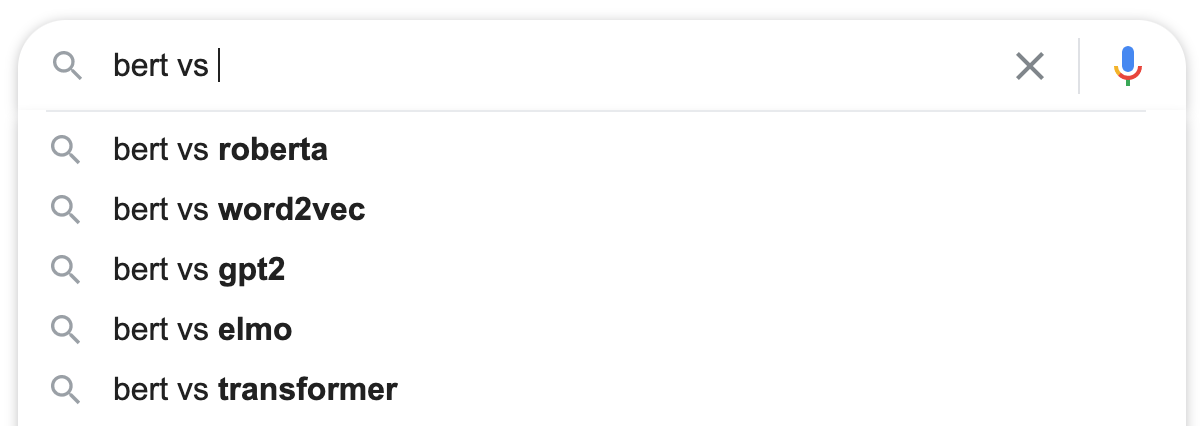
Entrer «vs» après le mot recherché
Cela m'est arrivé.
En fait, c'est un gros problème. Il s'agit d'une technique qui, lors de la recherche d'une alternative à quelque chose, peut faire gagner une tonne de temps.
Je vois 3 raisons pour lesquelles cette technique fonctionne très bien si elle est utilisée pour trouver des informations sur les technologies, certains développements et concepts qu'ils veulent comprendre:
- La meilleure façon d'apprendre quelque chose de nouveau est de découvrir comment c'est, nouveau, similaire à ce qui est déjà connu, ou en quoi le nouveau diffère du connu. Par exemple, dans la liste de phrases qui apparaît après «vs», vous pouvez voir quelque chose à propos duquel vous pouvez dire: «Et, donc, il s'avère que ce que je recherche, ressemble à ceci me est déjà familier.»
- — . , , .
- «vs» — , Google , - -. «or», - -. , «or», Google , - .
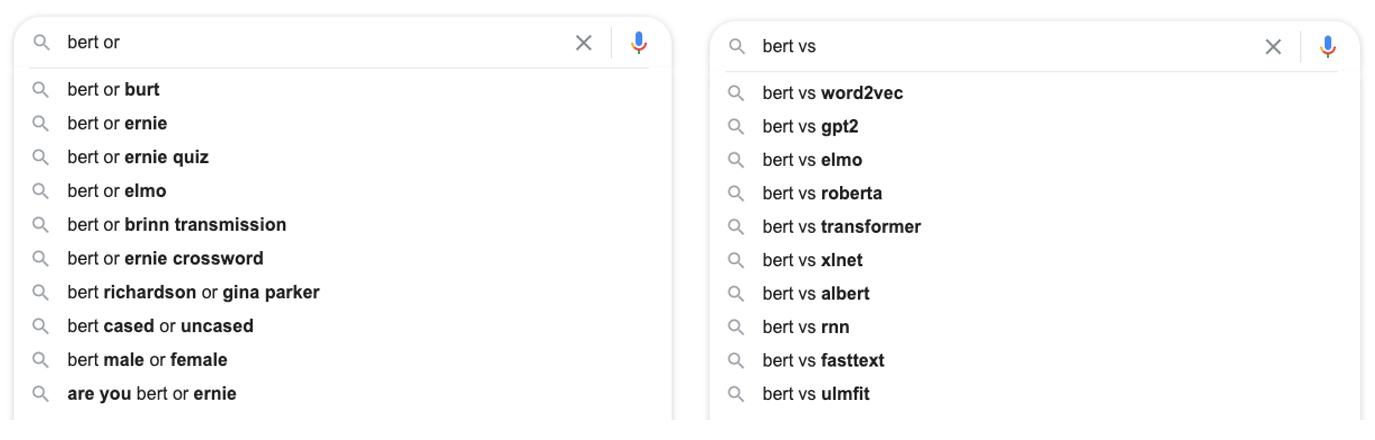
Lors du traitement d'une place ou d'une demande, Google fait des suggestions concernant Sesame Street. Et le bert vs query me donne des conseils sur Google BERT.
Cela m'a fait réfléchir. Mais que se passe-t-il si nous prenons les mots suggérés par Google après avoir entré "vs" et les recherchons, en ajoutant également "vs" après eux? Et si vous répétiez cela plusieurs fois? Si tel est le cas, vous pouvez obtenir un joli graphique de réseau des requêtes associées.
Par exemple, cela peut ressembler à ceci.
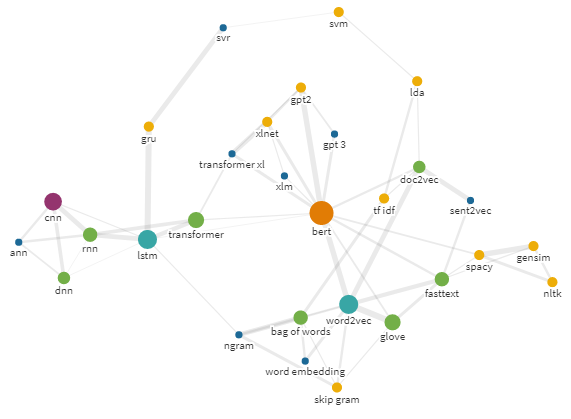
Graphique d'ego pour requête bert avec rayon 25
Il s'agit d'une technique très utile pour créer des cartes mentales de technologies, de développements ou d'idées qui reflètent la relation d'entités similaires.
Je vais vous dire comment créer de tels graphiques.
Automatiser la collecte de données "vs" de Google
Voici un lien que vous pouvez utiliser pour obtenir des suggestions de saisie semi-automatique en XML de Google. Cette fonctionnalité ne semble pas être une API destinée à un usage général, elle ne devrait donc probablement pas être trop lourde sur ce lien.
http://suggestqueries.google.com/complete/search?&output=toolbar&gl=us&hl=en&q=<search_term>
Le paramètre URL
output=toolbarindique que nous sommes intéressés par les résultats au format XML, gl=usdéfinit le code du pays, hl=ennous permet de spécifier la langue et la construction q=<search_term>est exactement ce dont nous avons besoin pour obtenir les résultats de l'auto-complétion.
Pour les paramètres
glet hl, des identifiants standard à deux lettres des pays et des langues sont utilisés .
Essayons tout cela en commençant une recherche avec, disons, une requête
tensorflow.
La première étape du travail consiste à se référer à l' endroit spécifié l'URL, en utilisant la structure suivante décrivant la requête:
q=tensorflow%20vs%20. Le lien entier ressemblera à ceci:
http://suggestqueries.google.com/complete/search?&output=toolbar&gl=us&hl=en&q=tensorflow%20vs%20
En réponse, nous obtenons les données XML.
Que faire avec XML?
Vous devez maintenant vérifier les résultats de l'achèvement de l'achèvement pour la conformité avec un certain ensemble de critères. Avec ceux qui nous conviennent, nous continuerons à travailler.

Vérification des résultats obtenus
J'ai, lors de la vérification des résultats, utilisé les critères suivants:
- La requête de recherche recommandée ne doit pas contenir le texte de requête d'origine (c'est-à-dire -
tensorflow). - La recommandation ne doit pas inclure les demandes qui ont été jugées appropriées auparavant (par exemple -
pytorch). - La recommandation ne doit pas inclure quelques mots «vs».
- Une fois que 5 recherches correspondantes sont trouvées, toutes les autres ne sont plus prises en compte.
Ce n'est qu'une façon de "nettoyer" la liste de suggestions de recherche de saisie semi-automatique de Google. De plus, je vois parfois l'intérêt de ne choisir dans la liste que des recommandations composées d'un seul mot, mais l'utilisation de cette technique dépend de chaque situation spécifique.
Ainsi, en utilisant cet ensemble de critères, nous avons obtenu les 5 résultats suivants, dont chacun se voit attribuer un certain poids.
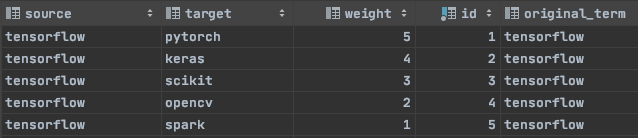
5 résultats
Itération suivante
Ces 5 recommandations trouvées sont ensuite soumises au même traitement que la requête de recherche d'origine. Ils sont transmis à l'API en utilisant le mot «vs» et encore 5 résultats d'auto-complétion sont sélectionnés qui répondent aux critères ci-dessus. Voici le résultat d'un tel traitement de la liste ci-dessus.

Recherche de résultats de saisie semi-automatique pour les mots déjà trouvés Vous
pouvez poursuivre ce processus en examinant les mots de la colonne qui n'ont pas encore été examinés
target.
Si vous effectuez de nombreuses itérations d'une telle recherche de mots, vous obtenez un tableau assez volumineux contenant des informations sur les requêtes et les poids. Ces données sont bien adaptées à la visualisation graphique.
L'ego compte
Le graphe de réseau que je vous ai montré au début de l'article est le soi-disant graphe ego, construit, dans notre cas, pour la requête
tensorflow. Un graphique de l'ego est un graphique dont tous les nœuds sont à une certaine distance du nœud tensorflow. Cette distance ne doit pas dépasser la distance spécifiée.
Et comment la distance entre les nœuds est-elle déterminée?
Jetons d'abord un œil au graphique fini.

Ego-graph pour requête tensorflow de rayon 22 On connaît déjà le
poids de l'arête reliant la requête
AetB. Il s'agit du rang de la recommandation de la liste de saisie semi-automatique, allant de 1 à 5. Pour rendre le graphique non orienté, vous pouvez simplement ajouter les poids des connexions entre les sommets allant dans deux directions (c'est-à-dire deAàBet, s'il y a une telle connexion, deBàA) ... Cela nous donnera des poids d'arête allant de 1 à 10.
La longueur d'arête (distance) sera donc calculée à l'aide de la formule
11 — ... Nous avons choisi le nombre 11 ici parce que le poids maximum du bord est de 10 (le bord aura ce poids si les deux recommandations apparaissent tout en haut de la liste d'achèvement de l'autre). En conséquence, la distance minimale entre les requêtes sera de 1. La
taille (taille) et la couleur (couleur) du sommet du graphe sont déterminées par le nombre (décompte) de cas dans lesquels la requête correspondante apparaît dans la liste des recommandations. En conséquence, il s'avère que plus le pic est grand, plus le concept qu'il représente est important.
Le graphe du moi considéré a un rayon de 22. Cela signifie que vous pouvez atteindre chaque requête, à partir du sommet
tensorflow, en marchant sur une distance ne dépassant pas 22. Jetons un coup d'œil à ce qui se passe si nous augmentons le rayon du graphe à 50.

Graphique de l'ego pour la requête tensorflow avec un rayon 50
Fait intéressant, il s'est avéré! Ce graphique contient la plupart des technologies de base que toute personne travaillant dans l'intelligence artificielle doit connaître. De plus, les noms de ces technologies sont regroupés logiquement.
Et tout cela est construit sur la base d'un seul mot-clé.
Comment dessiner des graphiques similaires?
J'ai utilisé l'outil Flourish en ligne pour dessiner un tel graphique .
Ce service vous permet de créer des diagrammes de réseau et d'autres diagrammes à l'aide d'une interface simple. Je suppose que cela vaut la peine de regarder pour ceux qui s'intéressent à la construction de graphiques d'ego.
Comment créer un graphique d'ego avec un rayon donné?
Pour créer un graphique de l'ego avec un rayon donné, vous pouvez utiliser le package Python
networkx. Il a une fonction très pratique ego_graph. Le rayon du graphique est spécifié lors de l'appel de cette fonction.
import networkx as nx
#
#nodes = [('tensorflow', {'count': 13}),
# ('pytorch', {'count': 6}),
# ('keras', {'count': 6}),
# ('scikit', {'count': 2}),
# ('opencv', {'count': 5}),
# ('spark', {'count': 13}), ...]
#edges = [('pytorch', 'tensorflow', {'weight': 10, 'distance': 1}),
# ('keras', 'tensorflow', {'weight': 9, 'distance': 2}),
# ('scikit', 'tensorflow', {'weight': 8, 'distance': 3}),
# ('opencv', 'tensorflow', {'weight': 7, 'distance': 4}),
# ('spark', 'tensorflow', {'weight': 1, 'distance': 10}), ...]
#
G=nx.Graph()
G.add_nodes_from(nodes)
G.add_edges_from(edges)
# - 'tensorflow'
EG = nx.ego_graph(G, 'tensorflow', distance = 'distance', radius = 22)
#
subgraphs = nx.algorithms.connectivity.edge_kcomponents.k_edge_subgraphs(EG, k = 3)
# , 'tensorflow'
for s in subgraphs:
if 'tensorflow' in s:
break
pruned_EG = EG.subgraph(s)
ego_nodes = pruned_EG.nodes()
ego_edges = pruned_EG.edges()
De plus, j'ai utilisé une autre fonction ici -
k_edge_subgraphs. Il est utilisé pour supprimer certains résultats qui ne répondent pas à nos besoins.
Par exemple, il
storms'agit d'un framework open source pour l'informatique distribuée en temps réel. Mais c'est aussi un personnage de l'univers Marvel. Selon vous, quelles suggestions de recherche "gagneront" si vous saisissez "tempête vs" dans Google?
La fonction
k_edge_subgraphstrouve des groupes de sommets qui ne peuvent pas être divisés en effectuant kou moins d'actions. En fait, voici les valeurs des paramètres k=2et k=3. En fin de compte, il ne reste que les sous-graphiques auxquels ils appartiennent tensorflow. Cela garantit que nous ne nous éloignons pas trop de l'endroit où nous avons commencé notre recherche et que nous ne nous éloignons pas trop.
L'utilisation des graphiques de l'ego dans la vie
Éloignons-nous de l'exemple c
tensorflowet considérons un autre graphe du moi. Cette fois - un graphique dédié à autre chose qui m'intéresse. Il s'agit d'un début d'échecs appelé le Parti espagnol (ouverture d'échecs Ruy Lopez).
▍Recherche des ouvertures d'échecs

Recherche du "jeu espagnol" (ruy lopez)
Notre méthode nous a permis de découvrir rapidement les idées d' ouverture les plus courantes, qui peuvent aider un chercheur d'échecs.
Voyons maintenant d'autres exemples d'utilisation de graphiques de l'ego.
▍ Une alimentation saine
Chou! Délicieux!
Mais que faire si vous aviez envie de remplacer un beau chou incomparable par autre chose? Le graphe de l'ego construit autour du chou (
kale) vous y aidera .
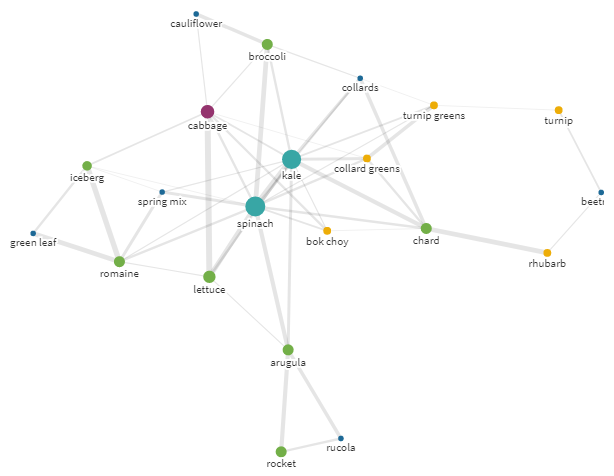
Graphique ego pour requête kale avec rayon 25
▍Nous achetons un chien
Il y a tellement de chiens, et si peu de temps ... J'ai besoin d'un chien. Mais lequel? Peut-être quelque chose comme un caniche (
poodle)?
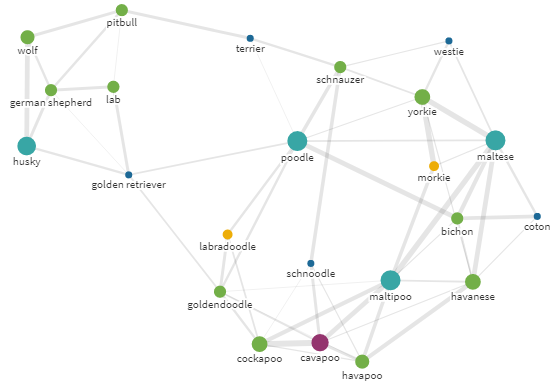
Graphique ego pour requête caniche avec rayon 18
▍ À la recherche de l'amour
Le chien et le chou ne changent rien? Besoin de trouver votre moitié? Si tel est le cas, voici un petit graphique de l'ego, mais très autonome, qui peut vous aider.

Graphique d'ego pour la demande de café et bagel de rayon 18
HatQue se passe-t-il si les applications de rencontres n'ont pas aidé?
Si les applications de rencontres ne sont pas utiles, cela vaut la peine de regarder l'émission au lieu de passer du temps avec de la glace au chou (ou une salade de roquette récemment découverte). Si vous aimez The Office (certainement celui qui a été tourné au Royaume-Uni), vous aimerez peut-être aussi certaines des autres séries.

Graphique de l'ego pour la requête de bureau avec un rayon 25
Résultat
Cela conclut mon histoire sur l'utilisation du mot "vs" dans les recherches Google et sur les graphiques de l'ego. J'espère que tout cela vous aidera au moins un peu dans votre recherche d'amour, d'un bon chien et d'une alimentation saine.
Utilisez-vous des techniques de recherche inhabituelles sur Internet?
