Nous portons à votre attention la traduction d'une recherche intéressante de la société Crowdstrike. Le matériel est consacré à l'utilisation du langage Rust dans le domaine de la science des données (en relation avec l'analyse des logiciels malveillants) et montre comment Rust peut rivaliser dans un tel domaine même avec NumPy et SciPy, sans parler de Python pur .

Bonne lecture!
Python est l'un des langages de programmation de science des données les plus populaires, et pour une bonne raison. L'indice de package Python (PyPI) contient une tonne de bibliothèques de science des données impressionnantes telles que NumPy, SciPy, Natural Language Toolkit, Pandas et Matplotlib. Avec une abondance de bibliothèques d'analyse de haute qualité disponibles et une vaste communauté de développeurs, Python est le choix évident pour de nombreux scientifiques des données.
Beaucoup de ces bibliothèques sont implémentées en C et C ++ pour des raisons de performances, mais fournissent des interfaces de fonction externes (FFI) ou des liaisons Python afin que les fonctions puissent être appelées à partir de Python. Ces implémentations de langage de bas niveau sont destinées à atténuer certaines des lacunes les plus visibles de Python, en particulier en termes de temps d'exécution et de consommation de mémoire. Si vous pouvez limiter le temps d'exécution et la consommation de mémoire, l'évolutivité est considérablement simplifiée, ce qui est essentiel pour réduire les coûts. Si nous pouvons écrire du code haute performance qui résout les problèmes de science des données, alors l'intégration d'un tel code avec Python sera un avantage significatif.
Lorsque vous travaillez à l'intersection de la science des données et de l' analyse des logiciels malveillantsnon seulement une exécution rapide est requise, mais également une utilisation efficace des ressources partagées, encore une fois, pour la mise à l'échelle. La mise à l'échelle est l'un des problèmes clés du Big Data, comme la gestion efficace de millions d'exécutables sur plusieurs plates-formes. Obtenir de bonnes performances sur les processeurs modernes nécessite un parallélisme, généralement implémenté à l'aide du multithreading; mais il doit également améliorer l'efficacité de l'exécution du code et la consommation de mémoire. Lors de la résolution de tels problèmes, il peut être difficile d'équilibrer les ressources du système local, et il est encore plus difficile de mettre en œuvre correctement des systèmes multithreads. L'essence de C et C ++ est que la sécurité des threads n'est pas fournie. Oui, il existe des bibliothèques externes spécifiques aux plates-formes, mais garantir la sécurité des threads est évidemment le devoir du développeur.
L'analyse des logiciels malveillants est intrinsèquement dangereuse. Les logiciels malveillants manipulent souvent les structures de données au format de fichier de manière involontaire, paralysant ainsi les utilitaires d'analyse. Un écueil relativement courant qui nous attend en Python est le manque de bonne sécurité de type. Python, qui accepte généreusement les valeurs
Noneattendues à leur place bytearray, peut sombrer dans un chaos complet, ce qui ne peut être évité qu'en remplissant le code de vérifications None. De telles hypothèses de "typage de canard" conduisent souvent à des plantages.
Mais il y a Rust. Rust est positionné à bien des égards comme la solution idéale à tous les problèmes potentiels décrits ci-dessus: le temps d'exécution et la consommation de mémoire sont comparables à C et C ++, et une sécurité de type étendue est fournie. Rust fournit également des fonctionnalités supplémentaires, telles que de solides garanties de sécurité de la mémoire et aucune surcharge d'exécution. Comme il n'y a pas de tels frais généraux, il est plus facile d'intégrer du code Rust avec du code d'autres langages, en particulier Python. Dans cet article, nous allons faire un tour rapide de Rust pour voir s'il est digne du battage médiatique qui lui est associé.
Exemple d'application pour la science des données
La science des données est un domaine très vaste avec de nombreux aspects appliqués, et il est impossible de tous les discuter dans un seul article. Une tâche simple pour la science des données consiste à calculer l'entropie informationnelle pour les séquences d'octets. Une formule générale de calcul de l'entropie en bits est donnée sur Wikipédia :
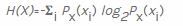
pour calculer l'entropie d'une variable aléatoire
X, nous comptons d'abord le nombre de fois où chaque valeur d'octet possible se produit 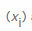 , puis divisons ce nombre par le nombre total d'éléments rencontrés pour calculer la probabilité de rencontrer une valeur spécifique
, puis divisons ce nombre par le nombre total d'éléments rencontrés pour calculer la probabilité de rencontrer une valeur spécifique 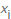 , respectivement
, respectivement 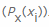 . Ensuite, nous comptons la valeur négative à partir de la somme pondérée des probabilités qu'une valeur particulière xi se produise , ainsi que les informations dites propres
. Ensuite, nous comptons la valeur négative à partir de la somme pondérée des probabilités qu'une valeur particulière xi se produise , ainsi que les informations dites propres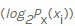 . Puisque nous calculons l'entropie en bits, elle est utilisée ici
. Puisque nous calculons l'entropie en bits, elle est utilisée ici 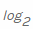 (notez la base 2 pour les bits).
(notez la base 2 pour les bits).
Essayons Rust et voyons comment il gère le calcul d'entropie par rapport au Python pur, ainsi que certaines des bibliothèques Python populaires mentionnées ci-dessus. Il s'agit d'une estimation simplifiée des performances potentielles de Rust en matière de science des données; cette expérience n'est pas une critique de Python ou des excellentes bibliothèques qu'il contient. Dans ces exemples, nous allons générer notre propre bibliothèque C à partir du code Rust que nous pouvons importer depuis Python. Tous les tests ont été exécutés sur Ubuntu 18.04.
Python pur
Commençons par une simple fonction Python pure (c
entropy.py) pour calculer l'entropie bytearray, en utilisant uniquement le module mathématique de la bibliothèque standard. Cette fonction n'est pas optimisée, prenons-la comme point de départ pour les modifications et les mesures de performances.
import math
def compute_entropy_pure_python(data):
"""Compute entropy on bytearray `data`."""
counts = [0] * 256
entropy = 0.0
length = len(data)
for byte in data:
counts[byte] += 1
for count in counts:
if count != 0:
probability = float(count) / length
entropy -= probability * math.log(probability, 2)
return entropy
Python avec NumPy et SciPy
Sans surprise, SciPy fournit une fonction de calcul d'entropie. Mais d'abord, nous utiliserons une fonction
unique()de NumPy pour calculer les fréquences d'octets. Comparer les performances de la fonction d'entropie SciPy avec d'autres implémentations est un peu injuste, car l'implémentation SciPy a des fonctionnalités supplémentaires pour calculer l'entropie relative (distance Kullback-Leibler). Encore une fois, nous allons faire un essai (espérons-le pas trop lent) pour voir quelles seront les performances des bibliothèques Rust compilées importées de Python. Nous nous en tiendrons à l'implémentation SciPy incluse dans notre script entropy.py.
import numpy as np
from scipy.stats import entropy as scipy_entropy
def compute_entropy_scipy_numpy(data):
""" bytearray `data` SciPy NumPy."""
counts = np.bincount(bytearray(data), minlength=256)
return scipy_entropy(counts, base=2)Python avec rouille
Ensuite, nous explorerons un peu plus notre implémentation Rust, par rapport aux implémentations précédentes, dans un souci de solidité et de solidité. Commençons par le package de bibliothèque par défaut généré avec Cargo. Les sections suivantes montrent comment nous avons modifié le package Rust.
cargo new --lib rust_entropy
Cargo.tomlNous commençons par un fichier manifeste obligatoire
Cargo.tomlqui définit le package Cargo et spécifie un nom de bibliothèque rust_entropy_lib. Nous utilisons le conteneur public cpython (v0.4.1) disponible sur crates.io, dans le registre de packages Rust. Pour cet article, nous utilisons Rust v1.42.0, la dernière version stable disponible au moment de la rédaction.
[package] name = "rust-entropy"
version = "0.1.0"
authors = ["Nobody <nobody@nowhere.com>"] edition = "2018"
[lib] name = "rust_entropy_lib"
crate-type = ["dylib"]
[dependencies.cpython] version = "0.4.1"
features = ["extension-module"]lib.rs
L'implémentation de la bibliothèque Rust est assez simple. Comme pour notre implémentation Python pure, nous initialisons le tableau de nombres pour chaque valeur d'octet possible et itérons sur les données pour remplir les nombres. Pour terminer l'opération, calculez et renvoyez la somme négative des probabilités multipliée par les
probabilités.
use cpython::{py_fn, py_module_initializer, PyResult, Python};
///
fn compute_entropy_pure_rust(data: &[u8]) -> f64 {
let mut counts = [0; 256];
let mut entropy = 0_f64;
let length = data.len() as f64;
// collect byte counts
for &byte in data.iter() {
counts[usize::from(byte)] += 1;
}
//
for &count in counts.iter() {
if count != 0 {
let probability = f64::from(count) / length;
entropy -= probability * probability.log2();
}
}
entropy
}
Il ne nous reste plus
lib.rsqu'un mécanisme pour appeler une fonction Rust pure depuis Python. Nous incluons dans lib.rsune (compute_entropy_cpython())fonction ajustée CPython pour appeler notre fonction Rust «pure» (compute_entropy_pure_rust()). Ce faisant, nous ne bénéficions que du maintien d'une seule implémentation Rust pure et de la fourniture d'un wrapper compatible CPython.
/// Rust CPython
fn compute_entropy_cpython(_: Python, data: &[u8]) -> PyResult<f64> {
let _gil = Python::acquire_gil();
let entropy = compute_entropy_pure_rust(data);
Ok(entropy)
}
// Python Rust CPython
py_module_initializer!(
librust_entropy_lib,
initlibrust_entropy_lib,
PyInit_rust_entropy_lib,
|py, m | {
m.add(py, "__doc__", "Entropy module implemented in Rust")?;
m.add(
py,
"compute_entropy_cpython",
py_fn!(py, compute_entropy_cpython(data: &[u8])
)
)?;
Ok(())
}
);Appel de code Rust depuis Python
Enfin, nous appelons l'implémentation Rust de Python (encore une fois, de
entropy.py). Pour ce faire, nous importons d'abord notre propre bibliothèque système dynamique compilée à partir de Rust. Ensuite, nous appelons simplement la fonction de bibliothèque fournie que nous avons précédemment spécifiée lors de l'initialisation du module Python à l'aide d'une macro py_module_initializer!dans notre code Rust. À ce stade, nous n'avons qu'un seul module Python ( entropy.py), qui comprend des fonctions pour appeler toutes les implémentations du calcul d'entropie.
import rust_entropy_lib
def compute_entropy_rust_from_python(data):
"" bytearray `data` Rust."""
return rust_entropy_lib.compute_entropy_cpython(data)Nous construisons le package de bibliothèque Rust ci-dessus sur Ubuntu 18.04 en utilisant Cargo. (Ce lien peut être utile pour les utilisateurs d'OS X).
cargo build --releaseUne fois l'assemblage terminé, nous renommons la bibliothèque résultante et la copions dans le répertoire où se trouvent nos modules Python, afin qu'elle puisse être importée à partir de scripts. La bibliothèque que vous avez créée avec Cargo est nommée
librust_entropy_lib.so, mais vous devez la renommer rust_entropy_lib.soafin de pouvoir importer avec succès pour ces tests.
Contrôle des performances: résultats
Nous avons mesuré les performances de chaque implémentation de fonction à l'aide de points d'arrêt pytest, en calculant l'entropie pour plus d'un million d'octets aléatoires. Toutes les implémentations sont affichées sur les mêmes données. Les benchmarks (également inclus dans entropy.py) sont indiqués ci-dessous.
# ### ###
# w/ NumPy
NUM = 1000000
VAL = np.random.randint(0, 256, size=(NUM, ), dtype=np.uint8)
def test_pure_python(benchmark):
""" Python."""
benchmark(compute_entropy_pure_python, VAL)
def test_python_scipy_numpy(benchmark):
""" Python SciPy."""
benchmark(compute_entropy_scipy_numpy, VAL)
def test_rust(benchmark):
""" Rust, Python."""
benchmark(compute_entropy_rust_from_python, VAL)Enfin, nous créons des scripts de pilote simples séparés pour chaque méthode nécessaire pour calculer l'entropie. Vient ensuite un script de pilote représentatif pour tester l'implémentation pure de Python. Le fichier contient
testdata.bin1 000 000 octets aléatoires utilisés pour tester toutes les méthodes. Chaque méthode répète le calcul 100 fois pour faciliter la capture des données d'utilisation de la mémoire.
import entropy
with open('testdata.bin', 'rb') as f:
DATA = f.read()
for _ in range(100):
entropy.compute_entropy_pure_python(DATA)Les implémentations pour SciPy / NumPy et Rust ont montré de bonnes performances, battant facilement l'implémentation Python pure non optimisée de plus de 100 fois. La version Rust ne fonctionnait que légèrement mieux que la version SciPy / NumPy, mais les résultats ont confirmé nos attentes: le Python pur est beaucoup plus lent que les langages compilés, et les extensions écrites en Rust peuvent rivaliser avec succès avec leurs homologues C (les battant même dans de tels microtest).
Il existe également d'autres méthodes pour améliorer la productivité. Nous pourrions utiliser des modules
ctypesou cffi. Vous pouvez ajouter des indices de type et utiliser Cython pour générer une bibliothèque que vous pouvez importer depuis Python. Toutes ces options nécessitent des compromis spécifiques à la solution.

Nous avons également mesuré l'utilisation de la mémoire pour chaque implémentation de fonctionnalité à l'aide de l'application GNU
time(à ne pas confondre avec la commande shell intégrée time). En particulier, nous avons mesuré la taille maximale de l'ensemble des résidents.
Alors que dans les implémentations pures Python et Rust, les tailles maximales pour cette partie sont assez similaires, l'implémentation SciPy / NumPy consomme beaucoup plus de mémoire pour ce benchmark. Cela est probablement dû à des fonctionnalités supplémentaires chargées en mémoire lors de l'importation. Quoi qu'il en soit, l'appel de code Rust à partir de Python ne semble pas introduire de surcharge mémoire importante.

Résultat
Nous sommes extrêmement impressionnés par les performances que nous obtenons en appelant Rust depuis Python. Dans notre évaluation franchement brève, l'implémentation de Rust a pu rivaliser en termes de performances avec l'implémentation de base C des packages SciPy et NumPy. La rouille semble être idéale pour un traitement efficace à grande échelle.
Rust a montré non seulement d'excellents temps d'exécution; Il convient de noter que la surcharge de mémoire dans ces tests était également minime. Ces caractéristiques d'exécution et d'utilisation de la mémoire semblent idéales à des fins d'évolutivité. Les performances des implémentations FFI SciPy et NumPy C sont certainement comparables, mais avec Rust nous obtenons des avantages supplémentaires que C et C ++ ne nous donnent pas. Les garanties de sécurité de la mémoire et de sécurité des fils sont un avantage très intéressant.
Alors que C fournit un temps d'exécution comparable à Rust, C lui-même ne fournit pas de sécurité des threads. Il existe des bibliothèques externes qui fournissent cette fonctionnalité pour C, mais il est de la responsabilité du développeur de s'assurer qu'elles sont utilisées correctement. Rust surveille les problèmes de sécurité des threads tels que les courses au moment de la compilation - grâce à son modèle de propriété - et la bibliothèque standard fournit une suite de mécanismes de concurrence, y compris des tuyaux, des verrous et des pointeurs intelligents comptés par référence.
Nous ne préconisons pas de porter SciPy ou NumPy sur Rust, car ces bibliothèques Python sont déjà bien optimisées et prises en charge par des communautés de développeurs sympas. D'un autre côté, nous vous recommandons fortement de porter du code de Python pur vers Rust qui n'est pas fourni dans les bibliothèques hautes performances. Dans le contexte des applications de science des données utilisées pour l'analyse de la sécurité, Rust apparaît comme une alternative compétitive à Python, compte tenu de sa rapidité et de ses garanties de sécurité.