Il y a eu beaucoup de controverse sur la façon de créer des logiciels avec une fiabilité accrue, les méthodologies, les approches de l'organisation du développement, les outils ont été discutés. Mais parmi toutes ces discussions, ce qui est perdu, c'est que le développement logiciel est un processus assez bien étudié et formalisé. Et si vous regardez ce processus, vous remarquerez que ce processus se concentre non seulement sur la façon dont le code est écrit / généré, mais sur la façon dont ce code est vérifié. Plus important encore, le développement nécessite l'utilisation d'outils auxquels vous pouvez «faire confiance».
Cette courte visite est terminée et voyons comment le code s'est avéré fiable. Tout d'abord, vous devez comprendre les caractéristiques du code qui répond aux exigences de fiabilité. Le terme même de «fiabilité du code» semble plutôt vague et contradictoire. Par conséquent, je préfère ne rien inventer et, lors de l'évaluation de la fiabilité du code, je suis guidé par les normes de l'industrie, par exemple, GOST R ISO 26262 ou KT-178C. Le libellé est différent, mais l'idée est la même: un code fiable est développé selon une norme unique (appelée norme de codage ) et le nombre d'erreurs d'exécution qu'il contient est minimisé. Cependant, tout n'est pas si simple ici - les normes prévoient des situations où, par exemple, le respect de la norme de codage n'est pas possible et un tel écart doit être documenté
Bourbier dangereux MISRA et autres
Les normes de codage visent à restreindre l'utilisation de constructions de langage de programmation qui peuvent être potentiellement dangereuses. En théorie, cela devrait améliorer la qualité du code, non? Oui, cela garantit la qualité du code, mais il est toujours important de se rappeler que le respect à 100% des règles de codage n'est pas une fin en soi. Si le code est 100% cohérent avec les règles de certains MISRA, cela ne signifie pas du tout qu'il est bon et correct. Vous pouvez passer beaucoup de temps à refactoriser, nettoyer les violations de la norme de codage, mais tout cela sera gaspillé si le code finit par fonctionner incorrectement ou contient des erreurs d'exécution. De plus, les règles de MISRA ou CERT ne sont généralement qu'une partie de la norme de codage adoptée dans l'entreprise.
L'analyse statique n'est pas une panacée
Les normes prescrivent une revue systématique du code afin de trouver des défauts dans le code et d'analyser le code pour les normes de codage.
Les outils d'analyse statique couramment utilisés à cette fin sont efficaces pour détecter les failles, mais ils ne prouvent pas que le code source est exempt d'erreurs d'exécution. Et de nombreuses erreurs détectées par les analyseurs statiques sont en fait de faux positifs d'outils. Par conséquent, l'utilisation de ces outils ne réduit pas de manière significative le temps passé à la révision du code en raison de la nécessité de vérifier les résultats de la vérification. Pire encore, ils risquent de ne pas détecter les erreurs d'exécution, ce qui est inacceptable pour les applications nécessitant une fiabilité élevée.
Vérification formelle du code
Ainsi, les analyseurs statiques ne sont pas toujours en mesure de détecter les erreurs d'exécution. Comment les détecter et les éliminer? Dans ce cas, une vérification formelle du code source est requise.
Tout d'abord, vous devez comprendre de quel type d'animal s'agit-il? La vérification formelle est la preuve du code sans erreur en utilisant des méthodes formelles. Cela semble effrayant, mais en fait - c'est comme une preuve d'un théorème de matan. Il n'y a pas de magie ici. Cette méthode diffère de l'analyse statique traditionnelle, car elle utilise une interprétation abstraiteplutôt que des heuristiques. Cela nous donne ce qui suit: nous pouvons prouver qu'il n'y a pas d'erreurs d'exécution spécifiques dans le code. Quelles sont ces erreurs? Ce sont toutes sortes de dépassements de tableau, de division par zéro, de dépassement d'entier, etc. Leur méchanceté réside dans le fait que le compilateur collectera le code contenant de telles erreurs (puisque ce code est syntaxiquement correct), mais lorsque ce code sera exécuté, ils apparaîtront.
Regardons un exemple. Ci-dessous dans les spoilers se trouve le code d'un simple contrôleur PI:
Afficher le code
pictrl.c
#include "pi_control.h"
/* Global variable definitions */
float inp_volt[2];
float integral_state;
float duty_cycle;
float direction;
float normalized_error;
/* Static functions */
static void pi_alg(float Kp, float Ki);
static void process_inputs(void);
/* control_task implements a PI controller algorithm that ../
*
* - reads inputs from hardware on actual and desired position
* - determines error between actual and desired position
* - obtains controller gains
* - calculates direction and duty cycle of PWM output using PI control algorithm
* - sets PWM output to hardware
*
*/
void control_task(void)
{
float Ki;
float Kp;
/* Read inputs from hardware */
read_inputs();
/* Convert ADC values to their respective voltages provided read failure did not occur, otherwise do not update input values */
if (!read_failure) {
inp_volt[0] = 0.0048828125F * (float) inp_val[0];
inp_volt[1] = 0.0048828125F * (float) inp_val[1];
}
/* Determine error */
process_inputs();
/* Determine integral and proprortional controller gains */
get_control_gains(&Kp,&Ki);
/* PI control algorithm */
pi_alg(Kp, Ki);
/* Set output pins on hardware */
set_outputs();
}
/* process_inputs computes the error between the actual and desired position by
* normalizing the input values using lookup tables and then taking the difference */
static void process_inputs(void)
{
/* local variables */
float rtb_AngleNormalization;
float rtb_PositionNormalization;
/* Normalize voltage values */
look_up_even( &(rtb_AngleNormalization), inp_volt[1], angle_norm_map, angle_norm_vals);
look_up_even( &(rtb_PositionNormalization), inp_volt[0], pos_norm_map, pos_norm_vals);
/* Compute error */
normalized_error = rtb_PositionNormalization - rtb_AngleNormalization;
}
/* look_up_even provides a lookup table algorithm that works for evenly spaced values.
*
* Inputs to the function are...
* pY - pointer to the output value
* u - input value
* map - structure containing the static lookup table data...
* valueLo - minimum independent axis value
* uSpacing - increment size of evenly spaced independent axis
* iHi - number of increments available in pYData
* pYData - pointer to array of values that make up dependent axis of lookup table
*
*/
void look_up_even( float *pY, float u, map_data map, float *pYData)
{
/* If input is below range of lookup table, output is minimum value of lookup table (pYData) */
if (u <= map.valueLo )
{
pY[1] = pYData[1];
}
else
{
/* Determine index of output into pYData based on input and uSpacing */
float uAdjusted = u - map.valueLo;
unsigned int iLeft = uAdjusted / map.uSpacing;
/* If input is above range of lookup table, output is maximum value of lookup table (pYData) */
if (iLeft >= map.iHi )
{
(*pY) = pYData[map.iHi];
}
/* If input is in range of lookup table, output will interpolate between lookup values */
else
{
{
float lambda; // fractional part of difference between input and nearest lower table value
{
float num = uAdjusted - ( iLeft * map.uSpacing );
lambda = num / map.uSpacing;
}
{
float yLeftCast; // table value that is just lower than input
float yRghtCast; // table value that is just higher than input
yLeftCast = pYData[iLeft];
yRghtCast = pYData[((iLeft)+1)];
if (lambda != 0) {
yLeftCast += lambda * ( yRghtCast - yLeftCast );
}
(*pY) = yLeftCast;
}
}
}
}
}
static void pi_alg(float Kp, float Ki)
{
{
float control_output;
float abs_control_output;
/* y = integral_state + Kp*error */
control_output = Kp * normalized_error + integral_state;
/* Determine direction of torque based on sign of control_output */
if (control_output >= 0.0F) {
direction = TRUE;
} else {
direction = FALSE;
}
/* Absolute value of control_output */
if (control_output < 0.0F) {
abs_control_output = -control_output;
} else if (control_output > 0.0F) {
abs_control_output = control_output;
}
/* Saturate duty cycle to be less than 1 */
if (abs_control_output > 1.0F) {
duty_cycle = 1.0F;
} else {
duty_cycle = abs_control_output;
}
/* integral_state = integral_state + Ki*Ts*error */
integral_state = Ki * normalized_error * 1.0e-002F + integral_state;
}
}
pi_control.h
/* Lookup table structure */
typedef struct {
float valueLo;
unsigned int iHi;
float uSpacing;
} map_data;
/* Macro definitions */
#define TRUE 1
#define FALSE 0
/* Global variable declarations */
extern unsigned short inp_val[];
extern map_data angle_norm_map;
extern float angle_norm_vals[11];
extern map_data pos_norm_map;
extern float pos_norm_vals[11];
extern float inp_volt[2];
extern float integral_state;
extern float duty_cycle;
extern float direction;
extern float normalized_error;
extern unsigned char read_failure;
/* Function declarations */
void control_task(void);
void look_up_even( float *pY, float u, map_data map, float *pYData);
extern void read_inputs(void);
extern void set_outputs(void);
extern void get_control_gains(float* c_prop, float* c_int);
Exécutons le test avec Polyspace Bug Finder , un analyseur statique certifié et qualifié, et obtenons les résultats suivants:
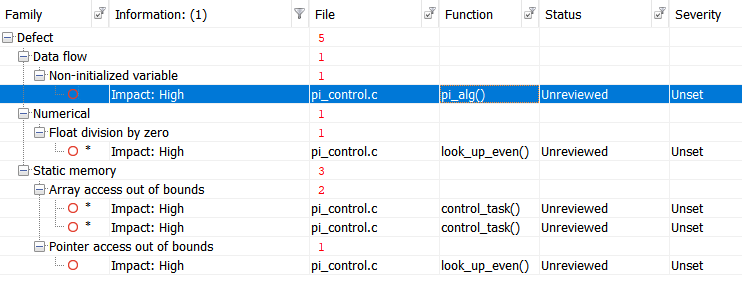
Pour plus de commodité, tabulons les résultats:
Voir les résultats
|
|
|
|
| Non-initialized variable
|
Local variable 'abs_control_output' may be read before being initialized.
|
159
|
| Float division by zero
|
Divisor is 0.0.
|
99
|
| Array access out of bounds
|
Attempt to access element out of the array bounds.
Valid index range starts at 0. |
38
|
| Array access out of bounds
|
Attempt to access element out of the array bounds.
Valid index range starts at 0. |
39
|
| Pointer access out of bounds
|
Attempt to dereference pointer outside of the pointed object at offset 1.
|
93
|
Vérifions maintenant le même code à l'aide de l'outil de vérification formelle Polyspace Code Prover:
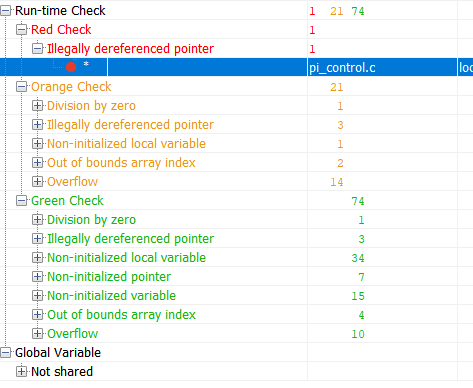
Le vert dans les résultats est un code qui s'est avéré exempt d'erreurs d'exécution. Rouge - erreur avérée. Orange - L'outil est à court de données. Les résultats marqués en vert sont les plus intéressants. Si pour une partie du code l'absence d'erreur d'exécution a été prouvée, alors pour cette partie du code, la quantité de tests peut être considérablement réduite (par exemple, les tests de robustesse ne peuvent plus être effectués) Et maintenant, regardons le tableau récapitulatif des erreurs potentielles et prouvées:
Voir les résultats
|
|
|
|
| Out of bounds array index
|
38
|
Warning: array index may be outside bounds: [array size undefined]
|
| Out of bounds array index
|
39
|
Warning: array index may be outside bounds: [array size undefined]
|
| Overflow
|
70
|
Warning: operation [-] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Illegally dereferenced pointer
|
93
|
Error: pointer is outside its bounds
|
| Overflow
|
98
|
Warning: operation [-] on float may overflow (result strictly greater than MAX FLOAT32)
|
| Division by zero
|
99
|
Warning: float division by zero may occur
|
| Overflow
|
99
|
Warning: operation [conversion from float32 to unsigned int32] on scalar may overflow (on MIN or MAX bounds of UINT32)
|
| Overflow
|
99
|
Warning: operation [/] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Illegally dereferenced pointer
|
104
|
Warning: pointer may be outside its bounds
|
| Overflow
|
114
|
Warning: operation [-] on float may overflow (result strictly greater than MAX FLOAT32)
|
| Overflow
|
114
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
115
|
Warning: operation [/] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Illegally dereferenced pointer
|
121
|
Warning: pointer may be outside its bounds
|
| Illegally dereferenced pointer
|
122
|
Warning: pointer may be outside its bounds
|
| Overflow
|
124
|
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
124
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
124
|
Warning: operation [-] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
142
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
142
|
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Non-uninitialized local variable
|
159
|
Warning: local variable may be non-initialized (type: float 32)
|
| Overflow
|
166
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
166
|
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
Ce tableau me dit ceci:
Il y a eu une erreur d'exécution sur la ligne 93 qui est garantie. Le reste des avertissements m'indique que j'ai configuré la vérification de manière incorrecte ou que j'ai besoin d'écrire un code de sécurité ou de les surmonter d'une autre manière.
Il peut sembler que la vérification formelle est très cool et que l'ensemble du projet doit être vérifié de manière incontrôlable. Cependant, comme pour tout instrument, il existe des limites, principalement liées aux coûts de temps. En bref, la vérification formelle est lente. Tellement lent. Les performances sont limitées par la complexité mathématique de l'interprétation abstraite elle-même et du volume du code à vérifier. Par conséquent, vous ne devez pas essayer de vérifier rapidement le noyau Linux. Tous les projets de vérification dans Polyspace peuvent être divisés en modules qui peuvent être vérifiés indépendamment les uns des autres, et chaque module a sa propre configuration. Autrement dit, nous pouvons personnaliser la rigueur de la vérification pour chaque module séparément.
"Faire confiance" aux outils
Lorsque vous traitez avec des normes industrielles telles que KT-178C ou GOST R ISO 26262, vous rencontrez constamment des choses comme "la confiance dans l'outil" ou la "qualification de l'outil". Qu'Est-ce que c'est? Il s'agit d'un processus dans lequel vous montrez que les résultats des outils de développement ou de test utilisés dans le projet peuvent être approuvés et que leurs erreurs sont documentées. Ce processus fait l'objet d'un article distinct, car tout n'est pas évident. L'essentiel ici est le suivant: les outils utilisés dans l'industrie sont toujours accompagnés d'un ensemble de documents et de tests qui aident dans ce processus.
Résultat
Avec un exemple simple, nous avons examiné la différence entre l'analyse statique classique et la vérification formelle. Peut-il être appliqué en dehors des projets qui nécessitent le respect des normes de l'industrie? Oui bien sûr, vous pouvez. Vous pouvez même demander une version d'essai ici .
En passant, si vous êtes intéressé, vous pouvez faire un article séparé sur la certification des instruments. Écrivez dans les commentaires si vous avez besoin d'un tel article.