
Le moment est donc venu pour la publication de la deuxième partie, aujourd'hui, nous allons continuer à développer notre éditeur de code et y ajouter l'auto-complétion et la mise en évidence des erreurs, et également expliquer pourquoi tout éditeur de code
EditTextne sera pas en retard.
Avant de poursuivre la lecture, je vous recommande fortement de lire la première partie .
introduction
 Tout d'abord, rappelons-nous où nous nous sommes arrêtés dans la dernière partie . Nous avons écrit une coloration syntaxique optimisée qui analyse le texte en arrière-plan et ne colore que sa partie visible, ainsi qu'une numérotation de ligne ajoutée (bien que sans sauts de ligne Android, mais quand même).
Tout d'abord, rappelons-nous où nous nous sommes arrêtés dans la dernière partie . Nous avons écrit une coloration syntaxique optimisée qui analyse le texte en arrière-plan et ne colore que sa partie visible, ainsi qu'une numérotation de ligne ajoutée (bien que sans sauts de ligne Android, mais quand même).
Dans cette partie, nous ajouterons la complétion du code et la mise en évidence des erreurs.
Achèvement du code
Tout d'abord, imaginons comment cela devrait fonctionner:
- L'utilisateur écrit un mot
- Après avoir entré les N premiers caractères, une fenêtre apparaît avec des conseils
- Lorsque vous cliquez sur l'indice, le mot est automatiquement "imprimé"
- La fenêtre avec des indices se ferme et le curseur est déplacé à la fin du mot
- Si l'utilisateur saisit lui-même le mot affiché dans l'info-bulle, la fenêtre avec des conseils devrait se fermer automatiquement
Ça ne ressemble à rien? Android a déjà un composant avec exactement la même logique -
MultiAutoCompleteTextViewdonc PopupWindownous n'avons pas à écrire des béquilles avec nous (elles ont déjà été écrites pour nous).
La première étape consiste à changer le parent de notre classe:
class TextProcessor @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyleAttr: Int = R.attr.autoCompleteTextViewStyle
) : MultiAutoCompleteTextView(context, attrs, defStyleAttr)
Maintenant, nous devons écrire
ArrayAdapterqui affichera les résultats trouvés. Le code complet de l'adaptateur ne sera pas disponible, des exemples d'implémentation peuvent être trouvés sur Internet. Mais je vais m'arrêter pour le moment avec le filtrage.
Pour
ArrayAdapterpouvoir comprendre quels conseils doivent être affichés, nous devons remplacer la méthode getFilter:
override fun getFilter(): Filter {
return object : Filter() {
private val suggestions = mutableListOf<String>()
override fun performFiltering(constraint: CharSequence?): FilterResults {
// ...
}
override fun publishResults(constraint: CharSequence?, results: FilterResults) {
clear() //
addAll(suggestions)
notifyDataSetChanged()
}
}
}
Et dans la méthode,
performFilteringremplissez la liste suggestionsde mots en fonction du mot que l'utilisateur a commencé à saisir (contenu dans une variable constraint).
Où obtenir les données avant de filtrer?
Tout dépend de vous - vous pouvez utiliser une sorte d'interpréteur pour sélectionner uniquement les options valides ou analyser tout le texte lorsque vous ouvrez le fichier. Pour simplifier l'exemple, j'utiliserai une liste toute faite d'options de saisie semi-automatique:
private val staticSuggestions = mutableListOf(
"function",
"return",
"var",
"const",
"let",
"null"
...
)
...
override fun performFiltering(constraint: CharSequence?): FilterResults {
val filterResults = FilterResults()
val input = constraint.toString()
suggestions.clear() //
for (suggestion in staticSuggestions) {
if (suggestion.startsWith(input, ignoreCase = true) &&
!suggestion.equals(input, ignoreCase = true)) {
suggestions.add(suggestion)
}
}
filterResults.values = suggestions
filterResults.count = suggestions.size
return filterResults
}
La logique de filtrage ici est plutôt primitive, on parcourt toute la liste et, en ignorant la casse, on compare le début de la chaîne.
Installé l'adaptateur, écrivez le texte - cela ne fonctionne pas. Qu'est-ce qui ne va pas? Sur le premier lien dans Google, nous tombons sur une réponse qui dit que nous avons oublié d'installer
Tokenizer.
À quoi sert Tokenizer?
En termes simples, cela
Tokenizeraide à MultiAutoCompleteTextViewcomprendre après quel caractère saisi le mot saisi peut être considéré comme complet. Il a également une implémentation toute faite sous forme de CommaTokenizerséparation des mots par des virgules, ce qui dans ce cas ne nous convient pas.
Eh bien, puisque
CommaTokenizernous ne sommes pas satisfaits, nous écrirons le nôtre:
Tokenizer personnalisé
class SymbolsTokenizer : MultiAutoCompleteTextView.Tokenizer {
companion object {
private const val TOKEN = "!@#$%^&*()_+-={}|[]:;'<>/<.? \r\n\t"
}
override fun findTokenStart(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i > 0 && !TOKEN.contains(text[i - 1])) {
i--
}
while (i < cursor && text[i] == ' ') {
i++
}
return i
}
override fun findTokenEnd(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i < text.length) {
if (TOKEN.contains(text[i - 1])) {
return i
} else {
i++
}
}
return text.length
}
override fun terminateToken(text: CharSequence): CharSequence = text
}
Voyons cela:
TOKEN - une chaîne avec des caractères qui séparent un mot d'un autre. Dans les méthodes findTokenStartet findTokenEndnous parcourons le texte à la recherche de ces symboles très séparateurs. La méthode terminateTokenvous permet de renvoyer un résultat modifié, mais nous n'en avons pas besoin, donc nous renvoyons simplement le texte inchangé.
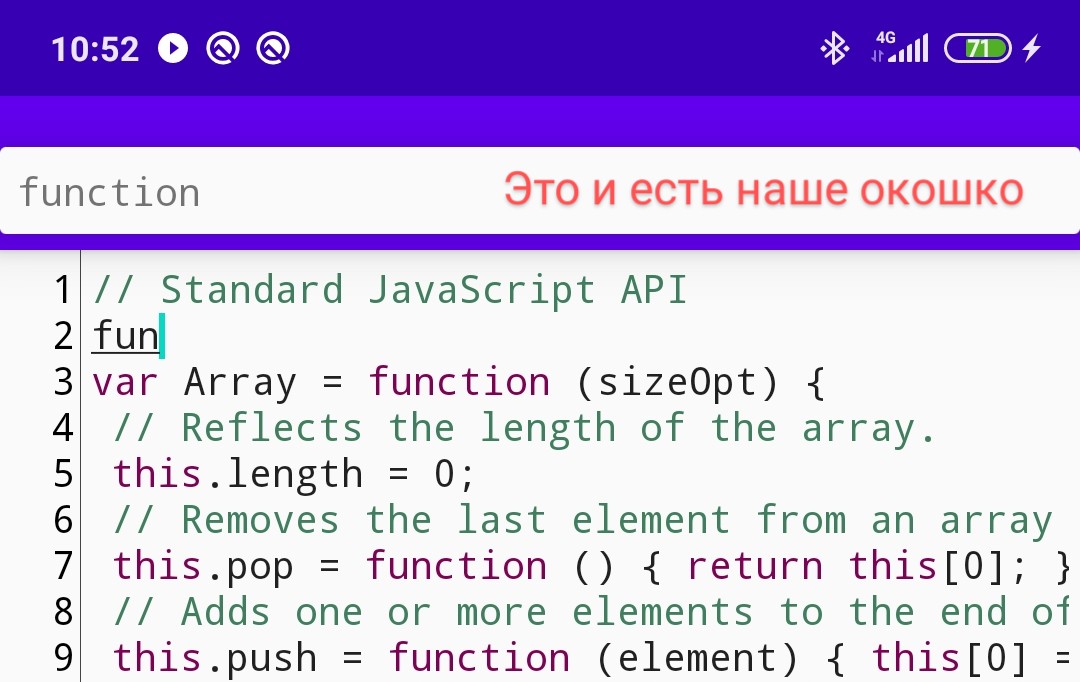
Je préfère également ajouter un délai d'entrée de 2 caractères avant d'afficher la liste:
textProcessor.threshold = 2Installez, exécutez, écrivez du texte - cela fonctionne! Mais pour une raison quelconque, la fenêtre avec les pointes se comporte étrangement - elle est affichée en pleine largeur, sa hauteur est petite et en théorie elle devrait apparaître sous le curseur, comment allons-nous le réparer?
Correction des défauts visuels
C'est là que le plaisir commence, car l'API nous permet de modifier non seulement la taille de la fenêtre, mais aussi sa position.
Tout d'abord, décidons de la taille. À mon avis, l'option la plus pratique serait une fenêtre de la moitié de la hauteur et de la largeur de l'écran, mais comme notre taille
Viewchange en fonction de l'état du clavier, nous sélectionnerons les tailles dans la méthode onSizeChanged:
override fun onSizeChanged(w: Int, h: Int, oldw: Int, oldh: Int) {
super.onSizeChanged(w, h, oldw, oldh)
updateSyntaxHighlighting()
dropDownWidth = w * 1 / 2
dropDownHeight = h * 1 / 2
}
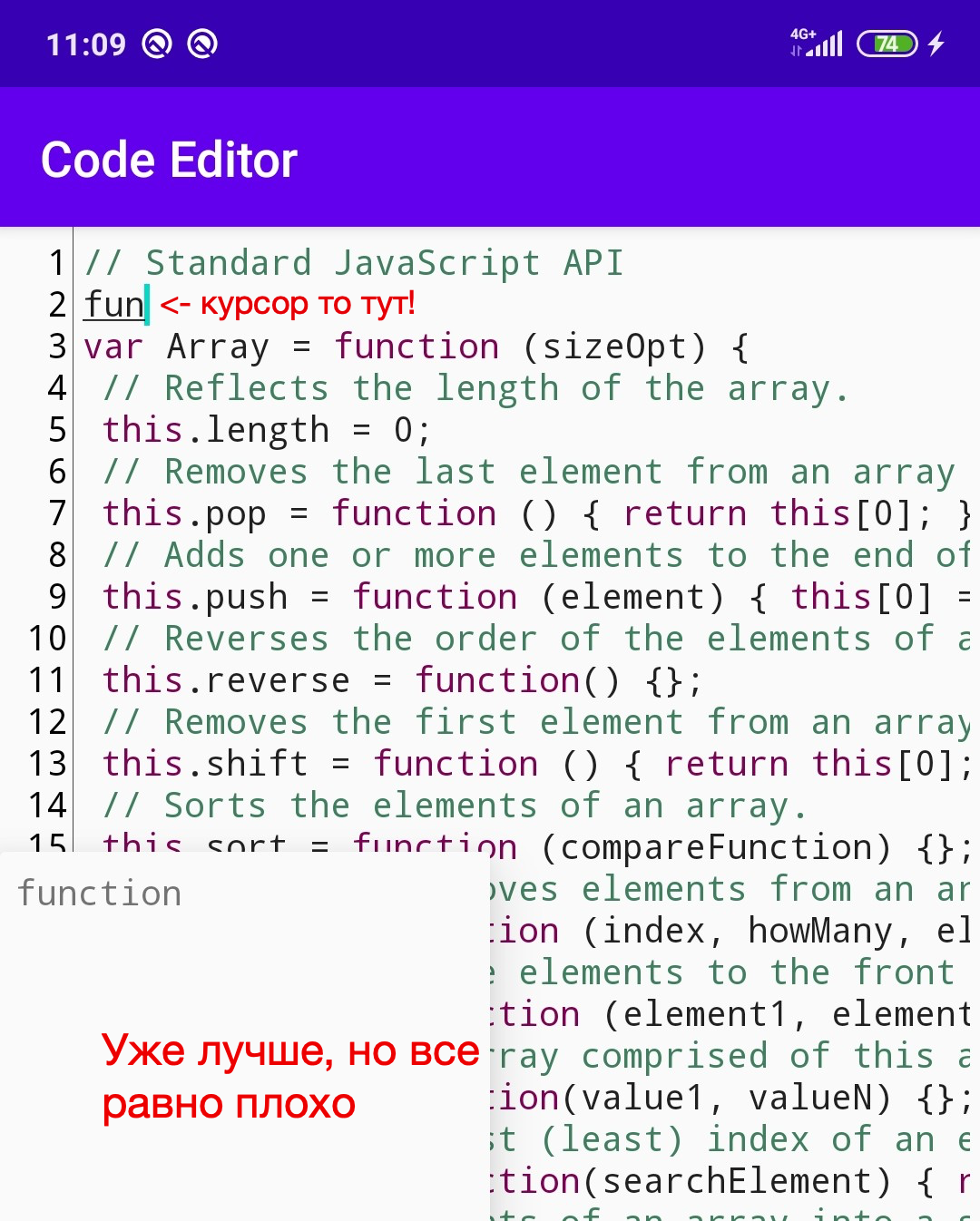 Ça a l'air mieux, mais pas beaucoup. Nous voulons que la fenêtre apparaisse sous le curseur et se déplace avec lui lors de l'édition.
Ça a l'air mieux, mais pas beaucoup. Nous voulons que la fenêtre apparaisse sous le curseur et se déplace avec lui lors de l'édition.
Si tout est assez simple avec le déplacement le long de X - nous prenons la coordonnée du début de la lettre et définissons cette valeur sur
dropDownHorizontalOffset, alors le choix de la hauteur sera plus difficile.
Google sur les propriétés des polices, vous pouvez tomber sur ce post . L'image que l'auteur a jointe montre clairement quelles propriétés nous pouvons utiliser pour calculer la coordonnée verticale.

Maintenant, écrivons une méthode que nous appellerons lorsque le texte deviendra
onTextChanged:
private fun onPopupChangePosition() {
val line = layout.getLineForOffset(selectionStart) //
val x = layout.getPrimaryHorizontal(selectionStart) //
val y = layout.getLineBaseline(line) // baseline
val offsetHorizontal = x + gutterWidth //
dropDownHorizontalOffset = offsetHorizontal.toInt()
val offsetVertical = y - scrollY // -scrollY ""
dropDownVerticalOffset = offsetVertical
}
Il semble qu'ils n'aient rien oublié - le décalage X fonctionne, mais le décalage Y est mal calculé. C'est parce que nous n'avons pas spécifié
dropDownAnchordans le balisage:
android:dropDownAnchor="@id/toolbar"En spécifiant
Toolbarla qualité, dropDownAnchornous informons le widget que la liste déroulante sera affichée en dessous .
Maintenant, si nous commençons à éditer le texte, tout fonctionnera, mais avec le temps, nous remarquerons que si la fenêtre ne rentre pas sous le curseur, elle est traînée avec un énorme retrait, ce qui a l'air moche. Il est temps d'écrire une béquille:

val offset = offsetVertical + dropDownHeight
if (offset < getVisibleHeight()) {
dropDownVerticalOffset = offsetVertical
} else {
dropDownVerticalOffset = offsetVertical - dropDownHeight
}
...
private fun getVisibleHeight(): Int {
val rect = Rect()
getWindowVisibleDisplayFrame(rect)
return rect.bottom - rect.top
}
Nous n'avons pas besoin de changer l'indentation si la somme est
offsetVertical + dropDownHeightinférieure à la hauteur visible de l'écran, car dans ce cas la fenêtre est placée sous le curseur. Mais si c'est encore plus, alors nous soustrayons du retrait dropDownHeight- il s'adaptera donc au curseur sans un énorme retrait que le widget lui-même ajoute.
PS Vous pouvez voir le clavier clignoter sur le gif, et pour être honnête, je ne sais pas comment le réparer, donc si vous avez une solution, écrivez.
Mettre en évidence les erreurs
Avec la mise en évidence des erreurs, tout est beaucoup plus simple qu'il n'y paraît, car nous ne pouvons pas détecter directement les erreurs de syntaxe dans le code - nous utiliserons une bibliothèque d'analyseurs tiers. Depuis que j'écris un éditeur pour JavaScript, mon choix s'est porté sur Rhino , un moteur JavaScript populaire qui a fait ses preuves et qui est toujours pris en charge.
Comment allons-nous analyser?
Lancer Rhino est une opération assez lourde, donc exécuter l'analyseur après chaque caractère entré (comme nous l'avons fait avec la mise en évidence) n'est pas du tout une option. Pour résoudre ce problème, j'utiliserai la bibliothèque RxBinding , et pour ceux qui ne veulent pas faire glisser RxJava dans le projet, vous pouvez essayer des options similaires .
L'opérateur
debouncenous aidera à réaliser ce que nous voulons, et si vous ne le connaissez pas, je vous conseille de lire cet article .
textProcessor.textChangeEvents()
.skipInitialValue()
.debounce(1500, TimeUnit.MILLISECONDS)
.filter { it.text.isNotEmpty() }
.distinctUntilChanged()
.observeOn(AndroidSchedulers.mainThread())
.subscribeBy {
//
}
.disposeOnFragmentDestroyView()
Maintenant écrivons un modèle que l'analyseur nous retournera:
data class ParseResult(val exception: RhinoException?)Je suggère d'utiliser la logique suivante: si aucune erreur n'est trouvée, il y en
exceptionaura null. Sinon, nous obtiendrons un objet RhinoExceptioncontenant toutes les informations nécessaires - numéro de ligne, message d'erreur, StackTrace, etc.
Eh bien, en fait, l'analyse elle-même:
// !
val context = Context.enter() // org.mozilla.javascript.Context
context.optimizationLevel = -1
context.maximumInterpreterStackDepth = 1
try {
val scope = context.initStandardObjects()
context.evaluateString(scope, sourceCode, fileName, 1, null)
return ParseResult(null)
} catch (e: RhinoException) {
return ParseResult(e)
} finally {
Context.exit()
}
Compréhension:
La chose la plus importante ici est la méthode
evaluateString- elle vous permet d'exécuter le code que nous avons passé sous forme de chaîne sourceCode. Le fileNamenom du fichier est indiqué dans - il sera affiché dans les erreurs, l'unité est le numéro de ligne pour commencer à compter, le dernier argument est le domaine de sécurité, mais nous n'en avons pas besoin, nous définissons donc null.
optimisationLevel et maximumInterpreterStackDepth
Un paramètre
optimizationLevelavec une valeur de 1 à 9 vous permet d'activer certaines «optimisations» de code (analyse de flux de données, analyse de flux de types, etc.), ce qui transformera une simple vérification d'erreur de syntaxe en une opération très longue, et nous n'en avons pas besoin.
Si vous l'utilisez avec une valeur de 0 , toutes ces "optimisations" ne seront pas appliquées, cependant, si je comprends bien, Rhino utilisera toujours certaines des ressources qui ne sont pas nécessaires pour une simple vérification d'erreur, ce qui signifie que cela ne nous convient pas.
Il ne reste qu'une valeur négative - en spécifiant -1 nous activons le mode "interpréteur", qui est exactement ce dont nous avons besoin. La documentation indique que c'est le moyen le plus rapide et le plus économique d'exécuter Rhino.
Le paramètre
maximumInterpreterStackDepthvous permet de limiter le nombre d'appels récursifs.
Imaginons ce qui se passe si vous ne spécifiez pas ce paramètre:
- L'utilisateur écrira le code suivant:
function recurse() { recurse(); } recurse(); - Rhino exécutera le code et dans une seconde notre application plantera avec
OutOfMemoryError. La fin.
Affichage des erreurs
Comme je l'ai dit plus tôt, dès que nous aurons le
ParseResultcontenant RhinoException, nous aurons tous les ensembles de données nécessaires à afficher, y compris le numéro de ligne - il suffit d'appeler la méthode lineNumber(). Écrivons
maintenant la ligne ondulée rouge que j'ai copiée dans StackOverflow . Il y a beaucoup de code, mais la logique est simple - tracez deux courtes lignes rouges sous des angles différents.
ErrorSpan.kt
class ErrorSpan(
private val lineWidth: Float = 1 * Resources.getSystem().displayMetrics.density + 0.5f,
private val waveSize: Float = 3 * Resources.getSystem().displayMetrics.density + 0.5f,
private val color: Int = Color.RED
) : LineBackgroundSpan {
override fun drawBackground(
canvas: Canvas,
paint: Paint,
left: Int,
right: Int,
top: Int,
baseline: Int,
bottom: Int,
text: CharSequence,
start: Int,
end: Int,
lineNumber: Int
) {
val width = paint.measureText(text, start, end)
val linePaint = Paint(paint)
linePaint.color = color
linePaint.strokeWidth = lineWidth
val doubleWaveSize = waveSize * 2
var i = left.toFloat()
while (i < left + width) {
canvas.drawLine(i, bottom.toFloat(), i + waveSize, bottom - waveSize, linePaint)
canvas.drawLine(i + waveSize, bottom - waveSize, i + doubleWaveSize, bottom.toFloat(), linePaint)
i += doubleWaveSize
}
}
}
Vous pouvez maintenant écrire une méthode pour installer span sur la ligne de problème:
fun setErrorLine(lineNumber: Int) {
if (lineNumber in 0 until lineCount) {
val lineStart = layout.getLineStart(lineNumber)
val lineEnd = layout.getLineEnd(lineNumber)
text.setSpan(ErrorSpan(), lineStart, lineEnd, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE)
}
}
Il est important de se rappeler que le résultat étant accompagné d'un délai, l'utilisateur peut avoir le temps d'effacer quelques lignes de code, puis il
lineNumberpeut être invalide.
 Par conséquent, pour ne pas l'obtenir,
Par conséquent, pour ne pas l'obtenir, IndexOutOfBoundsExceptionnous ajoutons un chèque au tout début. Eh bien, selon le schéma familier, nous calculons le premier et le dernier caractère de la chaîne, puis définissons la plage.
L'essentiel est de ne pas oublier d'effacer le texte des plages déjà définies dans
afterTextChanged:
fun clearErrorSpans() {
val spans = text.getSpans<ErrorSpan>(0, text.length)
for (span in spans) {
text.removeSpan(span)
}
}
Pourquoi les éditeurs de code sont-ils en retard?
Dans deux articles, nous avons écrit un bon éditeur de code héritant de
EditTextet MultiAutoCompleteTextView, mais nous ne pouvons pas nous vanter de performances lorsque nous travaillons avec de gros fichiers.
Si vous ouvrez le même TextView.java pour 9k + lignes de code, tout éditeur de texte écrit selon le même principe que le nôtre sera lag.
Q: Pourquoi QuickEdit n'est-il pas en retard alors?
R: Parce que sous le capot, il n'utilise ni
EditText, ni TextView.
Récemment, les éditeurs de code sur CustomView gagnent en popularité ( ici et là , enfin, ou ici et là, Il y en a beaucoup). Historiquement, TextView a trop de logique redondante dont les éditeurs de code n'ont pas besoin. Les premières choses qui viennent à l'esprit sont le remplissage automatique , les Emoji , les dessins composés , les liens cliquables , etc.
Si j'ai bien compris, les auteurs des bibliothèques se sont simplement débarrassés de tout cela, à la suite de quoi ils ont obtenu un éditeur de texte capable de travailler avec des fichiers d'un million de lignes sans trop de charge sur l'interface utilisateur. (Bien que je puisse me tromper partiellement, je n'ai pas beaucoup compris la source)
Il existe une autre option, mais à mon avis moins attrayante - les éditeurs de code sur WebView ( ici et là, il y en a beaucoup aussi). Je ne les aime pas parce que l'interface utilisateur sur WebView semble pire que celle native, et ils perdent également face aux éditeurs sur le CustomView en termes de performances.
Conclusion
Si votre tâche est d'écrire un éditeur de code et d'atteindre le sommet de Google Play, ne perdez pas de temps et prenez une bibliothèque toute faite sur CustomView. Si vous voulez vivre une expérience unique, écrivez tout vous-même à l'aide de widgets natifs.
Je laisserai également un lien vers le code source de mon éditeur de code sur GitHub , vous y trouverez non seulement les fonctionnalités dont j'ai parlé dans ces deux articles, mais aussi bien d'autres qui ont été laissées sans attention.
Remercier!