
Comment puis-je économiser sur les coûts du cloud lorsque je travaille avec Kubernetes? Il n'existe pas de solution unique, mais cet article présente plusieurs outils pour vous aider à gérer vos ressources plus efficacement et à réduire vos coûts de cloud computing.
J'ai écrit cet article en pensant à Kubernetes pour AWS, mais il s'appliquera (presque) de la même manière aux autres fournisseurs de cloud. Je suppose que votre ou vos grappes ont déjà une mise à l'échelle automatique ( cluster-autoscaler ) configurée . La suppression de ressources et la réduction de votre déploiement ne vous feront économiser que si cela réduit également votre parc de nœuds de travail (instances EC2).
Cet article couvrira:
- nettoyer les ressources inutilisées ( kube-janitor )
- réduction d'échelle pendant les heures creuses ( kube-downscaler )
- en utilisant l'échelle automatique horizontale (HPA),
- réduction de la surréservation des ressources ( kube-resource-report , VPA)
- en utilisant des instances Spot
Nettoyer les ressources inutilisées
Travailler dans un environnement au rythme rapide est formidable. Nous voulons que les organisations techniques accélèrent . Une livraison logicielle plus rapide signifie également plus de déploiements de relations publiques, d'environnements de prévisualisation, de prototypes et de solutions d'analyse. Tout est déployé sur Kubernetes. Qui a le temps de nettoyer manuellement les déploiements de test? Il est facile d'oublier la suppression de l'expérience il y a une semaine. La facture cloud finira par augmenter en raison du fait que nous avons oublié de fermer:

(Henning Jacobs:
Zhiza:
(cité) Corey Quinn:
Mythe: Votre compte AWS est fonction du nombre de vos utilisateurs.
Réalité: Votre compte AWS est fonction du nombre de vos ingénieurs.
Ivan Kurnosov (en réponse):
Réalité: Votre compte AWS est une fonction qui dépend du nombre de choses que vous avez oublié de désactiver / supprimer.)
Kubernetes Janitor (kube-janitor) aide à nettoyer votre cluster. La configuration du concierge est flexible pour une utilisation globale et locale:
- Les règles générales pour l'ensemble du cluster peuvent déterminer la durée de vie maximale (TTL) pour les déploiements PR / test.
- Les ressources individuelles peuvent être annotées avec janitor / ttl, par exemple pour supprimer automatiquement le pic / prototype après 7 jours.
Les règles générales sont définies dans le fichier YAML. Son chemin est transmis via un paramètre
--rules-fileà kube-janitor. Voici un exemple de règle pour supprimer tous les espaces de noms avec -pr-un nom après deux jours:
- id: cleanup-resources-from-pull-requests
resources:
- namespaces
jmespath: "contains(metadata.name, '-pr-')"
ttl: 2dL'exemple suivant réglemente l'utilisation de l'étiquette d'application sur les pods Deployment et StatefulSet pour tous les nouveaux Deployments / StatefulSet en 2020, mais permet en même temps l'exécution de tests sans cette étiquette pendant une semaine:
- id: require-application-label
# deployments statefulsets "application"
resources:
- deployments
- statefulsets
# . http://jmespath.org/specification.html
jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'"
ttl: 7dExécution d'une démo limitée dans le temps pendant 30 minutes dans le cluster où kube-janitor est en cours d'exécution:
kubectl run nginx-demo --image=nginx
kubectl annotate deploy nginx-demo janitor/ttl=30mLes volumes persistants (AWS EBS) constituent une autre source d'augmentation des coûts. La suppression d'un StatefulSet Kubernetes ne supprime pas ses volumes persistants (PVC - PersistentVolumeClaim). Les volumes EBS inutilisés peuvent facilement entraîner des coûts de plusieurs centaines de dollars par mois. Kubernetes Janitor a une fonction pour nettoyer les PVC inutilisés. Par exemple, cette règle supprimera tous les PVC qui ne sont pas montés par le module et qui ne sont pas référencés par StatefulSet ou CronJob:
# PVC, StatefulSets
- id: remove-unused-pvcs
resources:
- persistentvolumeclaims
jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced"
ttl: 24hKubernetes Janitor peut vous aider à garder votre cluster «propre» et à éviter l'accumulation lente des coûts du cloud computing. Pour les instructions de déploiement et de configuration, suivez le fichier README de kube-janitor .
Réduction de l'entartrage pendant les heures creuses
Les systèmes d'essai et intermédiaires sont généralement requis pour fonctionner uniquement pendant les heures de travail. Certaines applications de production, telles que les outils de back-office / d'administration, nécessitent également une disponibilité limitée et peuvent être désactivées la nuit.
Kubernetes Downscaler (kube-downscaler) permet aux utilisateurs et aux opérateurs de réduire l'échelle du système pendant les heures creuses. Les déploiements et les StatefulSets peuvent évoluer jusqu'à zéro réplicas. CronJobs peut être mis en pause. Kubernetes Downscaler est configurable pour l'ensemble du cluster, un ou plusieurs espaces de noms ou des ressources individuelles. Vous pouvez définir "temps d'inactivité" ou vice versa "temps d'exécution". Par exemple, pour réduire autant que possible la mise à l'échelle pendant la nuit et le week-end:
image: hjacobs/kube-downscaler:20.4.3
args:
- --interval=30
#
- --exclude-namespaces=kube-system,infra
# kube-downscaler, Postgres Operator,
- --exclude-deployments=kube-downscaler,postgres-operator
- --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin
- --include-resources=deployments,statefulsets,stacks,cronjobs
- --deployment-time-annotation=deployment-timeVoici un graphique pour la mise à l'échelle des nœuds de travail du cluster au cours du week-end: La

réduction d'environ 13 à 4 nœuds de travail fait certainement une différence mesurable sur la facture AWS.
Mais que se passe-t-il si je dois travailler pendant le «temps d'arrêt» du cluster? Certains déploiements peuvent être exclus définitivement de la mise à l'échelle en ajoutant l'annotation downscaler / exclude: true. Les déploiements peuvent être temporairement exclus à l'aide de l'annotation downscaler / exclude-until avec un horodatage absolu au format AAAA-MM-JJ HH: MM (UTC). Si nécessaire, l'ensemble du cluster peut être réduit en déployant un pod annoté
downscaler/force-uptime, par exemple en exécutant nginx dummy:
kubectl run scale-up --image=nginx
kubectl annotate deploy scale-up janitor/ttl=1h #
kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=trueVoir README kube-downscaler si vous êtes intéressé par les instructions de déploiement et les options supplémentaires.
Utiliser l'échelle automatique horizontale
De nombreuses applications / services utilisent un schéma de chargement dynamique: parfois leurs modules sont inactifs, et parfois ils fonctionnent à pleine capacité. Travailler avec une flotte permanente de pods pour faire face à la charge de pointe maximale n'est pas économique. Kubernetes prend en charge la mise à l'échelle automatique horizontale via la ressource HorizontalPodAutoscaler (HPA). L'utilisation du processeur est souvent un bon indicateur de la mise à l'échelle:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 100
type: UtilizationZalando a créé un composant permettant de connecter facilement des métriques personnalisées pour la mise à l'échelle: l' adaptateur de métriques Kube (kube-metrics-adapter) est un adaptateur de métrique universel pour Kubernetes qui peut collecter et gérer des métriques personnalisées et externes pour la mise à l'échelle automatique du foyer horizontal. Il prend en charge la mise à l'échelle basée sur les métriques Prometheus, les files d'attente SQS et d'autres personnalisations. Par exemple, pour mettre à l'échelle votre déploiement pour une métrique personnalisée représentée par l'application elle-même sous la forme JSON dans / métriques, utilisez:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
annotations:
# metric-config.<metricType>.<metricName>.<collectorName>/<configKey>
metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps"
metric-config.pods.requests-per-second.json-path/path: /metrics
metric-config.pods.requests-per-second.json-path/port: "9090"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: requests-per-second
target:
averageValue: 1k
type: AverageValueLa configuration de l'échelle horizontale automatique avec HPA devrait être l'une des actions par défaut pour améliorer l'efficacité des services sans état. Spotify a une présentation avec leur expérience et leurs recommandations pour HPA: faites évoluer vos déploiements, pas votre portefeuille .
Réservation de ressources redondantes réduite
Les charges de travail Kubernetes déterminent leurs besoins en CPU / mémoire via des "demandes de ressources". Les ressources CPU sont mesurées dans des cœurs virtuels ou plus souvent en "millicores", par exemple, 500m implique 50% de vCPU. Les ressources mémoire sont mesurées en octets et des suffixes communs peuvent être utilisés, par exemple 500Mi ce qui signifie 500 mégaoctets. Les demandes de ressources «bloquent» le volume sur les nœuds de travail, c'est-à-dire qu'un module avec une demande de CPU de 1000 m sur un nœud avec 4 CPU virtuels ne laissera que 3 CPU virtuels disponibles pour les autres modules. [1]
Slack (réserve excédentaire)Est la différence entre les ressources demandées et l'utilisation réelle. Par exemple, un pod qui demande 2 Gio de mémoire mais n'utilise que 200 Mio a ~ 1,8 Gio de mémoire "excédentaire". L'excédent coûte de l'argent. On peut approximativement estimer qu'un gigaoctet de mémoire excédentaire coûte ~ 10 $ par mois. [2]
Kubernetes Resource Report (kube-resource-report) affiche les réserves excédentaires et peut vous aider à identifier les économies potentielles:

Rapport sur les ressources Kubernetesmontre l'excédent agrégé par application et par équipe. Cela vous permet de trouver des endroits où les demandes de ressources peuvent être réduites. Le rapport HTML généré ne fournit qu'un instantané de l'utilisation des ressources. Vous devez examiner l'utilisation du processeur / de la mémoire au fil du temps pour déterminer les demandes de ressources adéquates. Voici un diagramme Grafana pour un service "typique" à forte utilisation du processeur: tous les pods utilisent nettement moins de 3 cœurs de processeur demandés:
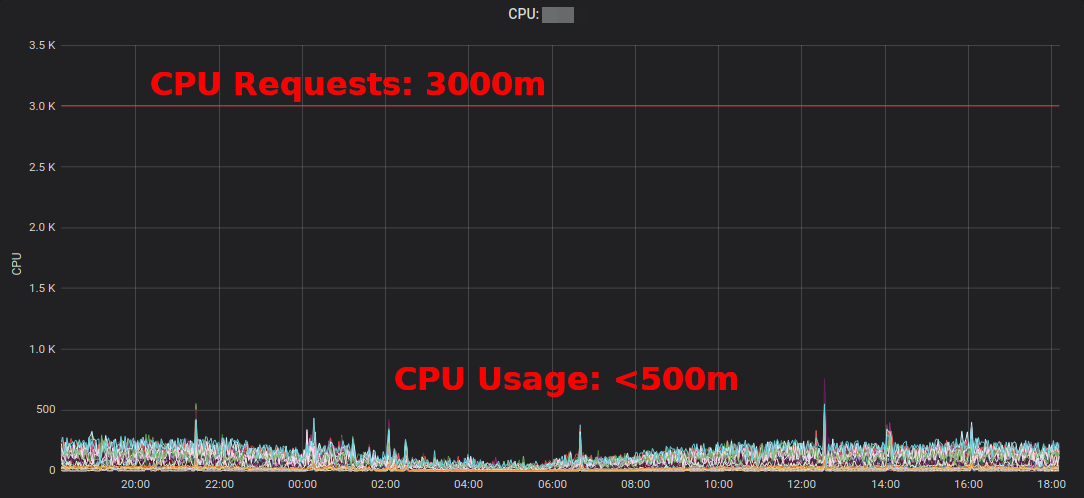
réduire la demande de processeur de 3000 m à ~ 400 m libère des ressources pour d'autres charges de travail et permet au cluster de se réduire.
«L'utilisation moyenne du processeur des instances EC2 fluctue souvent dans la plage de pourcentage à un chiffre», écrit Corey Quinn . Alors que pour EC2, estimer la taille correcte peut être une mauvaise décisionLa modification de certaines demandes de ressources Kubernetes dans un fichier YAML est facile et peut générer d'énormes économies.
Mais voulons-nous vraiment que les gens changent les valeurs des fichiers YAML? Non, les voitures peuvent faire beaucoup mieux! C'est exactement ce que fait l'autoscaler de pod vertical (VPA) de Kubernetes : il adapte les demandes de ressources et les contraintes en fonction de la charge de travail. Voici un exemple de graphique des demandes de CPU Prometheus (fine ligne bleue) adapté par VPA au fil du temps:

Zalando utilise VPA dans tous ses clusters pour les composants d'infrastructure. Les applications non critiques peuvent également utiliser VPA.
boucle d'orpar Fairwind est un outil qui crée un APV pour chaque déploiement dans un espace de noms, puis affiche la recommandation APV dans son tableau de bord. Il peut aider les développeurs à établir les demandes de processeur / mémoire correctes pour leurs applications:

j'ai écrit un petit blog sur VPA en 2019, et VPA a récemment été discuté à la communauté des utilisateurs finaux du CNCF .
Utilisation d'instances ponctuelles EC2
Enfin, les coûts AWS EC2 peuvent être réduits en utilisant des instances Spot comme nœuds de travail Kubernetes [3] . Les instances ponctuelles sont disponibles avec une remise allant jusqu'à 90% par rapport aux prix sur demande. L'exécution de Kubernetes sur EC2 Spot est une bonne combinaison: vous devez spécifier plusieurs types d'instances différents pour une disponibilité plus élevée, ce qui signifie que vous pouvez obtenir un nœud plus grand pour le même prix ou un prix inférieur, et la capacité accrue peut être utilisée par les charges de travail de conteneur Kubernetes.
Comment exécuter Kubernetes sur EC2 Spot? Il existe plusieurs options: utilisez un service tiers tel que SpotInst (maintenant appelé "Spot", ne me demandez pas pourquoi), ou ajoutez simplement le Spot AutoScalingGroup (ASG) à votre cluster. Par exemple, voici un extrait de CloudFormation pour un Spot ASG «à capacité optimisée» avec plusieurs types d'instances:
MySpotAutoScalingGroup:
Properties:
HealthCheckGracePeriod: 300
HealthCheckType: EC2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandPercentageAboveBaseCapacity: 0
SpotAllocationStrategy: capacity-optimized
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: "m4.2xlarge"
- InstanceType: "m4.4xlarge"
- InstanceType: "m5.2xlarge"
- InstanceType: "m5.4xlarge"
- InstanceType: "r4.2xlarge"
- InstanceType: "r4.4xlarge"
LaunchTemplate:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
MinSize: 0
MaxSize: 100
Tags:
- Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot
PropagateAtLaunch: true
Value: "true"Quelques remarques sur l'utilisation de Spot avec Kubernetes:
- Vous devez gérer les complétions Spot, par exemple en drainant un nœud à un arrêt d'instance
- Zalando utilise le fork de l' auto-scaling officiel du cluster avec les priorités du pool de nœuds
- Les nœuds Spot peuvent être forcés d'accepter des «inscriptions» de charges de travail à exécuter dans Spot
Résumé
J'espère que vous trouverez certains de ces outils utiles pour réduire votre facture de cloud computing. Vous pouvez également trouver la plupart du contenu dans ma conférence et mes diapositives DevOps Gathering 2019 sur YouTube .
Quelles sont vos meilleures pratiques pour réduire les coûts du cloud sur Kubernetes? Veuillez nous le faire savoir sur Twitter (@try_except_) .
[1] En fait, moins de 3 processeurs virtuels resteront utilisables car la bande passante de l'hôte est réduite par les ressources système réservées. Kubernetes fait la distinction entre la capacité physique d'un nœud et les ressources «allouées» ( Node Allocatable ).
[2] Exemple de calcul: une copie de m5.large avec 8 Gio de mémoire coûte ~ 84 USD par mois (eu-central-1, On-Demand), soit Le blocage de 1/8 nœud coûte environ 10 $ par mois.
[3] Il existe de nombreuses autres façons de réduire votre score EC2, par exemple, les instances réservées, le plan d'épargne, etc. - Je ne couvrirai pas ces sujets ici, mais vous devriez certainement les découvrir!
En savoir plus sur le cours.