
Dodo Pizza compte plus de 600 pizzerias dans 13 pays du monde, et la plupart des processus dans les pizzerias sont contrôlés à l' aide du système d' information Dodo IS , que nous écrivons et soutenons. Par conséquent, la fiabilité et la stabilité du système sont importantes pour la survie.
Désormais, la stabilité et la fiabilité du système d'information de l'entreprise sont prises en charge par l'équipe SRE ( Site Reliability Engineering ), mais cela n'a pas toujours été le cas.
Contexte: mondes parallèles de développeurs et d'infrastructures
Pendant de nombreuses années, j'ai développé en tant que développeur fullstack typique (et un peu scrum master), appris à écrire du bon code, appliqué les pratiques d'Extreme Programming et réduit soigneusement le nombre de WTF dans les projets que j'ai touchés. Mais plus l'expérience apparaissait dans le développement de logiciels, plus je réalisais l'importance de systèmes fiables pour la surveillance et le traçage des applications, de journaux de haute qualité, de tests automatiques totaux et de mécanismes pour assurer une haute fiabilité des services. Et de plus en plus souvent, il a commencé à regarder «par-dessus la clôture» pour l'équipe d'infrastructure.
Mieux je comprenais l'environnement dans lequel mon code fonctionne, plus j'étais surpris: les tests automatiques pour tout et pour tout, CI, versions fréquentes, refactoring sécurisé et propriété collective du code dans le monde du logiciel sont depuis longtemps routiniers et familiers. Dans le même temps, dans le monde des «infrastructures», l'absence de tests automatiques, la modification des systèmes de production en mode semi-manuel est encore normale, et la documentation n'est souvent que dans la tête des individus, mais pas dans le code.
Ce fossé culturel et technologique provoque non seulement la confusion, mais aussi des problèmes: à l'intersection du développement, des infrastructures et des affaires. Certains des problèmes d'infrastructure sont difficiles à résoudre en raison de la proximité du matériel et des outils relativement peu développés. Mais le reste peut être vaincu si vous commencez à regarder tous vos playbooks et scripts Bash Ansible comme un produit logiciel à part entière et à leur appliquer les mêmes exigences.
Triangle des problèmes des Bermudes
Cependant, je partirai de loin - avec les problèmes pour lesquels toutes ces danses sont nécessaires.
Problèmes de développeur
Il y a deux ans, nous nous sommes rendu compte qu'une grande chaîne de pizzas ne pouvait pas vivre sans sa propre application mobile et avons décidé de l'écrire:
- mettre sur pied une grande équipe;
- pendant six mois, ils ont rédigé une application pratique et belle;
- soutenu le grand lancement avec de délicieuses promotions;
- et le premier jour est tombé en toute sécurité sous charge.
Il y avait beaucoup de jambages au départ, bien sûr, mais surtout je m'en souviens. Au moment du développement, un serveur faible était déployé en production, presque une calculatrice, qui traitait les requêtes de l'application. Avant l'annonce publique de l'application, elle devait être augmentée - nous vivons dans Azure, et cela a été résolu en cliquant sur un bouton.
Mais personne n'a appuyé sur ce bouton: l'équipe d'infrastructure ne savait même pas qu'une sorte d'application serait publiée aujourd'hui. Ils ont décidé qu'il était de la responsabilité de l'équipe d'application de superviser la production du service "non critique". Et le développeur backend (c'était son premier projet dans Dodo) a décidé que les gars de l'infrastructure le faisaient dans les grandes entreprises.
Ce développeur, c'était moi. Puis j'ai déduit pour moi une règle évidente mais importante:
, , , . .
Ce n'est pas difficile maintenant. Ces dernières années, un grand nombre d'outils sont apparus qui permettent aux programmeurs de se plonger dans le monde de l'exploitation et de ne rien casser: Prometheus, Zipkin, Jaeger, ELK stack, Kusto.
Cependant, de nombreux développeurs ont encore de sérieux problèmes avec ceux appelés infrastructure / DevOps / SRE. En conséquence, les programmeurs:
dépendent de l'équipe d'infrastructure. Cela provoque de la douleur, des malentendus, parfois de la haine mutuelle.
Ils conçoivent leurs systèmes indépendamment de la réalité et ne prennent pas en compte où et comment leur code sera exécuté. Par exemple, l'architecture et la conception d'un système en cours de développement pour la vie dans le cloud seront différentes de celles d'un système hébergé sur site.
Ils ne comprennent pas la nature des bogues et des problèmes associés à leur code.Cela est particulièrement visible lorsque les problèmes sont liés à la charge, à l'équilibrage des requêtes, aux performances du réseau ou du disque dur. Les développeurs n'ont pas toujours cette connaissance.
Impossible d'optimiser l'argent et les autres ressources de l'entreprise qui sont utilisées pour maintenir leur code. D'après notre expérience, il arrive que l'équipe d'infrastructure inonde simplement le problème d'argent, par exemple en augmentant la taille du serveur de base de données en production. Par conséquent, les problèmes de code n'atteignent souvent même pas les programmeurs. C'est juste que pour une raison quelconque, l'infrastructure commence à coûter plus cher.
Problèmes d'infrastructure
Il y a aussi des difficultés «de l'autre côté».
Il est difficile de gérer des dizaines de services et d'environnements sans code de qualité. Nous avons plus de 450 référentiels sur GitHub. Certains d'entre eux ne nécessitent pas de support opérationnel, certains sont morts et enregistrés pour l'historique, mais une partie importante contient des services qui doivent être pris en charge. Ils doivent héberger quelque part, ils ont besoin de surveillance, de collecte de journaux, de pipelines CI / CD uniformes.
Pour gérer tout cela, nous avons récemment utilisé activement Ansible. Notre référentiel Ansible contenait:
- 60 rôles;
- 102 livres de jeu;
- liaison en Python et Bash;
- tests manuels en Vagrant.
Tout a été écrit par une personne intelligente et bien écrit. Mais, dès que d'autres développeurs de l'infrastructure et des programmeurs ont commencé à travailler activement avec ce code, il s'est avéré que les playbooks se cassent et que les rôles sont dupliqués et "envahis par la mousse".
La raison en était que ce code n'utilisait pas la plupart des pratiques standard dans le monde du développement logiciel. Il n'avait pas de pipeline CI / CD, et les tests étaient compliqués et lents, donc tout le monde était trop paresseux ou "pas le temps" de les exécuter manuellement, sans parler d'en écrire de nouveaux. Un tel code est voué à l'échec si plus d'une personne y travaille.
Sans connaissance du code, il est difficile de répondre efficacement aux incidents.Lorsqu'une alerte arrive à PagerDuty à 3 heures du matin, vous devez rechercher un programmeur qui vous expliquera quoi et comment. Par exemple, que ces erreurs 500 affectent l'utilisateur, alors que d'autres sont liées au service secondaire, les clients finaux ne le voient pas et vous pouvez le laisser ainsi jusqu'au matin. Mais à trois heures du matin, il est difficile de réveiller les programmeurs, il est donc conseillé de comprendre comment fonctionne le code que vous supportez.
De nombreux outils nécessitent une intégration dans le code de l'application. Les responsables de l'infrastructure savent ce qu'il faut surveiller, comment se connecter et à quoi faire attention pour le traçage. Mais ils ne peuvent souvent pas intégrer tout cela dans le code de l'application. Et ceux qui le peuvent, ne savent pas quoi et comment intégrer.
"Téléphone cassé".Expliquer quoi et comment surveiller pour la centième fois est désagréable. Il est plus facile d'écrire une bibliothèque partagée à transmettre aux programmeurs pour réutilisation dans leurs applications. Mais pour ce faire, vous devez être capable d'écrire du code dans le même langage, dans le même style et avec les mêmes approches que celles utilisées par vos développeurs d'applications.
Problèmes commerciaux
L'entreprise a également deux gros problèmes qui doivent être résolus.
Pertes directes dues à l'instabilité du système liées à la fiabilité et à la disponibilité.
En 2018, nous avons eu 51 incidents critiques et les éléments critiques du système n'ont pas fonctionné pendant plus de 20 heures au total. En termes monétaires, cela représente 25 millions de roubles de pertes directes dues aux commandes non livrées et non livrées. Et combien nous avons perdu sur la confiance des employés, des clients et des franchisés est impossible à calculer, cela n'est pas évalué en argent.
Coûts de support pour l'infrastructure actuelle. Parallèlement, l'entreprise s'est fixé un objectif pour 2018: réduire de 3 fois le coût des infrastructures par pizzeria. Mais ni les programmeurs ni les ingénieurs DevOps au sein de leurs équipes ne pourraient même arriver à résoudre ce problème. Il y a des raisons pour cela:
- , ;
- , operations ( DevOps), ;
- , .
?
Comment résoudre tous ces problèmes? Nous avons trouvé la solution dans le livre "Site Reliability Engineering" de Google. Quand nous l'avons lu, nous avons compris - c'est ce dont nous avons besoin.
Mais il y a une nuance - il faut des années pour mettre en œuvre tout cela, et il faut commencer quelque part. Considérez les données initiales que nous avions initialement.
Toute notre infrastructure vit presque entièrement dans Microsoft Azure. Il existe plusieurs pôles de vente indépendants répartis sur différents continents: Europe, Amérique et Chine. Il existe des supports de charge qui répètent la production, mais qui vivent dans un environnement isolé, ainsi que des dizaines d'environnements DEV pour les équipes de développement.
Parmi les bonnes pratiques SRE que nous avions déjà:
- mécanismes de surveillance des applications et des infrastructures (spoiler: en 2018 nous les pensions bons, mais maintenant nous avons déjà tout réécrit);
- 24/7 on-call;
- ;
- ;
- CI/CD- ;
- , ;
- SRE .
Mais il y avait des problèmes que je voulais résoudre en premier lieu:
l'équipe d'infrastructure était surchargée. Il n'y avait pas assez de temps et d'efforts pour des améliorations globales en raison du système d'exploitation actuel. Par exemple, nous voulions depuis très longtemps, mais n'avons pas pu nous débarrasser d'Elasticsearch dans notre stack, ni dupliquer l'infrastructure d'un autre fournisseur de cloud pour éviter les risques (ceux qui ont déjà essayé le multicloud peuvent rire ici).
Chaos dans le code. Le code d'infrastructure était chaotique, dispersé dans différents référentiels et non documenté nulle part. Tout était basé sur la connaissance des individus et rien d'autre. C'était un gigantesque problème de gestion des connaissances.
«Il y a des programmeurs, mais il y a des ingénieurs d'infrastructure.»Malgré le fait que nous ayons une culture DevOps assez bien développée, il y avait toujours cette séparation. Deux classes de personnes avec des expériences complètement différentes, parlant des langues différentes et utilisant différents outils. Bien sûr, ils sont amis et communiquent, mais souvent ne se comprennent pas à cause d'expériences complètement différentes.
Équipes d'intégration SRE
Pour résoudre ces problèmes et commencer à évoluer vers SRE, nous avons lancé un projet d'intégration. Mais ce n'était pas une intégration classique - la formation de nouveaux employés (nouveaux arrivants) pour ajouter des personnes à l'équipe actuelle. Il s'agissait de la création d'une nouvelle équipe d'ingénieurs et de programmeurs d'infrastructure - la première étape vers une structure SRE à part entière.
Nous avons alloué 4 mois au projet et fixé trois objectifs:
- Former les programmeurs avec les connaissances et les compétences requises pour les tâches et les activités opérationnelles dans l'équipe d'infrastructure.
- Écrivez IaC - une description de toute l'infrastructure dans le code. De plus, il devrait s'agir d'un logiciel complet avec des tests CI / CD.
- Recréez toute notre infrastructure à partir de ce code et oubliez de cliquer manuellement sur les machines virtuelles avec la souris dans Azure.
Composition des participants: 9 personnes, 6 de l'équipe de développement, 3 de l'infrastructure. Pendant 4 mois, ils ont dû quitter le travail normal et se plonger dans les tâches désignées. Pour maintenir la «vie» en entreprise, 3 autres personnes de l'infrastructure sont restées en service, s'occupent des systèmes d'exploitation et couvrent l'arrière. En conséquence, le projet a été sensiblement étiré et a duré plus de cinq mois (de mai à octobre 2019).
Deux composantes de l'intégration: la formation et la pratique
L'intégration se composait de deux parties: apprendre et travailler sur l'infrastructure en code.
Formation. Au moins 3 heures par jour ont été allouées à la formation:
- pour lire les articles et livres de la liste des références: Linux, réseaux, SRE;
- lors de conférences sur des outils et technologies spécifiques;
- aux clubs technologiques, tels que Linux, où nous avons analysé des cas complexes et des cas.
Un autre outil d'apprentissage est la démo interne. Il s'agit d'une réunion hebdomadaire où chacun (qui a quelque chose à dire) en 10 minutes a parlé de la technologie ou du concept qu'il a implémenté dans notre code pour la semaine. Par exemple, Vasya a changé le pipeline pour travailler avec les modules Terraform, et Petya a réécrit l'assemblage d'image à l'aide de Packer.
Après la démo, nous avons commencé les discussions sous chaque sujet dans Slack, où les participants intéressés pouvaient discuter de manière asynchrone de tout plus en détail. Nous avons donc évité de longues réunions pour 10 personnes, mais en même temps tout le monde dans l'équipe comprenait bien ce qui se passait avec notre infrastructure et où nous allions.

Entraine toi. La deuxième partie de l'intégration consiste à créer / décrire l'infrastructure dans le code . Cette partie a été divisée en plusieurs étapes.
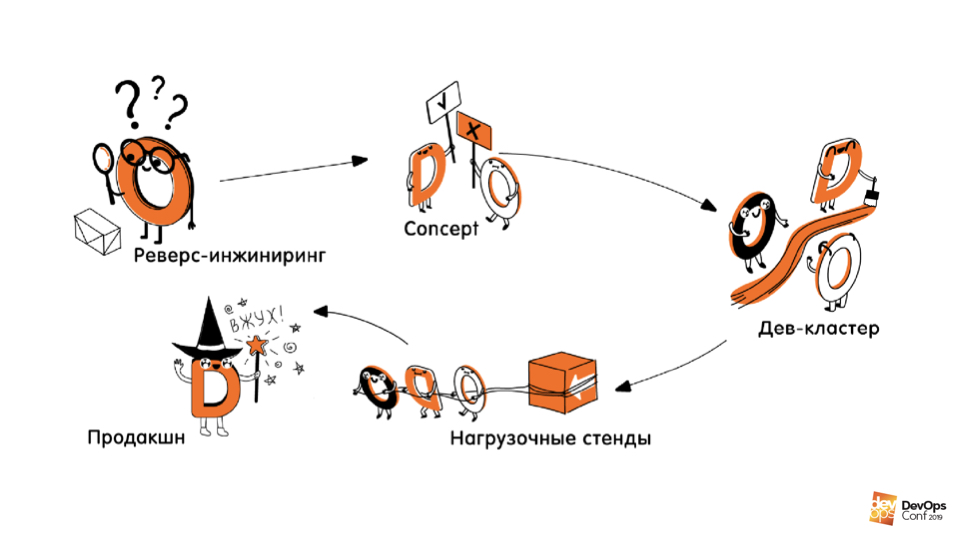
Ingénierie inverse de l'infrastructure.Il s'agit de la première étape au cours de laquelle nous avons analysé ce qui est déployé où, comment ce qui fonctionne, où quels services fonctionnent, où quelles machines et leurs tailles. Tout est entièrement documenté.
Concepts. Nous avons expérimenté différentes technologies, langages, approches, compris comment décrire notre infrastructure, quels outils utiliser pour cela.
Écriture de code. Cela comprenait l'écriture du code lui-même, la création de pipelines CI / CD, des tests et la création de processus autour de tout cela. Nous avons écrit le code qui décrit et avons su créer notre infrastructure de développement à partir de zéro.
Recréer est synonyme de test de charge et de production.Il s'agit de la quatrième étape qui devait se dérouler après l'intégration, mais elle a été reportée pour l'instant, car le profit en est, curieusement, bien inférieur à celui des jeunes filles qui sont créées / recréées très souvent.
Au lieu de cela, nous sommes passés aux activités de projet: nous nous sommes séparés en petites sous-commandes et avons repris ces projets d'infrastructure globale qui n'avaient pas été atteints auparavant. Et bien sûr, nous avons rejoint la montre.
Nos outils pour l'IaC
- Terraform .
- Packer Ansible .
- Jsonnet Python .
- Azure, .
- VS Code — IDE, , , , .
- — , .
Pratiques de programmation extrêmes dans l'infrastructure
La principale chose que nous, en tant que programmeurs, avons apportée avec nous, ce sont les pratiques de programmation extrême que nous utilisons dans notre travail. XP est une méthodologie de développement logiciel flexible qui combine la compression des meilleures approches, pratiques et valeurs de développement.
Il n'y a pas un seul programmeur qui n'utiliserait pas au moins certaines des pratiques de programmation extrême, même s'il ne le sait pas. Dans le même temps, dans le monde des infrastructures, ces pratiques sont contournées, malgré le fait qu'elles chevauchent beaucoup les pratiques de Google SRE.
Il y a un article séparé sur la façon dont nous avons adapté XP pour l'infrastructure .. Mais en bref: les pratiques XP fonctionnent également pour le code d'infrastructure, bien qu'avec des limitations, des adaptations, mais elles fonctionnent. Si vous souhaitez les appliquer à la maison, invitez des personnes expérimentées dans l'application de ces pratiques. La plupart de ces pratiques sont décrites d'une manière ou d'une autre dans le même livre sur le SRE .
Cela aurait pu bien se passer, mais cela ne fonctionne pas de cette façon.
Problèmes techniques et d'origine humaine en cours de route
Il y avait deux types de problèmes dans le projet:
- Techniques : limites du monde «de fer», manque de connaissances et d'outils bruts qui ont dû être utilisés car il n'y en a pas d'autres. Ce sont des problèmes courants pour tout programmeur.
- Humain : l'interaction des personnes dans une équipe. Communication, prise de décision, formation. Avec cela, c'était pire, nous devons donc nous attarder plus en détail.
Nous avons commencé à développer l'équipe d'intégration comme nous le ferions avec n'importe quelle autre équipe de programmation. Nous nous attendions à ce qu'il y ait les étapes habituelles de formation d'une équipe selon Tuckman : prise d'assaut, rationnement, et à la fin nous arriverons à la productivité et au travail productif. Par conséquent, ils ne craignaient pas qu'au début il y ait eu des difficultés de communication, de prise de décision, des difficultés pour se mettre d'accord.
Deux mois se sont écoulés, mais la phase d'assaut s'est poursuivie. Seulement plus près de la fin du projet, nous avons réalisé que tous les problèmes avec lesquels nous nous débattions et que nous ne percevions pas comme liés les uns aux autres étaient le résultat d'un problème fondamental commun - deux groupes de personnes complètement différentes se sont réunis en équipe:
- Des programmeurs expérimentés avec des années d'expérience, pour lesquels ils ont développé leurs propres approches, habitudes et valeurs au travail.
- Un autre groupe du monde des infrastructures avec sa propre expérience. Ils ont des bosses différentes, des habitudes différentes, et ils pensent aussi qu'ils savent vivre correctement.
Il y avait un affrontement de deux points de vue sur la vie dans une équipe. Nous ne l'avons pas vu tout de suite et n'avons pas commencé à travailler avec, ce qui nous a fait perdre beaucoup de temps, d'énergie et de nerfs.
Mais éviter cette collision est impossible. Si vous invitez des programmeurs forts et des ingénieurs d'infrastructure faibles au projet, vous aurez un échange de connaissances à sens unique. Au contraire, cela ne fonctionne pas non plus - certains en avalent d'autres et c'est tout. Et vous devez obtenir un certain mélange, vous devez donc être préparé au fait que le "broyage" peut être très long (dans notre cas, nous n'avons pu stabiliser l'équipe qu'un an plus tard, tout en disant au revoir à l'un des ingénieurs les plus forts techniquement).
Si vous souhaitez constituer une telle équipe, n'oubliez pas de faire appel à un coach Agile, à un scrum master ou à un psychothérapeute, celui que vous préférez. Peut-être qu'ils aideront.
Résultats de l'intégration
Sur la base des résultats du projet d'intégration (il s'est terminé en octobre 2019), nous:
- Nous avons créé un produit logiciel à part entière qui gère notre infrastructure DEV, avec son propre pipeline CI, des tests et d'autres attributs d'un produit logiciel de qualité.
- Nous avons doublé le nombre de personnes prêtes à être en service et allégé le fardeau de l'équipe actuelle. Après six mois supplémentaires, ces personnes sont devenues des SRE complets. Désormais, ils peuvent éteindre un incendie sur le marché, consulter une équipe de programmeurs sur NTF ou écrire leur propre bibliothèque pour les développeurs.
- SRE. , , .
- : , , , .
: ,
Plusieurs idées du développeur. Ne marchez pas sur notre râteau, sauvez-vous et votre entourage des nerfs et du temps.
L'infrastructure est dans le passé. Quand j'étais dans ma première année (il y a 15 ans) et que j'ai commencé à apprendre JavaScript, j'avais NotePad ++ et Firebug pour le débogage de mes outils. Même alors, il était nécessaire de faire des choses complexes et belles avec ces outils.
Je ressens la même chose maintenant lorsque je travaille avec des infrastructures. Les outils actuels sont juste en cours de formation, beaucoup d'entre eux ne sont pas encore sortis et ont la version 0.12 (bonjour Terraform), et beaucoup d'entre eux rompent régulièrement la compatibilité avec les versions précédentes.
Pour moi, en tant que développeur d'entreprise, il est absurde d'utiliser de telles choses en production. Mais il n'y en a tout simplement pas d'autres.
Lisez la documentation.En tant que programmeur, je suis allé assez rarement sur les quais. Je connaissais suffisamment mes outils: mon langage de programmation préféré, mon framework et bases de données préférés. Tous les outils supplémentaires, par exemple les bibliothèques, sont généralement écrits dans le même langage, ce qui signifie que vous pouvez toujours consulter le code source. L'EDI vous dira toujours quels paramètres sont nécessaires et où. Même si je me trompe, je vais rapidement le découvrir en exécutant des tests rapides.
Cela ne fonctionnera pas dans l'infrastructure, il existe un grand nombre de technologies différentes que vous devez connaître. Mais il est impossible de tout savoir en profondeur et beaucoup a été écrit dans des langues inconnues. Par conséquent, lisez (et écrivez) attentivement la documentation - sans cette habitude, ils ne vivent pas longtemps ici.
Les commentaires sur le code d'infrastructure sont inévitables.Dans le monde du développement, les commentaires sont un signe de mauvais code. Ils deviennent rapidement obsolètes et commencent à mentir. C'est un signe que le développeur n'a pas pu exprimer ses pensées autrement. Lorsque vous travaillez avec l'infrastructure, les commentaires sont également le signe d'un mauvais code, mais vous ne pouvez pas vous en passer. Pour les instruments dispersés qui sont vaguement liés les uns aux autres et ne se connaissent pas, les commentaires sont indispensables.
Souvent, les configs et DSL habituels sont cachés sous le code. Dans ce cas, toute logique se produit quelque part plus profondément, où il n'y a pas d'accès. Cela change considérablement l'approche du code, du test et de son utilisation.
N'ayez pas peur de laisser les développeurs entrer dans l'infrastructure.Ils peuvent apporter des pratiques et des approches utiles (et nouvelles) du monde du développement logiciel. Utilisez les pratiques et les approches de Google décrites dans le livre sur le SRE, bénéficiez et soyez heureux.
PS: , , , .
PPS: DevOpsConf 2019 . , , : , , DevOps-, .
PPPS: , DevOps-, DevOps Live 2020. : , - . , DevOps-. — « » .
, DevOps Live , , CTO, .