
Photo du site Unsplash . Par Sasha • Stories
Scikit-learn est l'une des bibliothèques d'apprentissage automatique Python les plus utilisées. Son interface standard simple permet le prétraitement des données, la formation, l'optimisation et l'évaluation du modèle.
Ce projet, conçu par David Cournapeau, est né dans le cadre du programme Google Summer of Code et est sorti en 2010. Depuis sa création, la bibliothèque est devenue une infrastructure riche pour la création de modèles d'apprentissage automatique. Les nouvelles fonctionnalités vous permettent de résoudre encore plus de tâches et d'améliorer la convivialité. Dans cet article, je présenterai dix des fonctionnalités les plus intéressantes que vous ne connaissez peut-être pas.
1. Ensembles de données intégrés
Dans l'API de la bibliothèque scikit-learn, vous pouvez trouver des ensembles de données intégrés contenant des données générées et réelles . Vous pouvez les utiliser avec une seule ligne de code. Ces données sont extrêmement utiles si vous venez d'apprendre ou si vous voulez simplement tester rapidement quelque chose.
En outre, à l'aide d'un outil spécial, vous pouvez générer vous-même des données synthétiques pour les tâches de régression
make_regression(), de clustering make_blobs()et de classification make_classification().
Chaque méthode produit des données déjà décomposées en X (caractéristiques) et Y (variable cible) afin qu'elles puissent être utilisées directement pour entraîner le modèle.
# Toy regression data set loading
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y = True)
# Synthetic regresion data set loading
from sklearn.datasets import make_regression
X,y = make_regression(n_samples=10000, noise=100, random_state=0)2. Accès à des ensembles de données publics tiers
Si vous souhaitez accéder à une variété de jeux de données publics directement via scikit-learn, consultez la fonctionnalité pratique qui vous permet d'importer des données directement depuis openml.org . Ce site contient plus de 21 000 ensembles de données différents qui peuvent être utilisés dans des projets d'apprentissage automatique.
from sklearn.datasets import fetch_openml
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)3. Classificateurs prêts pour la formation des modèles de base
Lors de la création d'un modèle d'apprentissage automatique pour un projet, il est conseillé de créer d'abord un modèle de référence. C'est un modèle factice qui prédit toujours la classe la plus courante. Cela vous donne les données de référence pour comparer votre modèle plus complexe. De plus, vous pouvez être sûr de la qualité de son travail, par exemple, qu'il produit plus qu'un simple ensemble de données sélectionnées au hasard.
La bibliothèque scikit-learn en a une
DummyClassifier()pour les problèmes de classification et DummyRegressor()pour travailler avec la régression.
from sklearn.dummy import DummyClassifier
# Fit the model on the wine dataset and return the model score
dummy_clf = DummyClassifier(strategy="most_frequent", random_state=0)
dummy_clf.fit(X, y)
dummy_clf.score(X, y)4. Propre API pour la visualisation
Scikit-learn possède une API de visualisation intégrée qui vous permet de visualiser le fonctionnement de votre modèle sans importer d'autres bibliothèques. Il fournit les options suivantes: tracés de dépendances, matrice d'erreur, courbes ROC et Precision-Recall.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()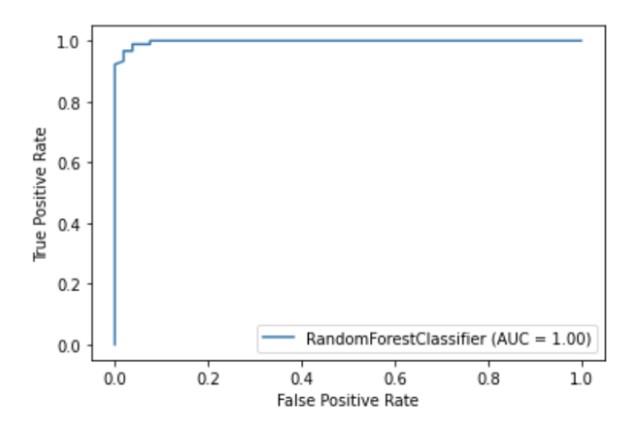
Illustration de l'auteur
5. Méthodes intégrées de sélection des fonctionnalités
L'un des moyens d'améliorer la qualité du modèle consiste à n'utiliser que les fonctionnalités les plus utiles dans la formation ou à supprimer les moins informatives. Ce processus s'appelle la sélection des fonctionnalités.
Scikit-learn dispose d'un certain nombre de méthodes pour effectuer la sélection de fonctionnalités , dont l'une est
SelectPercentile(). Cette méthode sélectionne le centile X des caractéristiques les plus informatives en fonction de la méthode statistique d'estimation spécifiée.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectPercentile, chi2
X,y = load_wine(return_X_y = True)
X_trasformed = SelectPercentile(chi2, percentile=60).fit_transform(X, y)6. Pipelines pour connecter les étapes du processus d'apprentissage automatique
En plus de pouvoir utiliser une énorme liste d'algorithmes d'apprentissage automatique, scikit-learn fournit également un certain nombre de fonctions pour le prétraitement et la transformation des données. Pour assurer la reproductibilité et l'accessibilité dans le processus d'apprentissage automatique dans scikit-learn ont été créés Pipeline , qui regroupe les différentes étapes et l'étape de prétraitement du modèle de formation.
Le pipeline stocke toutes les étapes du flux de travail sous la forme d'un objet unique qui peut être appelé par les méthodes fit et prédire. Lorsque vous exécutez la méthode fit sur un objet de pipeline, les étapes de prétraitement et d'apprentissage du modèle sont exécutées automatiquement.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Chain together scaling the variables with the model
pipe = Pipeline([('scaler', StandardScaler()), ('rf', RandomForestClassifier())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)7. ColumnTransformer pour varier les méthodes de prétraitement pour différentes fonctionnalités
De nombreux ensembles de données contiennent différents types d'entités, qui nécessitent plusieurs étapes différentes pour le prétraitement. Par exemple, vous pourriez être confronté à un mélange de données catégoriques et numériques, et vous pourriez vouloir mettre à l'échelle des colonnes numériques et convertir des caractéristiques catégorielles en numériques à l'aide du codage à chaud.
Le pipeline scikit-learn est équipé d'une fonction ColumnTransformer , qui vous permet d'indiquer facilement la méthode de prétraitement la plus appropriée pour des colonnes spécifiques via l'indexation ou en spécifiant les noms de colonne.
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))8. Obtenez facilement une image HTML de votre pipeline
Les pipelines sont souvent assez complexes, en particulier lorsqu'ils travaillent avec des données réelles. Par conséquent, il est très pratique que vous puissiez utiliser scikit-learn pour générer un diagramme HTML des étapes de votre pipeline.
from sklearn import set_config
set_config(display='diagram')
lr
Illustration de l'auteur
9. Fonction de traçage pour visualiser les arbres de décision
La fonction
plot_tree()permet de créer un diagramme des étapes présentes dans le modèle d'arbre de décision.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
plt.show()10. De nombreuses bibliothèques tierces qui étendent les fonctions scikit-learn
Il existe de nombreuses bibliothèques tierces compatibles et étendant scikit-learn.
Par exemple, la bibliothèque Category Encoders , qui offre un plus large choix de méthodes de prétraitement pour les fonctions catégorielles, ou la bibliothèque ELI5 , pour une interprétation plus détaillée des modèles.
Les deux ressources sont également accessibles directement via le pipeline scikit-learn.
# Pipeline using Weight of Evidence transformer from category encoders
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import category_encoders as ce
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('woe', ce.woe.WOEEncoder())])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))Merci de votre attention!