
Dans le monde moderne du Big Data, Apache Spark est le standard de facto pour le développement de tâches de traitement par lots. En outre, il est également utilisé pour créer des applications de streaming fonctionnant dans le concept de micro-lots, traitant et envoyant des données par petites portions (Spark Structured Streaming). Et traditionnellement, il faisait partie de la pile globale Hadoop, utilisant YARN (ou, dans certains cas, Apache Mesos) comme gestionnaire de ressources. D'ici 2020, son utilisation traditionnelle pour la plupart des entreprises est sous une grande question en raison du manque de distributions Hadoop décentes - le développement de HDP et CDH a cessé, CDH est sous-développé et a un coût élevé, et le reste des fournisseurs Hadoop ont cessé d'exister ou ont un avenir vague.Par conséquent, l'intérêt croissant de la communauté et des grandes entreprises est le lancement d'Apache Spark utilisant Kubernetes - devenu la norme dans l'orchestration de conteneurs et la gestion des ressources dans les clouds privés et publics, il résout le problème de la planification des ressources incommode des tâches Spark sur YARN et fournit une plate-forme en développement constant avec de nombreuses et des distributions open source pour les entreprises de toutes tailles et de toutes tailles. De plus, sur la vague de popularité, la plupart ont déjà réussi à acquérir quelques-unes de leurs installations et à accroître leur expertise dans leur utilisation, ce qui simplifie le déménagement.il résout la planification délicate des tâches Spark sur YARN et fournit une plate-forme en constante évolution avec de nombreuses distributions commerciales et open source pour les entreprises de toutes tailles et de toutes catégories. De plus, sur la vague de popularité, la plupart ont déjà réussi à acquérir quelques-unes de leurs installations et à accroître leur expertise dans leur utilisation, ce qui simplifie le déménagement.il résout la planification délicate des tâches Spark sur YARN et fournit une plate-forme en constante évolution avec de nombreuses distributions commerciales et open source pour les entreprises de toutes tailles et de toutes catégories. De plus, sur la vague de popularité, la plupart ont déjà réussi à acquérir quelques-unes de leurs installations et à accroître leur expertise dans leur utilisation, ce qui simplifie le déménagement.
À partir de la version 2.3.0, Apache Spark a acquis un support officiel pour l'exécution de tâches dans le cluster Kubernetes, et aujourd'hui, nous parlerons de la maturité actuelle de cette approche, des différents cas d'utilisation et des pièges qui seront rencontrés lors de la mise en œuvre.
Tout d'abord, nous examinerons le processus de développement de tâches et d'applications basées sur Apache Spark et mettrons en évidence les cas typiques dans lesquels vous devez exécuter une tâche sur un cluster Kubernetes. Lors de la préparation de cet article, OpenShift est utilisé comme un kit de distribution et les commandes pertinentes pour son utilitaire de ligne de commande (oc) seront données. Pour les autres distributions Kubernetes, les commandes correspondantes de l'utilitaire de ligne de commande Kubernetes standard (kubectl) ou leurs analogues (par exemple, pour oc adm policy) peuvent être utilisées.
Le premier cas d'utilisation est Spark-submit
Dans le processus de développement de tâches et d'applications, le développeur doit exécuter des tâches pour déboguer la transformation des données. Théoriquement, les stubs peuvent être utilisés à ces fins, mais le développement avec la participation de copies réelles (bien que testées) de systèmes finis s'est montré plus rapide et mieux dans cette classe de tâches. Dans le cas où l'on débogue sur des instances réelles de systèmes d'extrémité, deux scénarios sont possibles:
- le développeur exécute la tâche Spark localement en mode autonome;
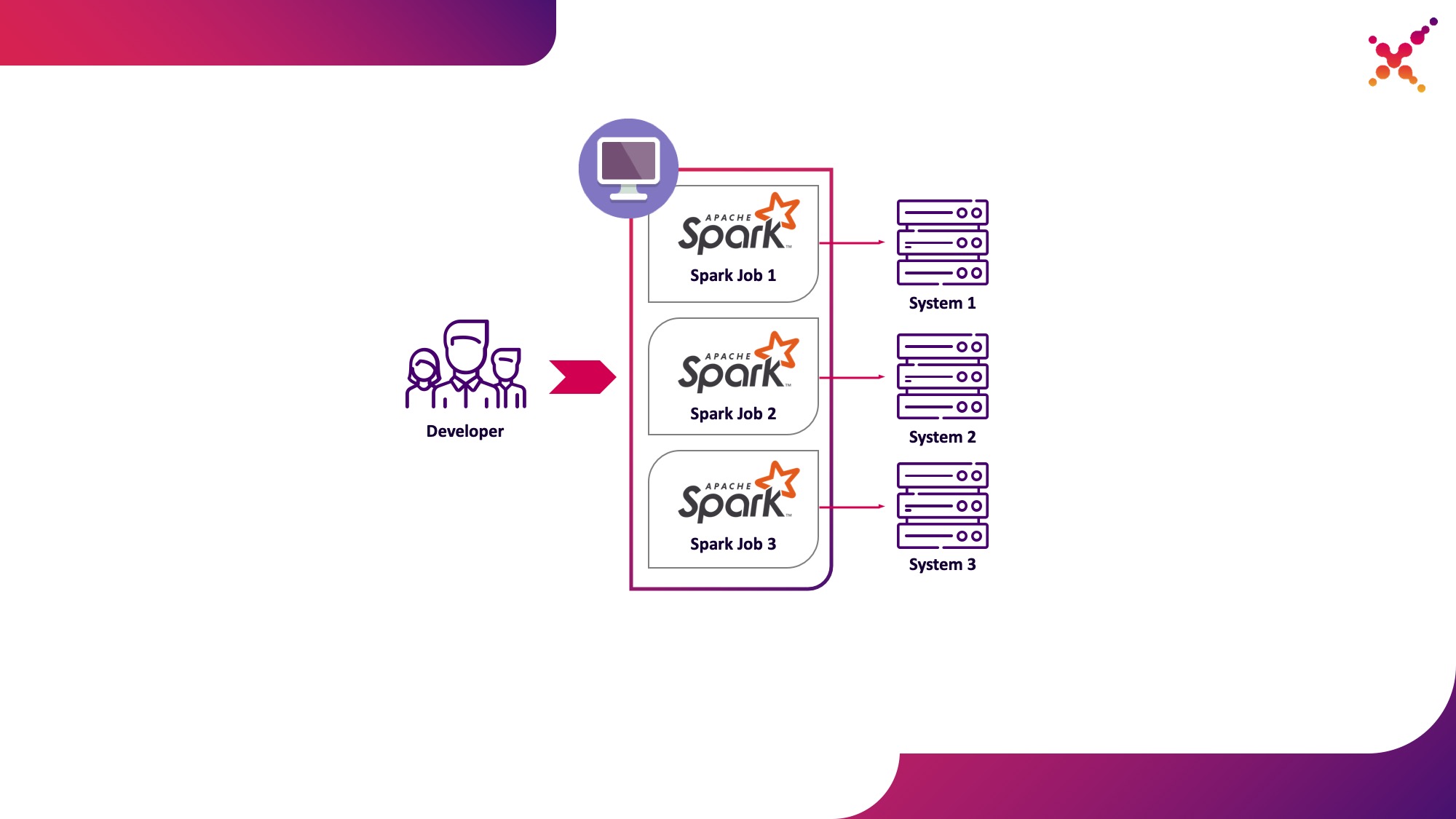
- un développeur exécute une tâche Spark sur un cluster Kubernetes dans une boucle de test.

La première option a le droit d'exister, mais comporte un certain nombre d'inconvénients:
- pour chaque développeur, il est nécessaire de donner accès depuis le lieu de travail à toutes les copies des systèmes terminaux dont il a besoin;
- la machine de travail nécessite des ressources suffisantes pour exécuter la tâche développée.
La deuxième option est dépourvue de ces inconvénients, car l'utilisation d'un cluster Kubernetes vous permet d'allouer le pool de ressources nécessaire pour exécuter des tâches et de lui fournir l'accès nécessaire aux instances des systèmes finaux, en lui fournissant de manière flexible un accès à l'aide du modèle de rôle Kubernetes pour tous les membres de l'équipe de développement. Soulignons-le comme premier cas d'utilisation: exécuter des tâches Spark à partir d'une machine de développement locale sur un cluster Kubernetes dans une boucle de test.
Examinons de plus près le processus de configuration de Spark pour qu'il s'exécute localement. Pour commencer à utiliser Spark, vous devez l'installer:
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
Nous collectons les packages nécessaires pour travailler avec Kubernetes:
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
La compilation complète prend beaucoup de temps, et pour créer des images Docker et les exécuter sur le cluster Kubernetes, en réalité, vous n'avez besoin que des fichiers jar du répertoire "assembly /", vous ne pouvez donc créer que ce sous-projet:
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
Pour exécuter des tâches Spark dans Kubernetes, vous devez créer une image Docker qui servira d'image de base. 2 approches sont possibles ici:
- L'image Docker générée comprend le code exécutable de la tâche Spark;
- L'image créée comprend uniquement Spark et les dépendances nécessaires, le code exécutable est hébergé à distance (par exemple, en HDFS).
Tout d'abord, construisons une image Docker contenant un exemple de test d'une tâche Spark. Pour créer des images Docker, Spark dispose d'un utilitaire appelé "docker-image-tool". Étudions l'aide à ce sujet:
./bin/docker-image-tool.sh --help
Il peut être utilisé pour créer des images Docker et les télécharger vers des registres distants, mais par défaut, il présente plusieurs inconvénients:
- sans faute crée 3 images Docker à la fois - pour Spark, PySpark et R;
- ne vous permet pas de spécifier le nom de l'image.
Par conséquent, nous utiliserons une version modifiée de cet utilitaire, illustrée ci-dessous:
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}" \
-t $(image_ref $IMAGE_REF) \
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
En l'utilisant, nous construisons une image Spark de base contenant une tâche de test pour calculer le nombre Pi à l'aide de Spark (ici {docker-registry-url} est l'URL de votre registre d'images Docker, {repo} est le nom du référentiel dans le registre, qui coïncide avec le projet dans OpenShift , {image-name} est le nom de l'image (si la séparation d'image à trois niveaux est utilisée, par exemple, comme dans le registre d'images intégré Red Hat OpenShift), {tag} est la balise de cette version de l'image):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
Connectez-vous au cluster OKD à l'aide de l'utilitaire de console (ici {OKD-API-URL} est l'URL de l'API du cluster OKD):
oc login {OKD-API-URL}
Récupérons le jeton de l'utilisateur actuel pour l'autorisation dans le registre Docker:
oc whoami -t
Connectez-vous au registre Docker interne du cluster OKD (utilisez le jeton obtenu avec la commande précédente comme mot de passe):
docker login {docker-registry-url}
Téléchargez l'image Docker intégrée dans le registre Docker OKD:
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
Vérifions que l'image construite est disponible dans OKD. Pour ce faire, ouvrez une URL avec une liste d'images du projet correspondant dans le navigateur (ici {project} est le nom du projet à l'intérieur du cluster OpenShift, {OKD-WEBUI-URL} est l'URL de la console Web OpenShift) - https: // {OKD-WEBUI-URL} / console / project / {projet} / parcourir / images / {image-name}.
Pour exécuter des tâches, un compte de service doit être créé avec les privilèges d'exécuter des pods en tant que root (nous aborderons ce point plus tard):
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
Exécutez la commande spark-submit pour publier la tâche Spark sur le cluster OKD, en spécifiant le compte de service créé et l'image Docker:
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
Ici:
--name est le nom de la tâche qui participera à la formation du nom des pods Kubernetes;
--class - la classe du fichier exécutable appelé lorsque la tâche démarre;
--conf - Paramètres de configuration Spark;
spark.executor.instances Le nombre d'exécuteurs Spark à exécuter.
spark.kubernetes.authenticate.driver.serviceAccountName - Le nom du compte de service Kubernetes utilisé lors du lancement des pods (pour définir le contexte de sécurité et les capacités lors de l'interaction avec l'API Kubernetes);
spark.kubernetes.namespace - Espace de noms Kubernetes dans lequel les pods pilote et exécuteur s'exécuteront;
spark.submit.deployMode - Méthode de lancement de Spark ("cluster" est utilisé pour la soumission standard de Spark, "client" pour Spark Operator et les versions ultérieures de Spark);
spark.kubernetes.container.image L'image Docker utilisée pour exécuter les pods.
spark.master - URL de l'API Kubernetes (l'externe est spécifié pour que l'appel se produise à partir de la machine locale);
local: // est le chemin d'accès à l'exécutable Spark dans l'image Docker.
Accédez au projet OKD correspondant et étudiez les pods créés - https: // {OKD-WEBUI-URL} / console / project / {project} / parcourir / pods.
Pour simplifier le processus de développement, une autre option peut être utilisée, dans laquelle une image Spark de base commune est créée, qui est utilisée par toutes les tâches à exécuter, et des instantanés des fichiers exécutables sont publiés sur un stockage externe (par exemple, Hadoop) et spécifiés lors de l'appel de spark-submit en tant que lien. Dans ce cas, vous pouvez exécuter différentes versions de tâches Spark sans reconstruire les images Docker, en utilisant par exemple WebHDFS pour publier des images. Nous envoyons une requête pour créer un fichier (ici {host} est l'hôte du service WebHDFS, {port} est le port du service WebHDFS, {path-to-file-on-hdfs} est le chemin souhaité vers le fichier sur HDFS):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE
Celui-ci recevra une réponse du formulaire (ici {location} est l'URL qui doit être utilisée pour télécharger le fichier):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
Chargez le fichier exécutable Spark dans HDFS (ici {path-to-local-file} est le chemin d'accès à l'exécutable Spark sur l'hôte actuel):
curl -i -X PUT -T {path-to-local-file} "{location}"
Après cela, nous pouvons effectuer une soumission spark à l'aide du fichier Spark téléchargé sur HDFS (ici {class-name} est le nom de la classe qui doit être lancée pour terminer la tâche):
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
Dans le même temps, il convient de noter que pour accéder à HDFS et permettre à la tâche de fonctionner, vous devrez peut-être modifier le Dockerfile et le script entrypoint.sh - ajoutez une directive au Dockerfile pour copier les bibliothèques dépendantes dans le répertoire / opt / spark / jars et inclure le fichier de configuration HDFS dans SPARK_CLASSPATH dans le point d'entrée. sh.
Deuxième cas d'utilisation - Apache Livy
De plus, lorsque la tâche est développée et qu'il est nécessaire de tester le résultat obtenu, la question se pose de la lancer dans le processus CI / CD et de suivre l'état de son exécution. Bien sûr, vous pouvez l'exécuter à l'aide d'un appel de soumission Spark local, mais cela complique l'infrastructure CI / CD car il nécessite l'installation et la configuration de Spark sur les agents / exécuteurs du serveur CI et la configuration de l'accès à l'API Kubernetes. Dans ce cas, l'implémentation cible a choisi d'utiliser Apache Livy comme API REST pour exécuter des tâches Spark hébergées dans le cluster Kubernetes. Il peut être utilisé pour lancer des tâches Spark sur le cluster Kubernetes à l'aide de requêtes cURL régulières, qui sont facilement implémentées en fonction de n'importe quelle solution CI, et son placement dans le cluster Kubernetes résout le problème d'authentification lors de l'interaction avec l'API Kubernetes.
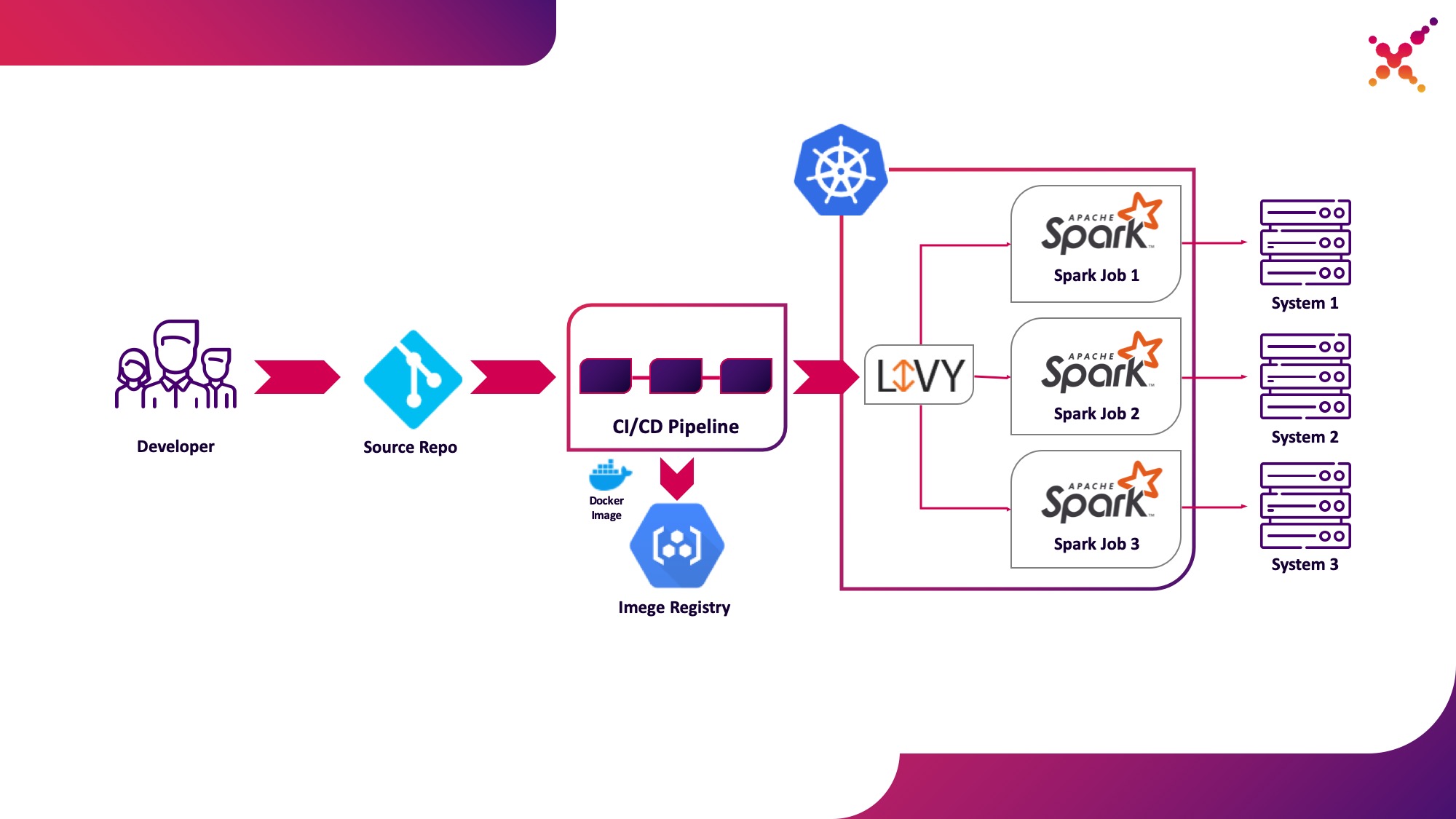
Soulignons-le comme deuxième cas d'utilisation: exécuter des tâches Spark dans le cadre du processus CI / CD sur un cluster Kubernetes dans une boucle de test.
Un peu sur Apache Livy - il fonctionne comme un serveur HTTP qui fournit une interface Web et une API RESTful qui vous permet d'exécuter à distance spark-submit en passant les paramètres nécessaires. Traditionnellement, il était livré dans le cadre de la distribution HDP, mais il peut également être déployé sur OKD ou toute autre installation Kubernetes en utilisant le manifeste approprié et un ensemble d'images Docker, comme celui-ci - github.com/ttauveron/k8s-big-data-experiments/tree/master /livy-spark-2.3 . Dans notre cas, une image Docker similaire a été créée, y compris Spark version 2.4.5 à partir du Dockerfile suivant:
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash && \
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz && \
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz && \
rm spark-2.4.5-bin-hadoop2.7.tgz && \
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip && \
unzip apache-livy-0.7.0-incubating-bin.zip && \
rm apache-livy-0.7.0-incubating-bin.zip && \
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy && \
mkdir /var/log/livy && \
ln -s /var/log/livy /opt/livy/logs && \
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
L'image générée peut être créée et téléchargée dans votre référentiel Docker existant, par exemple le référentiel OKD interne. Pour le déployer, le manifeste suivant est utilisé ({registry-url} est l'URL du registre d'images Docker, {image-name} est le nom de l'image Docker, {tag} est la balise de l'image Docker, {livy-url} est l'URL souhaitée où le serveur sera accessible. Livy; le manifeste "Route" est utilisé si Red Hat OpenShift est utilisé comme distribution Kubernetes, sinon le manifeste Ingress ou Service correspondant de type NodePort est utilisé):
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4/spark:v1.0.14'
image: '{registry-url}/{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/livy
name: livy-log
- mountPath: /opt/.livy-sessions/
name: livy-sessions
- mountPath: /opt/livy/conf/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: /opt/spark/conf/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- /usr/local/bin/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=/opt/.livy-sessions/
livy.spark.master=k8s://http://localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
Après son application et le lancement réussi du pod, l'interface graphique de Livy est disponible sur le lien: http: // {livy-url} / ui. Avec Livy, nous pouvons publier notre tâche Spark à l'aide d'une requête REST, par exemple de Postman. Un exemple de collection avec des requêtes est présenté ci-dessous (dans le tableau "args", les arguments de configuration avec les variables nécessaires au fonctionnement de la tâche en cours peuvent être passés):
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Submit job with jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar\", \n\t\"className\": \"org.apache.spark.examples.SparkPi\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-1\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t}\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Submit job without jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"hdfs://{host}:{port}/{path-to-file-on-hdfs}\", \n\t\"className\": \"{class-name}\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-2\",\n\t\"proxyUser\": \"0\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t},\n\t\"args\": [\n\t\t\"HADOOP_CONF_DIR=/opt/spark/hadoop-conf\",\n\t\t\"MASTER=k8s://https://kubernetes.default.svc:8443\"\n\t]\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
Exécutons la première requête de la collection, allons dans l'interface OKD et vérifions que la tâche a été lancée avec succès - https: // {OKD-WEBUI-URL} / console / project / {project} / parcourir / pods. Dans ce cas, une session apparaîtra dans l'interface Livy (http: // {livy-url} / ui), dans laquelle, à l'aide de l'API Livy ou d'une interface graphique, vous pourrez suivre la progression de la tâche et étudier les journaux de session.
Voyons maintenant comment fonctionne Livy. Pour ce faire, examinons les journaux du conteneur Livy à l'intérieur du pod avec le serveur Livy - https: // {OKD-WEBUI-URL} / console / project / {projet} / parcourir / pods / {livy-pod-name}? Tab = logs. À partir d'eux, vous pouvez voir que lorsque vous appelez l'API Livy REST dans un conteneur nommé "livy", un spark-submit est exécuté, similaire à celui que nous avons utilisé ci-dessus (ici {livy-pod-name} est le nom du pod créé avec le serveur Livy). La collection fournit également une deuxième requête qui vous permet d'exécuter des tâches avec l'hébergement à distance de l'exécutable Spark à l'aide du serveur Livy.
Troisième cas d'utilisation - Spark Operator
Maintenant que la tâche a été testée, la question se pose de l'exécuter régulièrement. Le moyen natif d'exécuter régulièrement des tâches dans le cluster Kubernetes est l'entité CronJob et vous pouvez l'utiliser, mais pour le moment, l'utilisation d'opérateurs pour contrôler les applications dans Kubernetes est très populaire, et pour Spark, il existe un opérateur assez mature, qui, entre autres, est utilisé dans les solutions de niveau entreprise. (par exemple, la plate-forme Lightbend FastData). Nous vous recommandons de l'utiliser - la version stable actuelle de Spark (2.4.5) a des options assez limitées pour configurer le lancement des tâches Spark dans Kubernetes, tandis que dans la prochaine version majeure (3.0.0), le support complet de Kubernetes est annoncé, mais sa date de sortie reste inconnue. Spark Operator compense cette lacune en ajoutant des paramètres de configuration importants (par exemple,montage de ConfigMap avec la configuration de l'accès à Hadoop dans les pods Spark) et la possibilité d'exécuter régulièrement la tâche selon un planning.
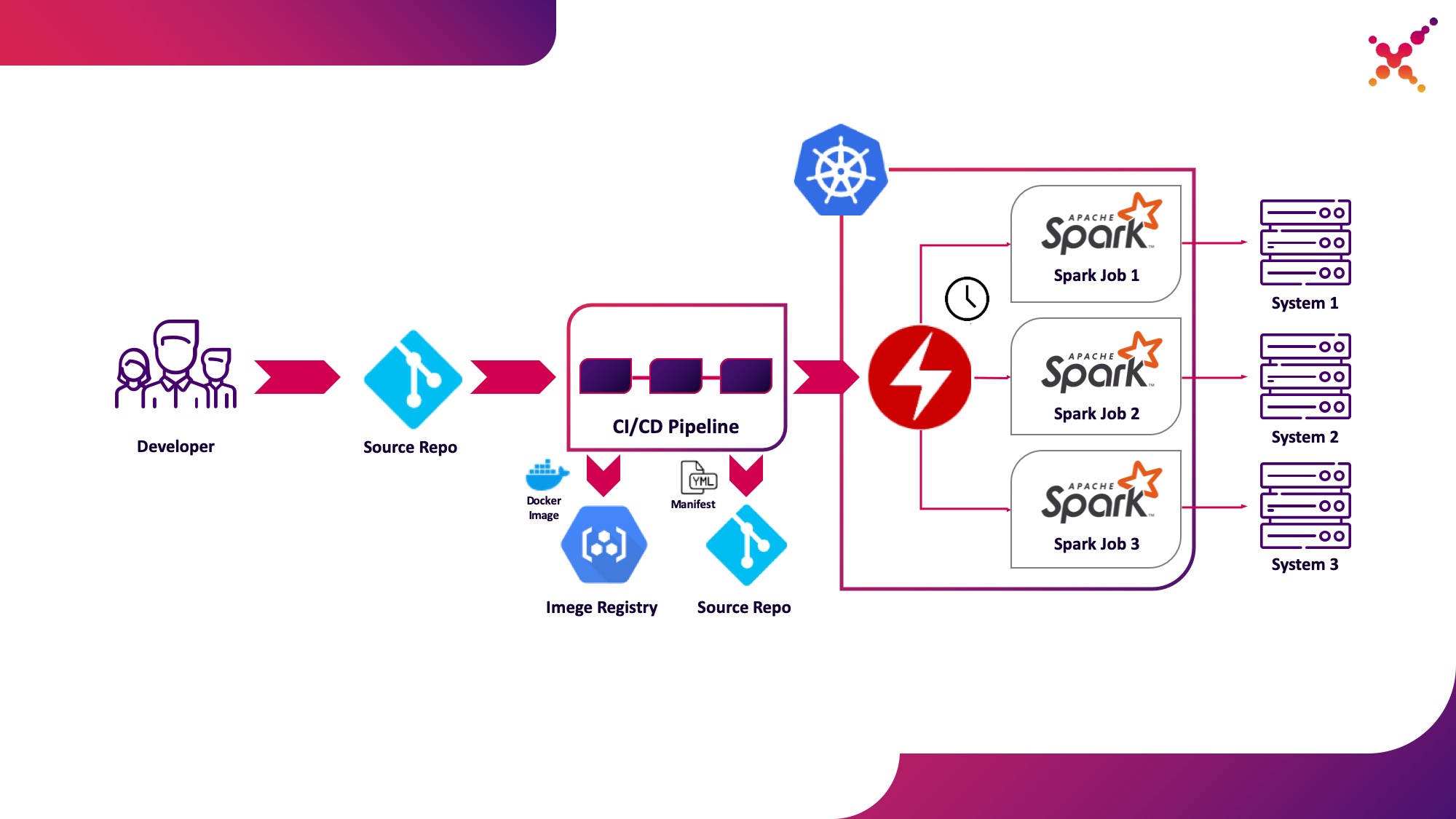
Soulignons-le comme troisième cas d'utilisation: exécuter régulièrement des tâches Spark sur un cluster Kubernetes dans une boucle de production.
Spark Operator est open source et développé dans le cadre de Google Cloud Platform - github.com/GoogleCloudPlatform/spark-on-k8s-operator . Son installation peut se faire de 3 manières:
- Dans le cadre de l'installation de Lightbend FastData Platform / Cloudflow;
- Avec Helm:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator
- (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). — Cloudflow API v1beta1. , Spark Git API, , «v1beta1-0.9.0-2.4.0». CRD, «versions»:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
Si l'opérateur est correctement défini, un pod actif avec l'opérateur Spark (par exemple, cloudflow-fdp-sparkoperator dans l'espace Cloudflow pour l'installation de Cloudflow) apparaîtra dans le projet correspondant et le type de ressource Kubernetes correspondant nommé "sparkapplications" apparaîtra. Vous pouvez examiner les applications Spark disponibles avec la commande suivante:
oc get sparkapplications -n {project}
Pour exécuter des tâches avec Spark Operator, vous devez effectuer 3 choses:
- créer une image Docker qui comprend toutes les bibliothèques requises, ainsi que les fichiers de configuration et exécutables. Dans l'image cible, il s'agit d'une image créée au stade CI / CD et testée sur un cluster de test;
- publier l'image Docker dans le registre accessible depuis le cluster Kubernetes;
- «SparkApplication» . (, github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/v1beta1-0.9.0-2.4.0/examples/spark-pi.yaml). :
- «apiVersion» API, ;
- «metadata.namespace» , ;
- «spec.image» Docker ;
- «spec.mainClass» Spark, ;
- «spec.mainApplicationFile» jar ;
- le dictionnaire "spec.sparkVersion" doit indiquer la version de Spark utilisée;
- le dictionnaire "spec.driver.serviceAccount" doit contenir un compte de service dans l'espace de noms Kubernetes approprié qui sera utilisé pour lancer l'application;
- le dictionnaire "spec.executor" doit indiquer la quantité de ressources allouées à l'application;
- le dictionnaire "spec.volumeMounts" doit spécifier le répertoire local dans lequel les fichiers de tâches Spark locaux seront créés.
Un exemple de génération d'un manifeste (ici {spark-service-account} est un compte de service dans le cluster Kubernetes pour exécuter des tâches Spark):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Ce manifeste spécifie un compte de service pour lequel, avant de publier le manifeste, vous devez créer les liaisons de rôle nécessaires qui fournissent les droits d'accès nécessaires à l'application Spark pour interagir avec l'API Kubernetes (si nécessaire). Dans notre cas, l'application a besoin des droits pour créer des pods. Créons la liaison de rôle requise:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
Il est également intéressant de noter que la spécification de ce manifeste peut spécifier le paramètre hadoopConfigMap, qui vous permet de spécifier un ConfigMap avec une configuration Hadoop sans avoir à placer d'abord le fichier correspondant dans l'image Docker. Il convient également au lancement régulier de tâches - en utilisant le paramètre «planning», un calendrier pour le lancement de cette tâche peut être spécifié.
Après cela, nous enregistrons notre manifeste dans le fichier spark-pi.yaml et l'appliquons à notre cluster Kubernetes:
oc apply -f spark-pi.yaml
Cela créera un objet de type "sparkapplications":
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
Cela créera un pod avec une application, dont le statut sera affiché dans les "sparkapplications" créées. Il peut être visualisé avec la commande suivante:
oc get sparkapplications spark-pi -o yaml -n {project}
Une fois la tâche terminée, le POD passera à l'état "Terminé", qui est également mis à jour en "sparkapplications". Les journaux d'application peuvent être consultés dans un navigateur ou à l'aide de la commande suivante (ici {sparkapplications-pod-name} est le nom du pod de la tâche en cours):
oc logs {sparkapplications-pod-name} -n {project}
Les tâches Spark peuvent également être gérées à l'aide de l'utilitaire sparkctl spécialisé. Pour l'installer, nous clonons le référentiel avec son code source, installons Go et construisons cet utilitaire:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
Examinons la liste des tâches Spark en cours d'exécution:
sparkctl list -n {project}
Créons une description pour la tâche Spark:
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Exécutons la tâche décrite en utilisant sparkctl:
sparkctl create spark-app.yaml -n {project}
Examinons la liste des tâches Spark en cours d'exécution:
sparkctl list -n {project}
Examinons la liste des événements de la tâche Spark démarrée:
sparkctl event spark-pi -n {project} -f
Examinons l'état de la tâche Spark en cours d'exécution:
sparkctl status spark-pi -n {project}
En conclusion, j'aimerais examiner les inconvénients découverts liés à l'exploitation de la version stable actuelle de Spark (2.4.5) dans Kubernetes:
- , , — Data Locality. YARN , , ( ). Spark , , , . Kubernetes , . , , , , Spark . , Kubernetes (, Alluxio), Kubernetes.
- — . , Spark , Kerberos ( 3.0.0, ), Spark (https://spark.apache.org/docs/2.4.5/security.html) YARN, Mesos Standalone Cluster. , Spark, — , , . root, , UID, ( PodSecurityPolicies ). Docker, Spark , .
- L'exécution de tâches Spark avec Kubernetes est toujours officiellement en mode expérimental, et des changements importants peuvent être apportés aux artefacts utilisés (fichiers de configuration, images de base Docker et scripts de démarrage) à l'avenir. En effet, lors de la préparation du matériel, les versions 2.3.0 et 2.4.5 ont été testées, le comportement était significativement différent.
Nous attendrons les mises à jour - une nouvelle version de Spark (3.0.0) a récemment été publiée, qui a apporté des changements tangibles au travail de Spark sur Kubernetes, mais a conservé le statut expérimental de prise en charge de ce gestionnaire de ressources. Peut-être que les prochaines mises à jour permettront vraiment de recommander totalement d'abandonner YARN et d'exécuter des tâches Spark sur Kubernetes, sans craindre pour la sécurité de votre système et sans avoir besoin d'affiner indépendamment les composants fonctionnels.
Ailette.