Qu'est-ce que la parole humaine? Ce sont des mots dont les combinaisons vous permettent d'exprimer telle ou telle information. La question se pose, comment savoir quand un mot se termine et un autre commence? La question est assez étrange, beaucoup penseront, car dès la naissance, nous entendons le discours des gens autour de nous, nous apprenons à parler, à écrire et à lire. Le bagage accumulé de connaissances linguistiques joue bien sûr un rôle important, mais il existe en outre des réseaux neuronaux du cerveau qui divisent le flux de la parole en mots et / ou syllabes. Aujourd'hui, nous allons nous familiariser avec une étude dans laquelle des scientifiques de l'Université de Genève (Suisse) ont créé un modèle de neuro-ordinateur de décodage de la parole en prédisant des mots et des syllabes. Quels processus cérébraux sont devenus la base du modèle, qu'entend-on par le grand mot «prédiction»,et quelle est l'efficacité du modèle créé? Les réponses à ces questions nous attendent dans le rapport des scientifiques. Aller.
Base d'étude
Pour nous, les humains, la parole humaine est compréhensible et articulée (le plus souvent). Mais pour une machine, ce n'est qu'un flux d'informations acoustiques, un signal solide qu'il faut décoder avant d'être compris.
Le cerveau humain agit à peu près de la même manière, cela se produit extrêmement rapidement et imperceptiblement pour nous. Les scientifiques pensent que le fondement de ce processus et de nombreux autres processus cérébraux sont certaines oscillations neuronales, ainsi que leurs combinaisons.
En particulier, la reconnaissance vocale est associée à une combinaison d'oscillations thêta et gamma, car elle permet de coordonner hiérarchiquement le codage des phonèmes en syllabes sans connaissance préalable de leur durée et de leur origine temporelle, c'est-à-dire traitement en amont * en temps réel.
* (bottom-up) — , .La reconnaissance vocale naturelle repose également fortement sur des indices contextuels pour prédire le contenu et la structure temporelle du signal vocal. Des études antérieures ont montré que lors de la perception de la parole continue, c'est le mécanisme de prédiction qui joue un rôle important. Ce processus est associé à des fluctuations bêta.
Un autre élément important de la reconnaissance vocale peut être appelé codage prédictif, lorsque le cerveau génère et met constamment à jour un modèle mental de l'environnement. Ce modèle est utilisé pour générer des prédictions tactiles qui sont comparées à la saisie tactile réelle. La comparaison du signal prévu et réel conduit à l'identification des erreurs qui servent à mettre à jour et à réviser le modèle mental.
En d'autres termes, le cerveau apprend toujours quelque chose de nouveau, mettant constamment à jour le modèle du monde qui l'entoure. Ce processus est considéré comme critique dans le traitement des signaux vocaux.
Les chercheurs notent que de nombreuses études théoriques soutiennent les approches ascendantes et descendantes * du traitement de la parole.
Perfectionnement à la baisse * ( top-down ) - analyse des composants du système pour la soumission de ses sous-systèmes composites par rétro-ingénierie.Un modèle de neuro-ordinateur précédemment développé, impliquant la connexion de réseaux réalistes d'excitation / inhibition thêta et gamma, a pu pré-traiter la parole afin qu'elle puisse ensuite être correctement décodée.
Un autre modèle, basé uniquement sur le codage prédictif, pourrait reconnaître avec précision des éléments de discours individuels (tels que des mots ou des phrases complètes, si nous les considérons comme un seul élément de discours).
Par conséquent, les deux modèles ont fonctionné, juste dans des directions différentes. L'un se concentrait sur l'aspect d'analyse de la parole en temps réel et l'autre sur la reconnaissance de segments de parole isolés (aucune analyse requise).
Mais que se passe-t-il si nous combinons les principes de base de ces modèles radicalement différents en un seul? Selon les auteurs de l'étude que nous envisageons, cela améliorera les performances et augmentera le réalisme biologique des modèles de traitement de la parole par neuro-ordinateur.
Dans leur travail, les scientifiques ont décidé de vérifier si un système de reconnaissance vocale basé sur un codage prédictif pouvait bénéficier des processus d'oscillations neuronales.
Ils ont développé le modèle de neuro-ordinateur Precoss (à partir du codage prédictif et des oscillations de la parole ), basé sur la structure de codage prédictif, auquel ils ont ajouté des fonctions oscillatoires thêta et gamma pour faire face à la nature continue de la parole naturelle.
Le but spécifique de ce travail était de trouver la réponse à la question de savoir si une combinaison de codage prédictif et d'oscillations neuronales peut être bénéfique pour l'identification rapide des composantes syllabiques des phrases naturelles. En particulier, les mécanismes par lesquels les ondes thêta peuvent interagir avec les flux d'information en amont et en aval ont été examinés, et l'impact de cette interaction sur l'efficacité du processus de décodage des syllabes a été évalué.
Architecture de modèle de précoss
Une fonction importante du modèle est qu'il doit être capable d'utiliser les signaux / informations temporaires présents dans la parole continue pour déterminer les limites des syllabes. Les scientifiques ont suggéré que les modèles génératifs internes, y compris les prédictions temporelles, devraient bénéficier de ces signaux. Pour tenir compte de cette hypothèse, ainsi que des processus répétitifs qui se produisent pendant la reconnaissance vocale, un modèle de codage prédictif continu a été utilisé.
Le modèle développé sépare clairement «quoi» et «quand». «Quoi» fait référence à l'identité d'une syllabe et à sa représentation spectrale (non pas temporelle, mais séquence ordonnée de vecteurs spectraux); «Quand» fait référence à la prédiction du moment et de la durée des syllabes.
En conséquence, les prédictions prennent deux formes: le début d'une syllabe, signalé par le module thêta; et la durée des syllabes, signalée par des oscillations thêta exogènes / endogènes, qui définissent la durée de la séquence unitaire synchronisée gamma (diagramme ci-dessous).
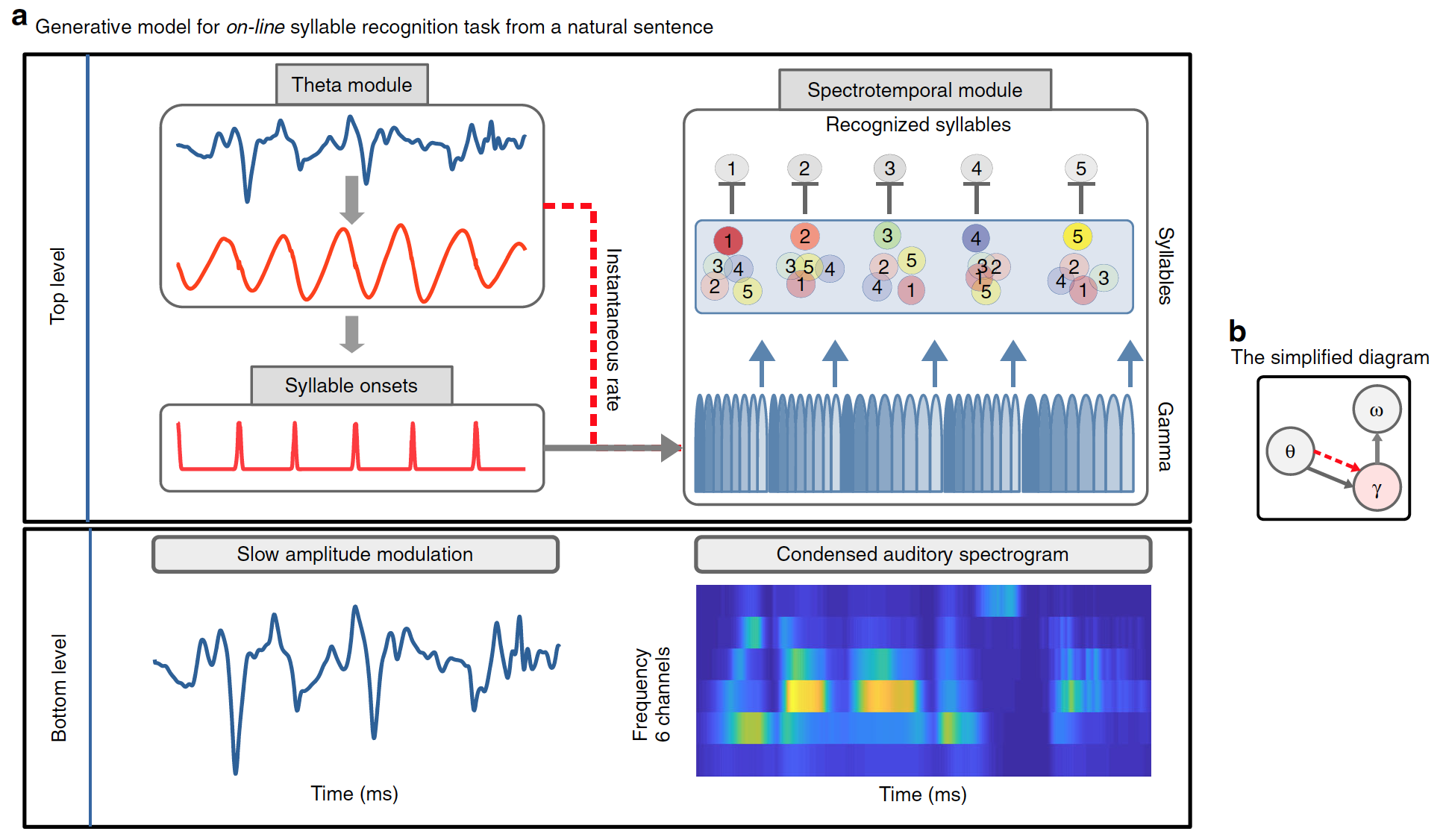
Image # 1
Precoss extrait un signal sensoriel des représentations internes de sa source en se référant à un modèle génératif. Dans ce cas, l'entrée sensorielle correspond à la modulation d'amplitude lente du signal de parole et au spectrogramme auditif à 6 canaux de la phrase naturelle complète, que le modèle génère en interne à partir de quatre composants:
- thêta vacille;
- une unité de modulation d'amplitude lente dans un module thêta;
- pool d'unités syllabiques (autant de syllabes qu'il y en a dans la phrase d'introduction naturelle, c'est-à-dire de 4 à 25);
- banque de huit unités gamma dans le module spectrotemporel.
Ensemble, les unités de syllabes et d'oscillations gamma génèrent des prédictions à la baisse concernant le spectrogramme d'entrée. Chacune des huit unités gamma représente une phase dans une syllabe; ils sont activés séquentiellement et toute la séquence d'activation est répétée. Par conséquent, chaque unité de syllabe est associée à une séquence de huit vecteurs (un par unité gamma) avec six composantes chacune (une par canal de fréquence). Un spectrogramme acoustique d'une syllabe individuelle est généré en activant l'unité correspondante de la syllabe pendant toute la durée de la syllabe.
Alors que le bloc de syllabe code un motif acoustique spécifique, les blocs gamma utilisent temporairement la prédiction spectrale correspondante pendant la durée de la syllabe. L'onde thêta donne des informations sur la longueur d'une syllabe, car sa vitesse instantanée affecte la vitesse / durée de la séquence gamma.
Enfin, les données accumulées sur la syllabe voulue doivent être supprimées avant de traiter la syllabe suivante. Pour ce faire, le dernier (huitième) bloc gamma, qui code la dernière partie d'une syllabe, réinitialise toutes les unités syllabiques à un niveau d'activation global faible, ce qui permet de collecter de nouvelles preuves.
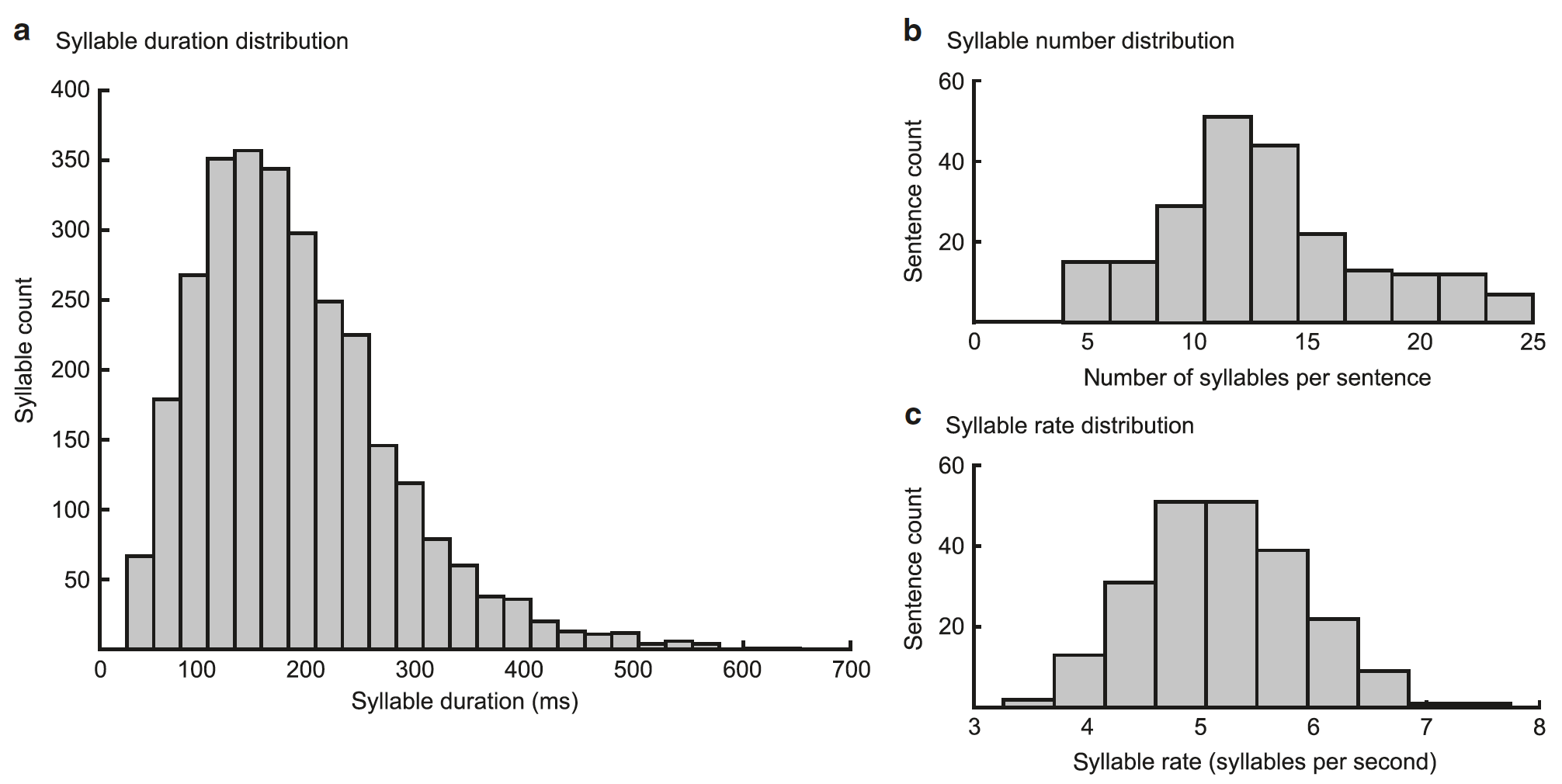
Image n ° 2
Les performances du modèle dépendent du fait que la séquence gamma coïncide avec le début d'une syllabe et si sa durée correspond à la durée d'une syllabe (50–600 ms, moyenne = 182 ms).
L'estimation du modèle par rapport à la séquence de syllabes est fournie par les unités de syllabes, qui, conjointement avec les unités gamma, génèrent les motifs spectro-temporels attendus (le résultat de l'opération du modèle), qui sont comparés au spectrogramme d'entrée. Le modèle met à jour ses estimations de la syllabe actuelle afin de minimiser la différence entre le spectrogramme généré et le spectrogramme réel. Le niveau d'activité augmente dans ces unités syllabiques, dont le spectrogramme correspond à une entrée sensorielle, et diminue dans d'autres. Dans le cas idéal, la minimisation des erreurs de prévision en temps réel conduit à une activité accrue dans une unité de syllabe distincte correspondant à la syllabe d'entrée.
Résultats de la simulation
Le modèle présenté ci-dessus comprend des oscillations thêta motivées physiologiquement, qui sont contrôlées par des modulations d'amplitude lentes du signal de parole et transmettent des informations sur le début et la durée de la syllabe à la composante gamma.
Cette liaison thêta-gamma fournit un alignement temporaire des prédictions générées en interne avec les limites de syllabe détectées par les données d'entrée (option A dans l'image n ° 3).
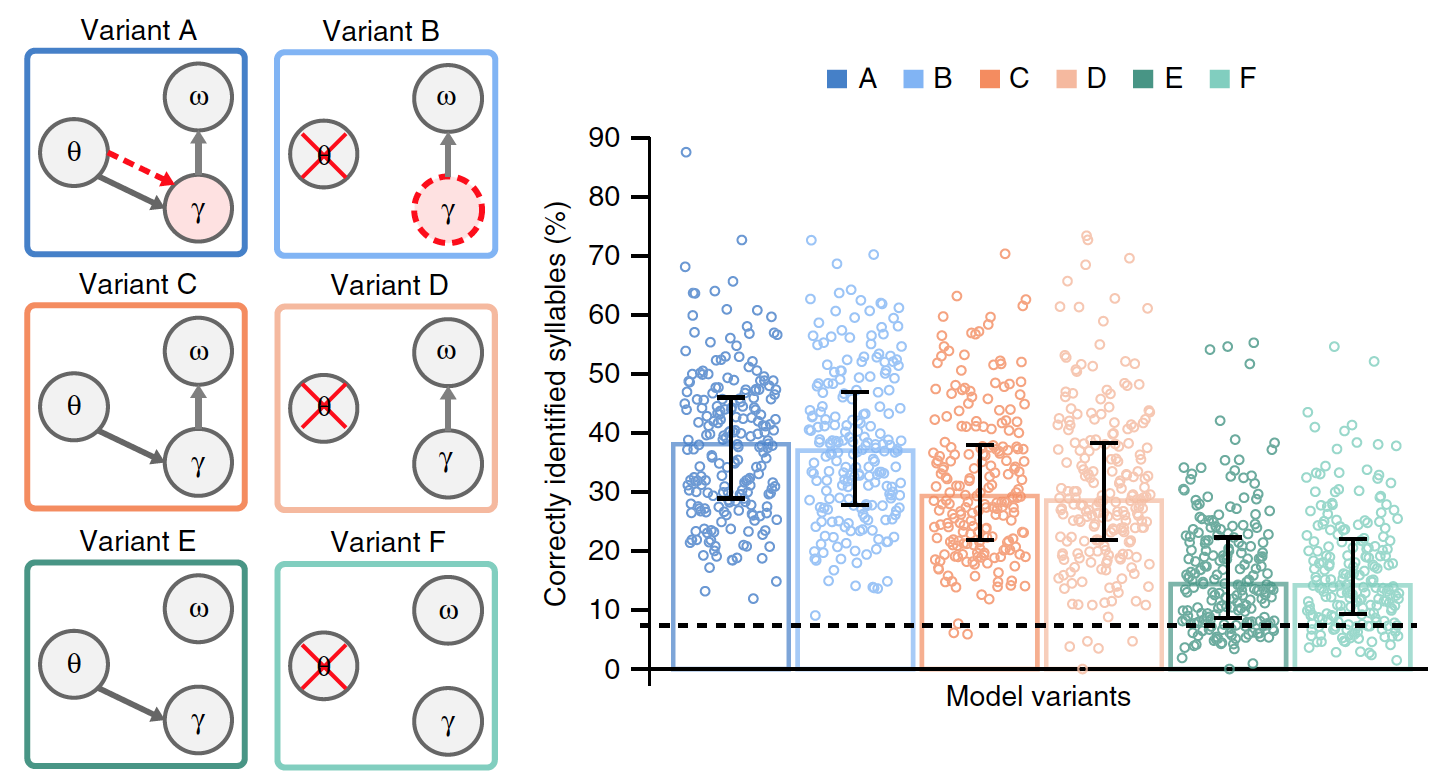
Image # 3
Pour évaluer la pertinence de la synchronisation des syllabes basée sur une modulation d'amplitude lente, le modèle A a été comparé à l'option B, dans laquelle l'activité thêta n'est pas modélisée par des oscillations, mais résulte de l'auto-répétition de la séquence gamma.
Dans le modèle B, la durée de la séquence gamma n'est plus contrôlée de manière exogène (en raison de facteurs externes) par des oscillations thêta, mais de manière endogène (en raison de facteurs internes), elle utilise le taux gamma préféré, qui, lorsque la séquence est répétée, conduit à la formation d'un rythme thêta interne. Comme dans le cas des oscillations thêta, la durée de la séquence gamma a une vitesse préférée dans la gamme thêta, qui peut potentiellement s'adapter à des durées syllabiques variables. Dans ce cas, il est possible de tester le rythme thêta résultant de la répétition de la séquence gamma.
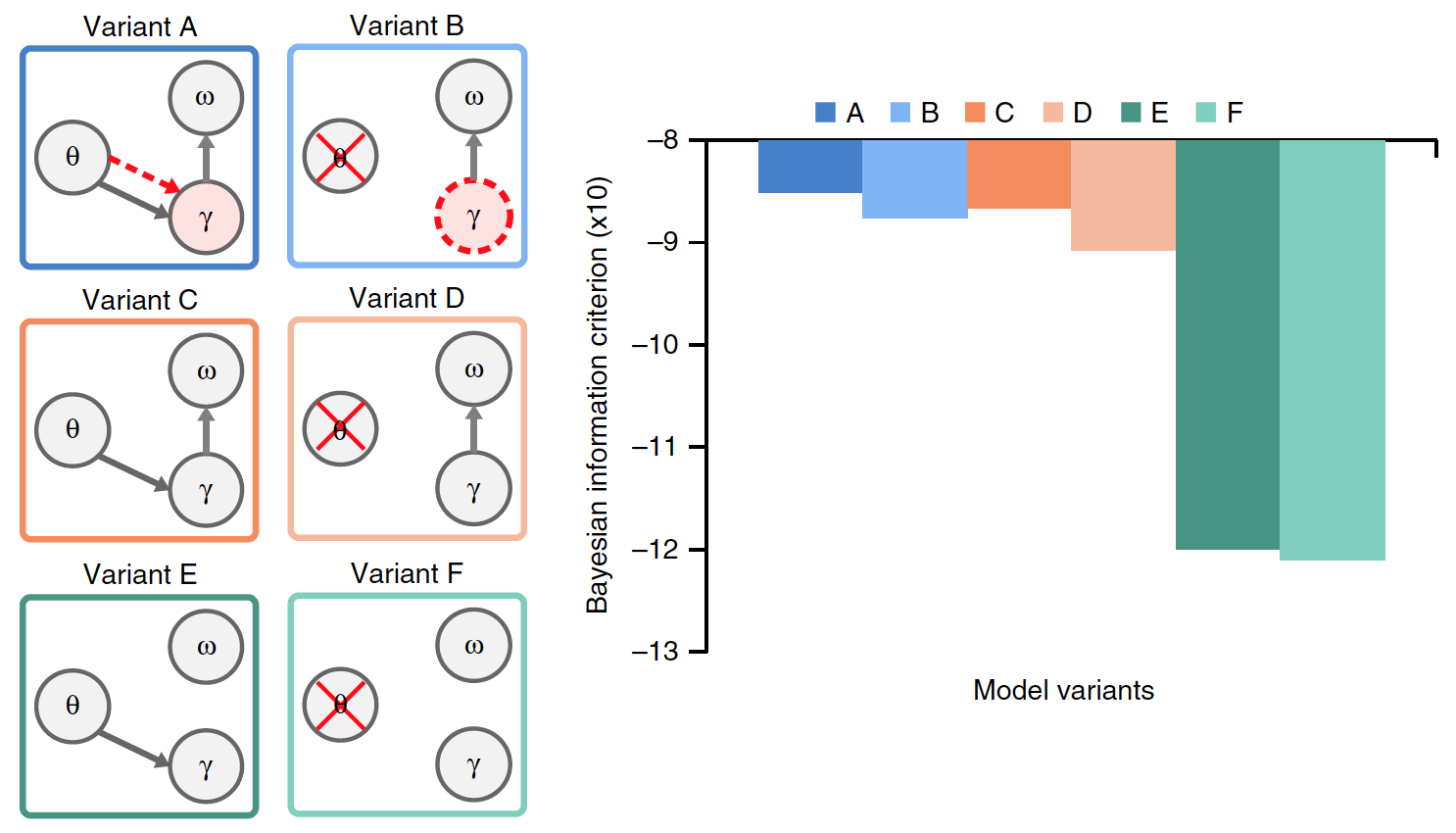
Pour évaluer plus précisément les effets spécifiques du thêta gamma de la composition et du rejet des données accumulées en unités syllabiques, des versions supplémentaires des modèles A et B précédents ont été faites.
Les options C et D se distinguaient par l'absence d'un taux de rayonnement gamma préféré. Les options E et F différaient en outre des options C et D en l'absence de réinitialisation des données accumulées sur les syllabes.
De toutes les variantes du modèle, seul A a une véritable connexion thêta-gamma, où l'activité gamma est déterminée par le module thêta, tandis que dans le modèle, la vitesse gamma est définie de manière endogène.
Il a fallu déterminer laquelle des variantes du modèle est la plus efficace, pour laquelle les résultats de leurs travaux ont été comparés en présence de données d'entrée communes (phrases naturelles). Le graphique de l'image ci-dessus montre les performances moyennes de chacun des modèles.
Des différences significatives étaient présentes entre les options. Par rapport aux modèles A et B, les performances étaient nettement inférieures dans les modèles E et F (23% en moyenne) et C et D (15%). Cela indique que l'effacement des données accumulées sur une syllabe précédente avant de traiter une nouvelle syllabe est un facteur critique dans le codage d'un flux de syllabes dans la parole naturelle.
La comparaison des options A et B avec les options C et D a montré que la connexion thêta-gamma, qu'elle soit stimulante (A) ou endogène (B), améliore considérablement les performances du modèle (en moyenne 8,6%).
D'une manière générale, des expériences avec différentes versions des modèles ont montré que cela fonctionnait mieux lorsque les unités syllabiques étaient réinitialisées après chaque séquence d'unités gamma (sur la base d'informations internes sur la structure spectrale de la syllabe), et lorsque le taux de rayonnement gamma était déterminé par couplage thêta-gamma.
La performance du modèle avec des phrases naturelles, par conséquent, ne dépend pas de la signalisation précise du début des syllabes par des oscillations thêta contrôlées par le stimulus, ni du mécanisme exact de la communication thêta-gamma.
Comme les scientifiques l'admettent eux-mêmes, c'est une découverte assez surprenante. D'un autre côté, l'absence de différences de performances entre la relation thêta-gamma pilotée par stimulus et endogène reflète le fait que la durée des syllabes dans la parole naturelle est très proche des attentes du modèle, auquel cas il n'y aura aucun avantage pour le signal thêta piloté directement par l'entrée.
Pour mieux comprendre une telle tournure des événements inattendue, les scientifiques ont mené une autre série d'expériences, mais avec des signaux vocaux compressés (x2 et x3). Comme le montrent les études comportementales, la compréhension de la parole compressée x2 ne change pratiquement pas, mais elle diminue considérablement lorsqu'elle est compressée par 3.
Dans ce cas, une liaison thêta-gamma stimulée peut être extrêmement utile pour analyser et décoder les syllabes. Les résultats de la simulation sont présentés ci-dessous.

Image # 4
Comme prévu, les performances globales ont chuté à mesure que le taux de compression augmentait. Pour la compression x2, il n'y avait toujours pas de différence significative entre le stimulus et la relation thêta-gamma endogène. Mais dans le cas de la compression x3, il y a une différence significative. Cela suggère que l'oscillation thêta stimulée par le stimulus, entraînant la liaison thêta-gamma, était plus bénéfique pour le processus de codage des syllabes que la vitesse thêta définie de manière endogène.
Il s'ensuit que la parole naturelle peut être traitée à l'aide d'un générateur de thêta endogène relativement fixe. Mais pour les signaux vocaux d'entrée plus complexes (c'est-à-dire lorsque le débit de parole change constamment), un générateur thêta contrôlé est nécessaire, qui fournit au codeur gamma des informations temporelles précises sur les syllabes (début de syllabe et durée de syllabe).
La capacité du modèle à reconnaître avec précision les syllabes dans la phrase d'entrée ne tient pas compte de la complexité variable des divers modèles comparés. Par conséquent, un critère d'information bayésien (BIC) a été évalué pour chaque modèle. Ce critère quantifie le compromis entre précision et complexité du modèle (image n ° 5).
L'
option A de l' image 5 a montré les valeurs BIC les plus élevées. Une comparaison précédente des modèles A et B n'a pas pu distinguer avec précision leurs performances. Cependant, grâce au critère BIC, il est devenu clair que la variante A offre une reconnaissance de syllabe plus sûre que le modèle sans oscillations thêta stimulées (modèle B).
Pour une connaissance plus détaillée des nuances de l'étude, je recommande d'examiner le rapport des scientifiques etdes matériaux supplémentaires .
Épilogue
En résumant les résultats ci-dessus, nous pouvons dire que le succès du modèle dépend de deux facteurs principaux. Le premier et le plus important est la réinitialisation des données accumulées en fonction des informations du modèle sur le contenu de la syllabe (dans ce cas, il s'agit de sa structure spectrale). Le deuxième facteur est la relation entre les processus thêta et gamma, qui garantit que l'activité gamma est incluse dans le cycle thêta, correspondant à la durée attendue d'une syllabe.
En substance, le modèle développé imitait le travail du cerveau humain. Le son entrant dans le système était modulé par une onde thêta, rappelant l'activité neuronale. Cela vous permet de définir les limites des syllabes. De plus, des ondes gamma plus rapides aident à coder la syllabe. Dans le processus, le système propose des syllabes possibles et ajuste la sélection si nécessaire. En sautant entre les premier et deuxième niveaux (thêta et gamma), le système découvre la version correcte de la syllabe, puis est remis à zéro pour recommencer le processus pour la syllabe suivante.
Au cours des tests pratiques, 2888 syllabes ont été décodées avec succès (220 phrases de langage naturel, l'anglais a été utilisé).
Cette étude a non seulement combiné deux théories opposées, les mettant en pratique comme un système unique, mais a également permis de mieux comprendre comment notre cerveau perçoit les signaux de la parole. Il nous semble que nous percevons la parole "telle quelle", c'est-à-dire sans processus de support compliqué. Cependant, compte tenu des résultats de la simulation, il s'avère que les oscillations neuronales thêta et gamma permettent à notre cerveau de faire de petites prédictions sur la syllabe que nous entendons, sur la base de laquelle la perception de la parole est formée.
Quiconque dit quoi que ce soit, mais le cerveau humain semble parfois beaucoup plus mystérieux et incompréhensible que les coins inexplorés de l'Univers ou les profondeurs désespérées de l'océan mondial.
Merci de votre attention, restez curieux et bonne semaine de travail, les gars. :)
Un peu de publicité
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir du contenu plus intéressant? Soutenez-nous en passant une commande ou en recommandant à des amis, VPS cloud pour les développeurs à partir de 4,99 $ , un analogue unique des serveurs d'entrée de gamme, qui a été inventé par nous pour vous: Toute la vérité sur VPS (KVM) E5-2697 v3 (6 cœurs) 10 Go DDR4 480 Go SSD 1 Gbps à partir de 19 $ ou comment diviser le serveur correctement? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher au centre de données Equinix Tier IV à Amsterdam? Nous avons seulement 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas!Dell R420 - 2x E5-2430 2,2 Ghz 6C 128 Go DDR3 2x960 Go SSD 1 Gbps 100 To - à partir de 99 $! Lisez à propos de Comment construire l'infrastructure de bldg. classe avec l'utilisation de serveurs Dell R730xd E5-2650 v4 coûtant 9000 euros pour un sou?