Tête anti-fraude Andrey Popov Nox_andrya fait une présentation sur la manière dont nous avons pu répondre à toutes ces exigences contradictoires. Le sujet central du rapport est un modèle permettant de calculer des facteurs complexes sur un flux de données et d'assurer la tolérance aux pannes du système. Andrey a également décrit brièvement la prochaine version encore plus rapide de l'antifraude, que nous développons actuellement.
L'équipe anti-fraude résout essentiellement le problème de classification binaire. Par conséquent, le rapport peut intéresser non seulement les spécialistes de la lutte contre la fraude, mais également ceux qui créent divers systèmes qui ont besoin de facteurs rapides, fiables et flexibles sur de grandes quantités de données.
- Salut Je m'appelle Andrey. Je travaille chez Yandex, je suis en charge du développement de l'antifraude. On m'a dit que les gens préféraient utiliser le mot «caractéristiques», je vais donc le mentionner tout au long de la conférence, mais le titre et l'introduction sont restés les mêmes, avec le mot «facteurs».
Qu'est-ce que l'antifraude?
Qu'est-ce que l'antifraude de toute façon? C'est un système qui protège les utilisateurs des impacts négatifs sur le service. Par influence négative, j'entends des actions délibérées qui peuvent dégrader la qualité du service et, par conséquent, aggraver l'expérience utilisateur. Il peut s'agir d'analyseurs et de robots assez simples qui aggravent nos statistiques, ou d'activités frauduleuses délibérément complexes. Le second, bien sûr, est plus difficile et plus intéressant à définir.
Contre quoi lutte contre la fraude? Quelques exemples.
Par exemple, imitation des actions des utilisateurs. Ceci est fait par les gars que nous appelons "SEO noir" - ceux qui ne veulent pas améliorer la qualité du site et le contenu du site. Au lieu de cela, ils écrivent des robots qui vont à la recherche Yandex, cliquent sur leur site. Ils s'attendent à ce que leur site augmente de cette façon. Au cas où, je vous rappelle que de telles actions contredisent le contrat d'utilisation et peuvent entraîner de graves sanctions de la part de Yandex.

Ou, par exemple, des critiques de triche. Un tel examen peut être vu de l'organisation sur Maps, qui met des fenêtres en plastique. Elle a elle-même payé pour cette critique.
L'architecture anti-fraude de haut niveau ressemble à ceci: un certain ensemble d'événements bruts tombent dans le système anti-fraude lui-même comme une boîte noire. A la sortie de celui-ci, des événements balisés sont générés.
Yandex propose de nombreux services. Tous, en particulier les plus gros, font face d'une manière ou d'une autre à différents types de fraude. Recherche, marché, cartes et des dizaines d'autres.
Où en étions-nous il y a deux ou trois ans? Chaque équipe a survécu du mieux qu'elle a pu sous l'assaut de la fraude. Elle a généré ses équipes anti-fraude, ses systèmes, qui ne fonctionnaient pas toujours bien, n'étaient pas très pratiques pour interagir avec les analystes. Et surtout, ils étaient mal intégrés les uns aux autres.
Je veux vous dire comment nous avons résolu ce problème en créant une plate-forme unique.

Pourquoi avons-nous besoin d'une plate-forme unique? Réutilisation de l'expérience et des données. La centralisation de l'expérience et des données en un seul endroit vous permet de répondre plus rapidement et mieux aux attaques de grande envergure - elles sont généralement interservices.
Boîte à outils unifiée. Les gens ont les outils auxquels ils sont habitués. Et évidemment la vitesse de connexion. Si nous lançons un nouveau service qui fait actuellement l'objet d'attaques actives, nous devons rapidement y connecter un antifraude de haute qualité.
Nous pouvons dire que nous ne sommes pas uniques à cet égard. Toutes les grandes entreprises sont confrontées à des problèmes similaires. Et chacun avec qui nous communiquons vient à la création de sa plateforme unique.
Je vais vous dire un peu comment nous classons les antifraudes.
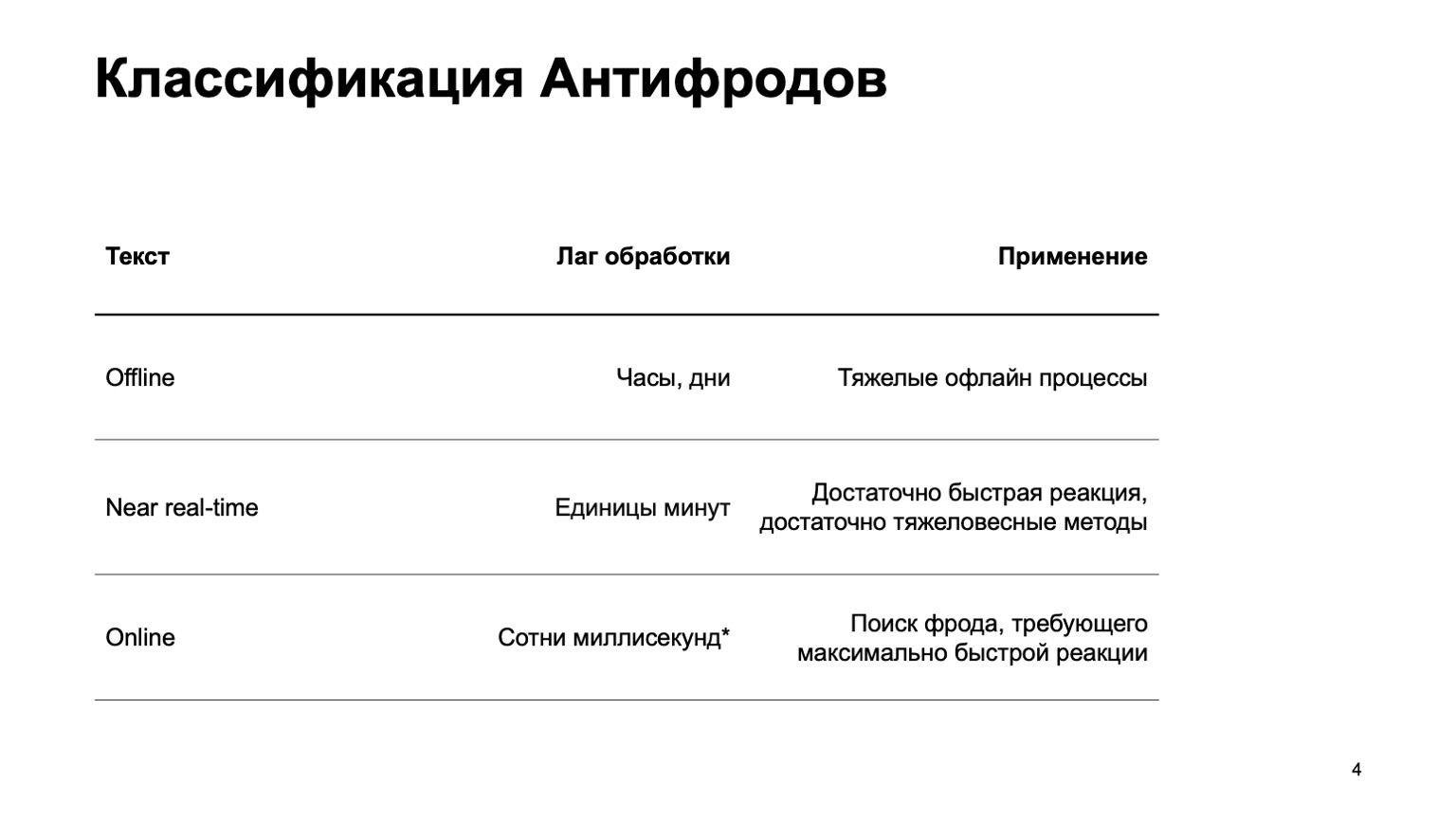
Il peut s'agir d'un système hors ligne qui compte des heures, des jours et des processus hors ligne lourds: par exemple, un clustering complexe ou un recyclage complexe. Je n'aborderai pratiquement pas cette partie du rapport. Il existe une partie en temps quasi réel qui fonctionne en quelques minutes. C'est une sorte de moyen d'or, elle a des réactions rapides et des méthodes lourdes. Tout d'abord, je vais me concentrer sur elle. Mais il est tout aussi important de dire qu'à ce stade, nous utilisons les données de l'étape ci-dessus.
Il existe également des pièces en ligne qui sont nécessaires dans les endroits où une réponse rapide est requise et il est essentiel d'éliminer la fraude avant même d'avoir reçu l'événement et de le transmettre à l'utilisateur. Ici, nous réutilisons à nouveau des données et des algorithmes d'apprentissage automatique calculés à des niveaux plus élevés.
Je parlerai de l'organisation de cette plate-forme unifiée, du langage pour décrire les fonctionnalités et interagir avec le système, de notre chemin vers l'augmentation de la vitesse, c'est-à-dire du passage de la deuxième étape à la troisième.
Je n'aborderai guère les méthodes ML elles-mêmes. En gros, je parlerai des plateformes qui créent des fonctionnalités, que nous utilisons ensuite en formation.
Qui pourrait être intéressé par cela? Évidemment, à ceux qui écrivent de la lutte contre la fraude ou combattent les fraudeurs. Mais aussi pour ceux qui ne font que démarrer le flux de données et lire les fonctionnalités, ML considère. Puisque nous avons élaboré un système assez général, vous serez peut-être intéressé par certains de ces éléments.
Quelles sont les exigences du système? Il y en a pas mal, en voici quelques-uns:
- Grand flux de données. Nous traitons des centaines de millions d'événements en cinq minutes.
- Fonctionnalités entièrement configurables.
- .
- , - exactly-once- , . — , , , , .
- , , .
De plus, je vais vous parler de chacun de ces points séparément.
Puisque pour des raisons de sécurité, je ne peux pas parler de vrais services, introduisons un nouveau service Yandex. En fait non, oubliez, c'est un service fictif que j'ai inventé pour montrer des exemples. Que ce soit un service sur lequel les gens ont une base de données de tous les livres existants. Ils entrent, donnent des notes de un à dix, et les attaquants veulent influencer la note finale afin que leurs livres soient achetés.
Toutes les coïncidences avec des services réels sont, bien entendu, aléatoires. Considérons tout d'abord la version en temps quasi réel, car en ligne n'est pas spécifiquement nécessaire ici à la première approximation.
Big Data
Yandex a un moyen classique de résoudre les problèmes de Big Data: utilisez MapReduce. Nous utilisons notre propre implémentation MapReduce appelée YT . Au fait, Maxim Akhmedov a une histoire à son sujet ce soir . Vous pouvez utiliser votre implémentation ou une implémentation open source comme Hadoop.
Pourquoi n'utilisons-nous pas la version en ligne tout de suite? Ce n'est pas toujours nécessaire, cela peut compliquer les recalculs dans le passé. Si nous avons ajouté un nouvel algorithme, de nouvelles fonctionnalités, nous souhaitons souvent recalculer les données du passé afin de changer les verdicts à ce sujet. Il est plus difficile d'utiliser des méthodes lourdes - je pense que c'est clair pourquoi. Et la version en ligne, pour plusieurs raisons, peut être plus exigeante en termes de ressources.
Si nous utilisons MapReduce, nous obtenons quelque chose comme ceci. Nous utilisons une sorte de mini-batching, c'est-à-dire que nous divisons le lot en les plus petits morceaux possibles. Dans ce cas, c'est une minute. Mais ceux qui travaillent avec MapReduce savent que moins que cette taille, probablement, il y a déjà des frais généraux trop importants du système lui-même - des frais généraux. Classiquement, il ne pourra pas faire face au traitement en une minute.
Ensuite, nous exécutons l'ensemble Réduire sur cet ensemble de lots et obtenons un lot balisé.

Dans nos tâches, il est souvent nécessaire de calculer la valeur exacte des fonctionnalités. Par exemple, si nous voulons calculer le nombre exact de livres que l'utilisateur a lu le mois dernier, nous calculerons cette valeur pour chaque lot et devons stocker toutes les statistiques collectées dans un seul endroit. Ensuite, supprimez les anciennes valeurs et ajoutez-en de nouvelles.
Pourquoi ne pas utiliser des méthodes de comptage approximatives? Réponse courte: nous les utilisons également, mais parfois dans des problèmes de lutte contre la fraude, il est important d'avoir exactement la valeur exacte pour certains intervalles. Par exemple, la différence entre deux et trois livres lus peut être assez importante pour certaines méthodes.
Par conséquent, nous avons besoin d'un historique de données volumineux dans lequel nous stockerons ces statistiques.
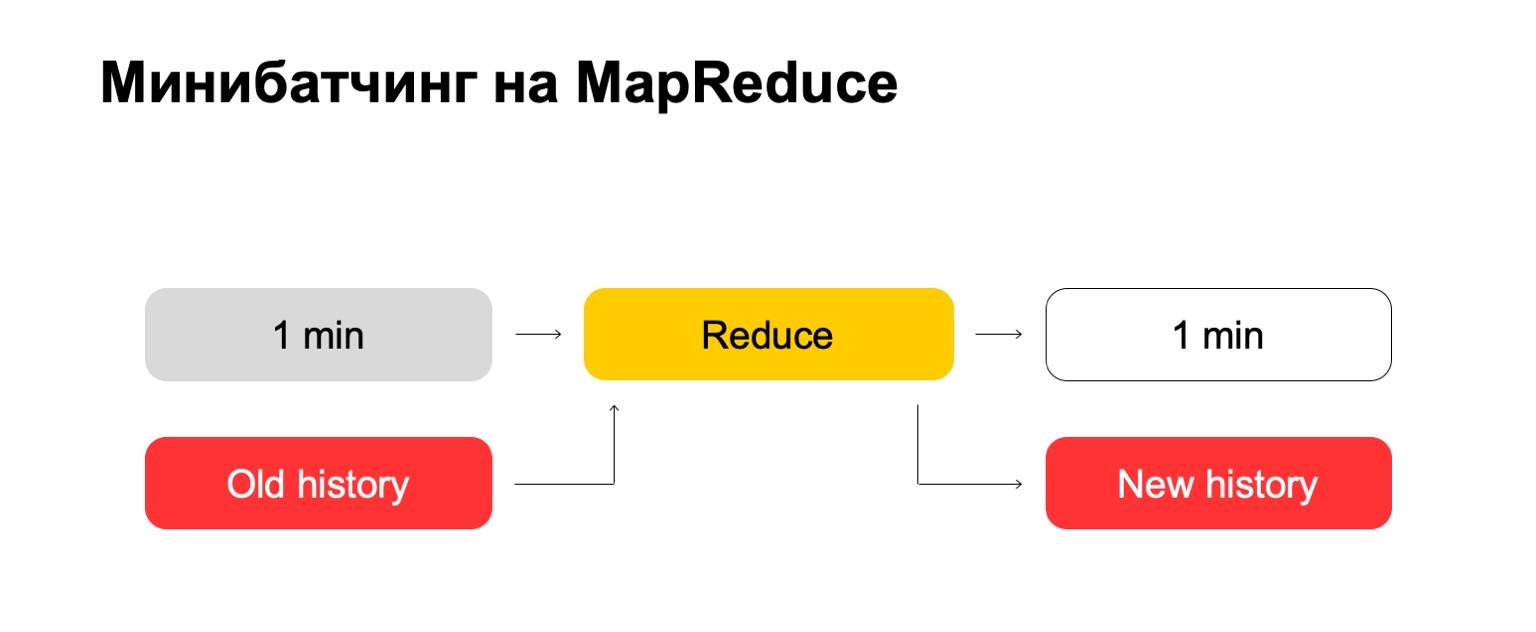
Essayons "de front". Nous avons une minute et une grande vieille histoire. Nous le mettons dans l'entrée Réduire et produisons un historique mis à jour et un journal balisé, des données.
Pour ceux d'entre vous qui ont travaillé avec MapReduce, vous savez probablement que cela peut fonctionner assez mal. Si l'historique peut être des centaines, voire des milliers, des dizaines de milliers de fois plus grand que le lot lui-même, alors un tel traitement peut fonctionner proportionnellement à la taille de l'historique, et non à la taille du lot.
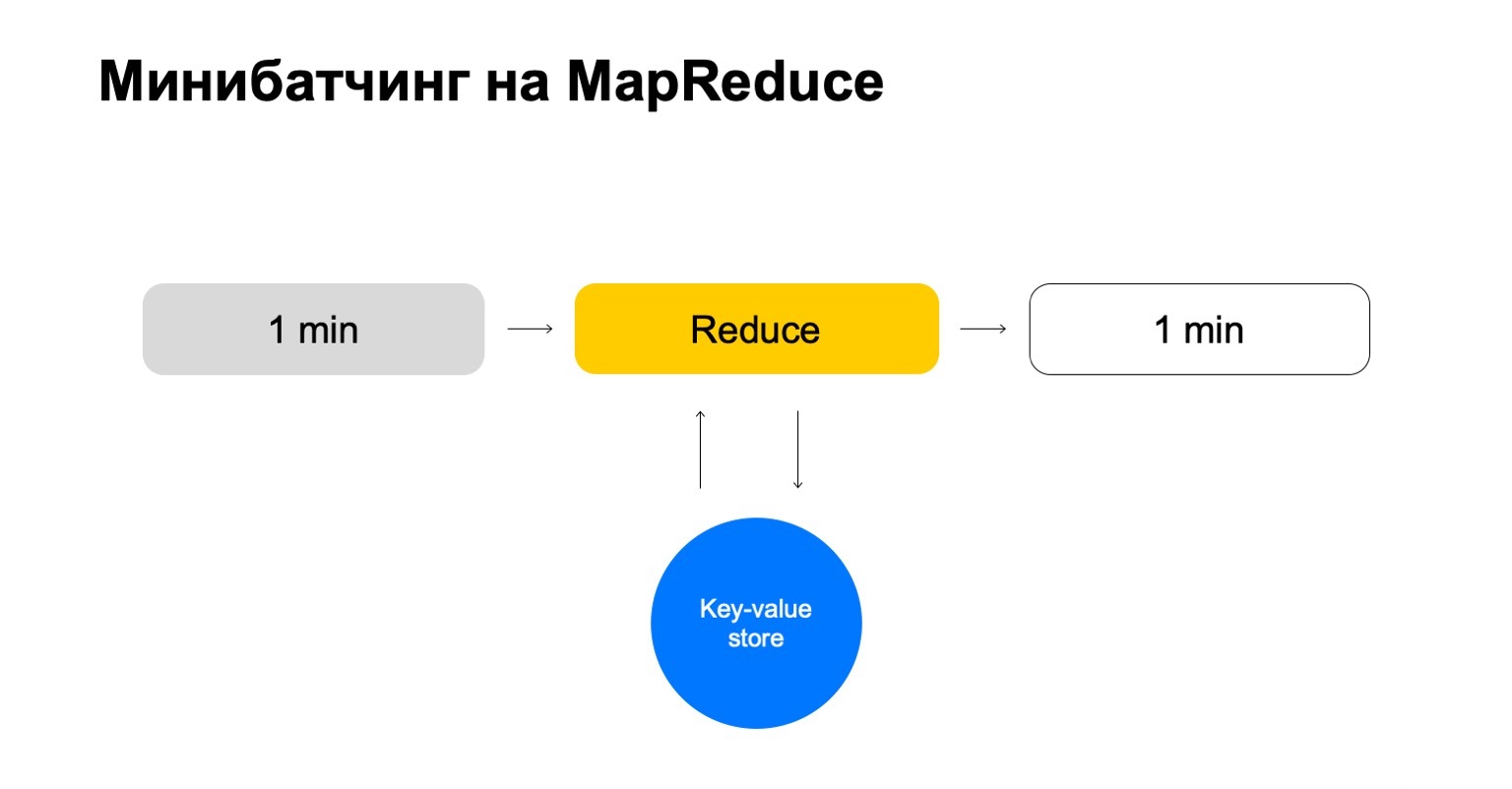
Remplaçons cela par un magasin clé-valeur. C'est à nouveau notre propre implémentation, le stockage clé-valeur, mais il stocke les données en mémoire. L'analogue le plus proche est probablement une sorte de Redis. Mais nous obtenons un léger avantage ici: notre implémentation du magasin clé-valeur est très étroitement intégrée à MapReduce et au cluster MapReduce sur lequel il s'exécute. Il s'avère une transaction pratique, un transfert de données pratique entre eux.
Mais le schéma général est que dans chaque tâche de cette réduction, nous allons accéder à ce stockage de clé-valeur, mettre à jour les données et les réécrire après avoir formulé un verdict à ce sujet.
Nous nous retrouvons avec une histoire qui ne gère que les clés dont nous avons besoin et qui évolue facilement.
Fonctionnalités configurables
Un peu sur la façon dont nous configurons les fonctionnalités. Les compteurs simples ne suffisent souvent pas. Pour rechercher des escrocs, vous avez besoin d'une variété de fonctionnalités, vous avez besoin d'un système intelligent et pratique pour les configurer.
Décomposons-le en trois étapes:
- Extrait, où nous extrayons les données de la clé donnée et du journal.
- Fusionner, où nous fusionnons ces données avec les statistiques qui sont dans l'histoire.
- Build, où nous formons la valeur finale de la fonctionnalité.
Par exemple, calculons le pourcentage d'histoires policières lues par un utilisateur.
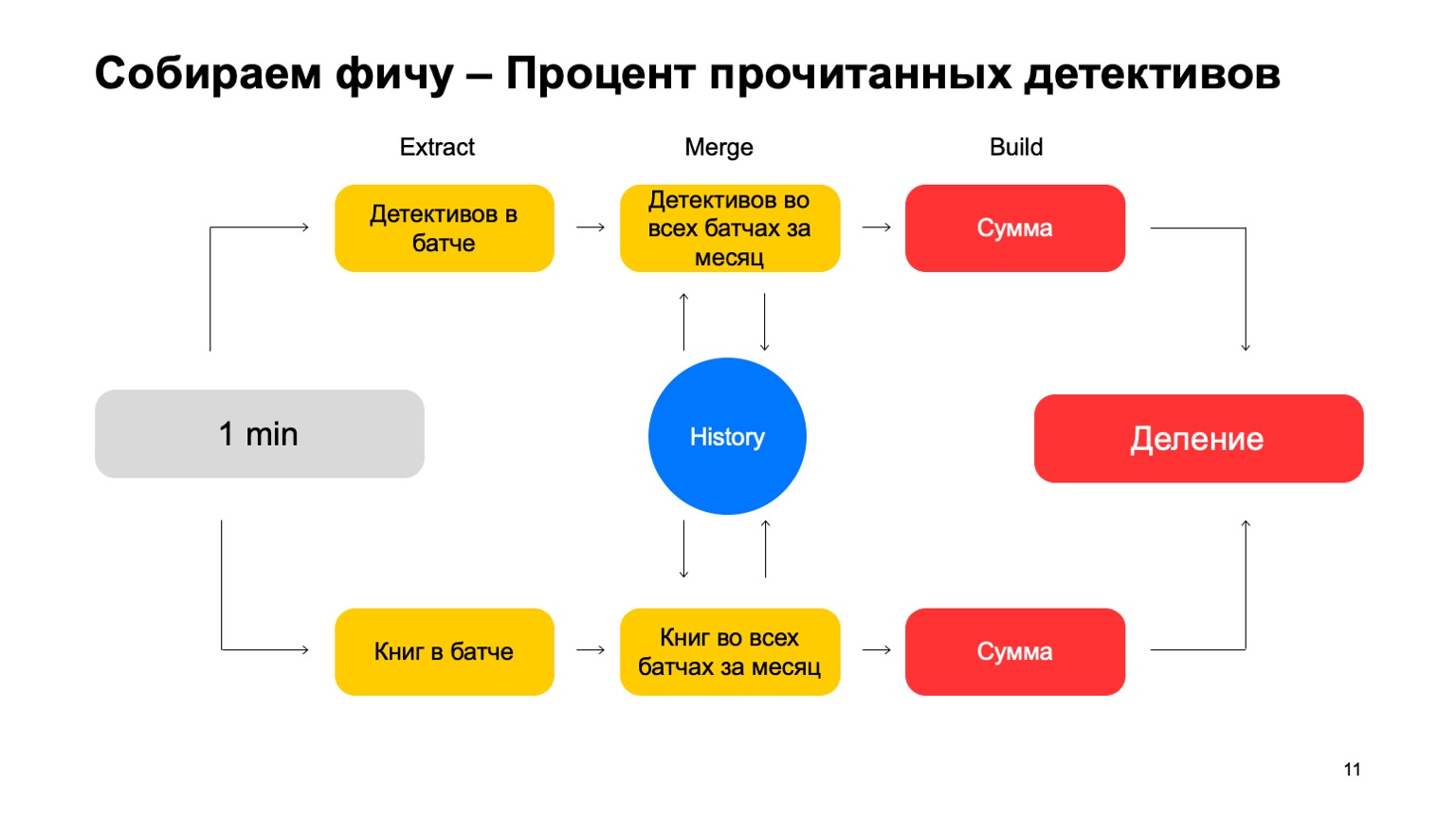
Si l'utilisateur lit trop d'histoires policières, il est trop méfiant. On ne sait jamais à quoi s'attendre de lui. Ensuite, Extract est la suppression du nombre de détectives que l'utilisateur a lu dans ce lot. Fusionner - prendre tous les détectives, toutes ces données à partir de lots pendant un mois. Et Build est un certain montant.
Ensuite, nous faisons de même pour la valeur de tous les livres qu'il a lus, et nous nous retrouvons avec la division.
Que faire si nous voulons compter différentes valeurs, par exemple, le nombre d'auteurs différents qu'un utilisateur lit?
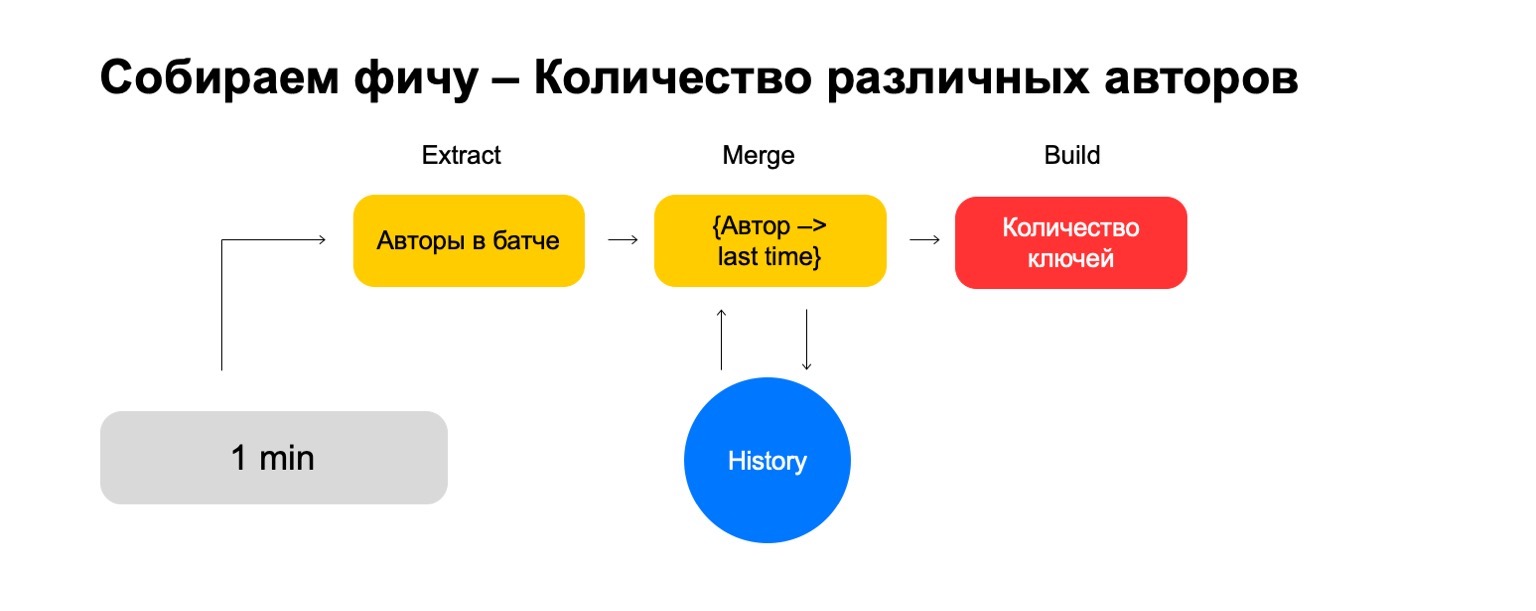
Ensuite, nous pouvons prendre le nombre d'auteurs différents que l'utilisateur a lu dans ce lot. De plus, stockez une structure dans laquelle nous faisons une association d'auteurs récemment, lorsque l'utilisateur les lit. Ainsi, si nous rencontrons à nouveau cet auteur chez l'utilisateur, nous mettons cette fois à jour. Si nous devons supprimer d'anciens événements, nous savons quoi supprimer. Pour calculer la caractéristique finale, nous comptons simplement le nombre de clés qu'il contient.

Mais dans un signal bruyant, de telles fonctionnalités ne suffisent pas pour une seule coupe, nous avons besoin d'un système pour coller leurs jointures, en collant ces caractéristiques à partir de différentes coupes.
Introduisons, par exemple, de telles coupes - utilisateur, auteur et genre.

Calculons quelque chose de difficile. Par exemple, fidélité moyenne des auteurs. Par fidélité, je veux dire que les utilisateurs qui lisent l'auteur - ils le lisent presque uniquement. De plus, cette valeur moyenne est assez faible pour le nombre moyen d'auteurs lus par les utilisateurs qui le lisent.
Cela pourrait être un signal potentiel. Lui, bien sûr, peut signifier que l'auteur est comme ça: il n'y a que des fans autour de lui, tout le monde qui le lit ne lit que lui. Mais cela peut aussi signifier que l'auteur lui-même tente de tromper le système et de créer ces faux utilisateurs qui sont censés le lire.
Essayons de le calculer. Comptons une fonctionnalité qui compte le nombre d'auteurs différents sur un long intervalle. Par exemple, ici les deuxième et troisième valeurs nous semblent suspectes, il y en a trop peu.
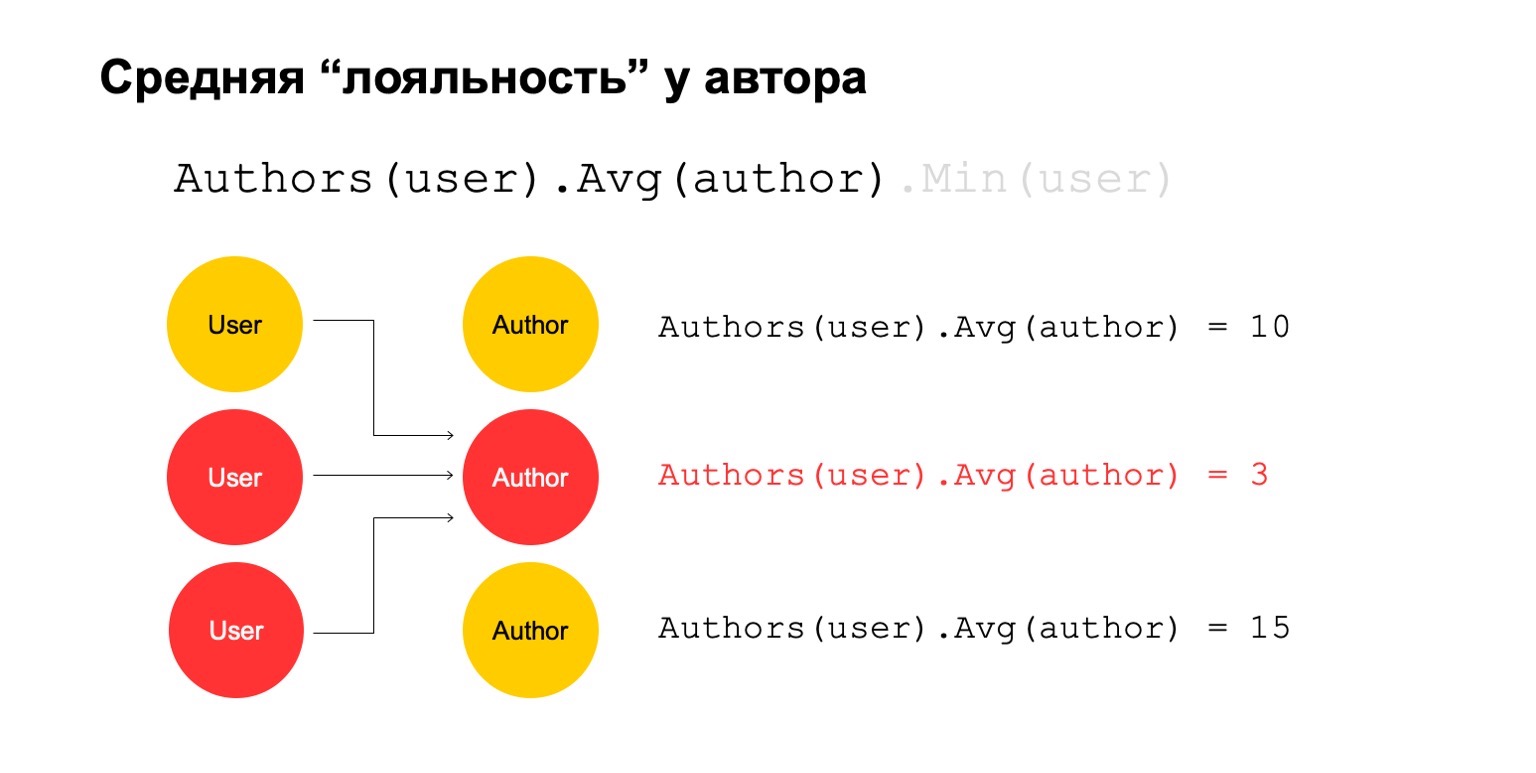
Calculons ensuite la valeur moyenne des auteurs liés sur un grand intervalle. Et puis ici la valeur moyenne est encore assez faible: 3. Pour une raison quelconque, cet auteur nous paraît suspect.
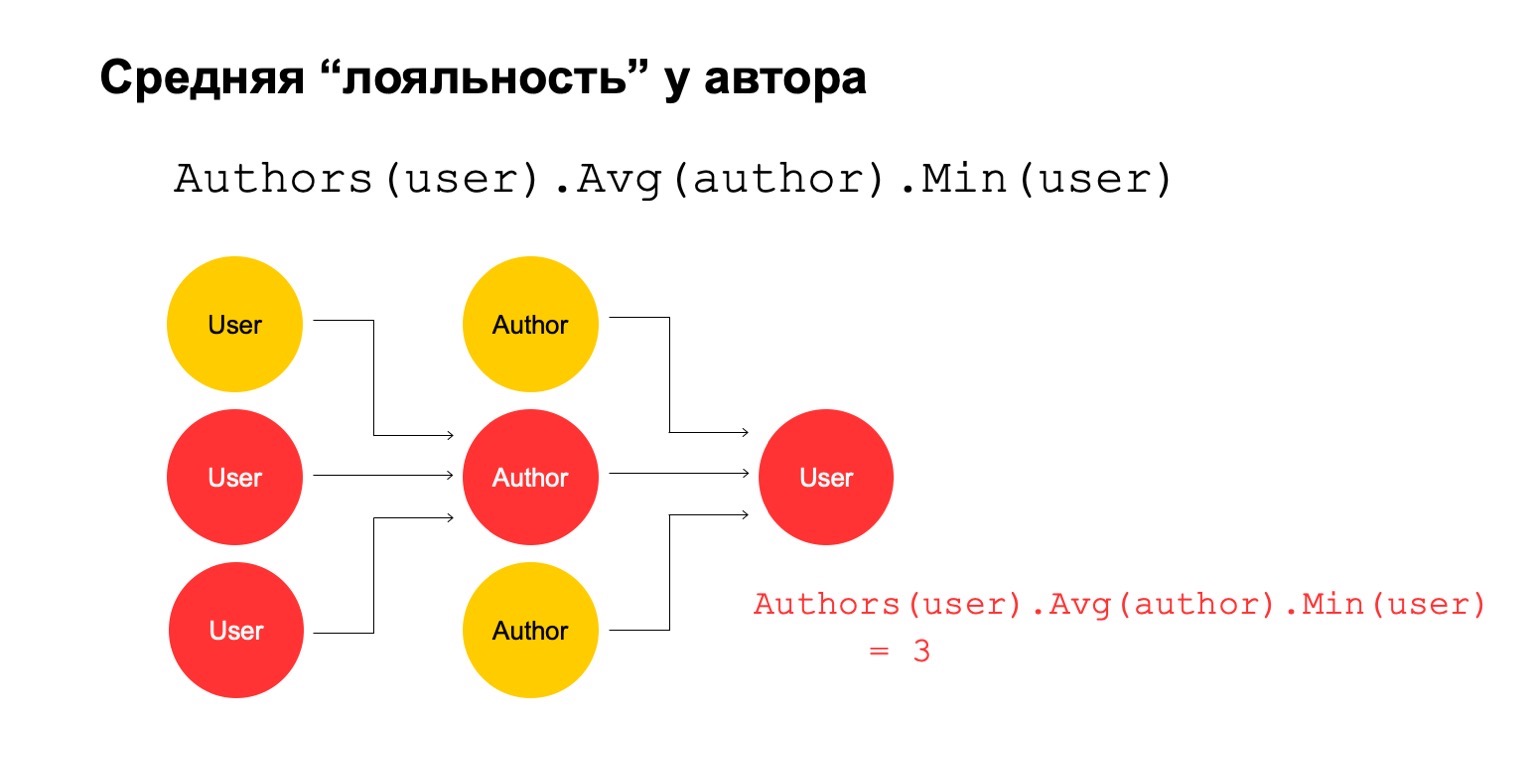
Et nous pouvons le renvoyer à l'utilisateur afin de comprendre que cet utilisateur particulier a une connexion avec l'auteur, ce qui nous semble suspect.
Il est clair que cela ne peut pas en soi être un critère explicite selon lequel l'utilisateur doit être filtré ou quelque chose du genre. Mais cela pourrait être l'un des signaux que nous pouvons utiliser.
Comment faire cela dans le paradigme MapReduce? Faisons plusieurs réductions consécutives et les dépendances entre elles.

Nous obtenons un graphique des réductions. Il influe sur les tranches que nous comptons les fonctionnalités, quelles jointures sont généralement autorisées, sur la quantité de ressources consommées: évidemment, plus il y a de réductions, plus il y a de ressources. Et latence, débit.
Construisons, par exemple, un tel graphe.
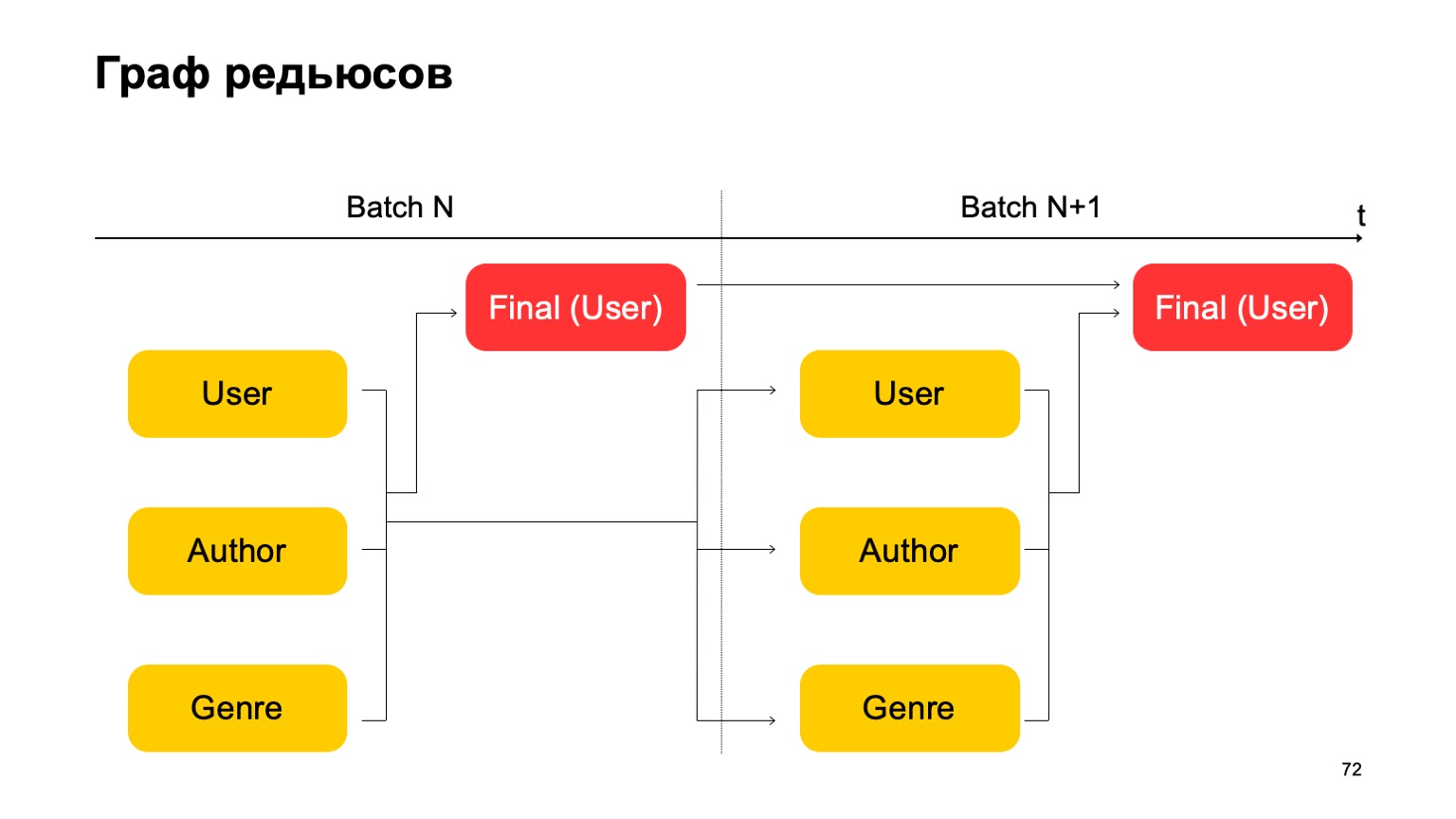
Autrement dit, nous allons diviser les réductions que nous avons en deux étapes. Dans un premier temps, nous calculerons différentes réductions en parallèle pour différentes sections - nos utilisateurs, auteurs et genre. Et nous avons besoin d'une sorte de deuxième étape, où nous collecterons les caractéristiques de ces différentes réductions et accepterons le verdict final.
Pour le prochain lot, nous faisons de même. De plus, nous avons une dépendance de la première étape de chaque lot sur la première étape du passé et la deuxième étape sur la deuxième étape du passé.
Il est important ici que nous n'ayons pas une telle dépendance:
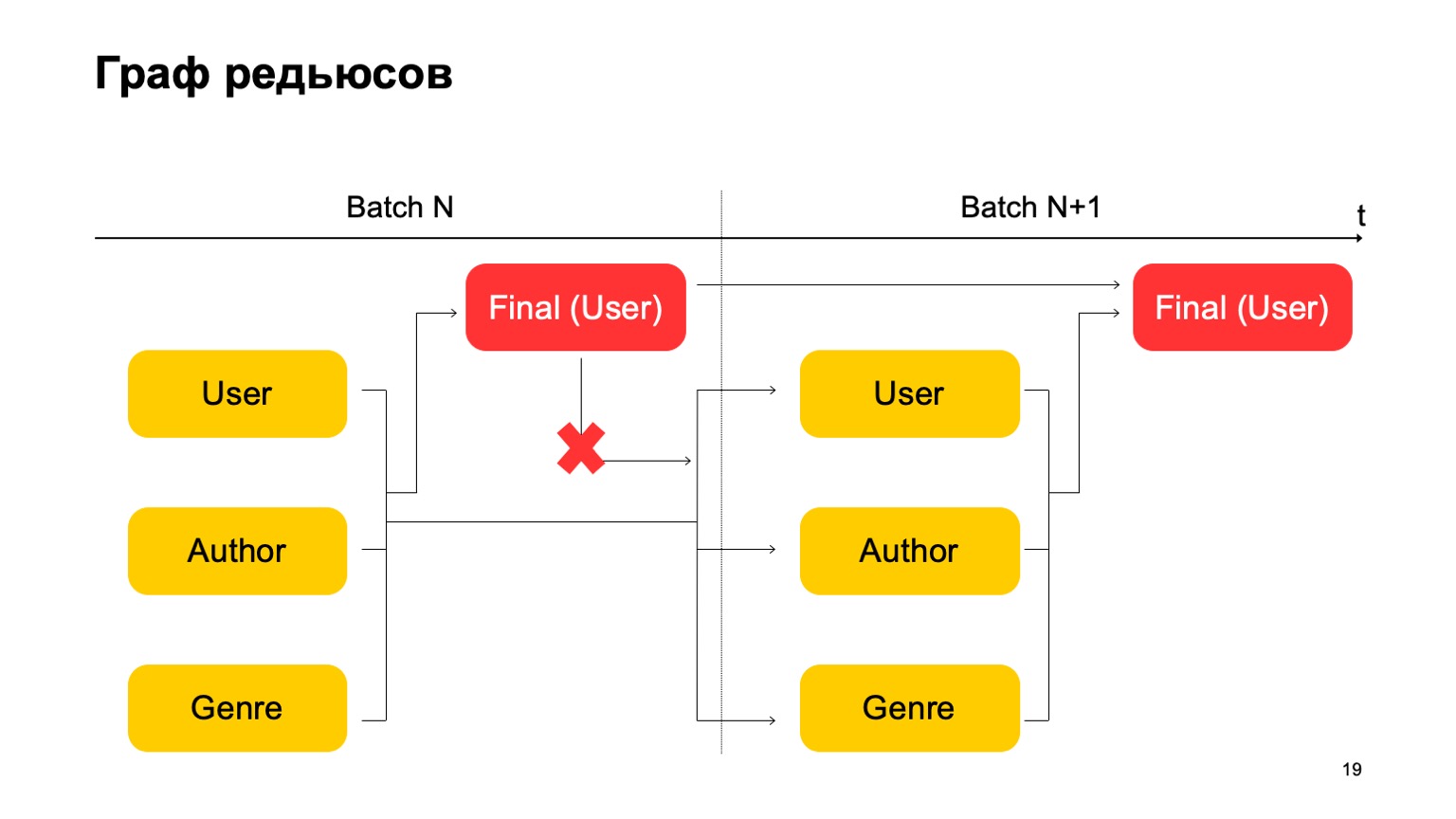
Autrement dit, nous obtenons en fait un convoyeur. Autrement dit, la première étape du lot suivant peut fonctionner en parallèle avec la deuxième étape du premier lot.
Comment pouvons-nous faire les statistiques en trois étapes, que j'ai données ci-dessus, si nous n'avons que deux étapes? Très simple. On peut lire la première valeur à la première étape du lot N.
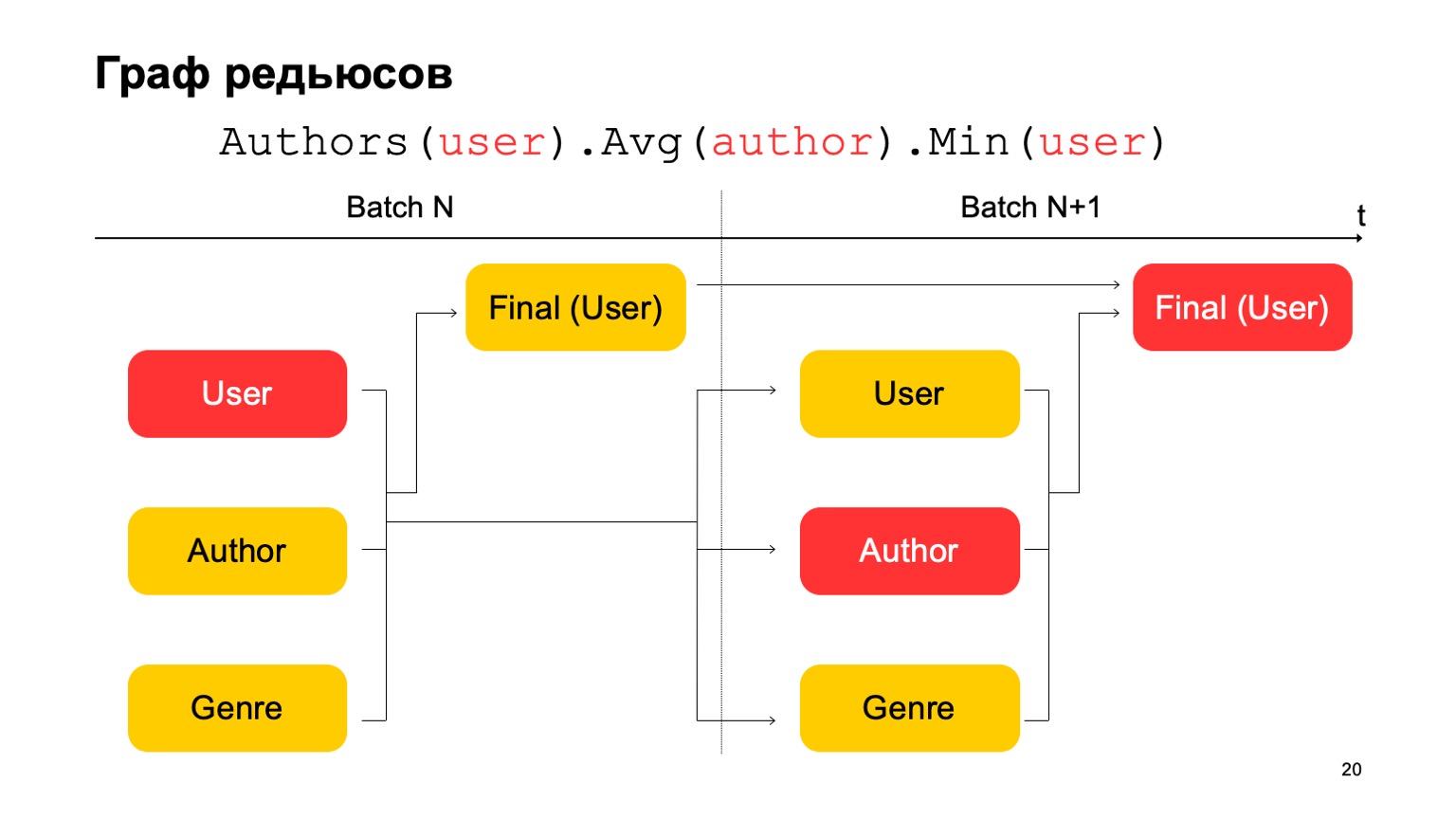
La deuxième valeur à la première étape du lot est N + 1, et la valeur finale doit être lue à la deuxième étape du lot N + 1. Ainsi, lors de la transition entre le premier étage et le second, il y aura, peut-être, des statistiques pas tout à fait précises pour le lot N + 1. Mais généralement, cela suffit pour de tels calculs.

Avec toutes ces choses, vous pouvez créer des fonctionnalités plus complexes à partir de cubes. Par exemple, l'écart de la note actuelle du livre par rapport à la note moyenne de l'utilisateur. Ou la proportion d'utilisateurs qui évaluent un livre de manière très positive ou très négative. Aussi suspect. Ou la note moyenne des livres par les utilisateurs qui ont plus de N notes pour différents livres. Il s'agit peut-être d'une évaluation plus précise et juste d'un certain point de vue.

À cela s'ajoute ce que nous appelons la relation entre les événements. Les doublons apparaissent souvent dans les journaux ou dans les données qui nous sont envoyées. Il peut s'agir d'événements techniques ou de comportements robotiques. Nous trouvons également de tels doublons. Ou, par exemple, certains événements liés. Supposons que votre système affiche des recommandations de livres et que les utilisateurs cliquent sur ces recommandations. Pour que les statistiques finales qui affectent le classement ne soient pas gâchées, nous devons nous assurer que si nous filtrons l'impression, nous devons également filtrer le clic sur la recommandation actuelle.
Mais comme notre flux peut venir de manière inégale, d'abord un clic, nous devons le reporter jusqu'à ce que nous voyions le spectacle et acceptions un verdict basé sur celui-ci.
Langue de description des fonctionnalités
Je vais vous parler un peu du langage utilisé pour décrire tout cela.

Vous n'êtes pas obligé de le lire, c'est par exemple. Nous avons commencé avec trois composants principaux. Le premier est une description des unités de données dans l'histoire, en général, de type arbitraire.

C'est une sorte de fonctionnalité, un nombre Nullable.

Et une sorte de règle. Comment appelle-t-on une règle? Il s'agit d'un ensemble de conditions pour ces fonctionnalités et autre chose. Nous avions trois fichiers distincts.
Le problème est qu'ici une chaîne d'actions est répartie sur différents fichiers. Un grand nombre d'analystes doivent travailler avec notre système. Ils étaient mal à l'aise.
Le langage s'avère impératif: nous décrivons comment calculer les données, et non déclaratif, quand nous décririons ce que nous devons calculer. Ce n'est pas non plus très pratique, il est assez facile de se tromper et un seuil d'entrée élevé. De nouvelles personnes arrivent, mais elles ne comprennent pas du tout comment travailler avec.
Solution - faisons notre propre DSL. Il décrit notre scénario plus clairement, c'est plus facile pour les nouvelles personnes, c'est plus de haut niveau. Nous nous sommes inspirés de SQLAlchemy, C # Linq et autres.
Je vais donner quelques exemples similaires à ceux que j'ai donnés ci-dessus.

Pourcentage de romans policiers lus. Nous comptons le nombre de livres lus, c'est-à-dire que nous les regroupons par utilisateur. Nous ajoutons un filtrage à cette condition, et si nous voulons calculer le pourcentage final, nous calculons simplement la note. Tout est simple, clair et intuitif.

Si nous comptons le nombre d'auteurs différents, nous groupons par utilisateur, définissons des auteurs distincts. A cela nous pouvons ajouter quelques conditions, par exemple, une fenêtre de calcul ou une limite sur le nombre de valeurs que nous stockons en raison de contraintes de mémoire. En conséquence, nous comptons compter, le nombre de clés qu'il contient.

Ou la loyauté moyenne dont je parlais. Autrement dit, encore une fois, nous avons une sorte d'expression calculée à partir du dessus. Nous regroupons par auteur et définissons une valeur moyenne parmi ces expressions. Ensuite, nous le restreignons à l'utilisateur.

À cela, nous pouvons alors ajouter une condition de filtre. Autrement dit, notre filtre peut être, par exemple, le suivant: la fidélité n'est pas trop élevée et le pourcentage de détectives est compris entre 80 sur 100.
Qu'utilisons-nous pour cela sous le capot?
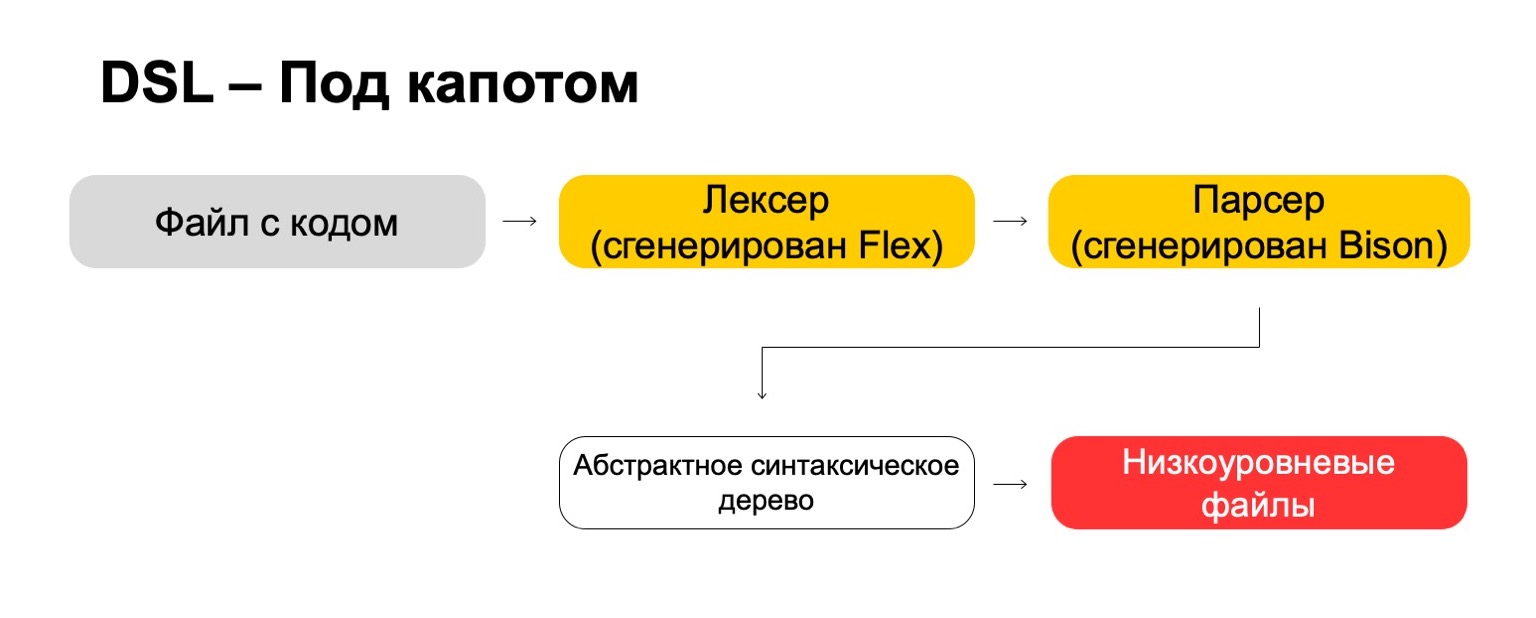
Sous le capot, nous utilisons les technologies les plus modernes directement des années 70, comme Flex, Bison. Peut-être que vous avez entendu. Ils génèrent du code. Notre fichier de code passe par notre lexer, qui est généré dans Flex, et par l'analyseur, qui est généré dans Bison. Le lexer génère des symboles terminaux ou des mots dans le langage, l'analyseur génère des expressions de syntaxe.
De cela, nous obtenons un arbre de syntaxe abstraite, avec lequel nous pouvons déjà faire des transformations. Et à la fin, nous les transformons en fichiers de bas niveau que le système comprend.
Quel est le résultat? C'est plus compliqué qu'il n'y paraît à première vue. Il faut beaucoup de ressources pour réfléchir à de petites choses comme les priorités pour les opérations, les cas extrêmes, etc. Vous devez apprendre des technologies rares qui ne vous seront probablement pas utiles dans la vraie vie, à moins que vous n'écriviez des compilateurs, bien sûr. Mais à la fin ça vaut le coup. C'est-à-dire que si vous avez, comme nous, un grand nombre d'analystes qui viennent souvent d'autres équipes, cela donne au final un avantage significatif, car il devient plus facile pour eux de travailler.
Fiabilité
Certains services nécessitent une tolérance aux pannes: traitement cross-DC et exactement une fois. Une violation peut entraîner des écarts dans les statistiques et des pertes, y compris des pertes monétaires. Notre solution pour MapReduce est telle que nous lisons les données à la fois sur un seul cluster et les synchronisons sur le second.
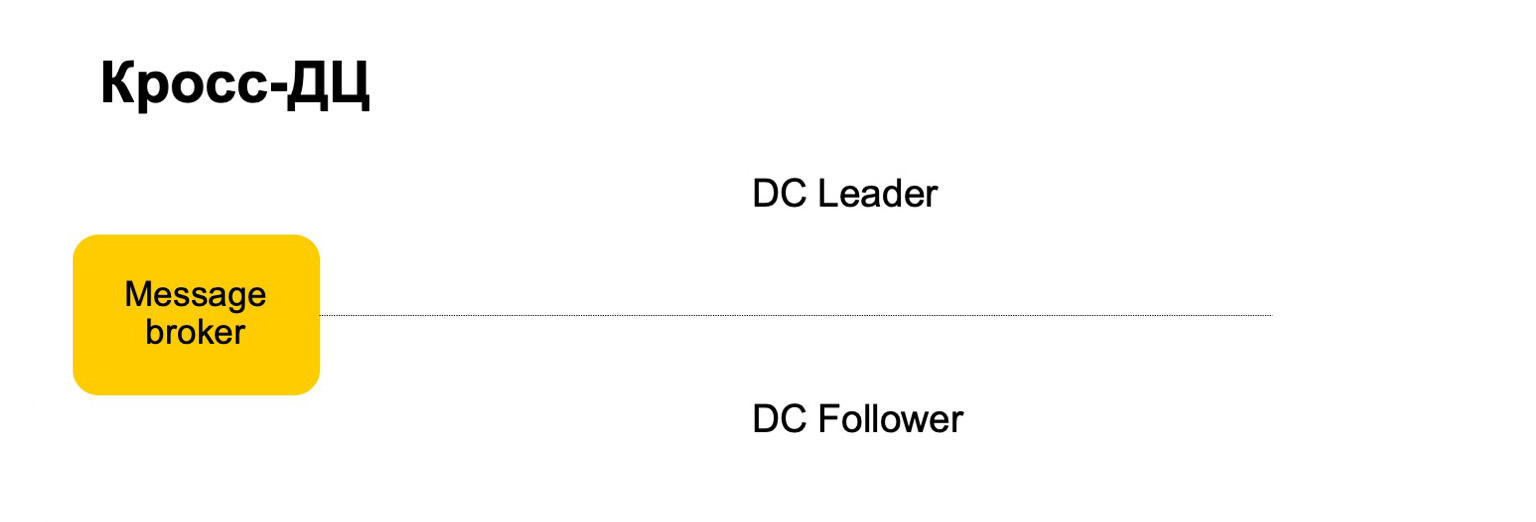
Par exemple, comment pourrions-nous nous comporter ici? Il y a un leader, un suiveur et un courtier de messages. On peut considérer qu'il s'agit d'une kafka conditionnelle, bien qu'ici, bien sûr, sa propre implémentation.
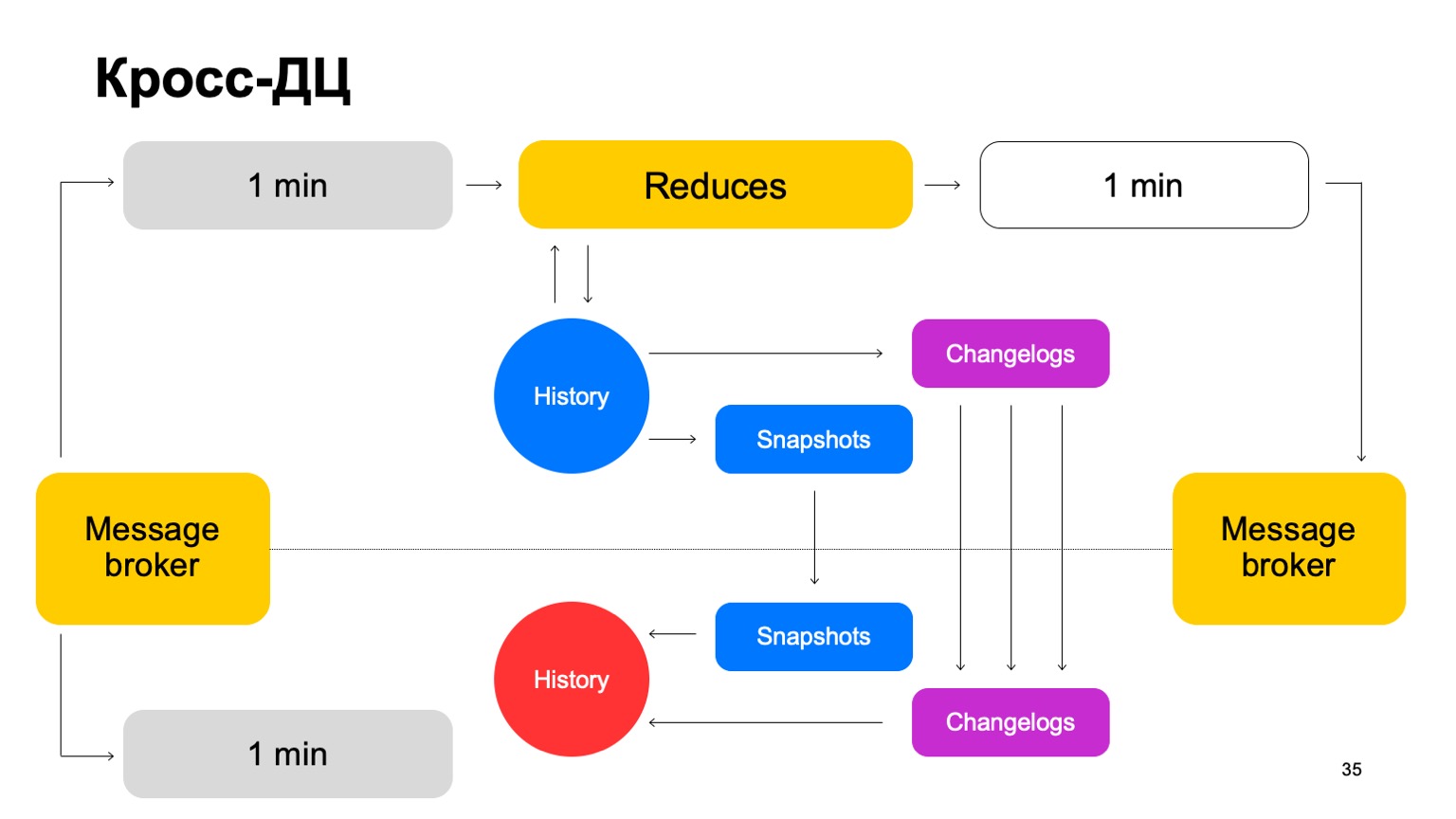
Nous livrons nos lots aux deux clusters, lançons un ensemble de réductions sur le même leader, acceptons les verdicts finaux, mettons à jour l'historique et renvoyons les résultats au service au courtier de messages.
De temps en temps, nous devons naturellement faire de la réplication. Autrement dit, nous collectons des instantanés, collectons les modifications - modifications pour chaque lot. Nous synchronisons les deux avec le deuxième suiveur de cluster. Et aussi évoquer une histoire qui est si chaude. Permettez-moi de vous rappeler que l’histoire est ici gardée en mémoire.
Ainsi, si un contrôleur de domaine pour une raison quelconque devient indisponible, nous pouvons assez rapidement, avec un décalage minimal, passer au deuxième cluster.
Pourquoi ne pas compter sur deux clusters en parallèle? Les données externes peuvent différer sur deux clusters, elles peuvent être fournies par des services externes. Qu'est-ce que les données externes de toute façon? C'est quelque chose qui découle de ce niveau supérieur. C'est-à-dire un regroupement complexe et autres. Ou simplement des données auxiliaires pour les calculs.
Nous avons besoin d'une solution convenue. Si nous comptons les verdicts en parallèle en utilisant des données différentes et basculons périodiquement entre les résultats de deux clusters différents, la cohérence entre eux diminuera considérablement. Et, bien sûr, économiser des ressources. Puisque nous utilisons les ressources du processeur sur un seul cluster à la fois.
Qu'en est-il du deuxième cluster? Quand nous travaillons, il est pratiquement inactif. Utilisons ses ressources pour une pré-production à part entière. Par pré-production à part entière, j'entends ici une installation à part entière qui accepte le même flux de données, fonctionne avec les mêmes volumes de données, etc.

Si le cluster n'est pas disponible, nous faisons passer ces installations de la vente à la pré-production. Ainsi, nous avons un pré-produit pour un certain temps, mais ça va.
L'avantage est que nous pouvons compter plus de fonctionnalités sur le prétraitement. Pourquoi est-ce même nécessaire? Parce qu'il est clair que si nous voulons compter un grand nombre de fonctionnalités, nous n'avons souvent pas besoin de les compter toutes en solde. Là, nous ne comptons que ce qui est nécessaire pour obtenir les verdicts définitifs.
(00:25:12)
Mais en même temps, nous avons une sorte de hot cache au stade du prétraitement, grand, avec une grande variété de fonctionnalités. En cas d'attaque, nous pouvons l'utiliser pour clore le problème et transférer ces fonctionnalités en production.
À cela s'ajoutent les avantages des tests B2B. Autrement dit, nous déployons tous, bien sûr, d'abord pour la prévente. Nous comparons entièrement toutes les différences et, par conséquent, nous ne nous trompons pas, nous minimisons la probabilité que nous puissions faire une erreur lors de la mise en vente.
Un peu sur le planificateur. Il est clair que nous avons une sorte de machines qui exécutent la tâche dans MapReduce. Ce sont des sortes de travailleurs. Ils synchronisent régulièrement leurs données avec la base de données Cross-DC. C'est juste l'état de ce qu'ils ont réussi à calculer pour le moment.
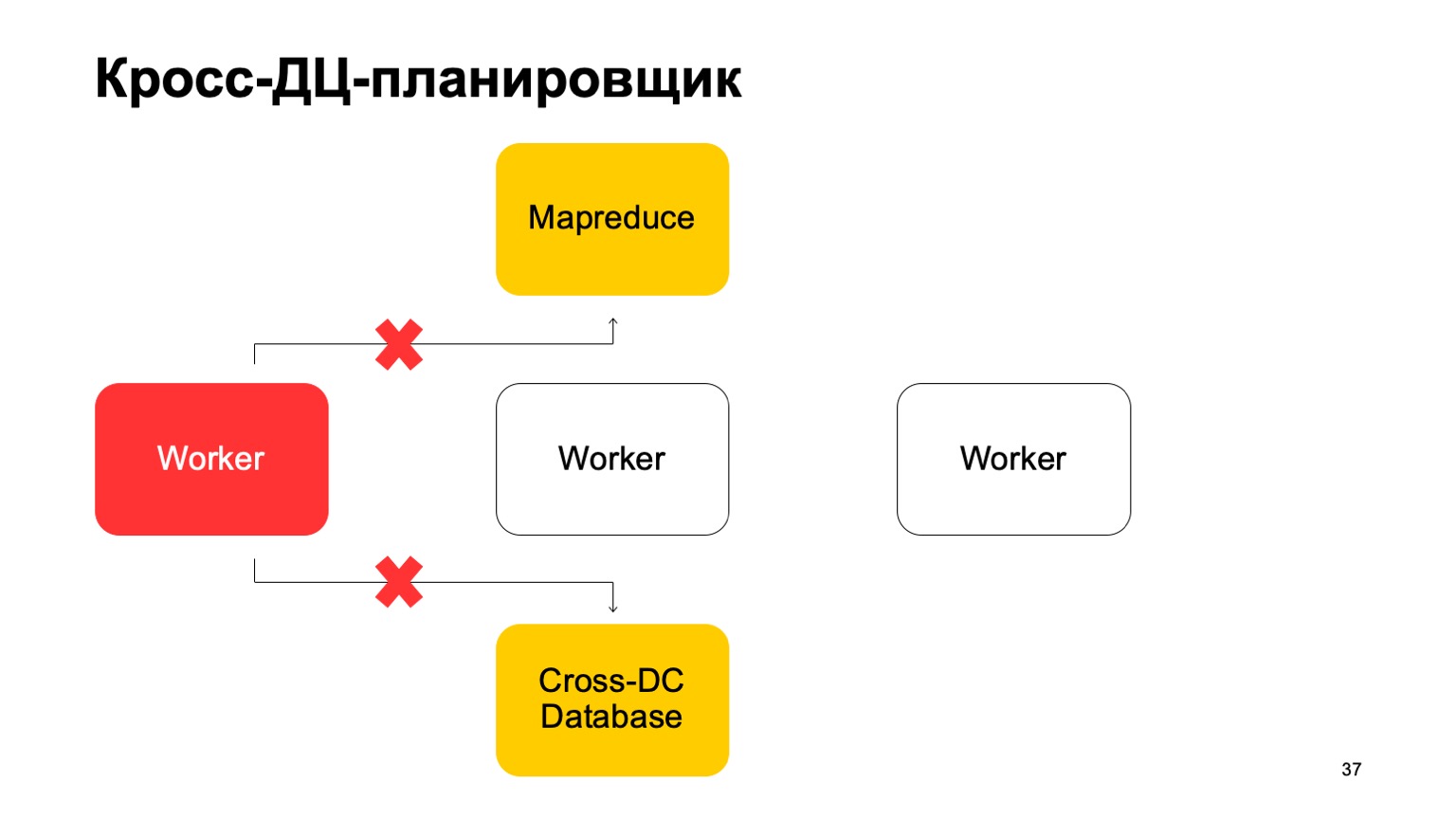
Si un travailleur devient indisponible, un autre travailleur tente de capturer le journal, prenez l'état.
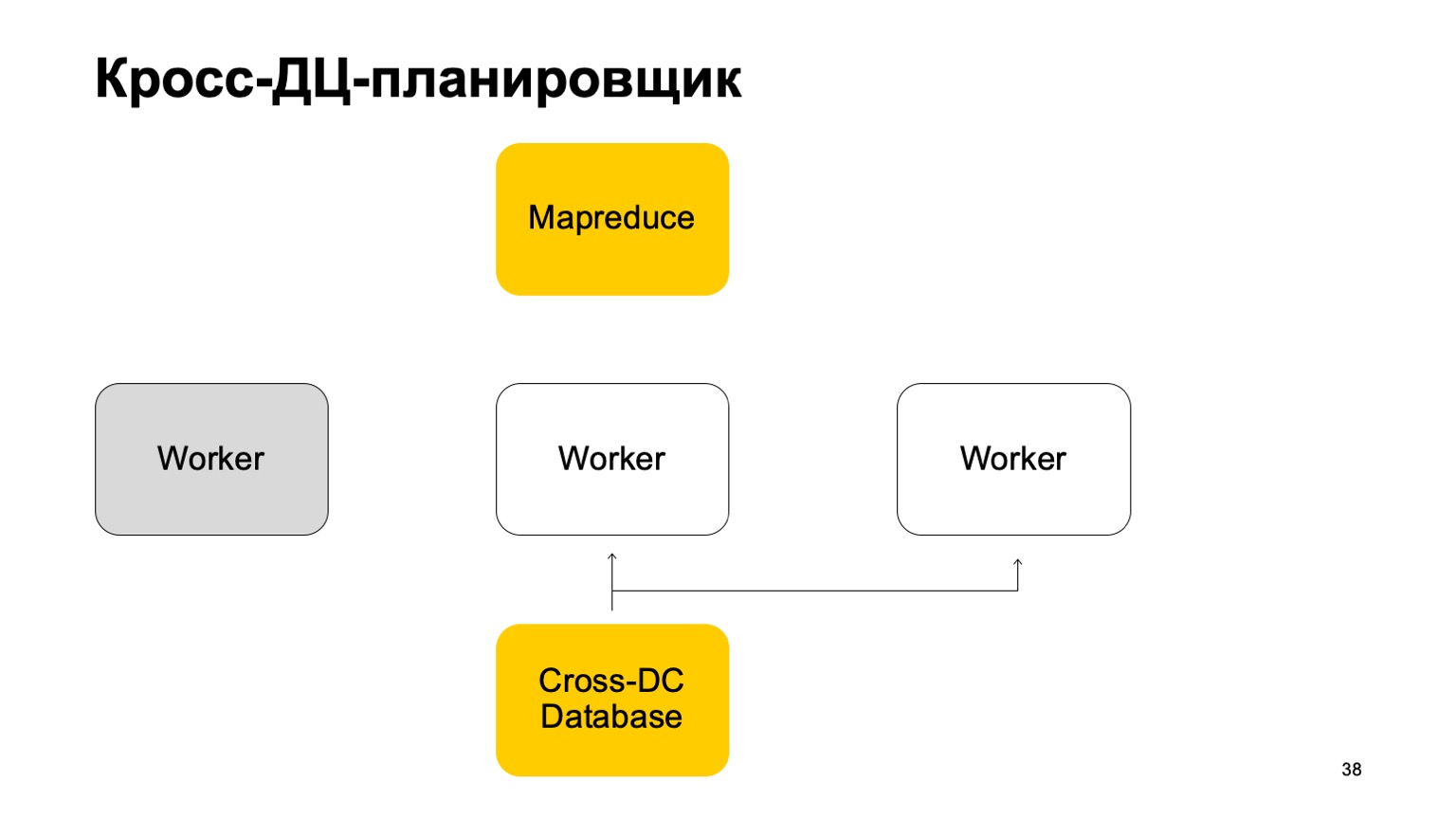
Levez-vous et continuez à travailler. Continuez à définir des tâches sur ce MapReduce.
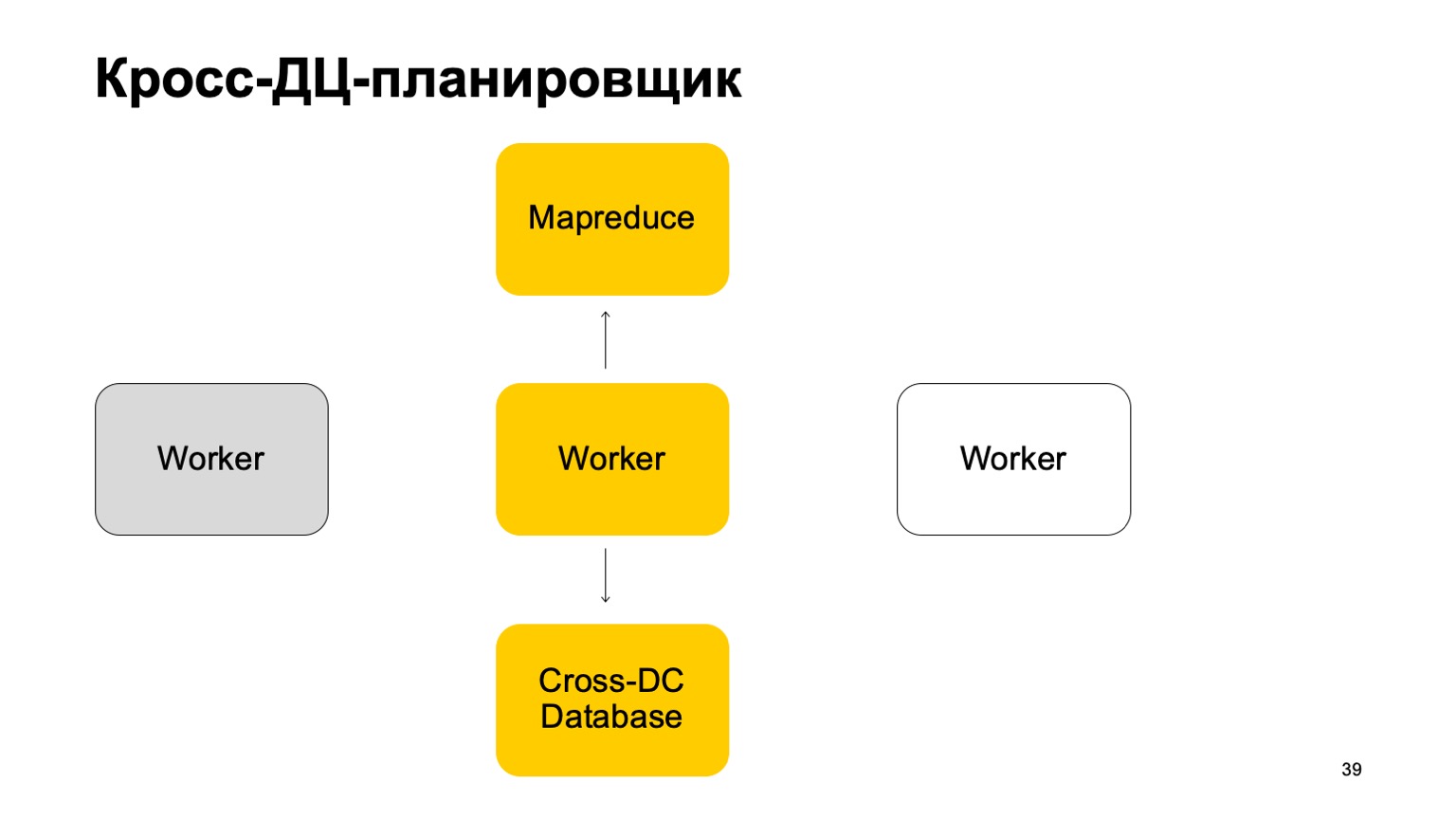
Il est clair qu'en cas de dépassement de ces tâches, certaines d'entre elles peuvent être redémarrées. Par conséquent, il y a une propriété très importante pour nous ici: l'idempotence, la possibilité de redémarrer chaque opération sans conséquences.
Autrement dit, tout le code doit être écrit de telle manière que cela fonctionne correctement.

Je vais vous dire un peu exactement une fois. Nous arrivons à un verdict de concert, c'est très important. Nous utilisons des technologies qui nous donnent de telles garanties et, bien entendu, nous surveillons tous les écarts, nous les réduisons à zéro. Même lorsqu'il semble que cela a déjà été réduit, de temps en temps, un problème très délicat se pose que nous n'avons pas pris en compte.
Instruments
Très brièvement sur les outils que nous utilisons. La maintenance de plusieurs antifraudes pour différents systèmes est une tâche difficile. Nous avons littéralement des dizaines de services différents, nous avons besoin d'une sorte de lieu unique où vous pouvez voir l'état de leur travail en ce moment.
Voici notre poste de commande, où vous pouvez voir l'état des clusters avec lesquels nous travaillons actuellement. Vous pouvez les basculer entre eux, déployer une version, etc.
Ou, par exemple, un tableau de bord des problèmes, où nous voyons immédiatement sur une seule page tous les problèmes de tous les antifraudes des différents services qui nous sont connectés. Ici, vous pouvez voir que quelque chose ne va clairement pas avec notre service de réservation pour le moment. Mais la surveillance fonctionnera et la personne de service l'examinera.
Que surveillons-nous du tout? De toute évidence, le retard du système est extrêmement important. Évidemment, la durée de chaque étape individuelle et, bien sûr, le filtrage des règles individuelles. C'est une exigence commerciale.
Des centaines de graphiques et de tableaux de bord apparaissent. Par exemple, sur ce tableau de bord, vous pouvez voir que le contour était suffisamment mauvais maintenant que nous avons un décalage important.
La vitesse
Je vais vous parler de la transition vers la partie en ligne. Le problème ici est que le décalage dans un circuit complet peut atteindre quelques minutes. C'est dans le contour sur MapReduce. Dans certains cas, nous devons bannir, détecter les fraudeurs plus rapidement.
Qu'est ce que ça pourrait être? Par exemple, notre service a désormais la possibilité d'acheter des livres. Et dans le même temps, un nouveau type de fraude de paiement est apparu. Vous devez y réagir plus rapidement. La question se pose - comment transférer tout ce schéma, en préservant idéalement autant que possible le langage d'interaction familier aux analystes? Essayons de le transférer "sur le front".
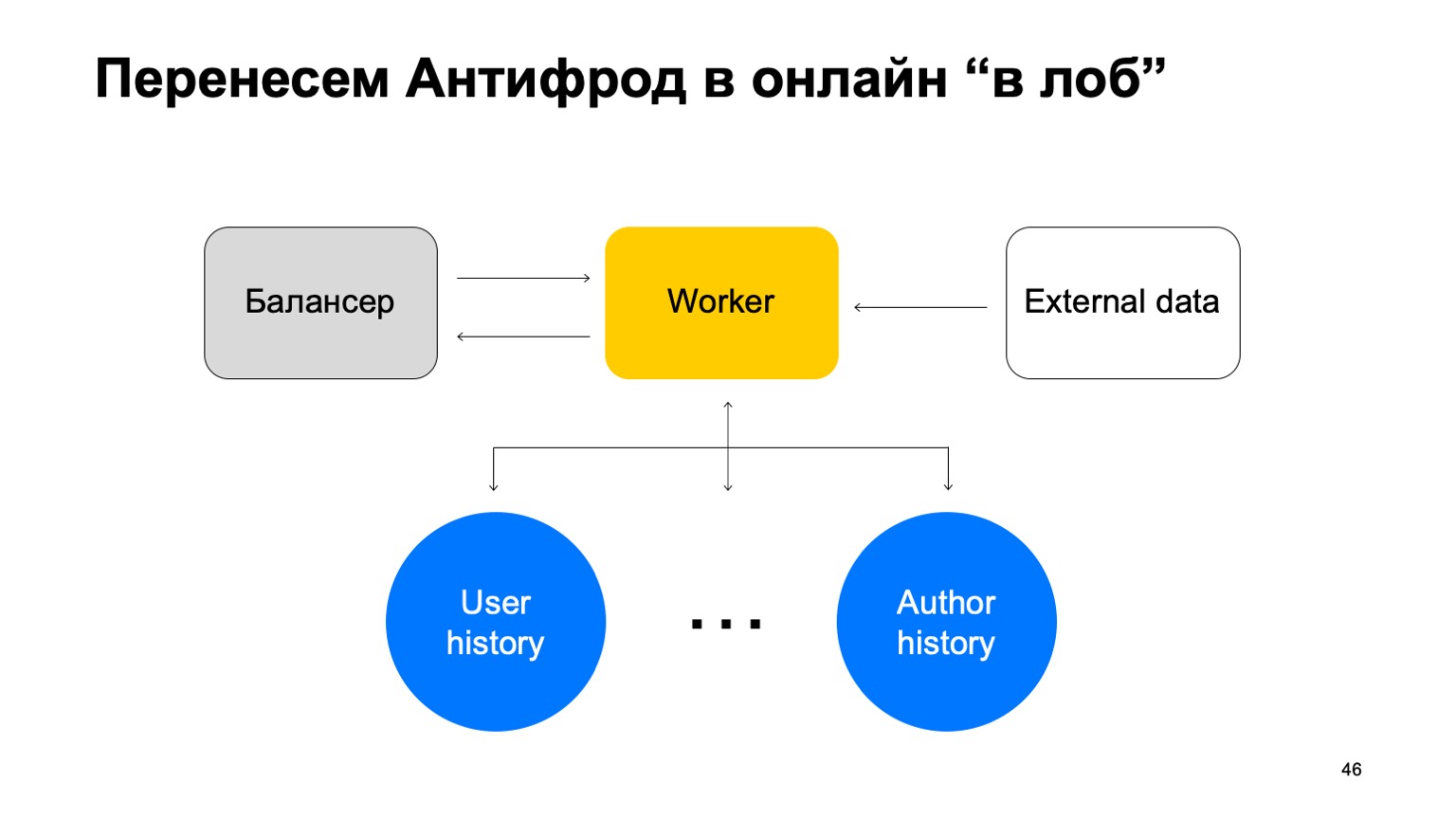
Supposons que nous ayons un équilibreur avec les données du service et un certain nombre de nœuds de calcul auxquels nous partageons les données de l'équilibreur. Il y a des données externes que nous utilisons ici, elles sont très importantes, et un ensemble de ces histoires. Permettez-moi de vous rappeler que chaque histoire est différente pour des réductions différentes, car elle a des clés différentes.
Dans un tel schéma, le problème suivant peut survenir.
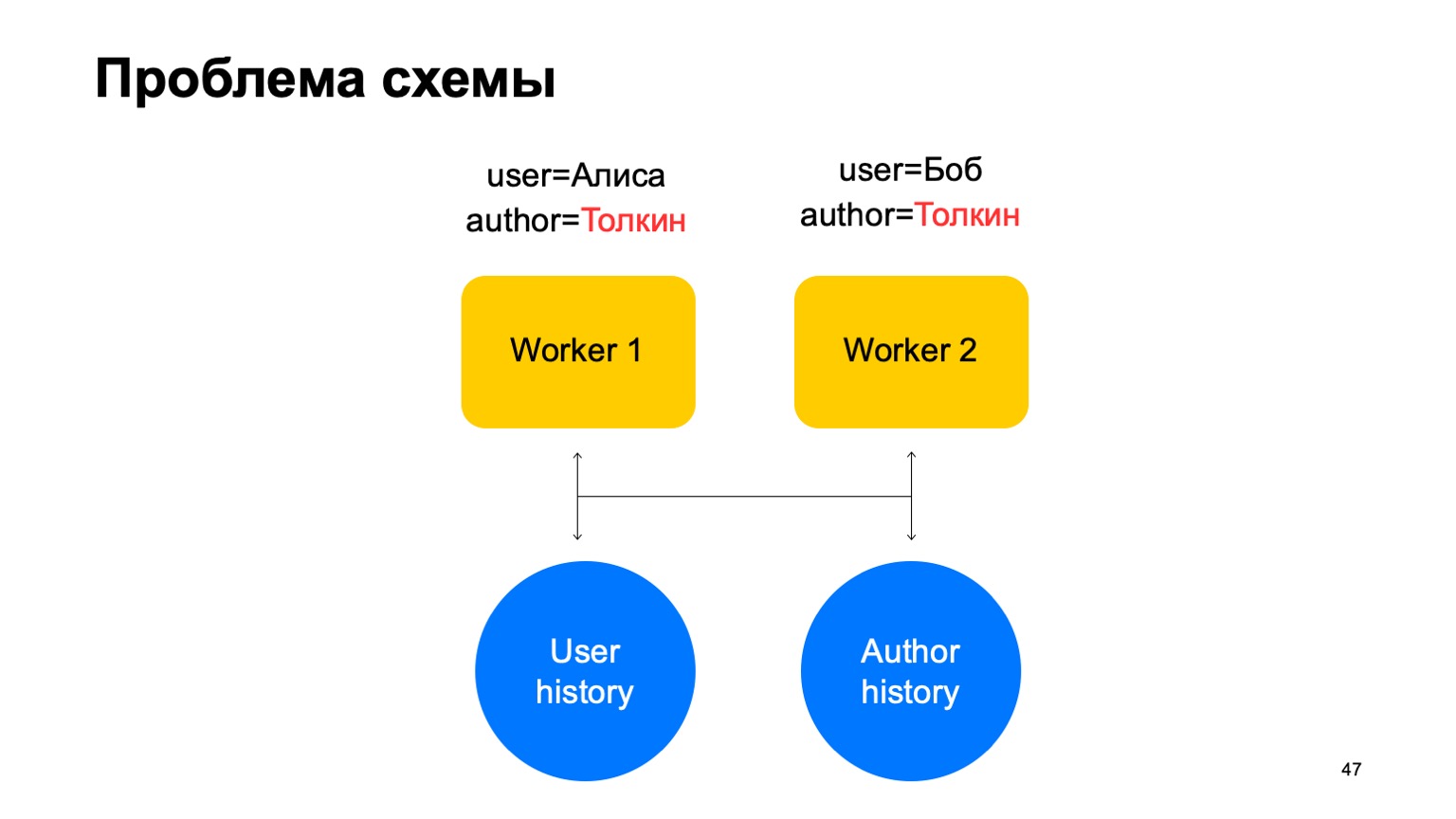
Disons que nous avons deux événements sur notre travailleur. Dans ce cas, avec tout partitionnement de ces travailleurs, une situation peut survenir lorsqu'une clé parvient à différents travailleurs. Dans ce cas, c'est l'auteur Tolkien, il est entré dans deux ouvriers.
Ensuite, nous lisons les données de ce stockage clé-valeur aux deux ouvriers de l'historique, nous les mettrons à jour différemment et une course se produira lorsque nous essaierons de réécrire.
Solution: Supposons que la lecture et l'écriture peuvent être séparées, que l'écriture peut avoir lieu avec un léger retard. Ce n'est généralement pas très important. Par un petit retard, je veux dire des unités de secondes ici. Ceci est important, en particulier, car notre implémentation de ce magasin clé-valeur prend plus de temps pour écrire les données que pour les lire.
Nous mettrons à jour les statistiques avec un décalage. En moyenne, cela fonctionne plus ou moins bien, étant donné que nous garderons l'état en cache sur les machines.
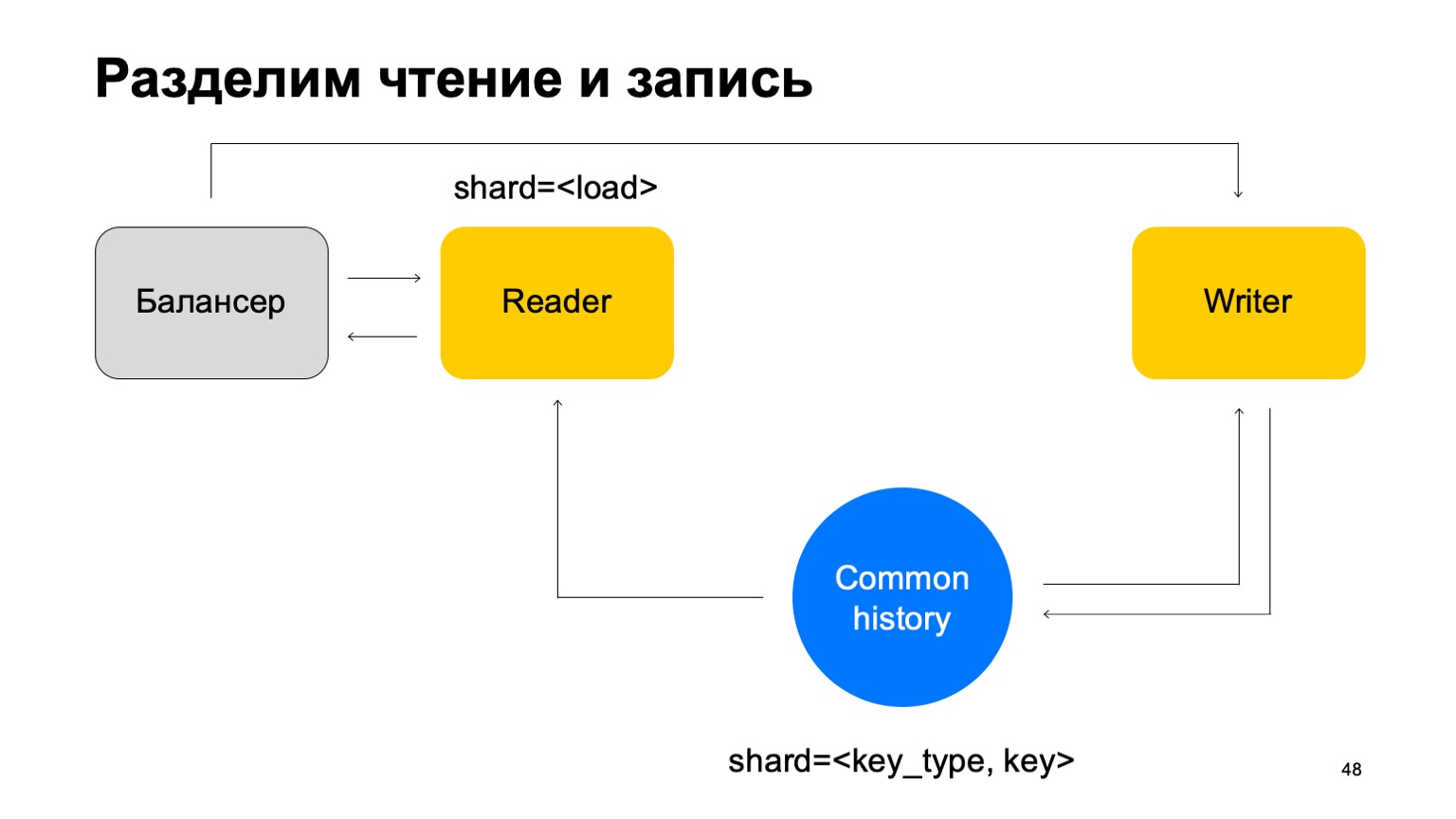
Et autre chose. Pour plus de simplicité, fusionnons ces histoires en une seule et notons-la par le type et la clé de la coupe. Nous avons une sorte d'histoire commune.
Ensuite, nous ajouterons à nouveau l'équilibreur, ajouterons les machines des lecteurs, qui peuvent être partitionnées de n'importe quelle manière - par exemple, simplement par chargement. Ils liront simplement ces données, accepteront les verdicts finaux et les renverront à l'équilibreur.
Dans ce cas, nous avons besoin d'un ensemble de machines d'écriture auxquelles ces données seront envoyées directement. Les écrivains mettront à jour l'histoire en conséquence. Mais ici, le problème se pose toujours, dont j'ai parlé ci-dessus. Changeons un peu la structure de l'écrivain.
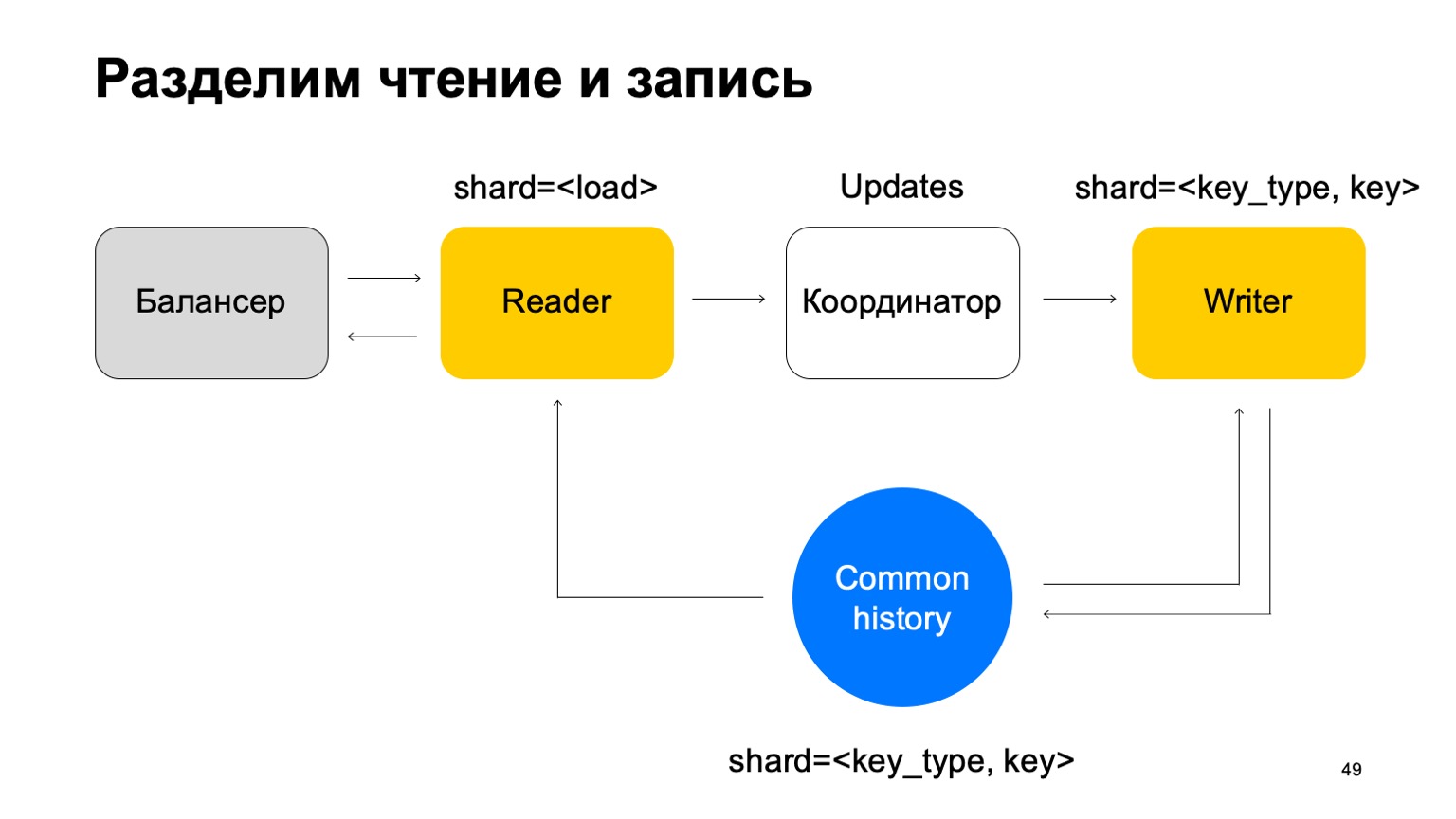
Nous allons faire en sorte qu'il soit partitionné de la même manière que l'historique - par le type et la valeur de la clé. Dans ce cas, lorsque son sharding est le même que l'histoire, nous n'aurons pas le problème que j'ai évoqué plus haut.
Ici, sa mission change. Il n'accepte plus les verdicts. Au lieu de cela, il accepte simplement les mises à jour du Reader, les mélange et les applique correctement à l'historique.
Il est clair qu'un composant est nécessaire ici, un coordinateur qui distribue ces mises à jour entre lecteurs et rédacteurs.
À cela, bien sûr, s'ajoute le fait que le travailleur doit maintenir un cache à jour. En conséquence, il s'avère que nous sommes responsables de centaines de millisecondes, parfois moins, et nous mettons à jour les statistiques en une seconde. En général, cela fonctionne bien, pour les services, cela suffit.

Qu'avons-nous obtenu du tout? Les analystes ont commencé à faire leur travail plus rapidement et de la même manière pour tous les services. Cela a amélioré la qualité et la connectivité de tous les systèmes. Vous pouvez réutiliser les données entre les anti-fraudes de différents services, et les nouveaux services obtiennent rapidement une anti-fraude de haute qualité.

Quelques réflexions à la fin. Si vous écrivez quelque chose comme ça, pensez immédiatement à la commodité des analystes en termes de support et d'extensibilité de ces systèmes. Rendez tout configurable, vous en avez besoin. Parfois, les propriétés cross-DC et exactement une fois sont difficiles à obtenir, mais elles le peuvent. Si vous pensez que vous l'avez déjà réalisé, revérifiez-le. Merci de votre attention.