Aujourd'hui, je veux parler d'autre chose - de quelque chose qui n'appartient en aucun cas aux meilleures pratiques, à l'aide desquelles il est très facile de se tirer une balle dans le pied et de ralentir une requête précédemment exécutée, ou de ne plus s'exécuter du tout en raison d'une erreur ... Il s'agit de conseils et de guides de planification.
Les astuces sont des astuces pour l'optimiseur de requêtes, une liste complète peut être trouvée sur MSDN . Certains d'entre eux sont vraiment des indices (par exemple, vous pouvez spécifier OPTION (MAXDOP 4)) afin que la requête puisse être exécutée avec un degré de parallélisme maximal = 4, mais il n'y a aucune garantie que SQL Server générera un plan parallèle avec cet indice.
L'autre partie est un guide direct pour l'action. Par exemple, si vous écrivez OPTION (HASH JOIN), SQL Server crée un plan sans NESTED LOOPS et MERGE JOINs. Et vous savez ce qui se passera s'il s'avère qu'il est impossible de créer un plan avec uniquement des jointures de hachage? L'optimiseur le dira - je ne peux pas créer de plan et la requête ne sera pas exécutée.
Le problème est qu'on ne sait pas avec certitude (du moins pour moi) quels indices sont des indices que l'optimiseur peut percuter; et quelles astuces sont des astuces manuelles qui peuvent provoquer le blocage de la requête en cas de problème. Il existe sûrement déjà une collection prête à l'emploi où cela est décrit, mais ce n'est en aucun cas une information officielle et peut changer à tout moment.
Plan Guide est une chose telle (que je ne sais pas traduire correctement) qui vous permet de lier un ensemble spécifique d'indices à une demande spécifique, dont vous connaissez le texte. Cela peut être pertinent si vous ne pouvez pas influencer directement le texte de requête généré par l'ORM, par exemple.
Les conseils et les guides de plan ne sont en aucun cas les meilleures pratiques, il est préférable d'omettre les conseils et ces guides, car la distribution des données peut changer, les types de données peuvent changer et un million de choses supplémentaires peuvent se produire, ce qui fait que vos requêtes avec des indices fonctionneront moins bien que sans eux, et dans certains cas, elles cesseront complètement de fonctionner. Vous devez être conscient à cent pour cent de ce que vous faites et pourquoi.
Maintenant, une petite explication de pourquoi je suis même entré dans cela.
J'ai une large table avec un tas de champs nvarchar de différentes tailles - de 10 à max. Et il y a un tas de requêtes dans cette table, que CHARINDEX recherche des occurrences de sous-chaînes dans une ou plusieurs de ces colonnes. Par exemple, il y a une demande qui ressemble à ceci:
SELECT *
FROM table
WHERE CHARINDEX(N' ', column)>1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET x ROWS FETCH NEXT y ROWS ONLYLa table a un index clusterisé sur l'ID et un index non groupé non unique sur la colonne. Comme vous le comprenez vous-même, tout cela n'a aucun sens, car dans WHERE nous utilisons CHARINDEX, ce qui n'est certainement pas SARGable. Pour éviter d'éventuels problèmes avec le SB, je vais simuler cette situation sur la base de données ouverte StackOverflow2013, que vous trouverez ici .
Considérez la table dbo.Posts, qui n'a qu'un index clusterisé par ID et une requête comme celle-ci:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYPour correspondre à ma base de données réelle, je crée un index sur la colonne Titre:
CREATE INDEX ix_Title ON dbo.Posts (Title);En conséquence, bien sûr, nous obtenons un plan d'exécution absolument logique, qui consiste à balayer l'index clusterisé dans la direction opposée:
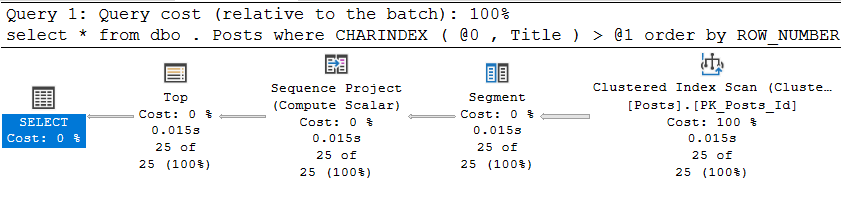

Et il est, certes, assez bien exécuté:
Tableau 'Messages'. Nombre de scans 1, lectures logiques 516, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Temps d'exécution de SQL Server:
temps CPU = 16 ms
Mais que se passe-t-il si, au lieu du mot commun «Données», nous recherchons quelque chose de plus rare? Par exemple, N'Aptana '(aucune idée de ce que c'est). Le plan, bien sûr, restera le même, mais les statistiques d'exécution, hum, changeront quelque peu:
Tableau 'Messages'. Nombre de scans 1, lectures logiques 253191, lectures physiques 113, lectures anticipées 224602, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Temps d'exécution de SQL Server:
temps CPU = 2563 ms
Et c'est aussi logique - le mot est beaucoup moins courant et SQL Server doit analyser beaucoup plus de données pour trouver 25 lignes avec lui. Mais d'une manière ou d'une autre, ce n'est pas cool, non?
Et je créais un index non clusterisé. Ce serait peut-être mieux si SQL Server l'utilise? Lui-même ne l'utilisera pas, alors j'ajoute un indice:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Title)));Et quelque chose est en quelque sorte complètement triste. Statistiques d'exécution:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Posts'. Scan count 5, logical reads 109312, physical reads 5, read-ahead reads 104946, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 35031 ms
et le plan:

maintenant, le plan d'exécution est parallèle et il a deux sortes, les deux avec des déversements dans tempdb. À propos, faites attention au premier tri, qui est effectué après une analyse d'index non clusterisée, avant la recherche de clé - il s'agit d'une optimisation SQL Server spéciale qui tente de réduire le nombre d'E / S aléatoires - les recherches de clés sont effectuées dans l'ordre croissant de la clé d'index cluster. Vous pouvez en savoir plus ici .
Le deuxième tri est nécessaire pour sélectionner 25 lignes dans l'ordre décroissant Id. À propos, SQL Server pourrait deviner qu'il devra trier à nouveau par Id, uniquement dans l'ordre décroissant et effectuer des recherches de clé dans le sens «opposé», en triant par ordre décroissant, et non croissant, de la clé d'index cluster au début.
Je ne fournis pas de statistiques sur l'exécution d'une requête avec un indice sur un index non clusterisé avec une recherche par l'entrée «Données». Sur mon disque dur à moitié mort dans un ordinateur portable, cela a pris plus de 16 minutes et je n'ai pas pensé à prendre une capture d'écran. Désolé, je ne veux plus attendre aussi longtemps.
Mais qu'en est-il de la demande? Une analyse d'index groupé est-elle le rêve ultime et vous ne pouvez rien faire plus rapidement?
Et si j'essayais d'éviter toutes sortes, j'ai pensé et créé un index non clusterisé, qui, en général, contredit ce qui est généralement considéré comme les meilleures pratiques pour les index non clusterisés:
CREATE INDEX ix_Id_Title ON dbo.Posts (Id DESC, Title);Maintenant, nous utilisons l'indication pour dire à SQL Server de l'utiliser:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Id_Title)));Oh, ça a bien fonctionné:

Tableau 'Messages'. Nombre de scans 1, lectures logiques 6259, lectures physiques 0, lectures anticipées 7816, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Temps d'exécution de SQL Server:
temps CPU = 1734 ms
Le gain de temps processeur n'est pas grand, mais il faut lire beaucoup moins - pas mal. Qu'en est-il des «données» fréquentes?
Tableau 'Messages'. Nombre de scans 1, lectures logiques 208, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Temps d'exécution de SQL Server:
temps CPU = 0 ms
Wow, c'est bien aussi. Maintenant, puisque la requête provient de l'ORM et que nous ne pouvons pas modifier son texte, nous devons trouver comment «clouer» cet index à la requête. Et le guide du plan vient à la rescousse.
La procédure stockée sp_create_plan_guide ( MSDN ) est utilisée pour créer un guide de plan .
Considérons-le en détail:
sp_create_plan_guide [ @name = ] N'plan_guide_name'
, [ @stmt = ] N'statement_text'
, [ @type = ] N'{ OBJECT | SQL | TEMPLATE }'
, [ @module_or_batch = ]
{
N'[ schema_name. ] object_name'
| N'batch_text'
| NULL
}
, [ @params = ] { N'@parameter_name data_type [ ,...n ]' | NULL }
, [ @hints = ] {
N'OPTION ( query_hint [ ,...n ] )'
| N'XML_showplan'
| NULL
} Nom - nom de guide de plan clair et unique
stmt- c'est la demande à laquelle vous devez ajouter l'indication. Il est important de savoir ici que cette demande doit être écrite EXACTEMENT de la même manière que la demande qui provient de l'application. Un espace étrange? Le guide du plan ne sera pas utilisé. Mauvais saut de ligne? Le guide du plan ne sera pas utilisé. Pour vous faciliter les choses, il y a un "life hack" sur lequel je reviendrai un peu plus tard (et que j'ai trouvé ici ).
type - indique où la demande spécifiée dans stmt. S'il fait partie d'une procédure stockée, il doit être OBJECT; si cela fait partie d'un lot de plusieurs requêtes, ou d'une requête ad hoc, ou d'un lot d'une requête, il devrait y avoir SQL. Si TEMPLATE est indiqué ici, il s'agit d'une histoire distincte sur le paramétrage des requêtes, que vous pouvez lire sur MSDN .
@module_or_batch dépend detype. Si untype= 'OBJECT', cela doit être le nom de la procédure stockée. Si untype= 'BATCH' - il devrait y avoir le texte du lot entier, spécifié mot à mot avec ce qui provient des applications. Un espace étrange? Eh bien, vous le savez déjà. S'il est NULL, alors nous considérons qu'il s'agit d'un lot d'une requête et qu'il correspond à ce qui est spécifié dansstmt avec toutes les restrictions.
paramètres- tous les paramètres passés à la demande avec les types de données doivent être répertoriés ici.
@hints est enfin la partie la plus intéressante, ici vous devez spécifier les astuces à ajouter à la requête. Ici, vous pouvez insérer explicitement le plan d'exécution requis au format XML, le cas échéant. Ce paramètre peut également être NULL, ce qui entraînera le fait que SQL Server n'utilisera pas les conseils qui sont explicitement spécifiés dans la requête dansstmt.
Nous créons donc un guide de plan pour la requête:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N''Data'', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY';
exec sp_create_plan_guide @name = N'PG_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = NULL
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'Et nous essayons d'exécuter la requête:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYWow, cela a fonctionné:
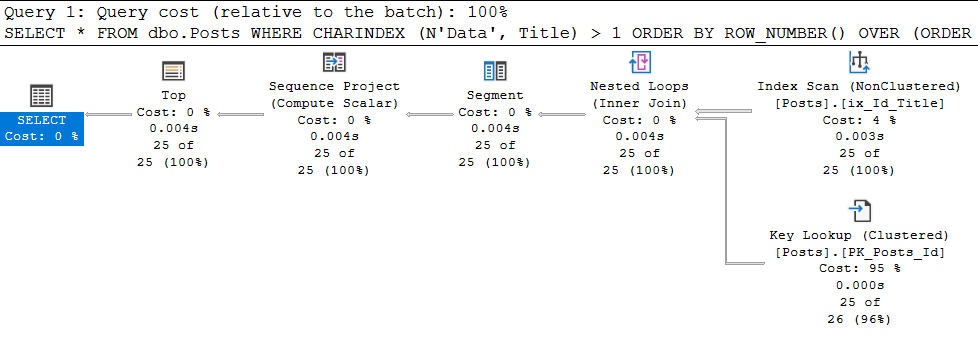
dans les propriétés de la dernière instruction SELECT, nous voyons:

Super, le plan giude a été appliqué. Et si vous recherchez «Aptana» maintenant? Et tout ira mal - nous reviendrons à nouveau sur l'analyse de l'index cluster avec toutes les conséquences. Pourquoi? Et parce que, le guide de plan est appliqué à une requête SPÉCIFIQUE, dont le texte coïncide un à un avec celui en cours d'exécution.
Heureusement pour moi, la plupart des requêtes sur mon système sont paramétrées. Je n’ai pas travaillé avec des requêtes non paramétrées et j’espère que je n’ai pas à le faire. Pour eux, vous pouvez utiliser des modèles (voir un peu plus haut sur TEMPLATE), vous pouvez activer PARAMETERISATION FORCÉE dans la base de données ( ne faites pas cela sans comprendre ce que vous faites !!! ) et, peut-être, après cela, vous pourrez lier le Guide du plan. Mais je n'ai vraiment pas essayé.
Dans mon cas, la requête est exécutée dans quelque chose comme ceci:
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Aptana', @p1 = 0, @p2 = 25;Par conséquent, je crée un guide de plan correspondant:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;';
exec sp_create_plan_guide @name = N'PG_paramters_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = N'@p0 nvarchar(250), @p1 int, @p2 int'
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'Et, hourra, tout fonctionne comme prévu:
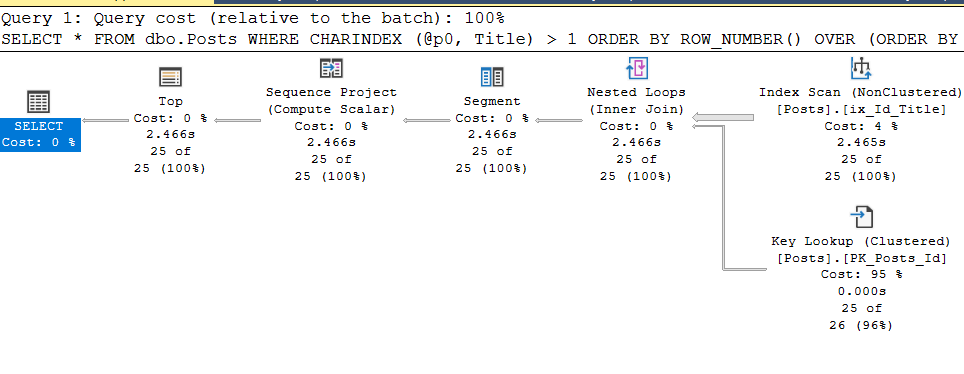

étant en dehors des conditions de la serre, il n'est pas toujours possible de spécifier correctement le paramètrestmtpour joindre un guide de plan à une demande, et pour cela il y a un "hack de vie" que j'ai mentionné ci-dessus. Nous effaçons le cache du plan, supprimons les guides, exécutons à nouveau la requête paramétrée et récupérons son plan d'exécution et son plan_handle du cache.
Une demande pour cela peut être utilisée, par exemple, comme ceci:
SELECT qs.plan_handle, st.text, qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text (qs.sql_handle) st
CROSS APPLY sys.dm_exec_query_plan (qs.plan_handle) qp
Nous pouvons maintenant utiliser la procédure stockée sp_create_plan_guide_from_handle pour créer un guide de plan à partir d'un plan existant.
Il prend comme paramètresNom- le nom du guide créé, @plan_handle - le handle du plan d'exécution existant et @statement_start_offset - qui définit le début de l'instruction dans le batch pour lequel le guide doit être créé.
En essayant:
exec sp_create_plan_guide_from_handle N'PG_dboPosts_from_handle'
, 0x0600050018263314F048E3652102000001000000000000000000000000000000000000000000000000000000
, NULL;Et maintenant, dans SSMS, nous regardons ce que nous avons dans Programmabilité -> Guides de plan:

maintenant, le plan d'exécution actuel a été "cloué" à notre demande en utilisant le guide de plan 'PG_dboPosts_from_handle', mais, mieux encore, maintenant, comme presque n'importe quel objet dans SSMS, nous pouvons créer des scripts et recréer comme nous en avons besoin.
RMB, Script -> Drop AND Create et nous obtenons un script prêt à l'emploi dans lequel nous devons remplacer la valeur du paramètre @hints par celle dont nous avons besoin, donc nous obtenons:
USE [StackOverflow2013]
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_control_plan_guide @operation = N'DROP', @name = N'[PG_dboPosts_from_handle]'
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_create_plan_guide @name = N'[PG_dboPosts_from_handle]', @stmt = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY', @type = N'SQL', @module_or_batch = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;',
@params = N'@p0 nvarchar(250), @p1 int, @p2 int',
@hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'
GONous exécutons et réexécutons la demande. Hourra, tout fonctionne:

si vous remplacez la valeur du paramètre, tout fonctionne de la même manière.
Veuillez noter qu'un seul guide peut correspondre à une déclaration. Si vous essayez d'ajouter un autre guide à la même instruction, vous recevrez un message d'erreur.
Msg 10502, niveau 16, état 1, ligne 1
Impossible de créer le guide de plan 'PG_dboPosts_from_handle2' car l'instruction spécifiée parstmtet @module_or_batch, ou par @plan_handle et @statement_start_offset, correspond au guide de plan existant 'PG_dboPosts_from_handle' dans la base de données. Supprimez le guide de plan existant avant de créer le nouveau guide de plan.
La dernière chose que je voudrais mentionner est la procédure stockée sp_control_plan_guide .
Avec son aide, vous pouvez supprimer, désactiver et activer les guides de plan - les deux un à la fois, en indiquant le nom, et tous les guides (je ne sais pas - tout du tout. Ou tout dans le contexte de la base de données dans laquelle la procédure est exécutée) - les valeurs sont utilisées pour cela @ paramètre d'opération - DROP ALL, DISABLE ALL, ENABLE ALL. Un exemple d'utilisation de HP pour un plan spécifique est donné juste au-dessus - un guide de plan spécifique avec le nom spécifié est supprimé.
Était-il possible de se passer d'indices et de guide de plan?
En général, s'il vous semble que l'optimiseur de requêtes est stupide et fait une sorte de jeu, et que vous savez comment faire, avec une probabilité de 99%, vous faites une sorte de jeu (comme dans mon cas). Cependant, dans le cas où vous n'avez pas la possibilité d'influencer directement le texte de la demande, un guide de plan qui vous permet d'ajouter un indice à la demande peut vous sauver la vie. Supposons que nous ayons la possibilité de réécrire le texte de la requête selon nos besoins - cela peut-il changer quelque chose? Sûr! Même sans l'utilisation du terme "exotique" sous forme de recherche plein texte, qui, en fait, devrait être utilisé ici. Par exemple, une telle requête a un plan et des statistiques d'exécution complètement normaux (pour une requête):
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Tableau 'Messages'. Nombre de scans 1, lectures logiques 6250, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Temps d'exécution de SQL Server:
temps CPU = 1500 ms
SQL Server trouve d'abord les 25 identificateurs requis par l'index «tordu» ix_Id_Title, et ensuite seulement fait une recherche dans l'index cluster pour les identificateurs sélectionnés - encore mieux qu'avec le guide! Mais que se passe-t-il si nous exécutons une requête sur 'Données' et affichons 25 lignes, à partir de la 20 000ème ligne:
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 20000 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Tableau 'Messages'. Nombre de scans 1, lectures logiques 5914, lectures physiques 0, lectures anticipées 0, lectures logiques lob 11, lectures physiques lob 0, lectures anticipées lob 0.
Temps d'exécution de SQL Server:
temps CPU = 1453 ms
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Data', @p1 = 20000, @p2 = 25;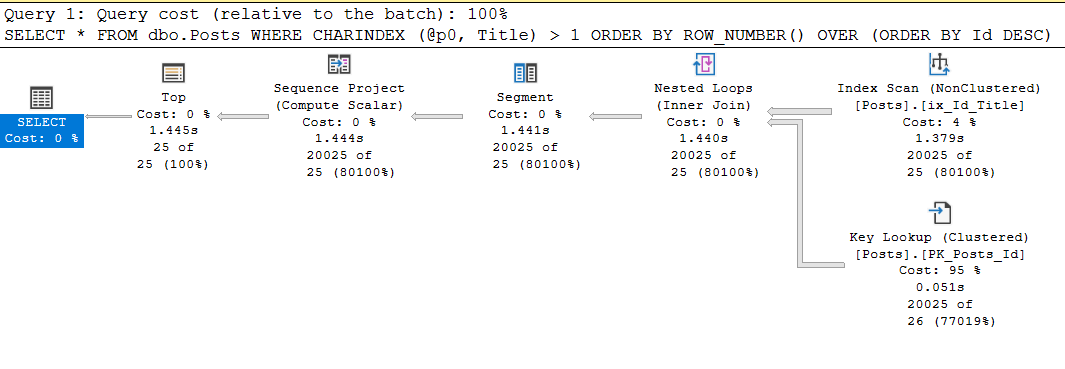
Table 'Posts'. Scan count 1, logical reads 87174, physical reads 0, read-ahead reads 0, lob logical reads 11, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1437 ms
Oui, le temps processeur est le même, car il est passé sur charindex, mais la requête avec le guide fait un ordre de grandeur plus de lectures, et cela peut devenir un problème.
Permettez-moi de résumer le résultat final. Les conseils et les guides peuvent vous aider beaucoup ici et maintenant, mais ils peuvent facilement aggraver les choses. Si vous spécifiez explicitement un indice avec un index dans le texte de la demande, puis supprimez l'index, la requête ne peut tout simplement pas être exécutée. Sur mon SQL Server 2017, la requête avec le guide, après la suppression de l'index, est exécutée correctement - le guide est ignoré, mais je ne peux pas être sûr qu'il en sera toujours ainsi et dans toutes les versions de SQL Server.
Il n'y a pas beaucoup d'informations sur le guide du plan en russe, j'ai donc décidé de l'écrire moi-même. Vous pouvez lire icisur les limitations dans l'utilisation des guides de plan, en particulier sur le fait que parfois une indication explicite de l'index avec un indice utilisant PG peut conduire au fait que les demandes tomberont. Je souhaite que vous ne les utilisiez jamais, et si vous devez - eh bien, bonne chance - vous savez où cela peut mener.