
La version complète de deux heures peut être visionnée sur la chaîne YouTube Hexlet .
Table des matières:
historique du produit et de l'entreprise
Comment fonctionne le développement de produits
Sélection et évolution de la technologie
- Flash → Toile
- Angulaire → Réagir
- Serveurs et bases de données
- Java
- Évolution des tests
- Croissance de la charge et refactoring
Processus en développement
- Solution technique et révision du code
- Revue de la performance
- Comment fonctionne l'embauche des ingénieurs
- Postes juniors
Histoire du produit et de l'entreprise
Miro est une plateforme de tableau blanc collaboratif en ligne pour la collaboration visuelle. Le mot clé est respectivement collaboration, collaboration, les indicateurs clés par lesquels nous mesurons notre efficacité sont le nombre de tableaux de collaboration et de sessions collaboratives qui se produisent dans le produit.
Nous nous appelons une plate-forme parce que nous sommes déjà allés au-delà d'un simple produit: nous avons une API ouverte, une place de marché, un bureau de développement, de sorte que toute entreprise peut développer le produit pour elle-même.
Notre public cible est constitué d'équipes de produits qui opèrent à partir du même bureau ou de bureaux différents. Le plus souvent, Miro est utilisé pour conduire des ateliers, des sessions stratégiques, des brainstormings, des pratiques agiles (planning, rétrospectives).

Je dirige le développement chez Miro. J'ai grandi à Perm et je continue à vivre ici. Historiquement, l'entreprise est apparue à Perm, d'où viennent nos fondateurs. La plupart de notre département de développement est maintenant là, et en 2019, nous avons lancé et développons activement un deuxième bureau d'ingénierie - à Amsterdam.
Auparavant, j'ai travaillé dans le développement sur mesure: j'ai commencé par construire des entrepôts de données analytiques en tant que développeur, puis je les ai conçus, puis j'ai mené de grands projets. En 2016, il a rejoint Miro alors que l'entreprise employait 30 personnes. Depuis, nous avons beaucoup grandi: nous avons maintenant cinq bureaux, 400 personnes, dont 140 ingénieurs.
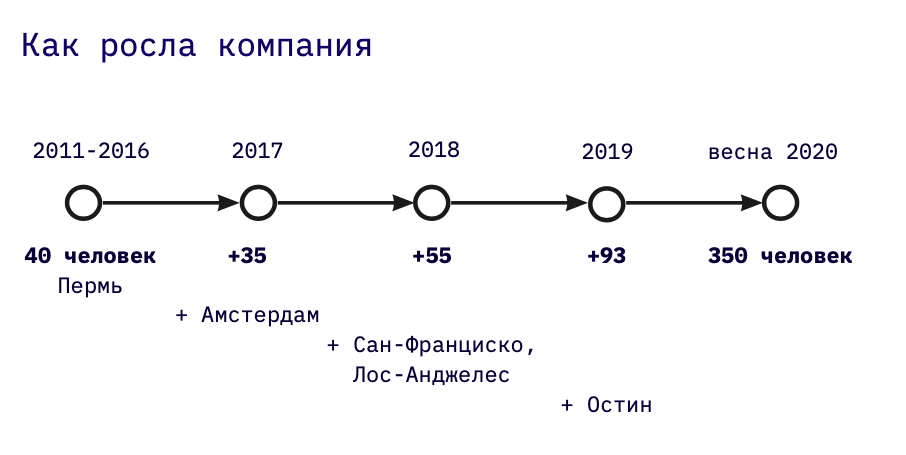
L'entreprise a été fondée en 2011. Notre principale fonction était et reste le développement de produits, qui représente aujourd'hui environ la moitié de l'entreprise.
Changement de nom
Nous avons pensé à changer de marque en 2015, mais nous avons fini par le faire en 2018. Notre ancien nom RealtimeBoard est long et complexe. Il était souvent erroné, abrégé en RTB ou, pire que tout, complètement oublié. De plus, c'est sans émotion, il n'y a pas d'histoire derrière. Nous voulions rendre le nouveau nom court, vaste, parlant, mémorable.
En conséquence, nous nous sommes inspirés des œuvres de l'artiste Joan Miró et avons choisi son nom de famille comme titre. La recherche proprement dite et le choix du nom ont pris plusieurs mois, puis quelques mois de plus nous avons lancé une nouvelle marque. À la suite de ce projet, il y a une série d'articles sur la façon dont le travail sur le projet a été organisé, et un article séparé sur un petit problème technique mais non trivial pour la migration transparente des utilisateurs autorisés de l'ancien vers le nouveau domaine.
Nous et les utilisateurs nous sommes rapidement habitués au nouveau nom. Nous grandissons rapidement, donc plusieurs millions de nouveaux utilisateurs ne savent même pas que nous avons été appelés différemment. Un joli bonus du changement de marque a été les récompenses des European Design Awards pour l'identité, que nous avons développées dans le cadre du changement de marque avec l'agence européenne Vruchtvlees .
Comment fonctionne le développement de produits dans Miro
Toute l'équipe de développement de produits de 170 personnes est située à Perm et Amsterdam: ingénieurs, produits, concepteurs de produits, scrum masters.
Auparavant, il était difficile pour moi d'imaginer que tant de personnes puissent travailler sur un seul produit. Mais aujourd'hui, je sais que des milliers d'ingénieurs travaillent sur le même produit chez Uber, Slack et Atlassian. Nous continuons à grandir et comprenons que nous ne sommes manifestement pas assez maintenant, et le prochain objectif dans ma tête est de 300 personnes en développement, puis nous continuerons à grandir. Ce n'est pas seulement un chiffre qui vous sort de la tête. Nous avons une planification stratégique, nous comprenons où nous voulons en être dans deux ans, dans cinq ans, et ce que nous devons faire pour cela.
En termes de structure organisationnelle, il existe des guildes: frontend, backend, QA, etc. Pour travailler sur des projets, ils sont regroupés dans des équipes transverses.
Les équipes sont réparties dans des domaines clés:
- Un produit horizontal est la principale fonctionnalité du produit que tous les utilisateurs voient: autocollants, texte, formes, cadres, etc.
- Direction des systèmes - responsable de la plate-forme et de l'infrastructure de base.
- La croissance consiste à augmenter le nombre d'utilisateurs: activation, engagement, retour, monétisation.
- Enterprise — , . -, Miro, . -, SaaS-, . , , .
- — 2019 . API, , marketplace, — , , .
- — , . , , , Miro, : Meetings & Workshops, Ideation & Brainstorming, Research & Design, Agile Workflows, Strategy & Planning, Mapping & Diagramming.
: , , . , . , : - .
Les principaux logiciels des ingénieurs: IntelliJ Idea, Jira, Slack, Zoom, Miro, Confluence. La plupart des employés travaillent sur des MacBook, la plupart des ingénieurs travaillent sur des MacBook Pro, pour certains nous achetons des machines plus puissantes si nécessaire.
Nous utilisons notre propre produit au quotidien: réunions internes, ateliers, brainstorming, planning.Cela vous permet de tester rapidement toutes les innovations du produit et simplifie grandement l'adaptation des nouveaux développeurs qui, dès le premier jour, travaillent avec le produit non seulement en termes de code, mais aussi en tant qu'utilisateurs. C'est une partie importante de notre culture - nous fabriquons un produit que nous devrions nous-mêmes être confortable et agréable à utiliser.
Pile, monolithe
Le front est Typescript, React et AngularJS. Le backend est Java. Bases de données - Redis, Postgres, pour la communication de cluster - Hazelcast et ActiveMQ. Nous hébergeons sur Amazon, dans le même centre de données. Il y a environ 400 serveurs en production. Les serveurs d'applications qui traitent les cartes utilisateurs peuvent être jusqu'à 100, tout est orchestré automatiquement.
Nous utilisons une pile d'Atlassian: Jira, Bitbucket, Bamboo et nos propres scripts qui sont boulonnés à Bamboo et permettent que tout soit déployé sur les serveurs. Jusqu'à présent, toutes les versions sont une grande version avant et une grande version arrière. Maintenant, nous réfléchissons à la façon de faire plus de ces versions.
Notre application principale est un monolithe modulaire: il existe un module qui est responsable de l'API, de la carte, de la fonction de service. Le monolithe est déployé en modules sur les serveurs requis, et non en un seul gros morceau sur tous les serveurs d'affilée, c'est-à-dire que nous avons également des serveurs avec des rôles différents.
Au sein de l'application, il existe de nombreuses intégrations et services supplémentaires que nous avons immédiatement effectués séparément et que les équipes publient indépendamment séparément du reste de l'avant et de l'arrière.
Lorsque vous avez une petite entreprise, il est beaucoup plus facile de commencer avec un monolithe et de ne pas clôturer l'infrastructure pour les services. Mais maintenant, nous en sommes venus à comprendre qu'un monolithe commun ne nous donne pas la possibilité de mettre à l'échelle des directions individuelles (produit horizontal, plate-forme, entreprise, etc.), nous développons donc une approche pour laisser un seul monolithe.
Communiqués
L'assemblage lui-même prend 15 à 20 minutes, y compris l'exécution de tests unitaires. Les tests de bout en bout peuvent prendre jusqu'à 40 minutes. L'ensemble du processus prend une heure et demie à deux heures pour amener le maître à sortir. Cela fait longtemps, nous avons encore quelque chose à travailler ici.
Il est probablement idéal de sortir toutes les cinq minutes. Mais pour cela, nous n'avons pas encore une équipe aussi nombreuse ni un public quotidien aussi large. Un large public est important pour les versions fréquentes, car cela vous permet de vous assurer rapidement que tout va bien en déployant les modifications à une petite proportion d'utilisateurs.
Sélection et évolution de la technologie
Je pense que le choix de la technologie doit être traité comme ceci: peu importe ce que vous choisissez, vous devez encore le changer un jour, surtout si l'entreprise et le produit grandissent. Par conséquent, le processus de changement des technologies est normal. La technologie est importante, mais elle doit être traitée différemment à différentes étapes du développement d'une entreprise.
Les petites entreprises qui débutent et recherchent des produits adaptés au marché fonctionnent rapidement, créent des MVP rapidement et les rejettent rapidement. Trouver un marché est plus important pour eux que de créer des solutions techniques complexes. Mais lorsque le marché est trouvé, les solutions techniques apparaissent, car elles permettent de créer une marge de sécurité pour la croissance et la sécurité.
Nous essayons d'abord de comprendre le problème que nous voulons résoudre en changeant les technologies. Ensuite, nous faisons beaucoup de recherches, explorons des alternatives, testons les performances. Cela se fait avec toutes les solutions techniques que nous allons mettre en œuvre: «ne prenez pas la première chose dont vous avez entendu parler pour la première fois sur le marché, mais recherchez et étudiez ce qui est le mieux adapté pour résoudre le problème».
Dans un grand produit et une équipe, un changement de technologie est une décision stratégique importante; il peut conduire à un arrêt partiel ou complet du développement produit, à un basculement des équipes vers de nouvelles tâches, etc. C'est long et coûteux, mais si cela n'est pas fait à temps, les problèmes qui apparaissent peuvent apporter beaucoup plus de difficultés.
Nous avons eu quelques grands changements technologiques, à l'avant et à l'arrière. Voici quelques exemples.
Flash → Toile
Jusqu'en 2015, tout le front était sur Flash, puis Flash a commencé à mourir et nous sommes passés à HTML et Canvas. Le changement de pile a eu un bon effet sur les performances et la convivialité du produit, et a conduit à une augmentation notable de l'audience. La transition a pris environ un an, c'était un projet vaste et complexe. Un article sur les détails de ce projet .
Nous envisageons actuellement de migrer vers WebGL, mais il n'y a pas encore de preuve claire que cela en vaut la peine.
Angulaire → Réagir
Au cours des deux dernières années, nous sommes progressivement passés d'Angular JS à React. Raisons principales:
- React permet une meilleure saisie, et plus tard, il vous permet de mieux refactoriser votre code et garantit que rien ne tombe.
- React . «» , Angular . Angular, React, .
- React , Angular JS .
En 2015, nous sommes passés des serveurs loués Hetzner à l'hébergement Amazon. Depuis plus d'un an, il y a eu un projet de migration de la base de données principale de Redis vers PostgreSQL. Nous avons des articles à ce sujet: gestion de projet de migration de données , création d'un cluster de basculement .
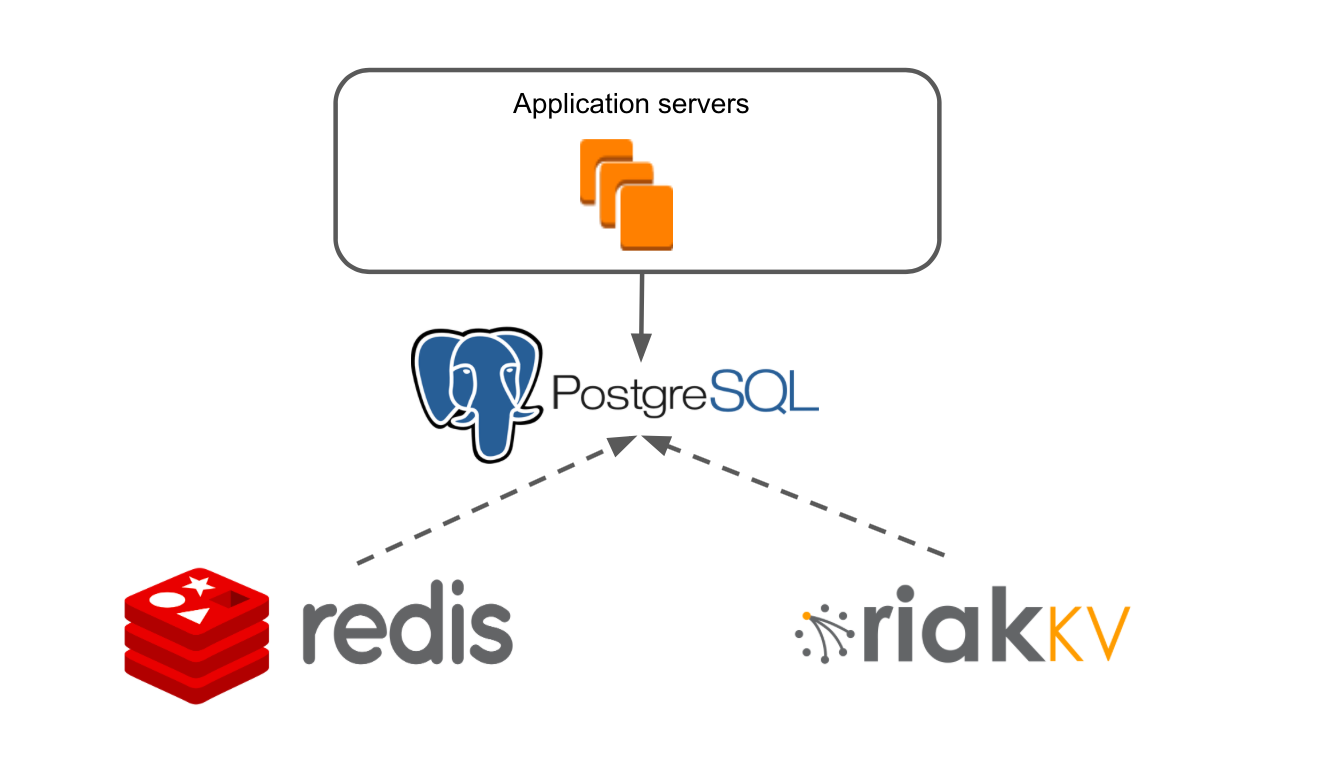
Notre cas est compliqué par le fait qu'à partir de la valeur clé du stockage, nous passons à une base de données SQL. Il y a beaucoup de refactoring. Il est important de tout faire pour que l'application ne s'arrête pas. C'est comme changer la roue d'une voiture en mouvement, car la base de données est la base sur laquelle repose l'application. Pour le contenu des tableaux, nous avons en fait tout fait sans maintenance. Oui, le processus de transition a été retardé, mais les utilisateurs n'ont rien remarqué, le produit a fonctionné.
La stabilité du produit est un objectif clé. Les utilisateurs stockent beaucoup de contenu dans Miro. Par conséquent, si un utilisateur a programmé une session ou une réunion, préparé un tableau de contenu pour celle-ci et que le produit n'est pas disponible à ce moment, il s'agit d'un échec, le contenu ne peut pas être utilisé. Bien que le zoom conditionnel puisse être rapidement remplacé par des Hangouts, le contenu ne peut pas être remplacé rapidement. Par conséquent, l'une de nos principales tâches est de garantir que le contenu pour les utilisateurs est toujours disponible.
Java
Java nous aide énormément en termes de productivité et de ressources de développement que nous pouvons trouver. Je sais que Booking passe de Pearl à Java car ils en ont assez de recycler leurs ingénieurs.
Les ingénieurs de C ++ et .Net viennent chez nous et s'adaptent normalement. Si vous êtes un développeur expérimenté, avez essayé différentes technologies et savez comment le système est construit, il n'est pas si difficile de plonger dans un nouveau langage. L'essentiel est que l'ingénieur propose les bonnes solutions, et il pourra certainement s'enfoncer dans la langue, j'y crois.
Évolution des tests
Au départ, nous n'avions que des tests manuels. Les versions ont été déployées toutes les deux à trois semaines, la préparation de la publication a pris une semaine: vous effectuez des tests de régression en quelques jours → trouvez les bogues critiques → corrigez → testez à nouveau manuellement. Quand il y avait plusieurs équipes, cela fonctionnait, mais avec vingt équipes, il est impossible de tout tester manuellement.
Nous avons donc commencé à penser à l'automatisation. Tout d'abord, nous avons écrit des autotests pour nous débarrasser complètement des tests de régression. Nous travaillons maintenant à la mise en place de processus de gestion de la qualité corrects tout au long du cycle de développement. Plus tôt nous pensons à la qualité, plus tôt nous trouverons les cas de pointe, comprendreons comment les tester - cela réduira au final le coût et accélérera le processus de développement. Un bogue que vous trouvez en vente ne vaut pas seulement le temps et les ressources nécessaires pour annuler la version et la corriger. Le bogue affecte l'expérience utilisateur globale du produit et il est très coûteux de corriger cette expérience.
Nous avons une guilde QA, dans laquelle les ingénieurs prennent des décisions sur les processus que nous devons mettre en œuvre maintenant, développent une stratégie qualité, puis chaque ingénieur QA aide ses équipes à mettre en œuvre ces processus par eux-mêmes:
- QA- -, . QA , . .
- QA , .
- QA , , .
Les versions Canary sont également un moyen de tester, lorsque nous déployons une fonctionnalité auprès d'un petit public et vérifions si nous avons manqué quelque chose. Nous lançons de nouvelles fonctionnalités importantes via des cases à cocher, déployons pour les utilisateurs bêta qui ont exprimé le désir de participer à des tests bêta (nos chefs de produit en apprendront plus lors des entretiens de recherche). Le nombre d'utilisateurs bêta et alpha inclut nécessairement nos équipes, nous déployons absolument toutes les nouvelles fonctionnalités pour nous-mêmes en premier lieu.
Une description détaillée de toutes les étapes de notre processus d'assurance qualité .
Croissance de la charge et refactoring
En raison du passage massif au télétravail en 2020, notre base d'utilisateurs a grimpé en flèche, et notre infrastructure annuelle et la résilience des applications se sont épuisées en quelques semaines. Dans la toute première semaine d'une forte augmentation de la charge, nous avons arrêté tout développement produit et réorienté les équipes pour qu'elles travaillent sur la tolérance aux pannes et les performances.
La marge de sécurité était nécessaire non seulement sur le backend, mais également sur le frontend et le client, car le nombre de travaux synchrones augmentait dans le produit. Si auparavant 20 personnes pouvaient travailler sur un seul conseil d'administration en même temps, maintenant c'est 300 personnes. Nos ingénieurs frontaux ont fait beaucoup et continuent de s'attaquer aux performances de charge. Par exemple, nous faisons en sorte que le tableau de bord avec la liste des tableaux se charge séparément de tout le reste et le faisons plus rapidement qu'auparavant. Et si l'utilisateur accède directement au tableau, et non via le tableau de bord, le code et le contenu du tableau doivent être chargés, sans tout le reste.
Nous allons beaucoup refactoriser afin que l'utilisateur reçoive plus rapidement les commentaires et le contenu du tableau, puis toutes les fonctionnalités principales - les scripts, l'interface - montent lentement. Pour ce faire, nous sommes passés à la division du code en modules «paresseux». Grâce à cela, nous avons accéléré d'environ un tiers, et le mois prochain, nous prévoyons d'accélérer encore deux fois en termes de chargement.
C'est la même chose en termes de performances sur la carte - il y a une guerre sur la vitesse et les ressources sur l'ordinateur sur lequel l'utilisateur s'exécute.Tout le monde n'est pas allé en ligne avec de bonnes machines; quelqu'un a sorti un vieil ordinateur portable à faible performance de l'étagère. Mais notre produit devrait bien fonctionner sur n'importe quel ordinateur portable. C'est un autre gros truc sur lequel nous travaillons beaucoup en ce moment.
Processus en développement
Solution technique et révision du code
Toute tâche commence par la préparation d'une solution produit. Une solution produit est une réponse à la question «Que va-t-on faire?». Un chef de produit basé sur la stratégie produit et les OKR effectue de nombreuses recherches pour découvrir ce qui manque actuellement aux utilisateurs dans notre produit. Sur la base de la recherche, le produit décrit la solution. La guilde alimentaire discute de la solution, la révise si nécessaire.
Sur la base d'une solution produit, une solution technique est formée qui répond à la question "Comment allons-nous faire cela?" Il est développé par les ingénieurs de l'équipe qui implémentera la fonctionnalité. La solution technique passe par plusieurs processus de revue:
- avec des équipes avec lesquelles il y a des intersections dans la fonctionnalité;
- revue de sécurité des composants que nous aborderons dans l'architecture;
- comment nous allons déployer le résultat.
Après cela, le développement commence directement. Il est important que la révision du code ne ralentisse pas le développement, donc récemment, au lieu d'avoir à recevoir deux révisions de code, nous avons introduit la responsabilité personnelle au niveau des composants. Désormais, au niveau du code, on sait toujours qui est responsable de cette pièce, ce qui facilite grandement la communication lors du développement. Ainsi, dès que vous avez apporté des modifications au code, le réviseur est automatiquement affecté, propriétaire de ce code. Si le code vous appartient, la révision est effectuée par un membre de votre équipe.
Pourquoi avons-nous introduit la responsabilité personnelle? Auparavant, il y avait quelques personnes, des "anciens", qui savaient comment tout le produit fonctionnait et pouvaient vérifier n'importe quel morceau de code. Mais à mesure que le produit se développait, les capacités de ces personnes commençaient à faire défaut, elles ne pouvaient plus savoir tout ce qui se passait dans le développement.Le processus de révision du code a commencé à ralentir le reste du processus, il n'était pas clair à qui s'adresser pour la révision du code. Ensuite, nous avons commencé à transmettre toutes les compétences nécessaires pour des blocs de produits spécifiques à l'équipe qui y travaille. Ainsi, les équipes ont pu effectuer elles-mêmes des revues de code. À un moment donné, cela nous a beaucoup aidé à accélérer.
Revue de la performance
L'entreprise a des notes, grâce auxquelles nous comprenons qui a quelles compétences, à quelle note correspond et, surtout, ce que chacun doit faire pour avancer. L'évaluation des performances a lieu deux fois par an, aide à capturer une image de la situation actuelle de chaque personne et à recevoir des commentaires personnalisés.
Sur la base de cette image, le chef d'équipe élabore des plans de développement personnel avec chaque membre de l'équipe: l'employé lui-même dit où il souhaite se développer, et la revue de performance met en évidence ses forces et ses lacunes.
Puis, régulièrement, une fois toutes les une à deux semaines, le chef d'équipe et l'employé tiennent des réunions 1: 1, où, entre autres, ils discutent et suivent le mouvement dans la direction prévue. Dans un an et demi, sur la base des résultats de ce mouvement, il y a une augmentation de grade et de salaire.
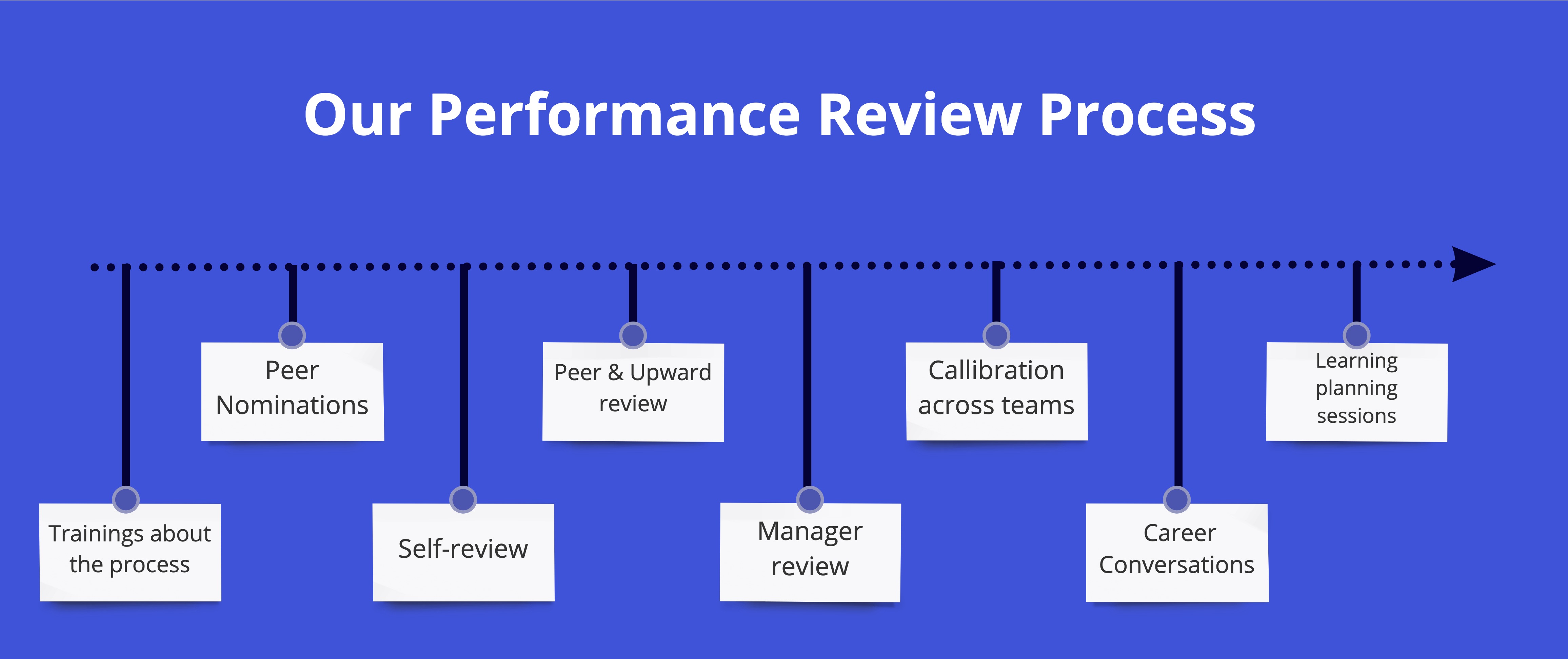
Tout est exactement pareil avec les chefs d'équipe, en plus il y a une formation externe et un mentorat externe pour eux.
Malheureusement, les gens ne se développent souvent pas aussi vite que l'entreprise - ce n'est pas grave. Nous sommes prêts à investir beaucoup dans la formation, car la croissance d'une entreprise dépend directement de la croissance des employés. Nous avons une rémunération pour les cours externes, nous avons recommandé des cours et des mentors. Nous compensons la formation obligatoire à 100% (par exemple, en anglais), nous essayons de compenser le reste 50 à 50, de sorte qu'il y ait une responsabilité mutuelle pour les résultats.
Nous allons rarement aux conférences. Nous essayons de choisir ceux qui parlent de technologies et de cas qui nous concernent en ce moment et pour lesquels nous n'avons pas suffisamment de connaissances.
Comment fonctionne l'embauche des ingénieurs
Notre chaîne de recrutement est standard pour la Russie et l'Europe. En Russie, l'entonnoir de recrutement est déjà étroit, de sorte que le premier entretien peut être mené non pas par un recruteur, mais immédiatement par un responsable du recrutement (généralement le chef d'équipe de l'équipe dans laquelle nous embauchons une personne) après que le recruteur a traité le CV et éliminé les postes vacants qui ne correspondent pas aux exigences.
J'ai le sentiment qu'en Russie, beaucoup moins d'ingénieurs recherchent activement du travail, par rapport à l'Europe, parce qu'ils ne veulent pas prendre de risques. Et lorsque de nombreuses entreprises sont entrées dans la zone à risque en raison de l'isolement, les gens sont devenus encore moins enclins à prendre des risques et à changer d'emploi.
Quoi qu'il en soit, la chaîne de recrutement commence par un entretien téléphonique de sélection avec un candidat, qui est mené par un recruteur ou un responsable du recrutement. Le but de la présélection est de comprendre rapidement comment un candidat répond aux exigences clés du poste vacant.
Après le dépistage, une tâche de test, puis un entretien technique, qui comprend, entre autres, une discussion sur la tâche de test. Ensuite - une réunion avec l'équipe dans laquelle le candidat travaillera. Pour nous, il s'agit d'une étape obligatoire, car elle permet tout d'abord de comprendre la culture du candidat, et non ses compétences techniques.
Après tous les entretiens, nous recueillons les commentaires des participants, faisons une offre.
Pour évaluer les tâches de test, nous utilisons un système de points, puis nous classons les résultats et voyons ainsi les meilleurs résultats. Dans les postes supérieurs, nous annulons parfois une tâche de test si le candidat dispose d'un bon référentiel public.
Postes juniors
Avant de passer au travail à distance, nous avons commencé à travailler avec des spécialistes juniors: nous avons embauché des Juns, diplômés, mais pas très activement. Maintenant, nous avons complètement gelé cette histoire, car il est très difficile de les intégrer à un endroit éloigné, et nous avons très peu d'expérience dans ce domaine jusqu'à présent. Par conséquent, nous nous concentrons sur les intermédiaires avec au moins 3-4 ans d'expérience.
Mais même lorsque nous avons travaillé avec les Juns, il était important pour nous qu'ils puissent atteindre les niveaux intermédiaires en un an, afin qu'ils apprennent et s'adaptent très rapidement.
Exigences de recrutement élevées
Il y a une légende selon laquelle il nous est très difficile de trouver un emploi en raison des exigences très élevées. Ce n'est pas entièrement vrai.
Nous sommes souvent interviewés par des candidats occupant le poste de chef d'équipe, qui, selon nos critères internes, sont intermédiaires. Cela se produit parce que, à la recherche de postes, ils se tournent vers des entreprises qui sont prêtes à donner des postes supérieurs à leurs compétences actuelles en plusieurs étapes, juste pour embaucher une personne. En conséquence, le résultat est un mauvais service: la personne n'a pas encore pompé au niveau requis, mais elle occupe déjà une position élevée; alors il ne pourra guère quitter l'entreprise, car il ne sera pas embauché pour le même poste dans d'autres entreprises.
Le plus gros bloqueur de l'embauche est l'anglais. Auparavant, nous pouvions embaucher sans connaissance de l'anglais, mais maintenant c'est impossible, et il est impossible de le pomper en quelques mois: un ingénieur dès les premières semaines de travail devra lire la documentation en anglais, correspondre en anglais avec des collègues, assister aux assemblées générales, dont la plupart se tiennent en anglais Langue.
Le produit se développe, de nouvelles tâches intéressantes apparaissent, nous avons donc toujours beaucoup de postes vacants en ingénierie à Perm et à Amsterdam.