Conditions préalables
La tâche de recherche d'une phrase dans un texte paginé se réduit à calculer le coefficient de pertinence pour chacune des pages puis à trier la liste par ordre décroissant du coefficient.
Dans le processus de calcul selon l'approche de base, chaque page est soumise à une analyse symbole par symbole, et c'est là que réside la possibilité d'optimisation.

Lors du calcul du coefficient, les groupes de caractères correspondants des chaînes de recherche et des données sont analysés, tandis que les groupes ne peuvent être formés que dans des mots. En revanche, compte tenu du problème de la surestimation de l’importance des mots «longs» (dans la deuxième partie ), comme solution possible, il a été proposé de « calculer la pertinence d’une expression de recherche en tant que moyenne de la pertinence des mots qu’il contient, calculée indépendamment ». L'utilisation d'un index produira un résultat équivalent à cette approche particulière.
Indice
L'idée de l'indexation n'est pas nouvelle et est la suivante - en raison du fait que les mots dans le texte sont répétés, la quantité de calculs peut être réduite. Pour ce faire, le texte dans lequel la recherche sera effectuée doit d'abord générer un index. Dans le cas le plus simple, l' index est un tableau de tous les mots du texte, qui, en plus des mots, contient des données sur les pages sur lesquelles ils apparaissent. Fragment du tableau d'index basé sur le texte du roman de L.N. "Guerre et paix" de Tolstoï (au total, il contient environ 50 000 mots), est illustré dans la figure.

Directement dans le processus de traitement d'une demande, la chaîne de recherche est d'abord divisée en mots. En outre, pour chacun des mots de la chaîne de recherche, la pertinence est calculée avec chacun des mots de l' index . Les résultats du calcul sont cumulés danstableau des résultats préliminaires contenant les colonnes "Mot de la chaîne de recherche", "Mot d'index", "Facteur de pertinence", "Numéro de page". Le tableau contient uniquement les lignes de l'index, le coefficient de pertinence pour lequel les mots ont dépassé le seuil spécifié. Autrement dit, chaque ligne de l'index avec un mot correspondant génère des lignes dans la table de résultats préliminaires égaux au nombre de pages de texte sur lesquelles ce mot apparaît. Vous trouverez ci-dessous un extrait du tableau des résultats préliminaires de la recherche de l'expression "Soirée chez Anna Pavlovna Sherer".

Ensuite, le tableau des résultats préliminaires est trié par colonnes Numéro de page , Mot de chaîne de recherche , Facteur(descendant).

En parcourant les lignes du tableau trié, pour chacune des pages et pour chaque mot de la chaîne de recherche, le mot le plus pertinent de cette page est identifié - grâce au tri décrit ci-dessus, c'est le premier mot pour chaque combinaison Numéro de page - Mot de la chaîne de recherche . Les autres lignes sont supprimées par combinaison.
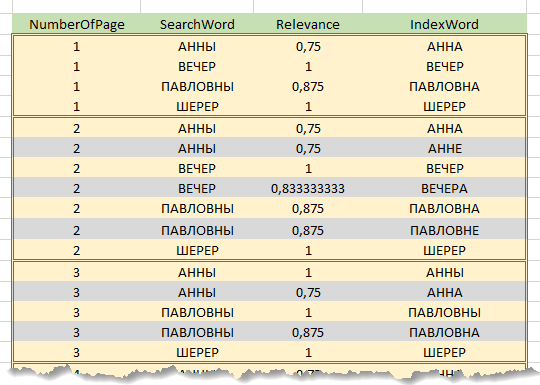
Ainsi, pour chaque page de texte incluse dans le tableau des résultats préliminaires , pour chaque mot de la chaîne de recherche, on trouvera les mots les plus pertinents de cette page avec les coefficients correspondants. La somme des coefficients de mots trouvés sur la page, rapportée au nombre de mots dans la barre de recherche, donnera le coefficient de pertinence pour la page.

Par exemple, sur la figure ci-dessus, la recherche est effectuée par la ligne «Soirée chez Anna Pavlovna Sherer» (la préposition «y» n'est pas prise en compte), les lignes surlignées en gris sont supprimées lors du contournement. Le coefficient de pertinence pour la page 1 sera (0,75 + 1 + 0,875 + 1) / 4 = 0,906, pour la page 2 - 0,906, pour 3 - 0,75.
Avantages
Si vous ne prenez pas en compte le temps passé dans l' indexation, dont les résultats sont réutilisés et tiennent compte du fait que le montant total de calcul, l' évaluation est reproduit en partie 1. , un multiple de la longueur de la chaîne de données:
 ;
;
on peut dire que le gain de l'utilisation de l'index sera un multiple du ratio:
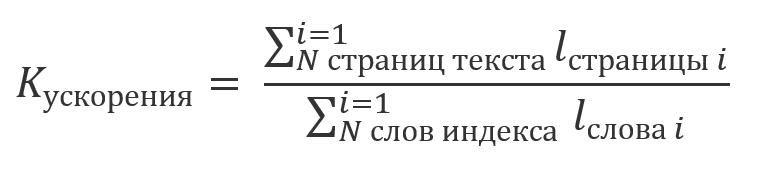
Par exemple, sur le stand de démonstration textradar.ru , le texte du roman "War and Peace" est divisé en 1488 pages de 2000 caractères chacune. Le nombre total de symboles dans les mots de l'index, composé de 52156 éléments, est de 434060. Autrement dit, le gain d'indexation sera d'environ 7:

Du fait que les résultats obtenus en utilisant l'indexation sont équivalents aux résultats obtenus en utilisant l'une des approches précédemment décrites sans elle, il devient possible de traiter conjointement les résultats de la recherche pour les parties indexées et non indexées du texte. En raison du fait que l'indexation est une opération relativement coûteuse et est généralement effectuée selon un calendrier, il est possible qu'une partie du texte soit indexée, et une partie ne l'est pas encore. Dans ce cas, le gain de quantité de calcul sera un multiple de la part du texte indexé dans sa taille totale:
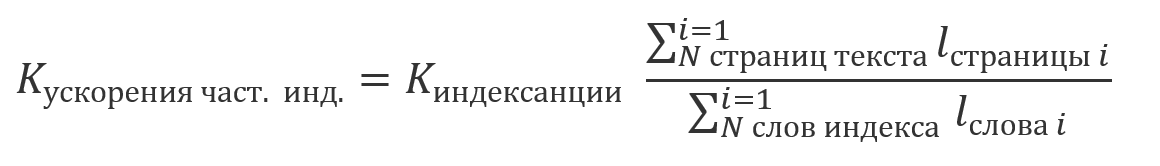
En plus d'améliorer la vitesse de recherche, l'utilisation d'un index ouvre un certain nombre d'autres possibilités. Par exemple, en utilisant les statistiques obtenues à partir de l'indexation, vous pouvez augmenter l'importance des mots rares, ainsi que mettre en évidence les pages de texte sur lesquelles les mots significatifs de la phrase de recherche se trouvent le plus souvent. Vous pouvez également étendre la table d'index avec des synonymes.
Ceci conclut le cycle de publications consacré à la description de TextRadar. Merci à tous pour votre intérêt et vos précieux commentaires qui nous ont permis d'aller plus loin que prévu.
Les résultats de l'application des approches décrites peuvent être vus sur le stand de démonstration déployé sur le site Web textradar.ru . L'implémentation (C # ASP.NET MVC) peut être trouvée ici .