Dans les parties précédentes:
Dans cette partie, nous allons parler de la création d'une liste d'objets affichés dans l'arborescence de navigation.
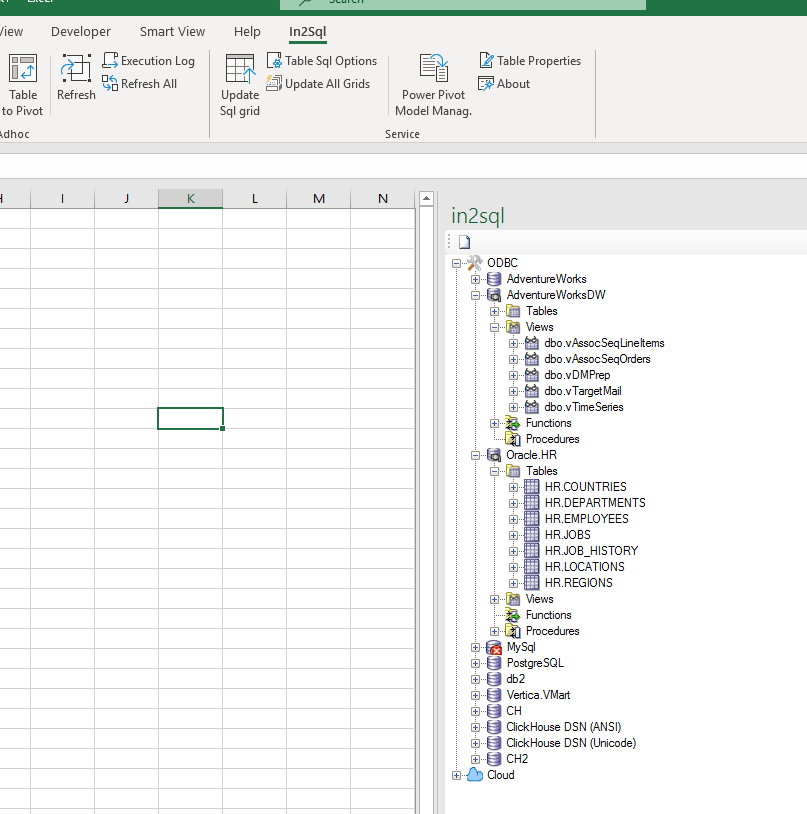
En standard, nous sélectionnons 4 types d'objets de base
- les tables
- Représentation
- Les fonctions
- Procédures.
De plus, chaque base de données a ses propres objets pour stocker des entités - par exemple:
- MS SQL - stocke les données dans sys.schemas, où elles sont séparées par type (type = 'V' - View, type = 'U' - tables)
- Oracle - tout est assez simple ici - il y a des objets user_views et user_tables qui stockent une description des paramètres utilisateur correspondants
- Vertica - v_catalog.views et v_catalog.tables
- PostegreSQL - pg_catalog.pg_views et pg_catalog.pg_tables
- MySQL - information_schema.views et information_schema.tables
- DB2 - toutes les données sont stockées dans SYSIBM.tables où table_type = 'VIEW' sont des vues et table_type = 'BASE TABLE' sont des tables.
- ClickHouse tous les objets sont dans system.tables, la division en tables et vues se produit sur le champ engine = 'View'
Ce manifold est géré par la classe in2SqlLibrary, dans laquelle se produit:
- détermination du type de connexion ODBC, en fonction du nom du fichier du pilote (getDBType)
- répartition des tables (getSqlTables) et des vues (getSqlViews) selon les types correspondants.
Afin d'accélérer le chargement du plugin excel (addin), ces données sont accessibles au moment de l'extension de la branche de l'artefact correspondant (j'en parlerai dans un autre article).