
Dès le début, je tiens à préciser que dans ce cas, Oracle est présenté comme un langage SQL collectif. Les regroupements et la manière dont ils sont appliqués s'appliquent à toute la famille de SQL (qui est compris ici comme un langage de requête structuré) et est applicable à toutes les requêtes avec des corrections pour la syntaxe de chaque langage.
Je vais essayer d'expliquer brièvement et facilement toutes les informations nécessaires en deux parties. Le message sera très probablement utile pour les développeurs novices. Qui s'en soucie - bienvenue au chat.
Partie 1: Offres Trier par, Grouper par, Ayant
Ici, nous allons parler de tri - Trier par, regrouper - Regrouper par, filtrer - Avoir et plan de requête. Mais tout d'abord.
Commandé par
L'opérateur Order by trie les valeurs de sortie, c'est-à-dire trie la valeur récupérée par une colonne spécifique. Le tri peut également être appliqué par un alias de colonne défini à l'aide d'un opérateur.
L'avantage de Order by est qu'il peut être appliqué aux colonnes numériques et chaînes. Les colonnes de chaînes sont généralement triées par ordre alphabétique.
Le tri croissant est appliqué par défaut. Si vous souhaitez trier les colonnes par ordre décroissant, utilisez l'opérateur DESC supplémentaire.
Syntaxe:
SELECT colonne1, colonne2, … (indique le nom)
FROM nom_table
ORDER BY colonne1, colonne2 … ASC | DESC ;
Regardons tout avec des exemples:
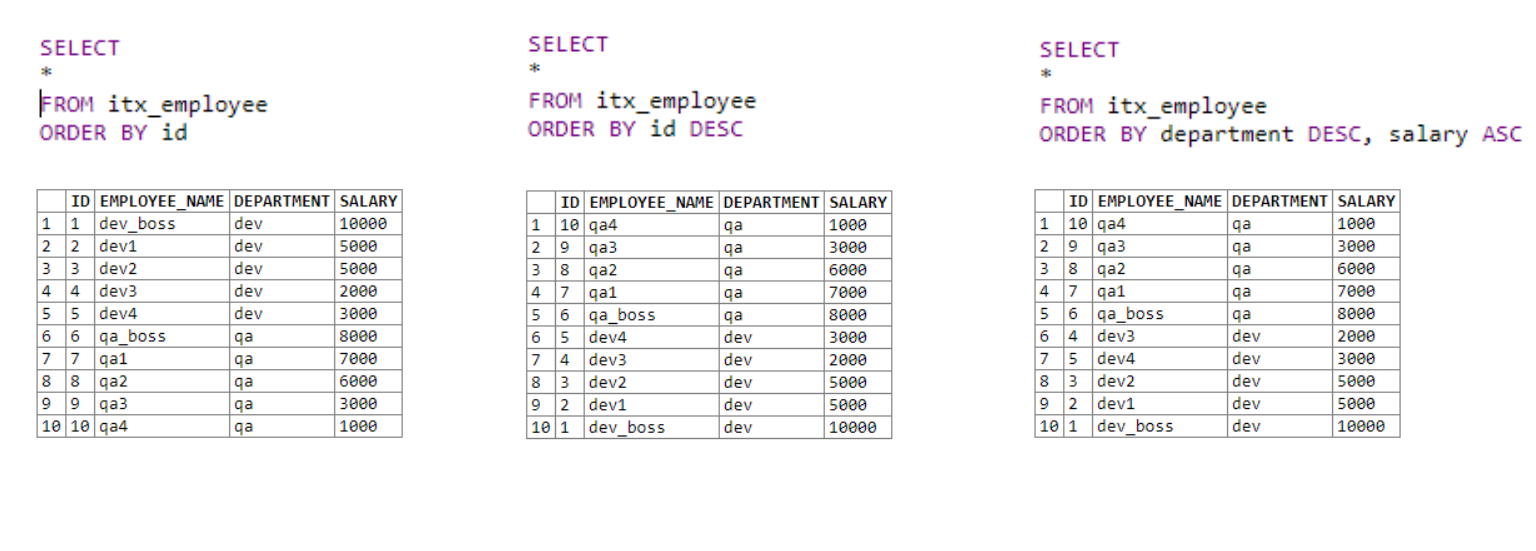
Dans le premier tableau, nous récupérons toutes les données et les trions par ordre croissant selon la colonne ID.
Dans le second, nous récupérons également toutes les données. Trier par la colonne ID dans l'ordre décroissant à l'aide du mot-clé DESC .
La troisième table utilise plusieurs champs de tri. Vient d'abord le tri par département. Si le premier opérateur est égal pour les champs du même département, la deuxième condition de tri est appliquée; dans notre cas, c'est le salaire.
C'est assez simple. Nous pouvons définir plus d'une condition de tri, ce qui nous permet de trier les listes de sortie plus intelligemment.
Par groupe
En SQL, la clause Group by collecte les données extraites d'une base de données dans des groupes spécifiques. Le regroupement divise toutes les données en ensembles logiques afin que les calculs statistiques puissent être effectués séparément dans chaque groupe.
Cet opérateur permet de combiner les résultats d'une sélection par une ou plusieurs colonnes. Après le regroupement, il n'y aura qu'une seule entrée pour chaque valeur utilisée dans la colonne.
L'utilisation de l'instruction SQL Group by est étroitement liée à l'utilisation des fonctions d'agrégation et de l'instruction SQL Have. Une fonction d'agrégation en SQL est une fonction qui renvoie une valeur unique sur un ensemble de valeurs de colonne. Par exemple: COUNT (), MIN (), MAX (), AVG (), SUM ()
Syntaxe:
SELECT nom_colonne (s)
FROM nom_table
WHERE condition
GROUP BY nom (s) colonne (s)
ORDER BY nom (s) colonne;
Group by apparaît après la clause WHERE conditionnelle dans la requête SELECT . Vous pouvez éventuellement utiliser ORDER BY pour trier les valeurs de sortie.
Donc, sur la base du tableau de l'exemple précédent, nous devons trouver le salaire maximum des employés de chaque département. L'échantillon final doit inclure le nom du département et le salaire maximum.
Solution 1 (sans utiliser le regroupement):
SELECT DISTINCT
ie.department
ie.slary
FROM itx_employee ie
WHERE ie.salary = (
SELECT
max(ie1.salary)
FROM itx_employee ie1
WHERE ie.department = ie1.department
)
Solution 2 (en utilisant le regroupement):
SELECT
department,
max(salary)
FROM itx_employee
GROUP BY department
Dans le premier exemple, nous résolvons le problème sans utiliser de regroupement, mais en utilisant une sous-sélection, i.e. mettez le second dans une sélection. Dans la deuxième solution, nous utilisons le regroupement.
Le deuxième exemple est plus court et plus lisible, bien qu'il remplisse les mêmes fonctions que le premier.
Comment Group by fonctionne pour nous: commence par diviser deux départements en groupes QA et dev. Ensuite, il cherche le salaire maximum pour chacun d'eux.
Ayant
Avoir est un outil de filtrage. Il indique le résultat de l'exécution des fonctions d'agrégation. La clause Have est utilisée dans SQL où WHERE ne peut pas être utilisé.
Si la clause WHERE définit un prédicat pour filtrer les lignes, alors Have est utilisé après le regroupement pour définir un prédicat logique qui filtre le groupe en fonction des valeurs des fonctions d'agrégation. La clause est nécessaire pour tester les valeurs obtenues à l'aide de fonctions d'agrégation à partir de groupes de lignes.
Syntaxe:
SELECT nom_colonne (s)
FROM nom_table
WHERE condition
GROUP BY nom (s) colonne (s)
HAVING condition
Tout d'abord, nous affichons les départements avec un salaire moyen supérieur à 4000. Ensuite, nous affichons le salaire maximum par filtrage.
Solution 1 (sans utiliser GROUP BY et HAVING):
SELECT DISTINCT
ie.department AS "DEPARTMENT",
(
(SELECT
AVG(ie1.salary)
FROM itx_employee ie1
WHERE ie1.department = ie.department)
) AS "AVG SALARY"
FROM itx_employee ie
where (SELECT
AVG(ie1.salary)
FROM itx_employee ie1
WHERE ie1.department = ie.department) > 4000
Solution 2 (en utilisant GROUP BY et HAVING):
SELECT
department,
AVG(salary)
FROM itx_employee
GROUP BY department
HAVING AVG(salary) > 4000
Le premier exemple utilise deux sous-sélections, l'une pour trouver le salaire maximum et l'autre pour filtrer le salaire moyen. Le deuxième exemple, encore une fois, est beaucoup plus simple et concis.
Demande de plan
Il arrive souvent qu'une requête s'exécute pendant une longue période, consommant d'importantes ressources de mémoire et de disques. Pour comprendre pourquoi une requête est longue et inefficace, nous pouvons examiner le plan de requête.
Un plan de requête est le plan d'exécution prévu pour une requête, c'est-à-dire comment le SGBD l'exécutera. Le SGBD notera toutes les opérations qui seront effectuées dans la sous-requête. Après avoir tout analysé, nous serons en mesure de comprendre où se trouvent les faiblesses de la requête et en utilisant le plan de requête, nous pouvons les optimiser.
L'exécution de toute instruction SQL dans Oracle récupère ce que l'on appelle le "plan d'exécution". Ce plan d'exécution de requête est une description de la manière dont Oracle va extraire les données en fonction de l'instruction SQL en cours d'exécution. Un plan est un arbre qui contient l'ordre des étapes et la relation entre elles.
Les outils qui vous permettent d'obtenir le plan d'exécution estimé d'une requête sont Toad, SQL Navigator, PL / SQL Developer , etc. Ils donnent un certain nombre d'indicateurs de la consommation de ressources d'une requête, parmi lesquels les principaux sont: coût - coût d'exécution et cardinalité (ou lignes ) - cardinalité (ou quantité) lignes).
Plus la valeur de ces indicateurs est élevée, moins la requête est efficace.
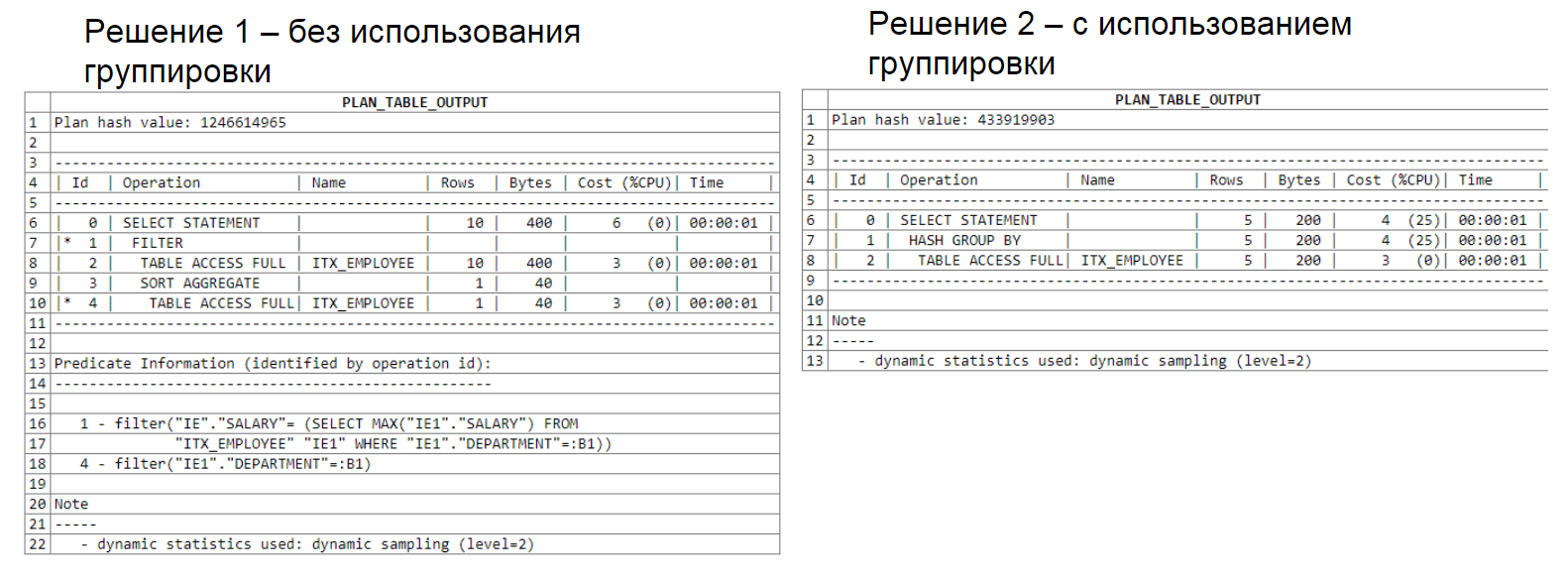
Ci-dessous vous pouvez voir l'analyse du plan de requête. La première solution utilise une sous-sélection, la seconde utilise un regroupement. Notez que la première solution a traité 22 lignes, la seconde en a traité 15.
Analyse du plan de requête:
Une autre analyse du plan de requête qui utilise deux sous-sélections:
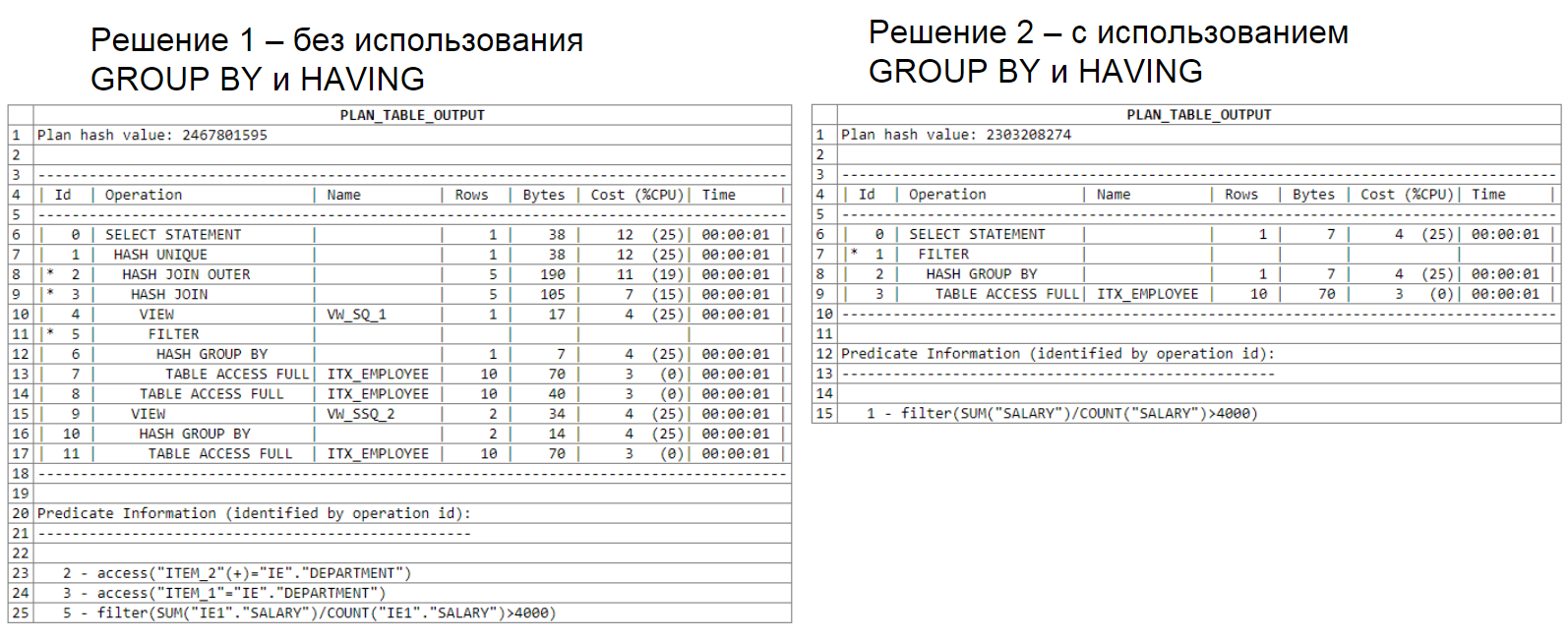
Cet exemple est présenté comme une variante d'utilisation inefficace des outils SQL et je ne vous recommande pas de l'utiliser dans vos requêtes.
Toutes les fonctionnalités ci-dessus vous faciliteront la vie lors de l'écriture de requêtes et augmenteront la qualité et la lisibilité de votre code.
Partie 2: Fonctions de la fenêtre
Les fonctions de fenêtre remontent à Microsoft SQL Server 2005. Elles effectuent des calculs sur une plage de lignes donnée dans une clause Select. En bref, une "fenêtre" est un ensemble de lignes à l'intérieur desquelles un calcul a lieu. "Window" vous permet de réduire les données et de mieux les traiter. Cette fonctionnalité vous permet de diviser l'ensemble de données en fenêtres.
Le fenêtrage a un énorme avantage. Il n'est pas nécessaire de créer un ensemble de données pour les calculs, ce qui vous permet d'enregistrer toutes les lignes de l'ensemble avec leur ID unique. Le résultat des fonctions de fenêtre est ajouté à la sélection résultante dans un autre champ.
Syntaxe:
SELECT nom_colonne (s)
Fonction d'agrégation (colonne pour les calculs)
OVER ([ PARTITION BYcolonne à grouper]
FROM nom_table
[ ORDER BY colonne à trier]
[ expression ROWS ou RANGE pour restreindre les lignes dans un groupe])
OVER PARTITION BY est une propriété permettant de définir la taille de la fenêtre. Ici, vous pouvez spécifier des informations supplémentaires, donner des commandes de service, par exemple, ajouter un numéro de ligne. La syntaxe de la fonction de fenêtre s'intègre parfaitement dans la sélection de colonne.
Regardons tout avec un exemple: un autre département a été ajouté à notre tableau, il y a maintenant 15 lignes dans le tableau. Nous essaierons de retirer les employés, leur salaire, ainsi que le salaire maximum de l'organisation.
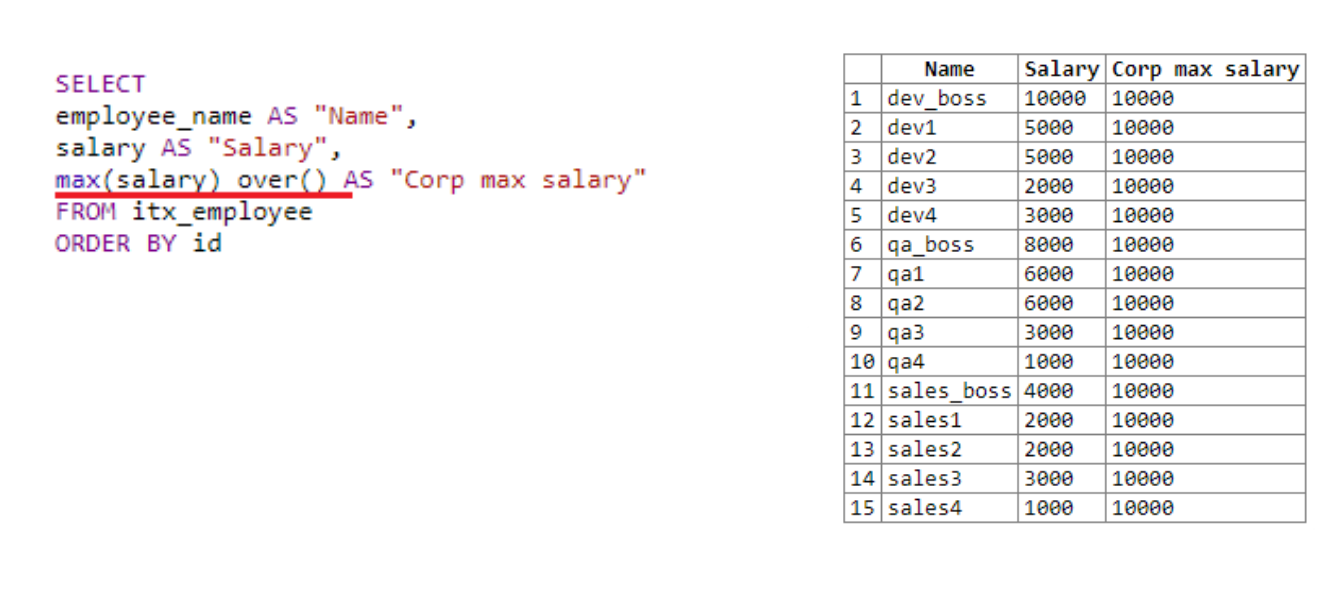
Dans le premier champ, nous prenons le nom, dans le second - le salaire. Ensuite, nous utilisons la fonction window sur ()... Nous l'utilisons pour obtenir le salaire maximum dans toute l'organisation, car la taille de la «fenêtre» n'est pas indiquée. Over () avec des parenthèses vides s'applique à toute la sélection. Par conséquent, partout le salaire maximum est de 10 000. Le résultat de l'action de la fonction fenêtre est ajouté à chaque ligne.
Si nous supprimons la mention de la fonction de fenêtre de la quatrième ligne de la requête, c'est-à-dire seul le max (salaire) reste , la demande ne fonctionnera pas. Le salaire maximum ne pouvait tout simplement pas être calculé. Étant donné que les données seraient traitées ligne par ligne et qu'au moment de l'appel de max (salaire), il n'y aurait qu'un seul numéro dans la ligne courante, c'est-à-dire employé actuel. C'est ici que vous pouvez voir l'avantage de la fonction de fenêtre. Au moment de l'appel, il fonctionne avec toute la fenêtre et avec toutes les données disponibles.
Regardons un autre exemple où vous devez afficher le salaire maximum de chaque département:
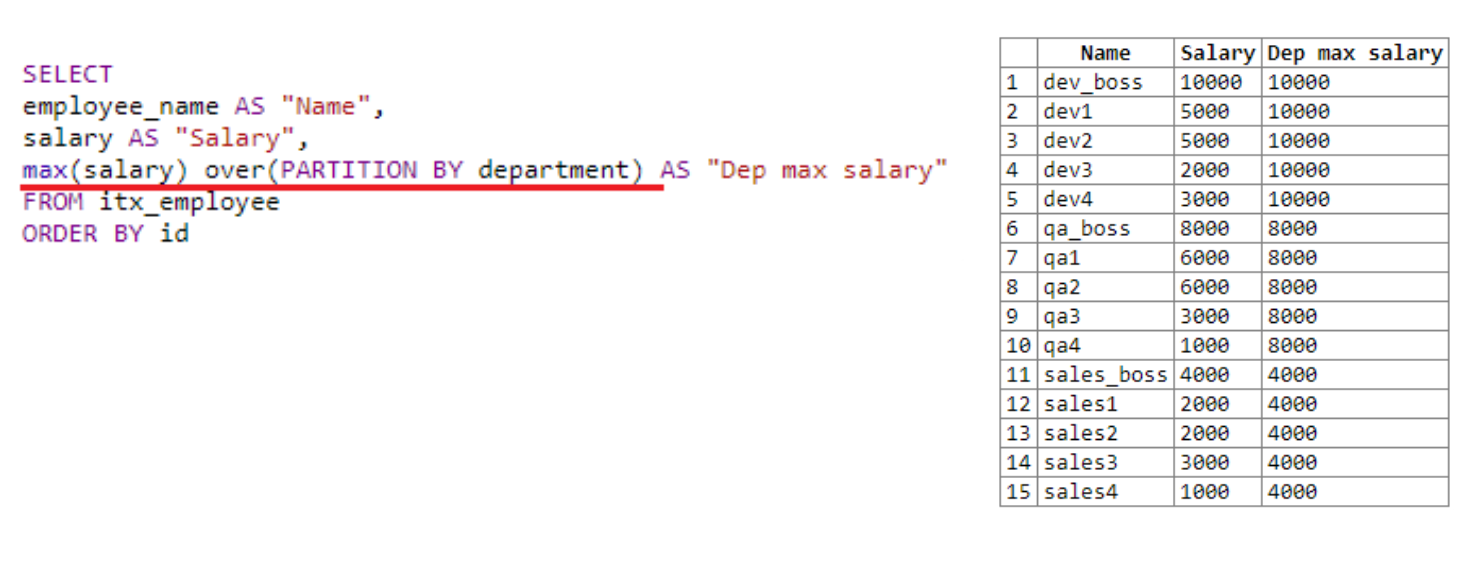
En fait, nous définissons le cadre de la "fenêtre", en le divisant en départements. Nous utilisons le département comme exemple de classement. Nous avons trois départements: dev, qa et ventes.
"Window" trouve le salaire maximum pour chaque département. À la suite de la sélection, nous voyons qu'il a trouvé le salaire maximum d'abord pour dev, puis pour qa, puis pour les ventes. Comme mentionné ci-dessus, le résultat de la fonction de fenêtre est écrit dans le résultat de l'extraction de chaque ligne.
Dans l'exemple précédent, les parenthèses après over n'étaient pas spécifiées. Ici, nous avons utilisé PARTITION BY, ce qui nous a permis de définir la taille de notre fenêtre. Ici, vous pouvez spécifier des informations supplémentaires, envoyer des commandes de service, par exemple, le numéro de ligne.
Conclusion
SQL n'est pas aussi simple qu'il y paraît à première vue. Tout ce qui est décrit ci-dessus est la fonctionnalité de base des fonctions de fenêtre. Avec leur aide, vous pouvez «simplifier» nos demandes. Mais il y a beaucoup plus de potentiel caché en eux: il y a des opérateurs utilitaires (par exemple ROWS ou RANGE) qui peuvent être combinés pour ajouter plus de fonctionnalités aux requêtes.
J'espère que l'article a été utile à tous ceux qui s'intéressent à ce sujet.