Je crois que presque tous les projets utilisant Ruby on Rails et Postgres comme arme principale sur le backend sont dans une lutte constante entre la vitesse de développement, la lisibilité / maintenabilité du code et la vitesse du projet en production. Je vais vous raconter mon expérience d'équilibrage entre ces trois baleines dans un cas où la lisibilité et la rapidité de travail ont souffert à l'entrée, et à la fin, il s'est avéré faire ce que plusieurs ingénieurs talentueux ont tenté de faire avant moi sans succès.

L'histoire entière prendra plusieurs parties. C'est le premier où je vais parler de ce qu'est PMDSC pour optimiser les requêtes SQL, partager des outils utiles pour mesurer les performances des requêtes dans postgres et me rappeler une ancienne feuille de triche utile qui est toujours pertinente.
Maintenant, après un certain temps, «avec le recul» je comprends qu'à l'entrée de cette affaire je ne m'attendais pas du tout à réussir. Par conséquent, ce post sera plutôt utile pour les développeurs audacieux et pas les plus expérimentés que pour les super-seniors qui ont vu des rails avec du SQL nu.
Des données d'entrée
Chez Appbooster, nous faisons la promotion des applications mobiles. Pour émettre et tester facilement des hypothèses, nous développons plusieurs de nos applications. Le backend pour la plupart d'entre eux est l'API Rails et Postgresql.
Le héros de cette publication est en cours de développement depuis fin 2013 - alors rails 4.1.0.beta1 venait de sortir. Depuis lors, le projet est devenu une application Web entièrement chargée qui s'exécute sur plusieurs serveurs dans Amazon EC2 avec une instance de base de données distincte dans Amazon RDS (db.t3.xlarge avec 4 processeurs virtuels et 16 Go de RAM). Les charges de pointe atteignent 25 000 tr / min, la charge moyenne journalière de 8 à 10 000 tr / min.
Cette histoire a commencé avec une instance de base de données, ou plutôt avec son solde créditeur.
Fonctionnement d'une instance de type «t» Postgres dans Amazon RDS: si votre base de données s'exécute avec une consommation de processeur moyenne inférieure à une certaine valeur, vous accumulez des crédits sur votre compte, que l'instance peut dépenser en consommation de processeur pendant les heures de charge élevée - cela vous évite de payer trop cher pour la capacité du serveur et pour faire face à une charge élevée. Plus de détails sur ce qu'ils paient et combien ils paient avec AWS peuvent être trouvés dans l'article de notre CTO .
Le solde des prêts à un moment donné était épuisé. Pendant un certain temps, cela n'a pas eu beaucoup d'importance, car le solde des prêts peut être reconstitué avec de l'argent - cela nous a coûté environ 20 dollars par mois, ce qui n'est pas très perceptible pour le coût total de location de la puissance de calcul. Dans le développement de produits, il est habituel de prêter principalement attention aux tâches formulées à partir des exigences de l'entreprise. L'augmentation de la consommation de CPU du serveur de base de données s'inscrit dans la dette technique et est compensée par le faible coût d'achat d'un solde créditeur.
Un beau jour, j'ai écrit dans le summari quotidien que j'étais très fatigué d'éteindre les «incendies» qui apparaissaient périodiquement dans différentes parties du projet. Si cela continue, le développeur épuisé consacrera du temps aux tâches commerciales. Le même jour, je suis allé voir le chef de projet principal, lui ai expliqué l'alignement et demandé du temps pour enquêter sur les causes des incendies périodiques et des réparations. Après avoir reçu le feu vert, j'ai commencé à collecter des données à partir de divers systèmes de surveillance.
Nous utilisons Newrelic pour suivre le temps de réponse total par jour. L'image ressemblait à ceci:
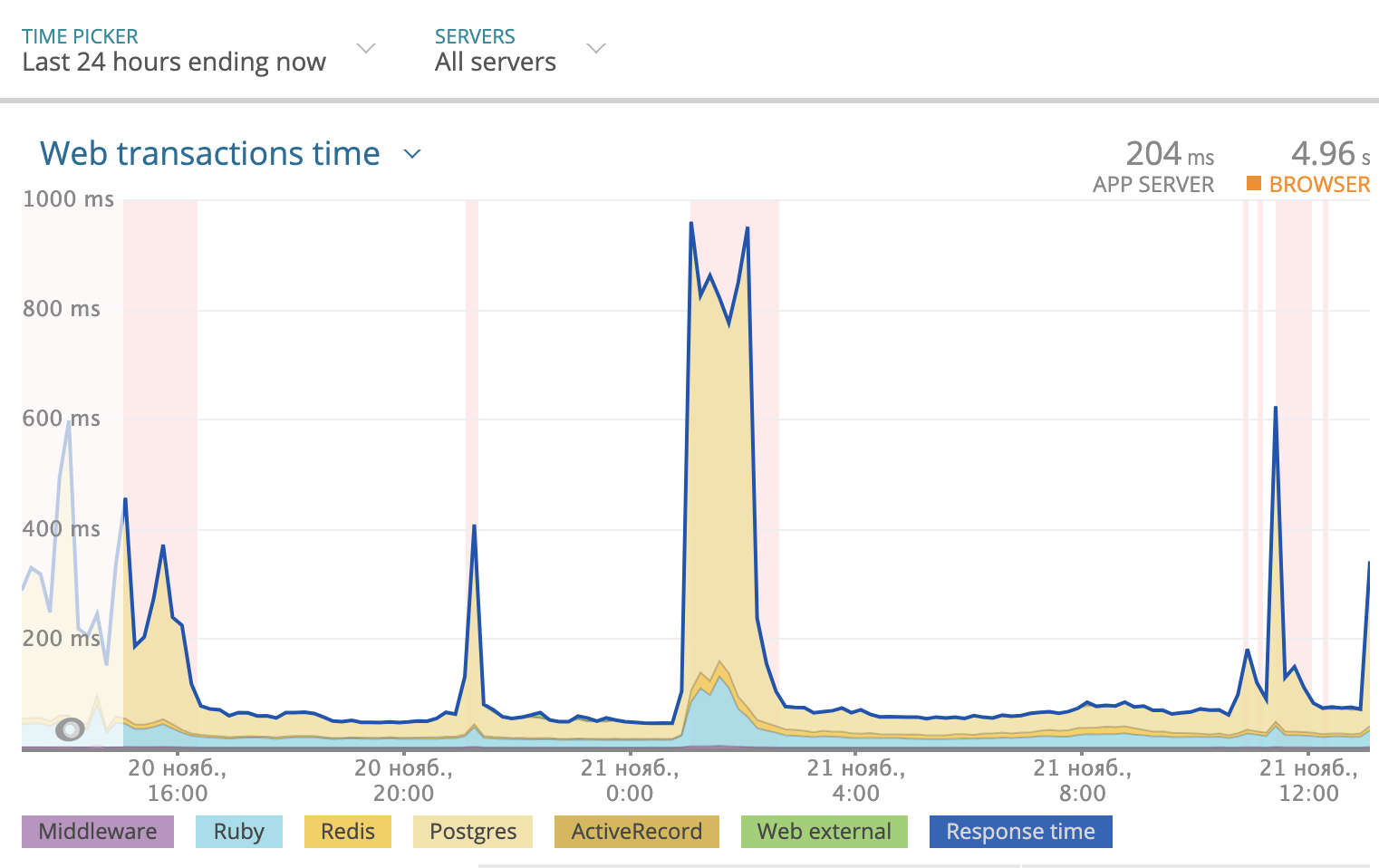
Une partie du temps de réponse pris par Postgres est surlignée en jaune dans le graphique. Comme vous pouvez le voir, parfois le temps de réponse atteignait 1000 ms, et la plupart du temps c'était la base de données qui réfléchissait à la réponse. Vous devez donc regarder ce qui se passe avec les requêtes SQL.
PMDSC est une pratique simple et directe pour tout travail d' optimisation SQL ennuyeux
Joue-le!
Mesure le!
Dessine le!
Supposez-le!
Vérifie ça!
Joue-le!
Peut-être la partie la plus importante de toute la pratique. Quand quelqu'un dit l'expression "Optimiser les requêtes SQL" - cela provoque plutôt un accès de bâillement et d'ennui chez la grande majorité des gens. Quand vous dites «enquête détective et recherche de méchants dangereux», cela vous engage davantage et vous met de bonne humeur. Par conséquent, il est important d'entrer dans le jeu. J'ai aimé jouer au détective. J'ai imaginé que les problèmes avec la base de données étaient soit des criminels dangereux, soit des maladies rares. Et il s'est imaginé dans le rôle de Sherlock Holmes, du lieutenant Columbo ou du docteur House. Choisissez un héros à votre goût et c'est parti!
Mesure le!

Pour analyser les statistiques de demande, j'ai installé PgHero . C'est un moyen très pratique pour lire les données de l'extension Postgres pg_stat_statements. Accédez à / queries et consultez les statistiques de toutes les requêtes des dernières 24 heures. Le tri des requêtes par défaut en fonction de la colonne Durée totale - la proportion du temps total pendant lequel la base de données traite la requête - une source précieuse pour trouver des suspects. Temps moyen - combien, en moyenne, la demande est exécutée. Appels - combien de demandes ont été faites pendant la période sélectionnée. PgHero considère que les demandes sont lentes si elles ont été exécutées plus de 100 fois par jour et ont pris plus de 20 millisecondes en moyenne. Liste des requêtes lentes sur la première page, immédiatement après la liste des index en double.

Nous prenons le premier de la liste et examinons les détails de la requête, vous pouvez immédiatement le voir expliquer analyser. Si le temps de planification est bien inférieur au temps d'exécution, alors quelque chose ne va pas avec cette demande et nous concentrons notre attention sur ce suspect.
PgHero a sa propre méthode de visualisation, mais j'ai aimé utiliser davantage Expliquer.depesz.com , en copiant les données depuis l'expliquer.
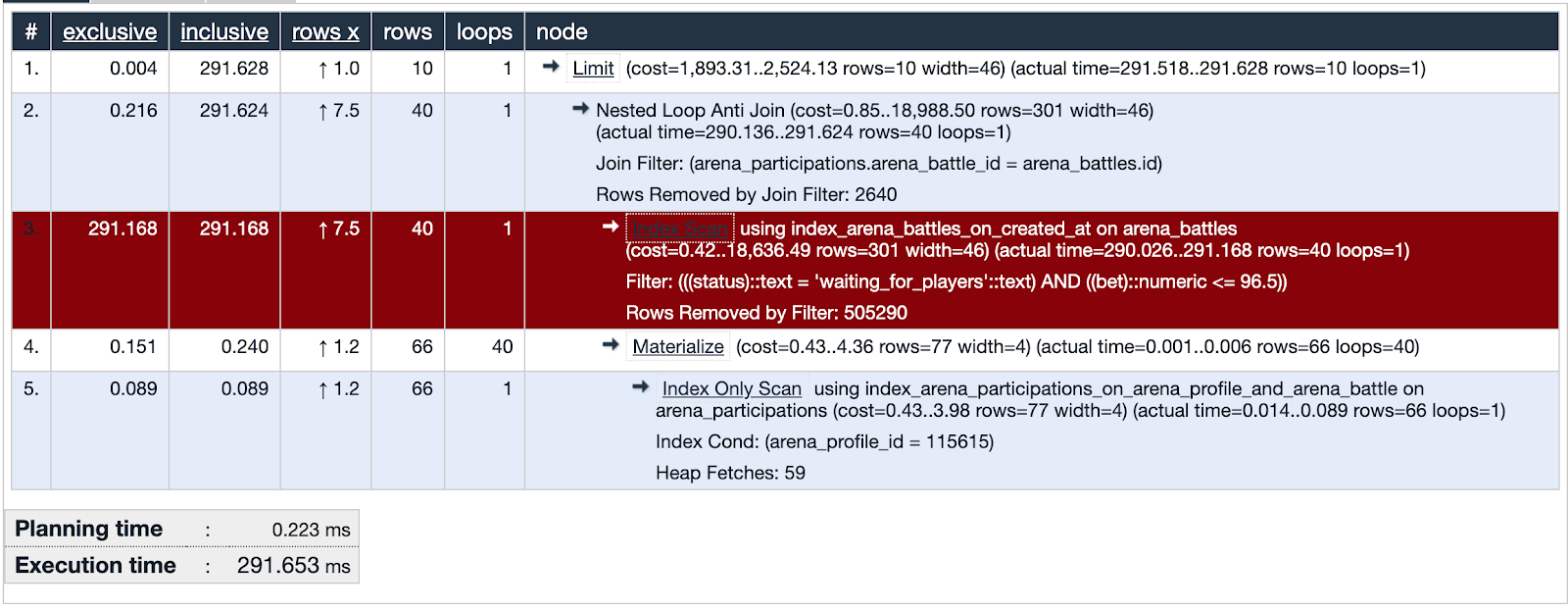
L'une des requêtes suspectes utilise l'analyse d'index. La visualisation montre que cet index n'est pas efficace et est un point faible - mis en évidence en rouge. Bien! Nous avons examiné les traces du suspect et trouvé des preuves importantes! La justice est inévitable!
Dessine le!
Tirons beaucoup de données utilisées dans la partie problématique de la requête. Il sera utile de comparer avec les données couvertes par l'index.
Un peu de contexte. Nous avons testé l'un des moyens de garder le public dans l'application - quelque chose comme une loterie dans laquelle vous pouvez gagner de la monnaie locale. Vous placez un pari, devinez un nombre de 0 à 100 et prenez tout le pot si votre nombre est le plus proche de celui que le générateur de nombres aléatoires a reçu. Nous l'avons appelé "Arena" et appelé les rallyes "Battles".

La base de données au moment de l'enquête contient environ cinq cent mille enregistrements de batailles. Dans la partie problématique de la demande, nous recherchons des batailles dans lesquelles le taux ne dépasse pas le solde de l'utilisateur et le statut de la bataille attend les joueurs. On voit que l'intersection des ensembles (surlignée en orange) est un très petit nombre d'enregistrements.
L'index utilisé dans la partie suspecte de la requête couvre toutes les batailles créées sur le champ created_at. La demande passe par 505330 enregistrements dans lesquels elle sélectionne 40 et 505290 élimine. Cela semble très inutile.
Supposez-le!
Nous émettons une hypothèse. Qu'est-ce qui aidera la base de données à trouver quarante des cinq cent mille enregistrements? Essayons de créer un index qui couvre le champ de taux, uniquement pour les batailles avec le statut «en attente de joueurs» - un index partiel.
add_index :arena_battles, :bet,
where: "status = 'waiting_for_players'",
name: "index_arena_battles_on_bet_partial_status"
Index partiel - n'existe que pour les enregistrements qui correspondent à la condition: le champ d'état est égal à «en attente de joueurs» et indexe le champ de taux - exactement ce qui est dans la condition de requête. Il est très avantageux d'utiliser cet index particulier: il ne prend que 40 kilo-octets et ne couvre pas les batailles qui ont déjà été jouées et nous n'avons pas besoin d'en obtenir un échantillon. A titre de comparaison, l'index index_arena_battles_on_created_at, qui a été utilisé par le suspect, prend environ 40 Mo, et la table des batailles est d'environ 70 Mo. Cet index peut être supprimé en toute sécurité si d'autres requêtes ne l'utilisent pas.
Vérifie ça!
Nous déployons la migration avec le nouvel index en production et observons comment la réponse du point final aux batailles a changé.
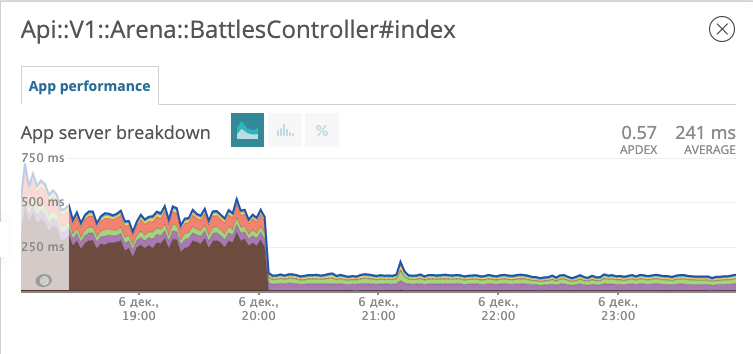
Le graphique montre l'heure à laquelle nous avons déployé la migration. Le soir du 6 décembre, le temps de réponse a diminué d'environ 10 fois, passant d'environ 500 ms à ~ 50 ms. Le suspect au tribunal a reçu le statut de prisonnier et est maintenant en prison. Bien!
Évasion de la prison
Quelques jours plus tard, nous avons réalisé que nous étions heureux tôt. Il semble que le prisonnier ait trouvé des complices, élaboré et mis en œuvre un plan d'évasion.
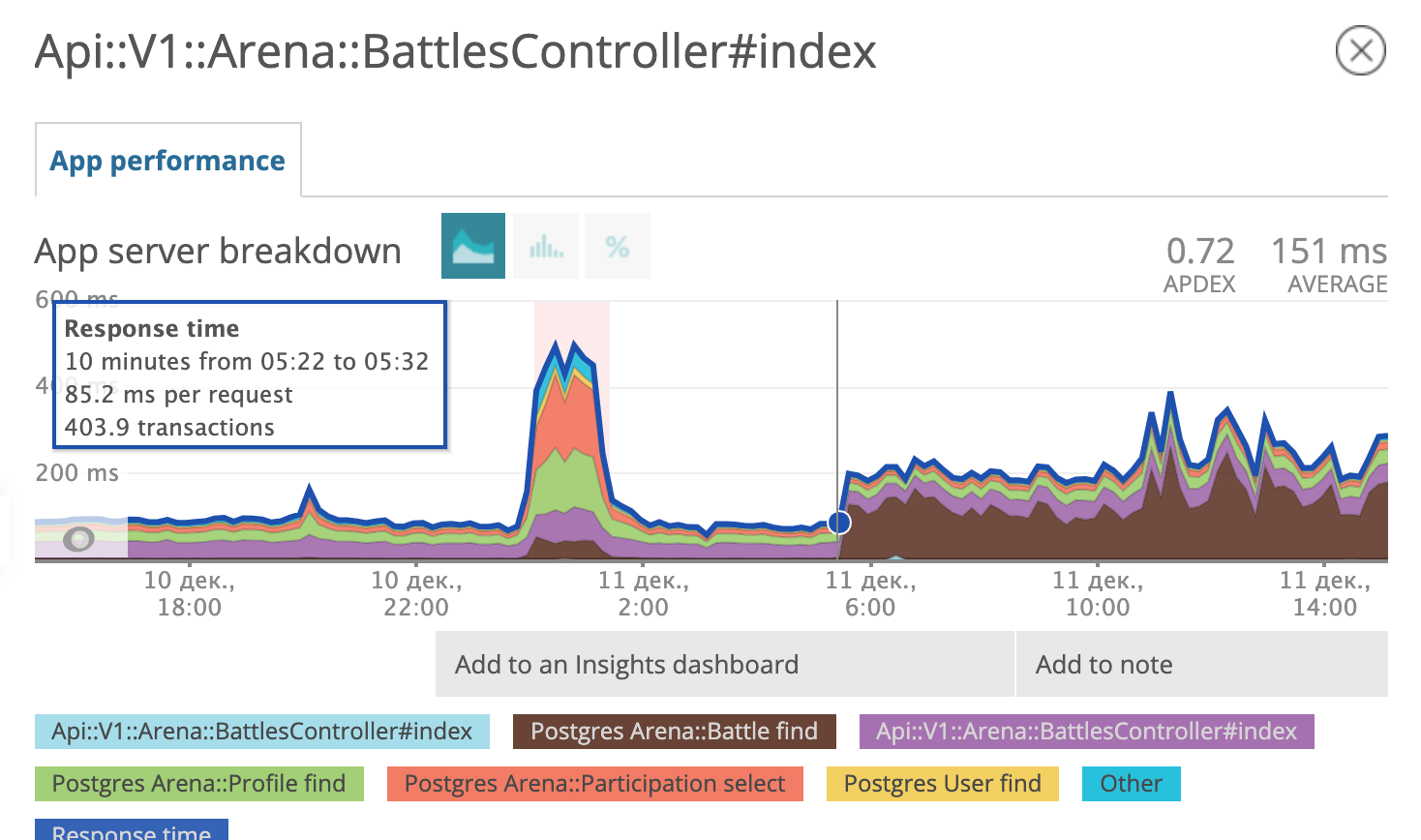
Le matin du 11 décembre, le planificateur de requêtes postgres a décidé que l'utilisation d'un nouvel index analysé n'était plus rentable pour lui et a recommencé à utiliser l'ancien.
Nous sommes de retour au stade Suppose it! Préparer un diagnostic différentiel, dans l'esprit du Dr House:
- Il peut être nécessaire d'optimiser les paramètres postgres;
- peut-être mettre à jour postgres vers une version plus récente en termes mineurs (9.6.11 -> 9.6.15);
- et peut-être, encore une fois, étudier attentivement quelles formes de requête SQL Rails?
Nous avons testé les trois hypothèses. Ce dernier nous a conduit sur la piste d'un complice.
SELECT "arena_battles".*
FROM "arena_battles"
WHERE "arena_battles"."status" = 'waiting_for_players'
AND (arena_battles.bet <= 98.13)
AND (NOT EXISTS (
SELECT 1 FROM arena_participations
WHERE arena_battle_id = arena_battles.id
AND (arena_profile_id = 46809)
))
ORDER BY "arena_battles"."created_at" ASC
LIMIT 10 OFFSET 0Passons en revue ce SQL ensemble. Nous sélectionnons tous les champs de bataille de la table de bataille dont le statut est égal à «en attente de joueurs» et le taux est inférieur ou égal à un certain nombre. Jusqu'à présent, tout est clair. Le prochain terme de la condition semble effrayant.
NOT EXISTS (
SELECT 1 FROM arena_participations
WHERE arena_battle_id = arena_battles.id
AND (arena_profile_id = 46809)
)Nous recherchons un résultat de sous-requête inexistant. Obtenez le premier champ de la table de participation au combat, où l'ID de combat correspond et le profil du participant appartient à notre joueur. Je vais essayer de dessiner l'ensemble décrit dans la sous-requête.
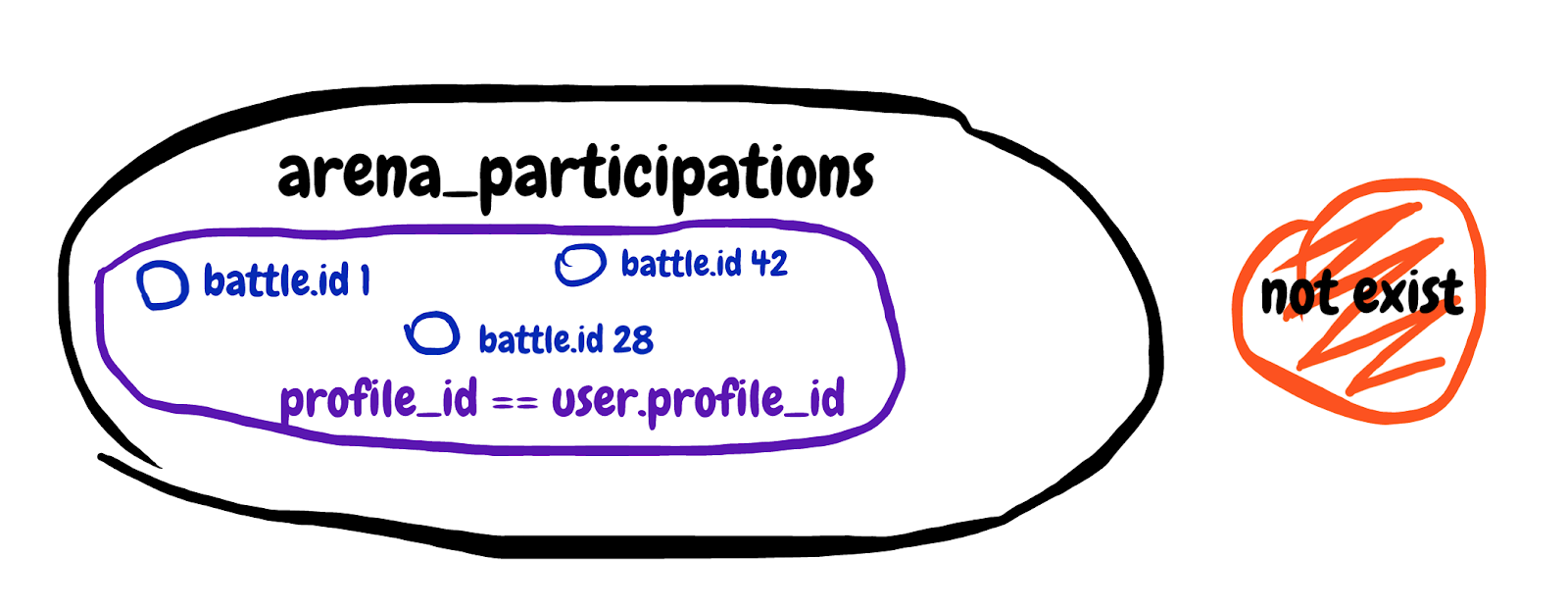
C'est difficile à comprendre, mais à la fin, avec cette sous-requête, nous avons essayé d'exclure les batailles auxquelles le joueur participe déjà. Nous regardons l'explication générale de la requête et voyons Temps de planification: 0,180 ms, Temps d'exécution: 12,119 ms. Nous avons trouvé un complice!
Il est temps pour ma feuille de triche préférée, qui circule sur Internet depuis 2008. Le voici:

Oui! Dès qu'une requête rencontre quelque chose qui devrait exclure un certain nombre d'enregistrements en fonction des données d'une autre table, ce mème avec barbe et boucles devrait apparaître en mémoire.
En fait, c'est ce dont nous avons besoin:

Enregistrez cette image pour vous-même ou, mieux encore, imprimez-la et accrochez-la à plusieurs endroits du bureau.
Nous réécrivons la sous-requête en LEFT JOIN WHERE B.key EST NULL, nous obtenons:
SELECT "arena_battles".*
FROM "arena_battles"
LEFT JOIN arena_participations
ON arena_participations.arena_battle_id = arena_battles.id
AND (arena_participations.arena_profile_id = 46809)
WHERE "arena_battles"."status" = 'waiting_for_players'
AND (arena_battles.bet <= 98.13)
AND (arena_participations.id IS NULL)
ORDER BY "arena_battles"."created_at" ASC
LIMIT 10 OFFSET 0La requête corrigée s'exécute sur deux tables à la fois. Nous avons ajouté un tableau avec les enregistrements de la participation de l'utilisateur aux batailles sur la «gauche» et ajouté la condition que l'identifiant de participation n'existe pas. Voyons l'expliquer analyser la requête reçue: Temps de planification: 0,185 ms, Temps d'exécution: 0,337 ms. Bien! Désormais, le planificateur de requêtes n'hésitera pas à utiliser l'index partiel, mais utilisera l'option la plus rapide. Le prisonnier évadé et son complice ont été condamnés à la réclusion à perpétuité dans une institution à régime strict. Il leur sera plus difficile de s'échapper.
Le résumé est bref.
- Utilisez Newrelic ou un autre service similaire pour trouver des prospects. Nous nous sommes rendu compte que le problème résidait précisément dans les requêtes de base de données.
- Utilisez la pratique PMDSC - cela fonctionne et dans tous les cas est très engageant.
- Utilisez PgHero pour trouver des suspects et enquêter sur des indices dans les statistiques de requêtes SQL.
- Utilisez expliquer.depesz.com - il est facile de lire expliquer analyser les requêtes là-bas.
- Essayez de dessiner beaucoup de données lorsque vous ne savez pas exactement ce que fait la demande.
- Pensez au dur à cuire avec des boucles partout sur la tête lorsque vous voyez une sous-requête à la recherche de quelque chose qui ne figure pas dans une autre table.
- Jouez au détective, vous pourriez même obtenir un badge.