Pour un aperçu, nous avons pris les actes de la CHI: Conférence sur les facteurs humains dans les systèmes informatiques de 10 ans, et avec l'aide de la PNL et de l'analyse des réseaux sociaux, nous avons examiné des sujets et des domaines à l'intersection des disciplines.

En Russie, l'accent est particulièrement mis sur les problèmes appliqués de conception UX. Beaucoup d'événements qui ont contribué à la croissance de HCI à l'étranger n'ont pas eu lieu dans notre pays: iSchools n'est pas apparu , de nombreux spécialistes impliqués dans des aspects connexes de la psychologie de l'ingénieur ont quitté la science, etc. En conséquence, la profession a réapparu, à partir de problèmes appliqués et de recherche. L'un des résultats de cette situation est visible même maintenant: il s'agit de la représentation extrêmement faible du travail de HCI russe dans les principales conférences.
Mais en dehors de la Russie, HCI s'est développé de manière très différente, en se concentrant sur une variété de sujets et de domaines. Au programme de master " Systèmes d'information et interaction homme-machine»Au HSE de Saint-Pétersbourg, nous discutons entre autres - avec des étudiants, des collègues, des diplômés de spécialités similaires d'universités européennes, des partenaires qui aident à développer le programme - ce qui appartient au domaine de l'interaction homme-machine. Et ces discussions montrent l'hétérogénéité de la direction dans laquelle chaque spécialiste a sa propre image incomplète du domaine.
De temps en temps, nous entendons des questions sur la façon dont cette direction est liée (et si elle est liée du tout) à l'apprentissage automatique et à l'analyse de données. Pour y répondre, nous nous sommes tournés vers les recherches récentes présentées à la conférence CHI .
Tout d'abord, nous vous dirons ce qui se passe dans des domaines tels que xAI et iML (eXplainable Artificial Intelligence et Interprétable Machine Learning) du côté des interfaces et des utilisateurs, ainsi que de la manière dont ils étudient en HCI les aspects cognitifs du travail des data scientists, et nous donnerons des exemples de travaux intéressants ces dernières années dans chaque domaine.
xAI et iML
Les techniques d'apprentissage automatique sont en cours de développement intensif et - surtout du point de vue du domaine en discussion - sont activement mises en œuvre dans la prise de décision automatisée. Par conséquent, les chercheurs discutent de plus en plus des questions suivantes: comment les utilisateurs non-machine learning interagissent-ils avec des systèmes où des algorithmes similaires sont utilisés? Une des questions importantes de cette interaction: comment amener les utilisateurs à faire confiance aux décisions prises par les modèles? Par conséquent, chaque année, les sujets de l'apprentissage automatique interprété (Apprentissage automatique interprétable - iML) et de l'intelligence artificielle explicable (Intelligence artificielle eXplainable - XAI) deviennent de plus en plus chauds.
En même temps, si lors de conférences telles que NeurIPS, ICML, IJCAI, KDD, les algorithmes et les moyens d'iML et de XAI sont discutés, le CHI se concentre sur plusieurs sujets liés aux caractéristiques de conception et à l'expérience d'utilisation de ces systèmes. Par exemple, au CHI-2020, plusieurs sections ont été consacrées à ce sujet à la fois, notamment «AI / ML & voir à travers la boîte noire» et «Faire face à l'IA: pas agAIn!». Mais même avant l'apparition de sections séparées, il y avait beaucoup de ces œuvres. Nous y avons identifié quatre domaines.
Conception de systèmes d'interprétation pour résoudre des problèmes appliqués
La première direction est la conception de systèmes basés sur des algorithmes d'interprétabilité dans divers problèmes appliqués: médicaux, sociaux, etc. De tels travaux se situent dans des domaines très différents. Par exemple, travailler chez CHI-2020 CheXplain: permettre aux médecins d'explorer et de comprendre l'analyse d'imagerie médicale basée sur les données et basée sur l'IA décrit un système qui aide les médecins à examiner et à expliquer les résultats de la radiographie pulmonaire. Elle propose des explications textuelles et visuelles supplémentaires, ainsi que des images avec le même résultat et le contraire (exemples à l'appui et contradictoires). Si le système prédit qu'une maladie est visible sur la radiographie, il montrera deux exemples. Le premier exemple de soutien est un instantané des poumons d'un autre patient qui a confirmé la même maladie. Le deuxième exemple, contradictoire, est un instantané dans lequel il n'y a pas de maladie, c'est-à-dire un instantané des poumons d'une personne en bonne santé. L'idée principale est de réduire les erreurs évidentes et de réduire le nombre de consultations externes dans les cas simples afin de faire un diagnostic plus rapidement.
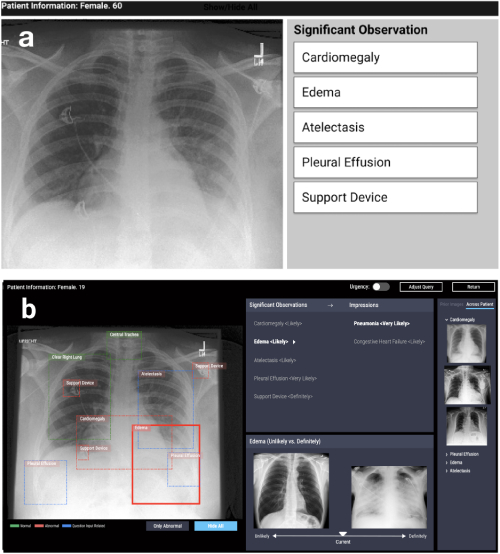
CheXpert: sélection de région automatisée + exemples (improbable vs définitivement)
Développement de systèmes pour la recherche de modèles d'apprentissage automatique
La deuxième direction est le développement de systèmes qui permettent de comparer ou de combiner de manière interactive plusieurs méthodes et algorithmes. Par exemple, dans le travail de Silva: Évaluer de manière interactive l'équité de l'apprentissage automatique à l'aide de la causalité au CHI-2020, un système a été présenté qui construit plusieurs modèles d'apprentissage automatique sur les données des utilisateurs et offre la possibilité de leur analyse ultérieure. L'analyse comprend la construction d'un graphique causal entre les variables et le calcul d'un certain nombre de mesures qui évaluent non seulement l'exactitude, mais aussi l'équité du modèle (différence de parité statistique, différence d'égalité des chances, différence de cotes moyennes, impact disparate, indice de Theil), ce qui aide à trouver des biais dans les prédictions.

Silva : graphique des relations entre les variables + graphiques pour comparer les métriques d'équité + mise en évidence en couleur des variables influentes dans chaque groupe
Problèmes généraux d'interprétabilité des modèles
Le troisième domaine est la discussion des approches du problème de l'interprétabilité des modèles en général. Le plus souvent, il s'agit de critiques, de critiques d'approches et de questions ouvertes: par exemple, ce que l'on entend par «interprétabilité». Ici, je voudrais noter l'examen à CHI-2018 Trends and Trajectories for Explainable, Accountable and Intelligible Systems: An HCI Research Agenda, dans lequel les auteurs ont passé en revue 289 articles majeurs sur les explications en intelligence artificielle et 12 412 publications les citant. À l'aide de l'analyse de réseau et de la modélisation thématique, ils ont identifié quatre domaines de recherche clés 1) Systèmes intelligents et ambiants (I&A), 2) IA explicable: algorithmes équitables, responsables et transparents (FAT) et apprentissage automatique interprétable (iML), 3) Théories de Explications: causalité et psychologie cognitive, 4) interactivité et apprentissage. En outre, les auteurs ont décrit les principales tendances de la recherche: apprentissage interactif et interaction avec le système.
Recherche d'utilisateurs
Enfin, le quatrième domaine est la recherche des utilisateurs sur les algorithmes et les systèmes qui interprètent les modèles d'apprentissage automatique. En d'autres termes, il s'agit d'études pour savoir si dans la pratique les nouveaux systèmes deviennent plus clairs et plus transparents, quelles difficultés les utilisateurs rencontrent lorsqu'ils travaillent avec des modèles interprétatifs plutôt qu'originaux, comment déterminer si le système est utilisé comme prévu (ou si une nouvelle application a été trouvée pour cela) - peut-être incorrect), quels sont les besoins des utilisateurs et si les développeurs leur offrent ce dont ils ont vraiment besoin.
Il existe de nombreux outils d'interprétation et algorithmes, alors la question se pose: comment comprendre quel algorithme choisir? En questionnant l'IA: informer les pratiques de conception pour des expériences utilisateur d'IA explicablesles problèmes de motivation pour l'utilisation d'algorithmes explicatifs sont discutés et les problèmes identifiés qui, avec toute la variété des méthodes, n'ont pas encore été suffisamment résolus. Les auteurs arrivent à une conclusion inattendue: la plupart des méthodes existantes sont construites de telle manière qu'elles répondent à la question «pourquoi» («pourquoi ai-je eu un tel résultat»), tandis que les utilisateurs ont également besoin d'une réponse à la question «pourquoi pas» («pourquoi pas un autre "), et parfois -" que faire pour changer le résultat. "
Le document indique également que les utilisateurs doivent comprendre quelles sont les limites d'applicabilité des méthodes, quelles sont leurs limites - et cela doit être explicitement implémenté dans les outils proposés. Ce problème est montré plus clairement dans l'articleInterpréter l'interprétabilité: comprendre l'utilisation des outils d'interprétabilité par les scientifiques des données pour l'apprentissage automatique . Les auteurs ont mené une petite expérience avec des spécialistes dans le domaine de l'apprentissage automatique: ils ont montré les résultats de plusieurs outils populaires pour interpréter les modèles d'apprentissage automatique et leur ont demandé de répondre à des questions liées à la prise de décisions basées sur ces résultats. Il s'est avéré que même les experts font trop confiance à ces modèles et ne prennent pas les résultats d'un œil critique. Comme tout outil, les modèles explicatifs peuvent être mal utilisés. Lors de l'élaboration de la boîte à outils, il est important d'en tenir compte, en utilisant les connaissances accumulées (ou les spécialistes) dans le domaine de l'interaction homme-machine afin de prendre en compte les caractéristiques et les besoins des utilisateurs potentiels.
Data Science, Notebooks, Visualization
Un autre domaine intéressant de l'IHM est l'analyse des aspects cognitifs du travail avec des données. Récemment, la science a soulevé la question de savoir comment les «degrés de liberté» du chercheur - les caractéristiques de la collecte de données, la conception expérimentale et le choix des méthodes analytiques - affectent les résultats de la recherche et leur reproductibilité. Si une grande partie de la discussion et des critiques est liée à la psychologie et aux sciences sociales, de nombreux problèmes concernent la fiabilité des conclusions dans le travail des analystes de données en général, ainsi que les difficultés à communiquer ces conclusions aux consommateurs de l'analyse.
Par conséquent, le sujet de ce domaine HCI est le développement de nouvelles façons de visualiser l'incertitude dans les prédictions des modèles, la création de systèmes de comparaison d'analyses effectuées de différentes manières, ainsi que l'analyse du travail des analystes avec des outils tels que les notebooks Jupyter.
Visualiser l'incertitude
La visualisation de l'incertitude est l'une des fonctionnalités qui distinguent les graphiques scientifiques de la présentation et de la visualisation d'entreprise. Pendant longtemps, le principe du minimalisme et de la concentration sur les principales tendances a été considéré comme la clé de cette dernière. Cependant, cela conduit à une trop grande confiance des utilisateurs dans une estimation ponctuelle d'une ampleur ou d'une prévision, ce qui peut être critique, surtout si nous devons comparer des prévisions avec différents degrés d'incertitude. Les affichages d'incertitude de l' emploi à l' aide de diagrammes de points quantiles ou de CDF améliorent la prise de décision en matière de transitexamine comment la visualisation de l'incertitude dans la prédiction pour les nuages de points et les fonctions de distribution cumulative aide les utilisateurs à prendre des décisions plus rationnelles en utilisant l'exemple du problème d'estimation de l'heure d'arrivée d'un bus à partir des données d'une application mobile. Ce qui est particulièrement intéressant, c'est que l'un des auteurs maintient le package ggdist pour R avec diverses options pour visualiser l'ambiguïté.

Exemples de visualisation d'incertitude ( https://mjskay.github.io/ggdist/ )
Cependant, des tâches de visualisation d'alternatives possibles sont souvent rencontrées, par exemple pour les séquences d'action utilisateur dans l'analyse Web ou l'analyse d'applications. Work Visualizing Incertainty and Alternatives in Event Sequence Predictions analyse comment une représentation graphique des alternatives basée sur le modèle Time-Aware Recurrent Neural Network (TRNN ) aide les experts à prendre des décisions et à leur faire confiance.
Comparaison des modèles
Aussi important que la visualisation de l'incertitude, un aspect du travail des analystes consiste à comparer comment - souvent caché - le choix par le chercheur de différentes approches de la modélisation à toutes ses étapes peut conduire à des résultats analytiques différents. En psychologie et en sciences sociales, le pré-enregistrement de la conception de la recherche et une séparation claire des études exploratoires et de confirmation gagnent en popularité. Cependant, dans les tâches où la recherche est davantage axée sur les données, une alternative peut être des outils qui vous permettent d'évaluer les risques cachés de l'analyse en comparant des modèles. Travailler à accroître la transparence des documents de recherche avec des analyses multivers explorablessuggère d'utiliser la visualisation interactive de plusieurs approches d'analyse dans les articles. En substance, l'article se transforme en une application interactive où le lecteur peut évaluer ce qui changera dans les résultats et les conclusions si une approche différente est appliquée. Cela semble également être une idée utile pour des analyses pratiques.
Travailler avec des outils d'organisation et d'analyse des données
Le dernier bloc de travail est lié à l'étude de la façon dont les analystes travaillent avec des systèmes comme Jupyter Notebooks, qui sont devenus un outil populaire pour organiser l'analyse des données. L'article Exploration and Explanation in Computational Notebooks analyse les contradictions entre la recherche et l'explication des objectifs d'apprentissage trouvés sur les documents interactifs Github, et Managing Messes in Computational Notebooksles auteurs analysent la façon dont les notes, les morceaux de code et les visualisations évoluent dans un flux de travail itératif d'analyste et suggèrent des ajouts possibles aux outils pour soutenir ce processus. Enfin, déjà au CHI 2020, les principaux problèmes des analystes à toutes les étapes du travail, du chargement des données au transfert d'un modèle en production, ainsi que les idées d'amélioration des outils, sont résumés dans l'article Qu'est-ce qui ne va pas avec les ordinateurs portables? Problèmes, besoins et opportunités de conception .
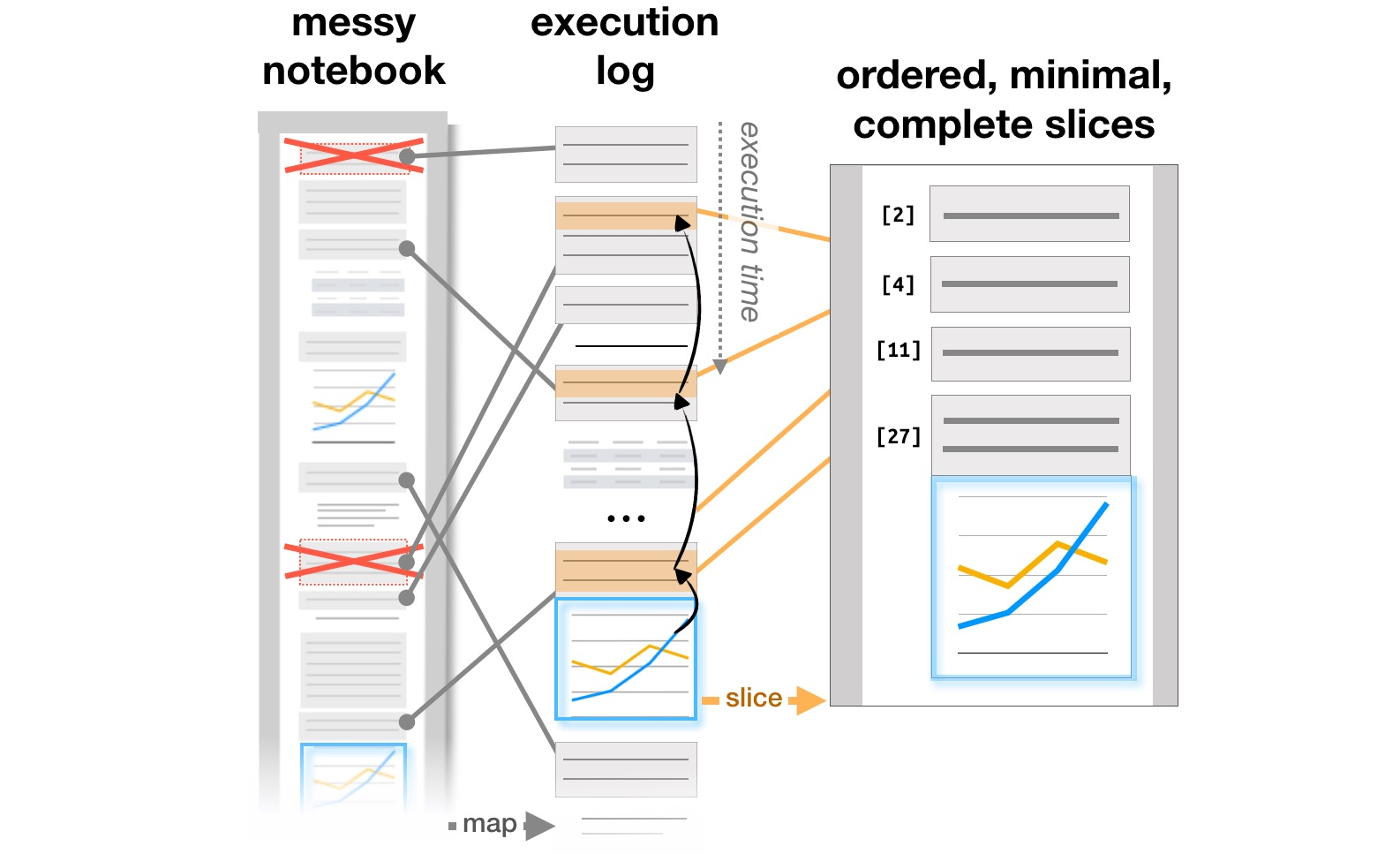
Transformation de la structure des rapports basée sur les journaux d'exécution ( https://microsoft.github.io/gather/ )
Résumer
En conclusion de la partie de la discussion «que fait HCI» et «pourquoi un spécialiste HCI connaît-il l'apprentissage automatique», je voudrais réitérer la conclusion générale tirée de la motivation et des résultats de ces études. Dès qu'une personne apparaît dans le système, cela conduit immédiatement à un certain nombre de questions supplémentaires: comment simplifier l'interaction avec le système et éviter les erreurs, comment l'utilisateur change le système, si l'utilisation réelle diffère de celle prévue. En conséquence, nous avons besoin de ceux qui comprennent comment fonctionne le processus de conception de systèmes avec l'intelligence artificielle et savent comment prendre en compte le facteur humain.
Nous enseignons tout cela sur le programme de master " Systèmes d'information et interaction homme-machine". Si vous êtes intéressé par la recherche HCI, regardez la lumière (la campagne d'admission vient de commencer ). Ou suivez notre blog: nous vous en dirons plus sur les projets sur lesquels les étudiants ont travaillé cette année.