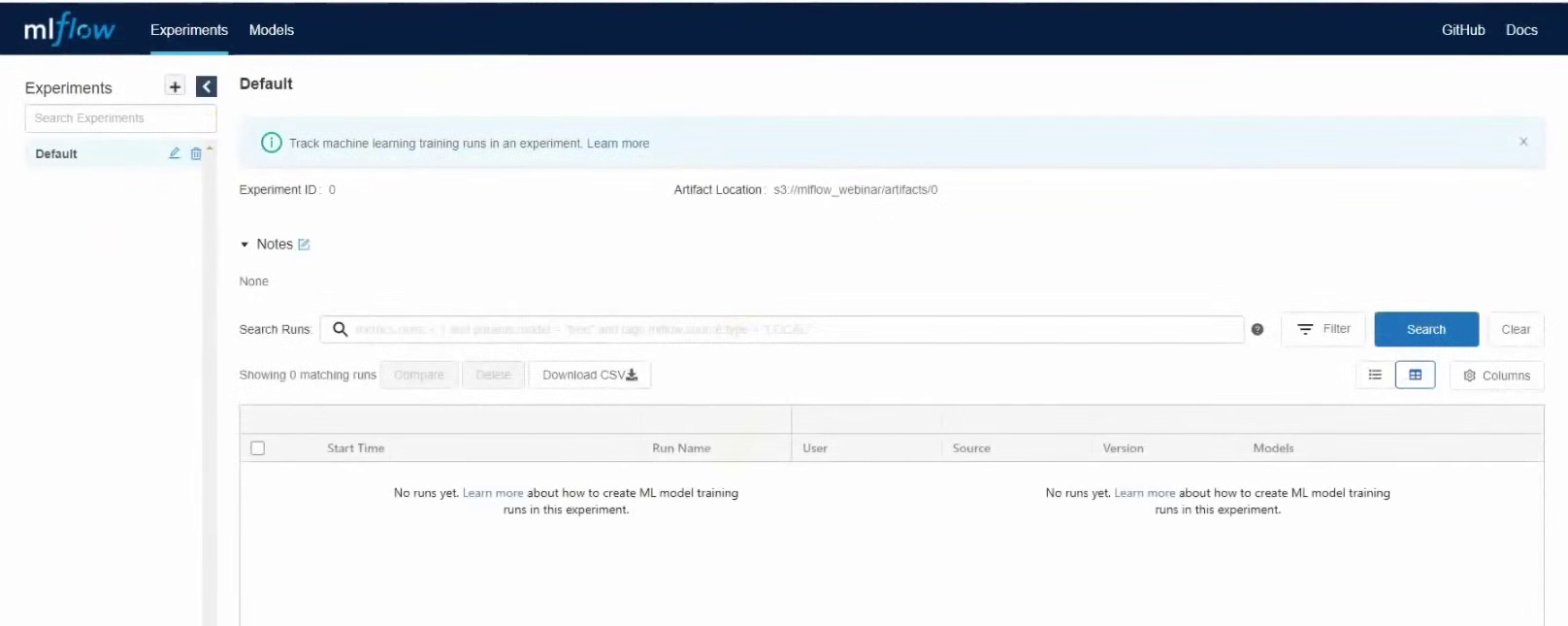
MLflow a démarré
Mais maintenant, il y a un petit problème dans notre schéma. Le serveur fonctionne tant que le terminal est en cours d'exécution. Si vous fermez le terminal, MLflow s'arrêtera. De plus, il ne redémarrera pas automatiquement si nous redémarrons le serveur. Pour résoudre ce problème, nous allons démarrer le serveur MLflow en tant que service systemd.
Créons donc deux répertoires pour stocker les journaux et les erreurs :
mkdir ~/mlflow_logs/ mkdir ~/mlflow_errors/
Ensuite, créons un fichier de service :
sudo nano /etc/systemd/system/mlflow-tracking.service
Ensuite, ajoutez-y le code. N'oubliez pas de substituer vos paramètres de connexion à la base de données et à S3, comme vous l'avez fait lors du démarrage manuel du serveur :
[Unit]
Description=MLflow Tracking Server
After=network.target
[Service]
Environment=MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com
Restart=on-failure
RestartSec=30
StandardOutput=file:/home/ubuntu/mlflow_logs/stdout.log
StandardError=file:/home/ubuntu/mlflow_errors/stderr.log
User=ubuntu
ExecStart=/bin/bash -c 'PATH=/home/ubuntu/anaconda3/envs/mlflow_env/bin/:$PATH exec mlflow server --backend-store-uri postgresql://PG_USER:PG_PASSWORD@REPLACE_WITH_INTERNAL_IP_POSTGRESQL/DB_NAME --default-artifact-root s3://REPLACE_WITH_YOUR_BUCKET/REPLACE_WITH_YOUR_DIRECTORY/ -h 0.0.0.0 -p 8000'
[Install]
WantedBy=multi-user.target
Maintenant, nous démarrons le service, activons le chargement automatique au démarrage du système et vérifions que le service est en cours d'exécution :
sudo systemctl daemon-reload
sudo systemctl enable mlflow-tracking
sudo systemctl start mlflow-tracking
sudo systemctl status mlflow-tracking
On voit que le service a démarré :
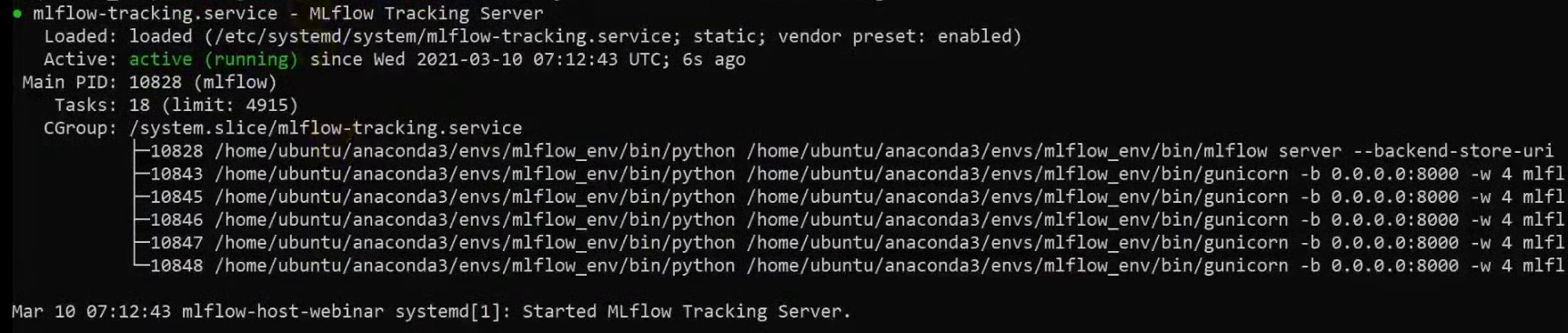
De plus, on peut consulter les logs, tout va bien là aussi :
head -n 95 ~/mlflow_logs/stdout.log

Ouvrez à nouveau l'interface Web et vérifiez que le serveur MLflow est en cours d'exécution. Ça y est, MLflow Tracking Server est installé et prêt à fonctionner.
Étape 3 : déployez JupyterHub dans le cloud et configurez-le pour qu'il fonctionne avec MLflow
Nous déploierons JupyterHub sur une machine virtuelle distincte afin que plus tard cet hôte puisse être fourni aux équipes d'ingénieurs de données ou de scientifiques des données. De cette façon, ils peuvent fonctionner avec JupyterHub, mais ils ne peuvent pas affecter le serveur MLflow. Nous utiliserons notre service Machine Learning in the Cloud, qui vous permet d'obtenir rapidement un environnement prêt à l'emploi avec JupyterHub, conda et d'autres outils utiles installés.
Dans le panneau MCS, accédez à la section Machine Learning et créez un environnement d'apprentissage.
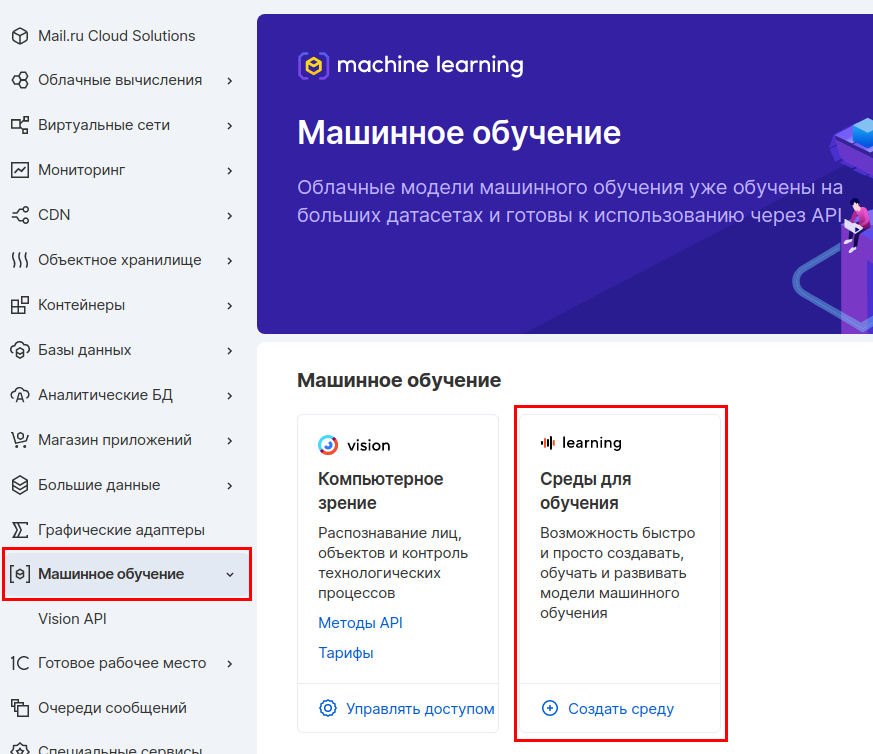
Nous sélectionnons les paramètres de la machine virtuelle. Nous prendrons 4 CPU et 8 Go de RAM.
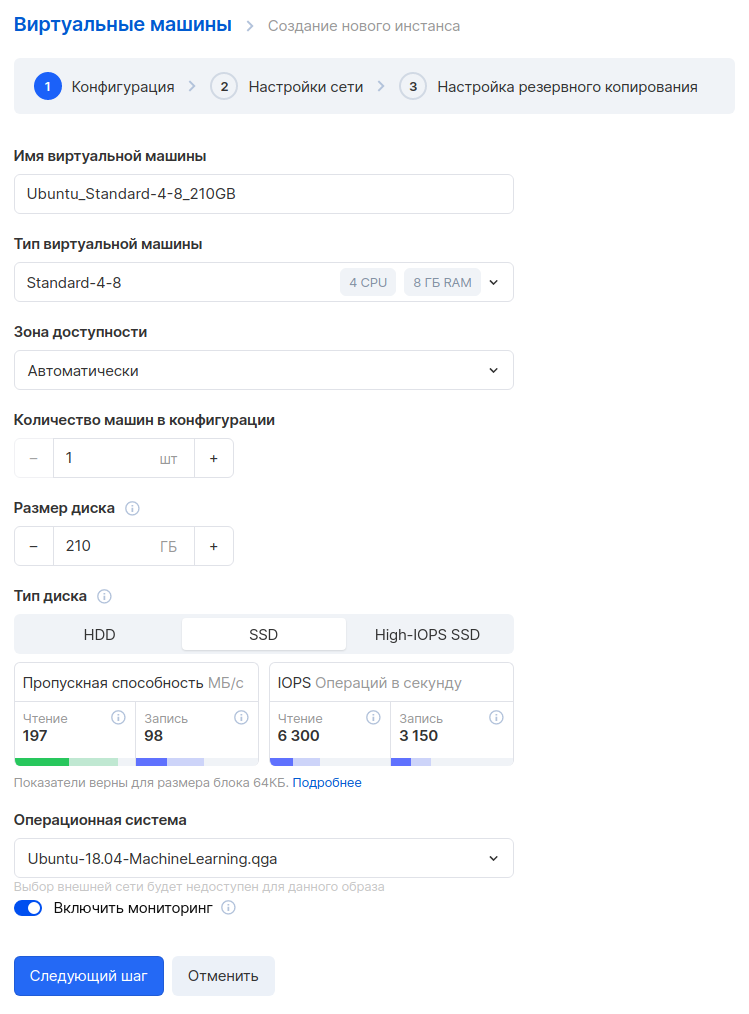
Dans l'étape suivante, nous mettons en place le réseau. Assurez-vous que le réseau est le même afin que cette machine puisse communiquer avec le reste des serveurs du réseau interne. Sélectionnez l'option "Attribuer une IP externe" afin que nous puissions ultérieurement nous connecter à cette machine depuis Internet.

La dernière étape consiste à configurer votre sauvegarde. Vous pouvez laisser les options par défaut.
Une fois la machine virtuelle créée, vous devez noter son adresse IP externe : elle nous sera utile plus tard.

Maintenant, nous nous connectons à cette machine via SSH et activons le JupyterHub installé. Nous utiliserons l'utilitaire tmux pour pouvoir nous détacher de l'écran et exécuter d'autres commandes.
tmux
jupyter-notebook --ip '*'
L'utilisation de tmux n'est pas une solution de produit. Nous allons maintenant le faire dans le cadre d'un projet de test, et pour les solutions produit, nous recommandons d'utiliser systemd, comme nous l'avons fait pour lancer MLflow Tracking Server.
Après avoir activé JupyterHub, la console aura une URL où vous devrez vous connecter à JupyterHub. Dans cette ligne, vous devez remplacer l'adresse IP externe de la machine virtuelle.

Accédez à cette adresse et consultez l'interface JupyterHub :
Maintenant, nous devons laisser le serveur fonctionner, mais en même temps exécuter d'autres commandes. Par conséquent, nous allons nous déconnecter de cette instance de terminal et la laisser s'exécuter en arrière-plan. Pour ce faire, appuyez sur la combinaison de touches ctrl + b d.
Le chargement direct des artefacts dans le stockage des artefacts sera effectué à partir de cet hôte. Par conséquent, nous devons configurer l'interopérabilité JupyterHub avec MLflow et S3. Tout d'abord, configurons quelques variables d'environnement. Ouvrons le fichier /etc/environment :
sudo nano /etc/environment
Et écrivez-y les adresses du serveur de suivi et du point de terminaison pour S3 :
MLFLOW_TRACKING_URI=http://REPLACE_WITH_INTERNAL_IP_MLFLOW_VM:8000 MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com
Nous devons également recréer les informations d'identification pour accéder à S3. Créons un fichier et un répertoire :
mkdir .aws nano ~/.aws/credentials
Écrivons ici la clé d'accès et la clé secrète :
[default] aws_access_key_id = REPLACE_WITH_YOUR_KEY aws_secret_access_key = REPLACE_WITH_YOUR_SECRET_KEY
Installons maintenant MLflow pour utiliser son côté client. Pour ce faire, créons un environnement et un noyau séparés :
conda create -n mlflow_env
conda activate mlflow_env
conda install python
pip install mlflow
pip install matplotlib
pip install sklearn
pip install boto3
conda install -c anaconda ipykernel
python -m ipykernel install --user --name ex --display-name "Python (mlflow)"
Étape 4 : paramètres de journalisation et métriques des expériences
Nous allons maintenant travailler directement avec le code. Accédez à nouveau à l'interface Web JupyterHub, lancez le terminal et clonez le référentiel :
git clone https://github.com/stockblog/webinar_mlflow/ webinar_mlflow
Ensuite, ouvrez le fichier mlflow_demo.ipynb et lancez séquentiellement les cellules.
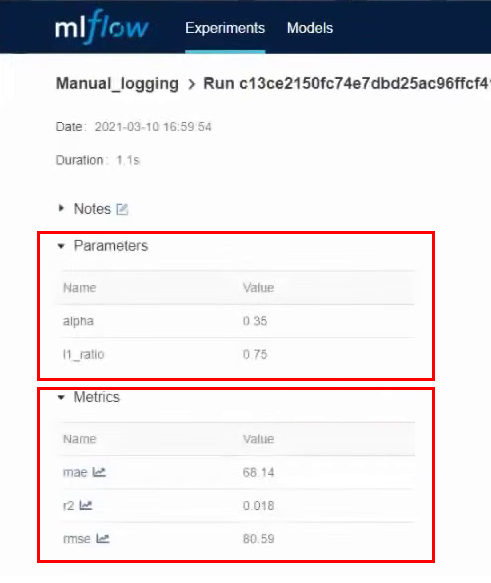
Dans la cellule numéro 3, nous testerons la journalisation manuelle des paramètres et des métriques. La cellule indique clairement les paramètres que nous voulons sécuriser. On lance la cellule et après qu'elle fonctionne, on passe à l'interface MLflow. Ici, nous voyons qu'une nouvelle expérience a été créée - Manual_logging.

Nous entrons dans les détails de cette expérience et voyons les paramètres et les métriques que nous avons indiqués lors de la journalisation :
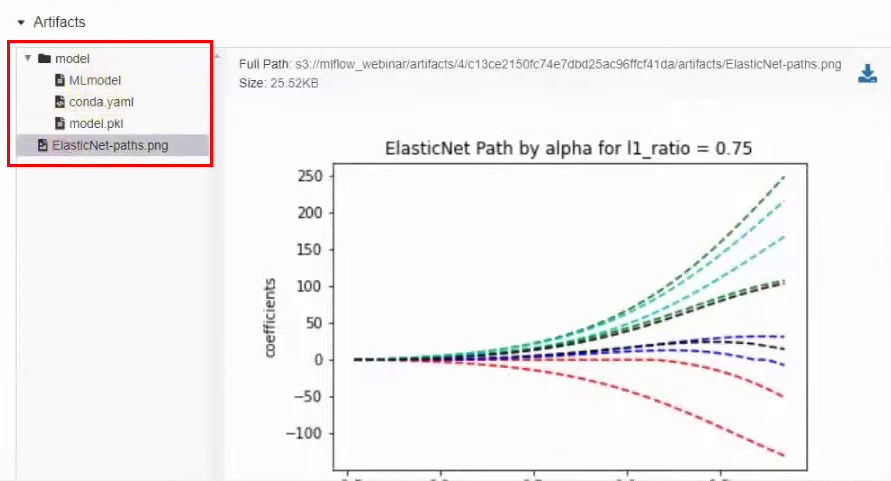
Dans la même fenêtre ci-dessous, il y a des artefacts qui sont directement liés au modèle, par exemple, un graphique :
Essayons maintenant d'enregistrer tous les paramètres automatiquement. Dans la cellule suivante, nous utilisons le même modèle, mais nous activons la journalisation automatique. La ligne est responsable de cela:
mlflow.sklearn.autolog(log_input_examples=True)
Nous devons spécifier la saveur que nous utiliserons, dans notre cas, il s'agit de sklearn. Nous avons également spécifié log_input_examples = True dans les paramètres de la fonction autolog. Dans le même temps, des exemples de données d'entrée pour le modèle seront automatiquement enregistrés : quelles colonnes, ce qu'elles signifient et à quoi ressemblent les données d'entrée. Cette information sera trouvée dans les artefacts. Cela peut s'avérer utile lorsqu'une équipe travaille sur plusieurs expériences en même temps. Parce qu'il n'est pas toujours possible de garder à l'esprit chaque modèle et tous les exemples de données pour celui-ci.
Dans cette cellule, nous avons supprimé toutes les lignes associées à la journalisation manuelle des métriques et des paramètres. Mais la journalisation des artefacts reste en mode manuel.
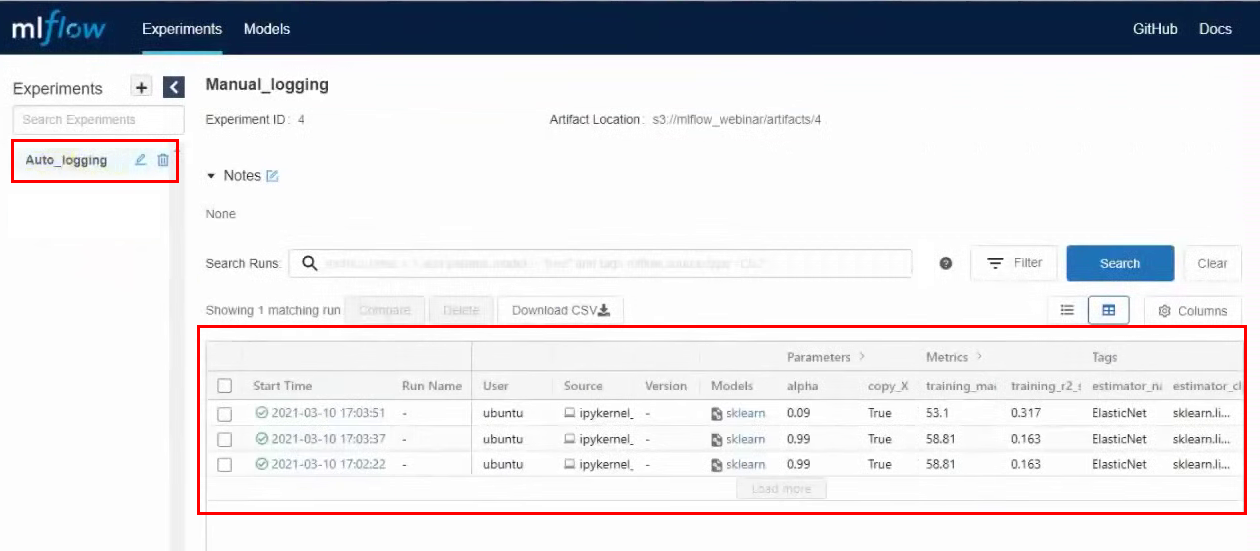
Nous lançons la cellule, après son exécution, une nouvelle expérience est créée. Nous allons à l'interface MLflow, allons à l'expérience Auto_logging et voyons qu'il y a maintenant beaucoup plus de paramètres et de métriques qu'avec la collecte manuelle :

Maintenant, si nous modifions les paramètres de la cellule et l'exécutons à nouveau, des lignes avec de nouveaux lancements apparaîtront dans les expériences dans MLflow. Par exemple, nous avons fait trois lancements avec des paramètres différents :
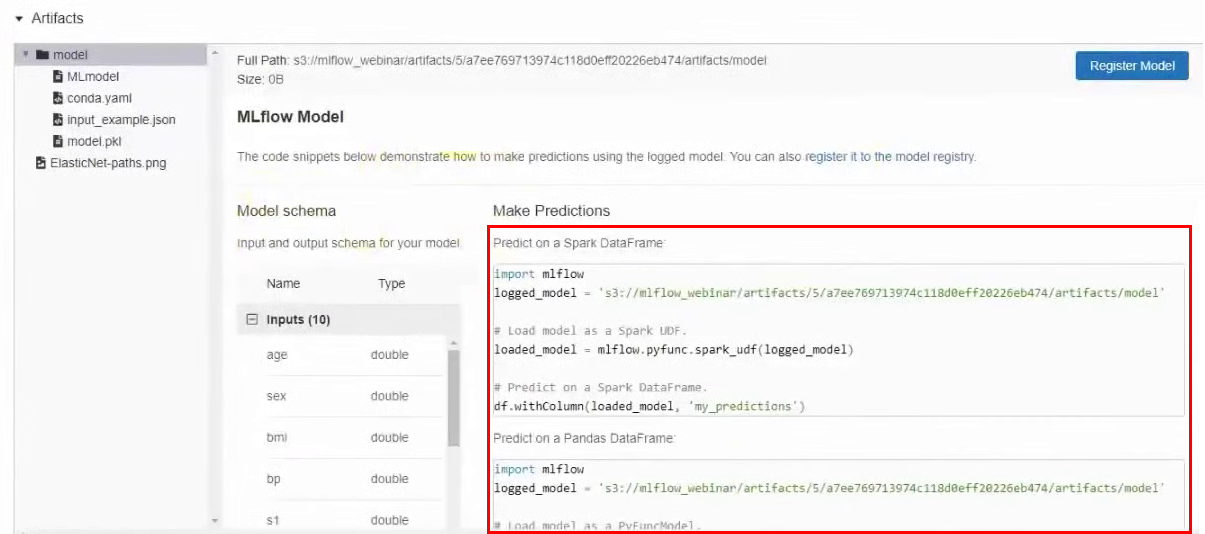
Vous trouverez également dans les artefacts un exemple d'utilisation de ce modèle particulier. Il existe un chemin de modèle dans S3 et des exemples pour différents frameworks.
Étape 5 : Tester les moyens de publier des modèles de ML
Nous avons donc fait les expériences, et maintenant nous allons publier le modèle. Nous allons examiner deux façons de procéder.
Méthode de publication n°1 : Accédez directement au référentiel S3. Copiez l'adresse du modèle dans le stockage S3 et publiez-la à l'aide de mlflow serve :
mlflow models serve -m s3://BUCKET/FOLDER/EXPERIMENT_NUMBER/INTERNAL_MLFLOW_ID/artifacts/model -h 0.0.0.0 -p 8001
Dans cette commande, nous spécifions l'hôte et le port sur lesquels le modèle sera disponible. Nous utilisons l'adresse 0.0.0.0, qui signifie l'hôte actuel. Il n'y a pas d'erreurs dans le terminal, ce qui signifie que le modèle a été publié :

Maintenant, testons-le. Dans une nouvelle fenêtre de terminal, connectez-vous via SSH au même serveur et essayez d'atteindre le modèle en utilisant curl. Si vous utilisez le même ensemble de données, vous pouvez copier complètement la commande sans modifications :
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"], "data":[[0.0453409833354632, 0.0506801187398187, 0.0606183944448076, 0.0310533436263482, 0.0287020030602135, 0.0473467013092799, 0.0544457590642881, 0.0712099797536354, 0.133598980013008, 0.135611830689079]]}' http://0.0.0.0:8001/invocations
Après avoir exécuté la commande, nous voyons le résultat :

Le modèle est également accessible depuis l'interface JupyterHub. Pour ce faire, exécutez la cellule appropriée , mais avant cela, remplacez l'adresse IP par la vôtre.
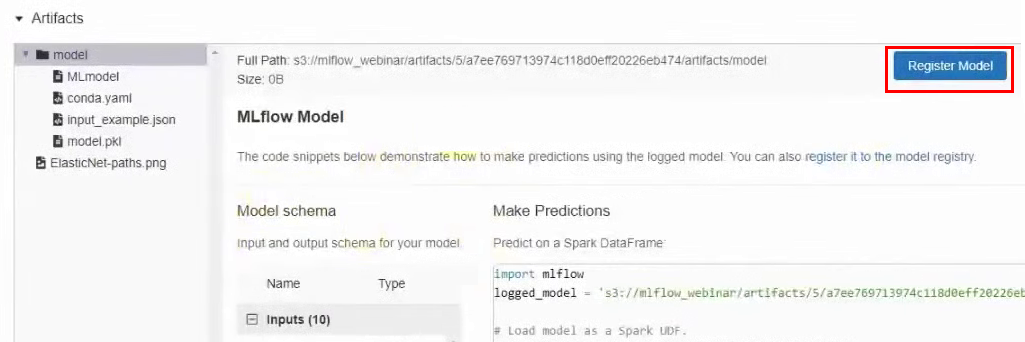
Méthode de publication n°2 : enregistrez le modèle dans MLflow. Nous pouvons également enregistrer le modèle dans MLflow, puis il sera disponible via l'interface utilisateur. Pour ce faire, retournez aux résultats de l'expérience, dans la section Artefacts, cliquez sur le bouton Enregistrer le modèle et dans la fenêtre qui apparaît, donnez-lui un nom.
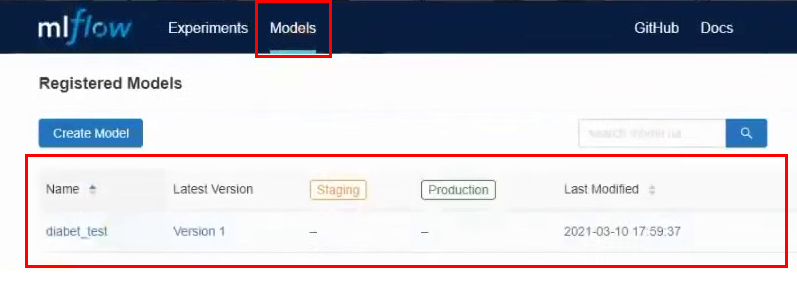
Maintenant, dans le menu du haut, allez dans l'onglet Modèles. Et on voit que dans la liste des modèles on a un nouveau modèle :
Entrons-y. Dans cette interface, vous pouvez transférer le modèle à différentes étapes, voir les paramètres d'entrée et les résultats. Vous pouvez également fournir une description du modèle, ce qui sera utile si plusieurs personnes y travaillent. Nous allons convertir notre modèle en Staging.
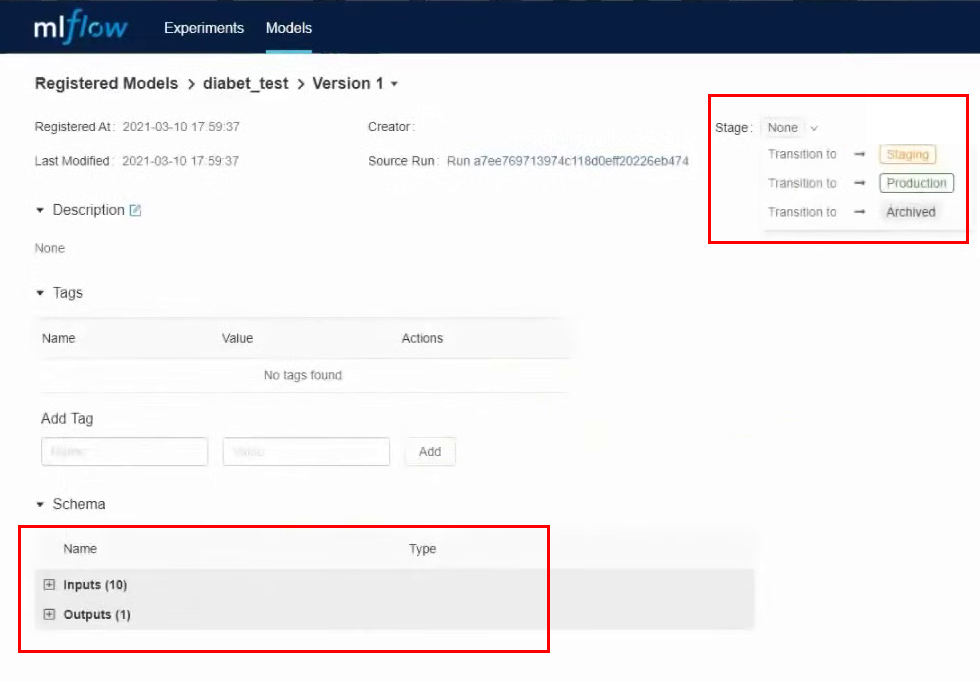
Nous effectuons presque toutes les actions via l'interface, mais de la même manière, vous pouvez travailler via l'API et la CLI. Toutes ces actions peuvent être automatisées : enregistrement des modèles, transfert à une autre étape, déploiement des modèles et tout le reste.
Maintenant, nous utiliserons également la commande serve pour publier le modèle, mais au lieu du long chemin dans S3, nous spécifierons simplement le nom du modèle :
mlflow models serve -m "models:/YOUR_MODEL_NAME/STAGE"
Veuillez noter que cette fois nous n'avons pas spécifié le port et que le modèle par défaut a été publié sur le port 5000 :

Maintenant, en utilisant curl, nous essayons à nouveau d'atteindre le modèle :
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"], "data":[[0.0453409833354632, 0.0506801187398187, 0.0606183944448076, 0.0310533436263482, 0.0287020030602135, 0.0473467013092799, 0.0544457590642881, 0.0712099797536354, 0.133598980013008, 0.135611830689079]]}' http://0.0.0.0:5000/invocations
Le résultat est le même:
Mais si nous essayons d'accéder au modèle à partir d'un autre serveur, nous échouerons. Parce que maintenant, le modèle n'est disponible que dans l'hôte où il est publié. Pour résoudre ce problème, publions le modèle avec le paramètre -h :
mlflow models serve -m "models:/YOUR_MODEL_NAME/STAGE" -h 0.0.0.0
Testons l'accès au modèle en utilisant la même cellule dans le JupyterHub, mais changeons le port en 5000. Le modèle renvoie un résultat. Il diffère légèrement du résultat ci-dessus, car pendant le webinaire, nous avons modifié certains paramètres.

Le modèle est également accessible à l'aide de Python. Un exemple peut être trouvé dans une autre cellule .
Mais dans les deux versions de la publication du modèle, il y a une particularité. Le modèle est disponible tant que le terminal est en cours d'exécution avec la commande serve. Lorsque nous fermons le terminal ou redémarrons le serveur, l'accès au modèle sera perdu. Pour éviter cela, nous publierons le modèle à l'aide du service systemd, comme nous l'avons fait pour lancer le serveur de suivi MLflow.
Créons un nouveau fichier de service :
sudo nano /etc/systemd/system/mlflow-model.service
Et nous y insérerons ces commandes, après avoir préalablement remplacé les variables par les nôtres.
[Unit]
Description=MLFlow Model Serving
After=network.target
[Service]
Restart=on-failure
RestartSec=30
StandardOutput=file:/home/ubuntu/mlflow_logs/stdout.log
StandardError=file:/home/ubuntu/mlflow_errors/stderr.log
Environment=MLFLOW_TRACKING_URI=http://REPLACE_WITH_INTERNAL_IP_MLFLOW_VM:8000
Environment=MLFLOW_CONDA_HOME=/home/ubuntu/anaconda3/
Environment=MLFLOW_S3_ENDPOINT_URL=https://hb.bizmrg.com
ExecStart=/bin/bash -c 'PATH=/home/ubuntu/anaconda3/envs/REPLACE_WITH_MLFLOW_ENV_OF_MODEL/bin/:$PATH exec mlflow models serve -m "models:/YOUR_MODEL_NAME/STAGE" -h 0.0.0.0 -p 8001'
[Install]
WantedBy=multi-user.target
Il existe une nouvelle variable que nous n'avons jamais utilisée auparavant : REPLACE_WITH_MLFLOW_ENV_OF_MODEL. Il s'agit d'un environnement MLflow individuel qui est automatiquement créé pour chaque modèle. Pour voir dans quel environnement votre modèle s'exécute, consultez la sortie de la commande serve lorsque vous avez exécuté le modèle. Il y a cet identifiant là-dedans :

Commençons maintenant et activons ce service pour que le modèle soit publié à chaque démarrage de l'hôte :
sudo systemctl daemon-reload
sudo systemctl enable mlflow-model
sudo systemctl start mlflow-model
Vérification de l'état :
sudo systemctl status mlflow-model
On voit qu'une erreur est apparue au démarrage :

En utilisant son exemple, nous analyserons comment vous pouvez trouver et éliminer les erreurs. Pour comprendre ce qui s'est réellement passé, vérifions les journaux. Ils se trouvent dans un dossier que nous avons créé spécifiquement pour les journaux.
head -n 95 ~/mlflow_logs/stdout.log
Dans notre exemple, à la toute fin du journal, vous pouvez voir que MLflow ne trouve pas la bibliothèque boto3, qui est nécessaire pour accéder à S3 :

Il existe deux options pour résoudre le problème :
- Installez la bibliothèque à la main dans l'environnement MLflow. Mais c'est une méthode de béquille, nous ne la considérerons pas.
- Enregistrez la bibliothèque dans les dépendances du fichier yaml. Nous allons considérer cette méthode.
Vous devez trouver le dossier dans le compartiment où ce modèle est stocké. Pour ce faire, revenez à l'interface MLflow et, dans les résultats de l'expérience, accédez à la section avec les artefacts. On se souvient du chemin :
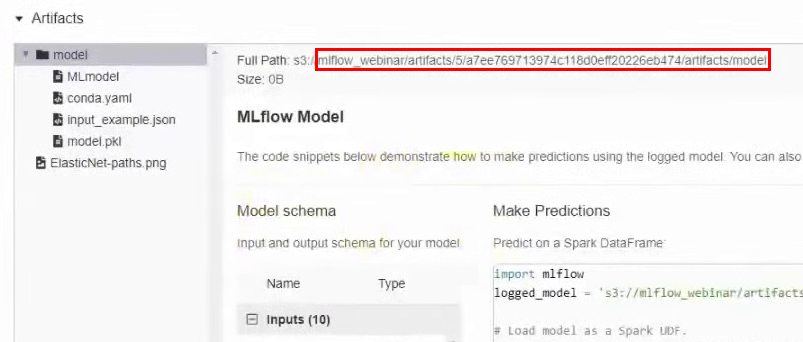
Dans l'interface MCS, accédez au bucket le long de ce chemin et téléchargez le fichier conda.yaml.
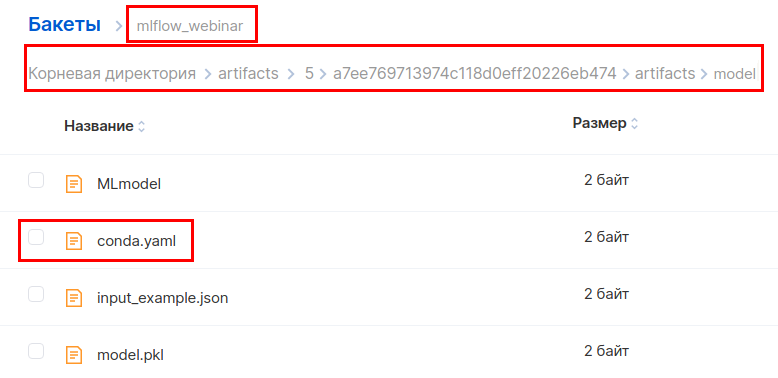
Ajoutez la bibliothèque boto3 à la section avec les dépendances et téléchargez à nouveau le fichier.
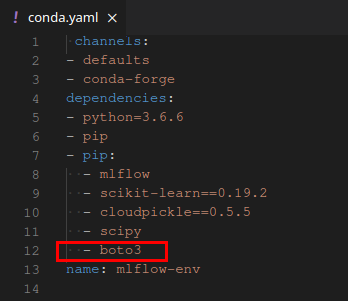
Essayons de redémarrer le service systemd :
sudo systemctl start mlflow-model
Tout va bien maintenant, le modèle a commencé. Vous pouvez à nouveau essayer de la joindre de différentes manières, comme nous l'avons fait auparavant. Notez que le port doit être à nouveau spécifié 8001. Créons
maintenant une image docker avec ce modèle afin qu'il puisse être facilement migré vers un autre environnement. Pour ce faire, docker doit être installé sur l'hôte. Nous ne considérerons pas le processus d'installation, mais fournirons simplement un lien vers les instructions officielles .
Exécutons la commande :
mlflow models build-docker -m "models:/YOUR_MODEL_NAME/STAGE" -n "DOCKER_IMAGE_NAME"
Dans le paramètre -n, nous spécifions le nom souhaité pour l'image docker. Résultat:

Testons-le. Nous lançons le conteneur, maintenant le modèle sera disponible sur le port 5001 :
docker run -p 5001:8080 YOUR_MODEL_NAME
Le modèle devrait maintenant être immédiatement disponible et actif. Allons vérifier:
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"], "data":[[0.0453409833354632, 0.0506801187398187, 0.0606183944448076, 0.0310533436263482, 0.0287020030602135, 0.0473467013092799, 0.0544457590642881, 0.0712099797536354, 0.133598980013008, 0.135611830689079]]}' http://127.0.0.1:5001/invocations
Vous pouvez également vérifier la disponibilité sur JupyterHub. En même temps, dans le terminal où nous avons lancé l'image docker, nous voyons que les requêtes proviennent de deux hôtes différents, local et JupyterHub :

Ça y est, l'image docker est assemblée, testée et prête à l'emploi.
Qu'avons-nous appris
Nous nous sommes donc familiarisés avec MLflow et avons appris à le déployer dans le cloud. La plupart des instructions sur le net se limitent à l'installation de MLflow sur la machine locale. C'est bon pour la familiarisation et l'expérimentation rapide, mais certainement pas une option de production.
Tout cela est possible car les plates-formes cloud fournissent de nombreux services prêts à l'emploi qui aident à simplifier et à accélérer le déploiement.
, , Mail.ru Cloud Solutions, 3000 ₽. , MLflow .