
salut! Notre société traite depuis longtemps le problème de la protection contre les attaques DDoS et, au cours de ce travail, j'ai réussi à me familiariser avec les domaines connexes de manière suffisamment détaillée - pour étudier les principes de création de bots et comment les utiliser. En particulier, le web scraping, c'est-à-dire la collecte massive de données publiques à partir de ressources Web à l'aide de robots.
À un moment donné, ce sujet m'a fasciné par une variété de problèmes appliqués dans lesquels le grattage est utilisé avec succès. Il faut noter ici que le «côté obscur» du web scraping m'intéresse le plus, c'est-à-dire les scénarios néfastes et mauvais de son utilisation et les effets négatifs qu'il peut avoir sur les ressources web et l'activité qui leur est associée.
Dans le même temps, en raison des spécificités de notre travail, le plus souvent c'était dans de tels (mauvais) cas que nous devions plonger en détail, étudier des détails intéressants. Et le résultat de ces plongées a été que mon enthousiasme a été transmis à mes collègues - nous avons mis en œuvre notre solution pour attraper des bots indésirables, mais j'ai accumulé suffisamment d'histoires et d'observations qui seront, je l'espère, un matériau intéressant pour vous.

Je vais parler de ce qui suit:
- Pourquoi les gens se grattent-ils du tout?
- Quels sont les types et les signes d'un tel grattage;
- Quel impact cela a-t-il sur les sites Web ciblés;
- Quels outils et capacités techniques les créateurs de bots utilisent-ils pour faire du scraping?
- Comment différentes catégories de robots peuvent être détectées et reconnues;
- Que faire et que faire si le grattoir vient visiter votre site (et si vous devez faire quoi que ce soit).
Commençons par un scénario hypothétique inoffensif - imaginons que vous êtes un étudiant, demain matin vous avez une défense de votre mémoire, vous n'avez pas de cheval qui traîne à partir de matériaux, il n'y a pas de chiffres, pas d'extraits, pas de citations - et vous comprenez que pour le reste de la nuit Vous n'avez ni le temps, ni l'énergie, ni le désir de parcourir manuellement toute cette base de connaissances.
Par conséquent, sur les conseils de camarades plus âgés, vous découvrez la ligne de commande Python et écrivez un script simple qui accepte les URL en entrée, y va, charge la page, analyse le contenu, trouve des mots-clés, des blocs ou des nombres d'intérêt, les ajoute dans un fichier, ou dans l'assiette et continue.
Chargez dans ce script le nombre requis d'adresses de publications scientifiques, de publications en ligne, de ressources d'actualité - il passe rapidement en revue tout, additionnant les résultats. Il vous suffit de dessiner des graphiques et des diagrammes, des tableaux dessus - et le lendemain matin, avec l'apparition d'un gagnant, vous obtenez votre point bien mérité.
Pensons-y - avez-vous mal fait quelqu'un dans le processus? Eh bien, à moins que vous n'ayez analysé le HTML avec une expression régulière, vous n'avez probablement fait de mal à personne, et plus encore aux sites que vous avez visités de cette manière. Il s'agit d'une activité ponctuelle, elle peut être qualifiée de modeste et discrète, et presque personne n'a souffert du fait que vous êtes venu, rapidement et tranquillement saisi la donnée dont vous aviez besoin.
D'un autre côté, le referiez-vous si tout a fonctionné la première fois? Regardons les choses en face - très probablement, vous le ferez, car vous venez d'économiser beaucoup de temps et de ressources, ayant reçu, très probablement, encore plus de données que vous ne le pensiez à l'origine. Et cela ne se limite pas à la recherche scientifique, universitaire ou générale.

Parce que l'information coûte de l'argent et que les informations recueillies à temps coûtent encore plus. C'est pourquoi le grattage est une source de revenus importante pour un grand nombre de personnes. Il s'agit d'un sujet indépendant populaire: entrez et voyez un tas de commandes vous demandant de collecter des données ou d'écrire un logiciel de scraping. Il existe également des organisations commerciales qui font du scraping sur commande ou fournissent des plates-formes pour cette activité, ce que l'on appelle le scraping as a service. Une telle variété et propagation est possible, également parce que le grattage lui-même est quelque chose d'illégal, de répréhensible et ne l'est pas. D'un point de vue juridique, il est très difficile de lui reprocher - surtout pour le moment, nous découvrirons bientôt pourquoi.

Pour moi, un intérêt particulier est également le fait qu'en termes techniques, personne ne peut vous interdire de lutter contre le grattage - cela crée une situation intéressante dans laquelle les participants au processus des deux côtés des barricades ont la possibilité dans un espace public de discuter des aspects techniques et organisationnels de cette question. Pour aller de l'avant, dans une certaine mesure, l'ingénierie a pensé et impliquer de plus en plus de personnes dans ce processus.

Du point de vue des aspects juridiques, la situation que nous examinons maintenant - avec l'autorisation du grattage, n'était pas toujours la même auparavant. Si l'on regarde un peu la chronologie des procès assez connus liés au grattage, on verra que même à l'aube de son aube, la première réclamation d'eBay était contre un grattoir qui collectait des données lors des enchères, et le tribunal lui a interdit de se livrer à cette activité. Pendant les 15 années suivantes, le statu quo a été plus ou moins préservé - les grandes entreprises ont remporté des poursuites contre les grattoirs quand elles ont découvert leur impact. Facebook et Craigslist, ainsi que quelques autres entreprises, ont signalé des réclamations qui se sont terminées en leur faveur.
Cependant, il y a un an, tout a soudainement changé. Le tribunal a estimé que la plainte de LinkedIn contre la société qui avait collecté des profils publics d'utilisateurs et des CV était infondée et ignorait les lettres et les menaces exigeant l'arrêt de l'activité. Le tribunal a jugé que la collecte de données publiques, qu'il s'agisse d'un robot ou d'un humain, ne peut pas être la base d'une réclamation de la société affichant ces données publiques. Ce puissant précédent juridique a modifié l'équilibre en faveur des grattoirs et a permis à davantage de personnes de montrer, de démontrer et d'essayer leur propre intérêt dans le domaine.
Cependant, en regardant toutes ces choses généralement inoffensives, n'oubliez pas que le grattage a de nombreuses utilisations négatives - lorsque les données sont collectées non seulement pour une utilisation ultérieure, mais dans le processus, l'idée de causer des dommages au site ou à l'entreprise derrière elle est réalisée. ou tente de s'enrichir d'une manière ou d'une autre aux dépens des utilisateurs de la ressource cible.
Regardons quelques exemples emblématiques.

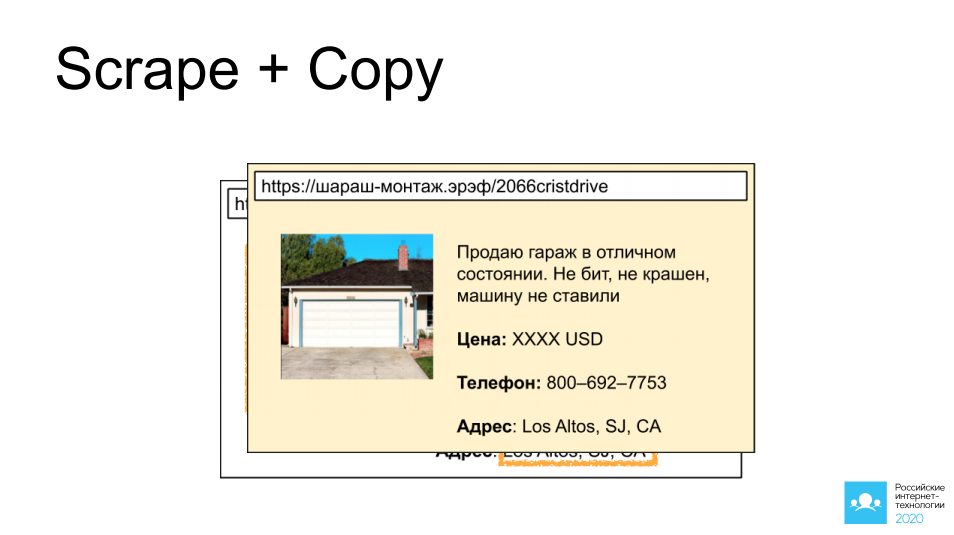
Le premier consiste à récupérer et à copier les publicités d'autres personnes à partir de sites donnant accès à de telles publicités: voitures, biens immobiliers, objets personnels. J'ai choisi un magnifique garage en Californie comme exemple. Imaginez que nous installions un bot là-bas, collections une photo, collections une description, prenions toutes les informations de contact, et après 5 minutes, la même annonce soit suspendue sur un autre site ayant un objectif similaire, et il est fort possible qu'une transaction rentable se produise.
Si nous activons un peu notre imagination ici et pensons au côté suivant - et si ce n'est pas notre concurrent qui fait cela, mais un attaquant? Une telle copie du site peut être très utile pour, par exemple, demander un paiement anticipé au visiteur, ou simplement proposer de saisir les coordonnées de la carte de paiement. Vous pouvez imaginer vous-même l'évolution des événements.
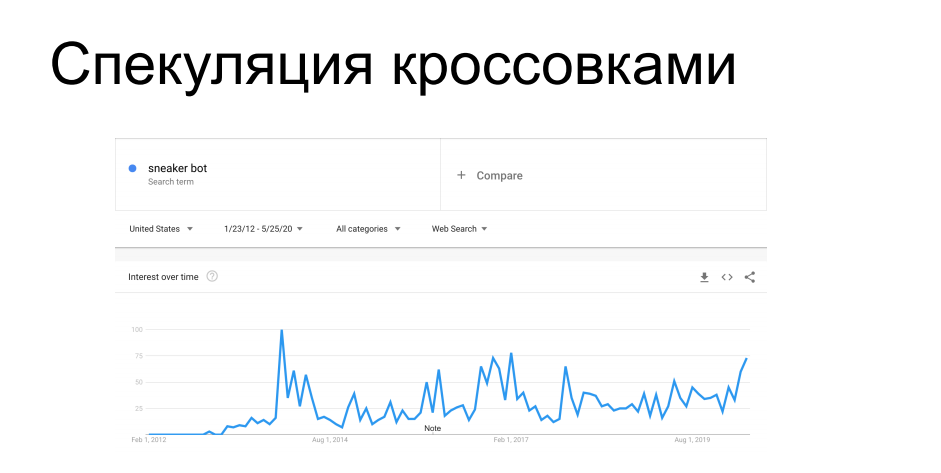
Un autre cas intéressant de grattage est l'achat d'articles à disponibilité limitée. Les fabricants de chaussures de sport tels que Nike, Puma et Reebok lancent périodiquement des baskets en édition limitée, etc. série signature - ils sont chassés par des collectionneurs, ils sont en vente pour une durée limitée. Devant les acheteurs, les bots accourent sur les sites Web des magasins de chaussures et engrangent la totalité du tirage, après quoi ces baskets flottent sur le marché gris avec un prix complètement différent. À un moment donné, cela a exaspéré les vendeurs et les détaillants qui les distribuent. Depuis 7 ans, ils se battent contre les grattoirs, etc. bots de sneaker avec un succès variable, tant sur le plan technique qu'administratif.

Vous avez probablement entendu des histoires lorsque lors de vos achats en ligne, il était nécessaire de se rendre dans un magasin de baskets en personne, ou à propos de pots de miel avec des baskets pour 100000 $, que le bot a achetés sans regarder, après quoi son propriétaire lui a pris la tête - toutes ces histoires sont dans cette tendance.
Et un autre cas similaire est l'épuisement des stocks dans les magasins en ligne. Il est similaire au précédent, mais aucun achat n'y est réellement effectué. Il y a une boutique en ligne et certains articles de marchandises que les robots entrants ratissent dans le panier dans la quantité affichée comme disponible dans l'entrepôt. En conséquence, un utilisateur légitime essayant d'acheter un produit reçoit un message indiquant que cet article n'est pas disponible, se gratte l'arrière de la tête de frustration et part pour un autre magasin. Les robots eux-mêmes déposent ensuite les paniers collectés, les marchandises sont renvoyées à la piscine - et celui qui en avait besoin vient et commande. Ou ne vient pas et ne commande pas, s'il s'agit d'un scénario de méfait et de hooliganisme. À partir de là, il est clair que même si de telles activités ne causent pas de dommages financiers directs à une entreprise en ligne, elles peuvent au moins perturber gravement les mesures commerciales,sur lesquels les analystes se concentreront. Des paramètres tels que la conversion, la fréquentation, la demande de produits, la vérification moyenne du panier - tous seront fortement tachés par les actions des robots en relation avec ces articles. Et avant de mettre ces paramètres en œuvre, ils devront être soigneusement et minutieusement nettoyés des effets des grattoirs.
En plus de cette orientation commerciale, le travail des grattoirs a également des effets techniques assez visibles - le plus souvent lorsque le grattage est effectué de manière active et intensive.
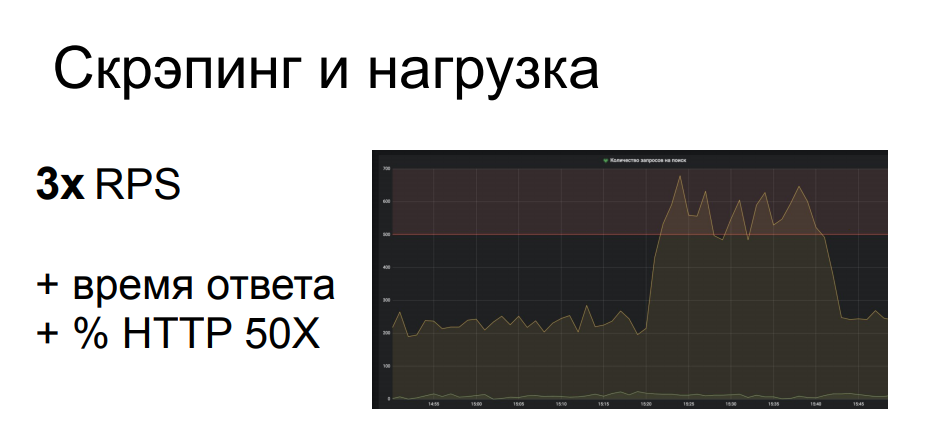
Un de nos exemples chez l'un de nos clients. Le racleur est arrivé à un emplacement avec une recherche paramétrée, ce qui est l'une des opérations les plus difficiles dans le backend de la structure en question. Le racleur a dû passer par de nombreuses requêtes de recherche, et il a effectué près de 700 RPS sur 200 à cet endroit. Cela a sérieusement chargé une partie de l'infrastructure, ce qui a causé la dégradation de la qualité de service pour le reste des utilisateurs légitimes, le temps de réponse a décollé, les 502 et 503 et des erreurs. En général, le grattoir ne s'en souciait pas du tout et il s'assit et faisait son travail pendant que tout le monde rafraîchissait frénétiquement la page du navigateur.
De là, il est clair qu'une telle activité peut très bien être classée comme une attaque DDoS appliquée - et c'est souvent le cas. Surtout si la boutique en ligne n'est pas si grande, elle ne dispose pas d'infrastructure réservée à plusieurs reprises en termes de performances et d'emplacement. Une telle activité peut bien, si vous ne mettez pas complètement la ressource - ce n'est pas très rentable pour le grattoir, car dans ce cas, il ne recevra pas ses données - alors tous les autres utilisateurs sont sérieusement contrariés.
Mais en plus du DDoS, le scraping a également des voisins intéressants de la sphère de la cybercriminalité. Par exemple, les connexions et les mots de passe par force brute utilisent une base technique similaire, c'est-à-dire qu'en utilisant les mêmes scripts, cela peut être fait en mettant l'accent sur la vitesse et les performances. Pour le remplissage des informations d'identification, les données utilisateur supprimées quelque part sont utilisées, qui sont poussées dans les champs de formulaire. Eh bien, cet exemple de copie de contenu et de publication sur des sites similaires est un travail préparatoire sérieux afin de glisser des liens de phishing et d'attirer des acheteurs sans méfiance.

Afin de comprendre comment différentes variantes de scraping peuvent, d'un point de vue technique, affecter la ressource, essayons de calculer la contribution de facteurs individuels à cette tâche. Faisons un peu d'arithmétique.

Disons que nous avons un tas de données à droite que nous devons collecter. Nous avons une tâche ou une commande pour récupérer 10 000 000 lignes d'articles de base, par exemple des étiquettes de prix ou des devis. Et sur le côté gauche, nous avons un budget temps, car demain ou dans une semaine, le client n'aura plus besoin de ces données - elles deviendront obsolètes et nous devrons les collecter à nouveau. Par conséquent, vous devez respecter un certain délai et, en utilisant vos propres ressources, le faire de manière optimale. Nous avons un certain nombre de serveurs - des machines et des adresses IP derrière lesquelles ils se trouvent, à partir desquels nous irons à la ressource qui nous intéresse. Nous avons un certain nombre d'instances d'utilisateurs que nous prétendons être - il y a une tâche à convaincre une boutique en ligne ou une base publique qu'il s'agit de personnes différentes ou d'ordinateurs différents qui recherchent certaines données, de sorte que cesqui analysera les journaux, il n'y avait aucun soupçon. Et nous avons des performances, un taux de demande, d'une telle instance.
Il est clair que dans un cas simple - une machine hôte, un étudiant avec un ordinateur portable, passant par le Washington Post, un grand nombre de demandes avec les mêmes signes et paramètres seront faites. Il sera très visible dans les journaux s'il y a beaucoup de telles demandes - ce qui signifie qu'il est facile de trouver et d'interdire, dans ce cas, par l'adresse IP.
Au fur et à mesure que l'infrastructure de scraping devient plus complexe, un plus grand nombre d'adresses IP apparaît, des proxies commencent à être utilisés, y compris des proxies maison - à leur sujet un peu plus tard. Et nous commençons à multi-instancier sur chaque machine - pour remplacer les paramètres de requête, les signes qui nous caractérisent, afin de faire tacher le tout dans les journaux et de ne pas être si visible.
Si nous continuons dans la même direction, alors nous avons la possibilité, dans le cadre de la même équation, de réduire l'intensité des requêtes de chaque instance de ce type - en les rendant plus rares, en les faisant tourner plus efficacement afin que les requêtes des mêmes utilisateurs ne se retrouvent pas dans les journaux à proximité. sans éveiller les soupçons et être similaire aux utilisateurs finaux (légitimes).
Eh bien, il y a un cas extrême - nous avons déjà eu un tel cas dans la pratique, lorsqu'un racleur est venu à un client à partir d'un grand nombre d'adresses IP avec des attributs utilisateur complètement différents derrière ces adresses, et chaque instance de ce type a fait exactement une demande de contenu. J'ai fait un GET vers la page produit souhaitée, je l'ai analysée et je suis partie - et je ne suis plus jamais apparue. De tels cas sont assez rares, car ils nécessitent plus de ressources (ce qui coûte de l'argent) pour être impliqués dans le même laps de temps. Mais en même temps, il devient beaucoup plus difficile de les retrouver et de comprendre que quelqu'un est même venu ici et les a grattés. Les outils de recherche sur le trafic tels que l'analyse comportementale - la construction d'un modèle de comportement d'un utilisateur particulier - deviennent très compliqués. Après tout, comment pouvez-vous faire une analyse comportementale s'il n'y a pas de comportement? Il n'y a pas d'historique des actions des utilisateurs,il n'avait jamais comparu auparavant et, chose intéressante, depuis, il n'est jamais venu non plus. Dans de telles conditions, si nous n'essayons pas de faire quelque chose à la première demande, il recevra ses données et partira, et il ne nous restera plus rien - nous n'avons pas résolu le problème de la lutte contre le grattage ici. Par conséquent, la seule opportunité est de deviner à la toute première demande que la mauvaise personne est venue, que nous voulons voir sur le site, et de lui donner une erreur ou de s'assurer qu'il ne reçoit pas ses données.que nous voulons voir sur le site, et lui donner une erreur ou s'assurer qu'il ne reçoit pas ses données.que nous voulons voir sur le site, et lui donner une erreur ou s'assurer qu'il ne reçoit pas ses données.
Afin de comprendre comment vous pouvez vous déplacer le long de cette échelle de complexité dans la construction d'un grattoir, examinons l'arsenal des créateurs de bots qui sont le plus souvent utilisés - et dans quelles catégories il peut être divisé.

La catégorie principale et la plus simple que la plupart des lecteurs connaissent est le scraping de scripts, l'utilisation de scripts suffisamment simples pour résoudre des problèmes relativement complexes.

Et cette catégorie est peut-être la plus populaire et la mieux documentée. Il est même difficile de recommander ce qu'il faut lire exactement, car, en réalité, il y a beaucoup de matériel. Beaucoup de livres ont été écrits en utilisant cette méthode, il y a beaucoup d'articles et de publications - en principe, il suffit de passer 5/4/3/2 minutes (selon l'impudence de l'auteur du matériel) pour analyser votre premier site. C'est une première étape logique pour beaucoup de ceux qui se lancent dans le scraping Web. Le "starter pack" d'une telle activité est le plus souvent Python, plus une bibliothèque qui peut faire des requêtes de manière flexible et modifier leurs paramètres, tels que les requêtes ou urllib2. Et une sorte d'analyseur HTML, généralement Beautiful Soup. Il existe également une option pour utiliser des bibliothèques créées spécifiquement pour le scraping, telles que scrapy, qui comprend toutes ces fonctionnalités avec une interface conviviale.
À l'aide d'astuces simples, vous pouvez vous faire passer pour différents appareils, différents utilisateurs, même sans pouvoir en quelque sorte dimensionner vos activités par machines, par adresses IP et par différentes plates-formes matérielles.

Pour éliminer l'odeur de celui qui inspecte les journaux du côté serveur à partir duquel les données sont collectées, il suffit de modifier les paramètres d'intérêt - et ce n'est pas difficile et rapide à faire. Examinons un exemple de format de journal personnalisé pour nginx - nous enregistrons une adresse IP, des informations TLS, des en-têtes qui nous intéressent. Ici, bien sûr, pas tout ce qui est habituellement collecté, mais nous avons besoin de cette restriction comme exemple - pour regarder un sous-ensemble, simplement parce que tout le reste est encore plus facile à «jeter».
Afin de ne pas être bannis par les adresses, nous utiliserons des proxys résidentiels, comme on les appelle à l'étranger - c'est-à-dire des procurations de machines louées (ou piratées) dans les réseaux domestiques des fournisseurs. Il est clair qu'en interdisant une telle adresse IP, il y a une chance d'interdire un certain nombre d'utilisateurs qui vivent dans ces maisons - et il peut bien y avoir des visiteurs sur votre site, donc parfois cela vous coûte plus cher de le faire.
Les informations TLS ne sont pas non plus difficiles à modifier - prenez les suites de chiffrement des navigateurs populaires et choisissez celle que vous aimez - la plus courante, ou faites-les pivoter périodiquement afin de se présenter comme des appareils différents.
En ce qui concerne les en-têtes, à l'aide d'une petite étude, vous pouvez définir le référent sur ce que le site gratté aime, et nous prenons l'agent utilisateur de Chrome, ou Firefox, afin qu'il ne diffère en aucun cas de dizaines de milliers d'autres utilisateurs.
Ensuite, en jonglant avec ces paramètres, vous pouvez vous faire passer pour des appareils différents et continuer à gratter sans avoir peur de vous faire remarquer à l'œil nu marchant dans les bûches. Pour l'œil armé, c'est encore un peu plus difficile, car de telles astuces simples sont neutralisées par les mêmes contre-mesures, plutôt simples.

Comparer les paramètres de demande, les en-têtes, les adresses IP entre eux et avec ceux connus du public vous permet d'attraper les scrapers les plus arrogants. Un exemple simple - un robot de recherche nous est venu, mais pour une raison quelconque, seule son adresse IP ne provient pas du réseau du moteur de recherche, mais d'un fournisseur de cloud. Même Google lui-même sur la page décrivant Googlebot recommande d'effectuer une recherche inversée dans les enregistrements DNS afin de s'assurer que ce bot provient bien de google.com ou d'autres ressources Google valides.
Il existe de nombreux contrôles de ce type, le plus souvent ils sont conçus pour les grattoirs qui ne se soucient pas du fuzzing, une sorte de substitution. Pour les cas plus complexes, il existe des méthodes plus fiables et plus lourdes, par exemple, glisser Javascript dans ce bot. Il est clair que dans de telles conditions, la lutte est déjà inégale - votre script Python ne pourra pas exécuter et interpréter le code JS. Mais cela peut être fait par l'auteur du script - si l'auteur du bot a suffisamment de temps, de désir, de ressources et de compétences pour aller voir ce que fait votre Javascript dans le navigateur.
L'essence des vérifications est que vous intégrez le script dans votre page, et il est important pour vous non seulement qu'il soit exécuté - mais aussi qu'il démontre une sorte de résultat, qui est généralement POST renvoyé au serveur avant que le client ne dorme suffisamment contenu, et la page elle-même se chargera. Par conséquent, si l'auteur du bot a résolu votre énigme et codé en dur les réponses correctes dans son script Python, ou, par exemple, comprend où il doit analyser les lignes de script elles-mêmes à la recherche des paramètres nécessaires et des méthodes appelées, et calculera la réponse par lui-même, il peut vous tromper. autour de votre doigt. Voici un exemple.

Je pense que certains auditeurs reconnaîtront ce morceau de javascript - c'est une vérification que l'un des plus grands fournisseurs de cloud au monde avait avant d'accéder à la page demandée, compacte et très simple, et en même temps, sans l'apprendre, c'est tellement facile le site ne perce pas. En même temps, après avoir appliqué un peu d'effort, nous pouvons demander à la page à la recherche des méthodes JS qui nous intéressent qui seront appelées, à partir d'elles, en comptant, trouver les valeurs qui nous intéressent à calculer, et coller les calculs dans le code. Après cela, n'oubliez pas de dormir quelques secondes en raison du retard, et le tour est joué.

Nous sommes arrivés à la page et nous pouvons ensuite analyser ce dont nous avons besoin, sans dépenser plus de ressources que de créer notre propre grattoir. Autrement dit, du point de vue de l'utilisation des ressources, nous n'avons besoin de rien de plus pour résoudre de tels problèmes. Il est clair que la course aux armements dans ce sens - écrire des défis JS, les analyser et les contourner par des outils tiers - n'est limitée que par le temps, le désir et les compétences de l'auteur de bots et de l'auteur de chèques. Cette course peut durer assez longtemps, mais à un moment donné, la plupart des scrapers deviennent inintéressants, car il existe des options plus intéressantes pour y faire face. Pourquoi s'asseoir et analyser le code JS en Python alors que vous pouvez simplement saisir et exécuter un navigateur?

Oui, je parle principalement de navigateurs headless, car cet outil, créé à l'origine pour les tests et les questions / réponses, s'est avéré idéal pour les tâches de scraping Web pour le moment.
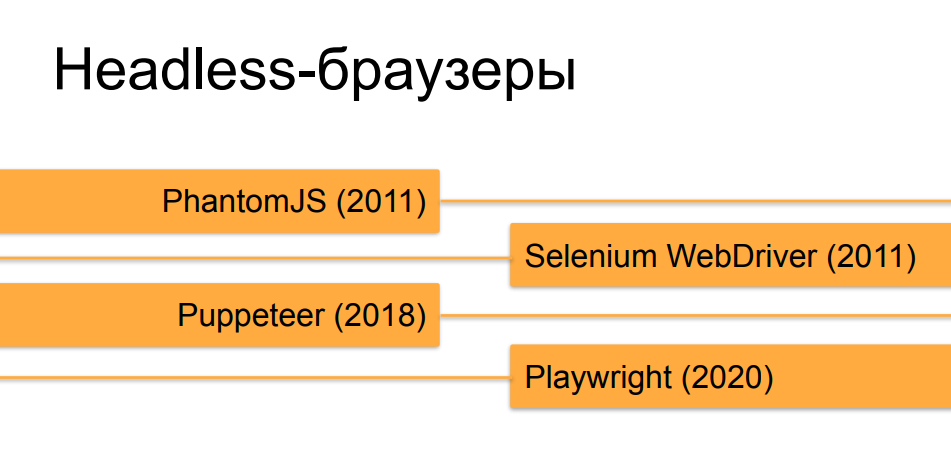
Nous n'entrerons pas dans les détails sur les navigateurs headless, je pense que la plupart des auditeurs les connaissent déjà. Les orchestrateurs, qui automatisent les navigateurs headless, ont connu une évolution assez rapide au cours des 10 dernières années. Au début, à l'époque de PhantomJS et des premières versions de Selenium 2.0 et Selenium WebDriver, un navigateur sans tête fonctionnant sous un automate n'était pas du tout difficile à distinguer d'un utilisateur en direct. Mais, avec le temps et l'émergence d'outils tels que Puppeteer pour Chrome sans tête et, maintenant, la création de gentlemen de Microsoft - Playwright, qui fait la même chose que Puppeteer, mais pas seulement pour Chrome, mais pour toutes les versions de navigateurs populaires, ils le sont de plus en plus et rapprochez les navigateurs headless des vrais en termes decomment ils peuvent être faits à l'aide d'une orchestration similaire en comportement et en différents signes et propriétés au navigateur d'une personne en bonne santé.

Afin de faire face à la reconnaissance de headless'ov dans le contexte des navigateurs ordinaires, derrière lesquels les gens sont assis, en règle générale, les mêmes contrôles javascript'ovye sont utilisés, mais plus profonds, détaillés, collectant un nuage de paramètres. Le résultat de cette collecte est renvoyé soit à l'outil de protection, soit au site à partir duquel le gratteur souhaitait collecter les données. Cette technologie s'appelle l'empreinte digitale, car elle recueille une véritable empreinte digitale numérique du navigateur et de l'appareil sur lequel il s'exécute.
Il y a pas mal de choses que JS vérifie lors de la prise d'empreintes digitales - elles peuvent être divisées en blocs conditionnels, dans chacun desquels le creusement peut continuer encore et encore. Il y a vraiment beaucoup de propriétés, certaines sont faciles à cacher, d'autres moins faciles. Et ici, comme dans l'exemple précédent, tout dépend de la méticulosité avec laquelle le grattoir a abordé la tâche de cacher les "queues" saillantes de l'absence de tête. Il y a des propriétés d'objets dans le navigateur, que l'orchestrateur remplace par défaut, il y a la propriété même (navigator.webdriver), qui est définie en headless, mais en même temps, elle ne l'est pas dans les navigateurs classiques. Il peut être masqué, une tentative de masquage peut être détectée en vérifiant certaines méthodes - ce qui vérifie ces vérifications peut également être caché et glissé une fausse sortie vers des fonctions qui impriment des méthodes, par exemple,et cela peut durer indéfiniment.
Un autre bloc de vérifications, en règle générale, est chargé d'étudier les paramètres de fenêtre et d'écran, qui par définition n'ont pas dans les navigateurs sans tête: vérifier les coordonnées, vérifier les tailles, quelle est la taille d'une image brisée qui n'a pas été dessinée. Il y a beaucoup de nuances qu'une personne qui connaît bien l'appareil des navigateurs peut prévoir et glisser une conclusion plausible (mais pas réelle) sur chacun d'entre eux, qui s'envolera lors des contrôles d'empreintes digitales vers le serveur, qui l'analysera. Par exemple, dans le cas du rendu de certaines images, 2D et 3D, au moyen de WebGL et Canvas, vous pouvez préparer complètement la sortie entière, la forger, la publier dans une méthode et faire croire à quelqu'un que quelque chose est vraiment dessiné.
Il y a plus de vérifications astucieuses qui ne se produisent pas en même temps, mais disons que le code JS tournera pendant un certain nombre de secondes sur la page, ou il se bloquera constamment et transférera certaines informations au serveur à partir du navigateur. Par exemple, suivre la position et la vitesse du mouvement du curseur - si le bot clique uniquement aux endroits dont il a besoin et suit les liens à la vitesse de la lumière, cela peut être suivi par le mouvement du curseur, si l'auteur du bot ne pense pas à écrire une sorte de , décalage.
Et il y a toute une jungle - ce sont des paramètres et des propriétés spécifiques à la version du modèle objet, qui sont spécifiques d'un navigateur à l'autre, d'une version à l'autre. Et pour que ces vérifications fonctionnent correctement et ne falsifient pas, par exemple, sur les utilisateurs en direct avec certains anciens navigateurs, vous devez prendre en compte un tas de choses. Tout d'abord, vous devez suivre la sortie des nouvelles versions, modifier vos chèques pour qu'ils prennent en compte l'état des choses sur les fronts. Il est nécessaire de maintenir la rétrocompatibilité pour que quelqu'un puisse accéder à un site protégé par de telles vérifications sur un navigateur atypique et en même temps ne pas être pris comme un bot, et bien d'autres.
C'est un travail laborieux et plutôt compliqué - de telles choses sont généralement effectuées par des entreprises qui fournissent la détection de bots en tant que service, et le faire par leurs propres moyens n'est pas un investissement très rentable en temps et en argent.
Mais que faire - nous devons vraiment gratter le site, accroché avec un nuage de tels contrôles sans tête et calculer notre chrome sans tête avec le marionnettiste, malgré tout, quels que soient nos efforts.
Une petite digression lyrique - toute personne intéressée à lire plus en détail sur l'histoire et l'évolution des chèques, par exemple, pour l'absence de tête de Chrome, il y a un drôle duel épistolaire entre deux auteurs. Je ne sais pas grand-chose d'un auteur, et l'autre s'appelle Antoine Vastel, un jeune français qui tient un blog sur les bots et leur détection, l'obscurcissement des chèques et bien d'autres choses intéressantes. Et donc, eux et leur homologue se disputent depuis deux ans pour savoir s'il est possible de détecter Chrome sans tête.
Et nous allons avancer et comprendre ce qu'il faut faire si nous ne pouvons pas passer les contrôles sans tête.

Cela signifie que nous n'utiliserons pas de headless, mais utiliserons de grands navigateurs réels qui nous dessinent des fenêtres et toutes sortes d'éléments visuels. Des outils tels que Puppeteer et Playwright permettent, au lieu de sans tête, de lancer des navigateurs avec un écran rendu, de lire les entrées de l'utilisateur à partir de là, de prendre des captures d'écran et bien plus encore qui ne sont pas disponibles pour les navigateurs sans composant visuel.

En plus de contourner les contrôles d'absence de tête, dans ce cas, vous pouvez également faire face au problème suivant - lorsque nous avons des constructeurs de sites rusés, cachez-vous du texte dans les images, rendez-les invisibles sans faire de clics supplémentaires ou d'autres actions et mouvements. Ils cachent certains éléments qui devraient être cachés, et qui se retrouvent sans tête: ils ne savent pas que cet élément ne doit pas être affiché à l'écran maintenant, et ils le rencontrent. Nous pouvons simplement dessiner cette image dans le navigateur, envoyer la capture d'écran à l'OCR, récupérer le texte en sortie et l'utiliser. Oui, c'est plus difficile, plus cher en termes de développement, prend plus de temps et consomme plus de ressources. Mais il existe des grattoirs qui fonctionnent de cette manière, et au détriment de la vitesse et des performances, ils collectent des données de cette manière.

"Et le CAPTCHA?" - tu demandes. Après tout, le captcha OCR (avancé) ne peut pas être résolu sans des choses plus complexes. Il y a une réponse simple à cela - si nous ne pouvons pas résoudre le captcha automatiquement, pourquoi ne pas utiliser le travail humain? Pourquoi séparer un robot et un humain, si vous pouvez combiner leur travail pour atteindre un objectif?
Il existe des services qui vous permettent de leur envoyer un captcha, où il est résolu par les mains de personnes assises devant les écrans, et grâce à l'API, vous pouvez obtenir une réponse à votre captcha, insérer un cookie dans la demande, par exemple, qui sera émise, puis traiter automatiquement les informations de ce site ... Chaque fois qu'un captcha apparaît, nous tirons l'apishka, obtenons une réponse au captcha - glissez-le dans la question suivante et passez à autre chose.
Il est clair que cela coûte également un joli centime - la solution captcha est achetée en gros. Mais si nos données sont plus chères que le coût de toutes ces astuces, alors, après tout, pourquoi pas?
Maintenant que nous avons examiné l'évolution vers la complexité de tous ces outils, réfléchissons à ce qu'il faut faire si le scraping se produit sur notre ressource en ligne - une boutique en ligne, une base de connaissances publique, ou autre.

La première chose à faire est de trouver le grattoir. Je vais vous dire ceci: tous les cas de rassemblement public n'apportent généralement pas d'effets négatifs, comme nous l'avons déjà considéré au début du rapport. En règle générale, des méthodes plus primitives, les mêmes scripts sans limitation de débit, sans limitation de la vitesse de requête, peuvent faire beaucoup plus de mal (si elles ne sont pas empêchées au moyen de la protection) que n'importe quel grattage complexe, sophistiqué et plein de navigateur avec une seule requête dans l'heure, qui au début doit encore être trouvée dans les journaux.

Par conséquent, vous devez d'abord comprendre que nous sommes en train d'être éraflés - pour examiner les significations qui sont généralement affectées par cette activité. Nous parlons maintenant de paramètres techniques et de métriques commerciales. Ces choses que vous pouvez voir dans votre Grafana, au fil du temps en regardant la charge et le trafic, toutes sortes de rafales et d'anomalies. Cela peut être fait manuellement si vous n'utilisez pas d'outil de sécurité, mais cela est fait de manière plus fiable par ceux qui savent comment filtrer le trafic, détecter toutes sortes d'incidents et les associer à certains événements. Car en plus d'analyser les journaux après coup et en plus d'analyser chaque demande individuelle, l'utilisation de certains moyens de protection accumulés de la base de connaissances peut fonctionner ici, qui a déjà vu les actions des grattoirs sur cette ressource ou sur des ressources similaires, et vous pouvez en quelque sorte comparer l'une avec l'autre - la parole sur l'analyse de corrélation.
Quant aux métriques métiers, nous avons déjà rappelé en utilisant l'exemple des scripts qui causent des dommages financiers directs ou indirects. S'il est possible de suivre rapidement la dynamique de ces paramètres, un grattage peut à nouveau être remarqué - et ensuite, si vous résolvez ce problème vous-même, bienvenue dans les journaux de votre backend.
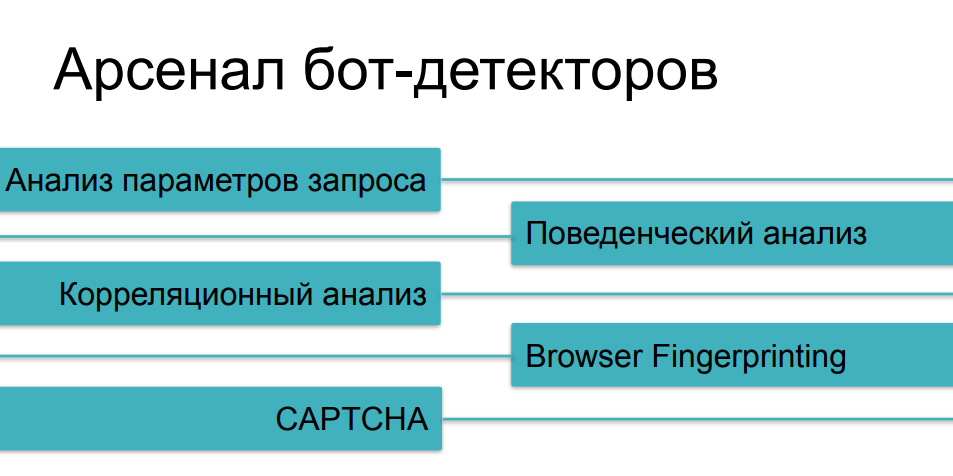
En ce qui concerne les moyens de protection utilisés contre le grattage agressif, nous avons déjà examiné la plupart des méthodes, en parlant de différentes catégories de robots. L'analyse du trafic nous aidera à partir des cas les plus simples, l'analyse comportementale nous aidera à suivre des choses telles que le fuzzing (substitution d'identité) et les scripts multi-instances. Contre des choses plus complexes, nous collecterons des impressions numériques. Et, bien sûr, nous avons un CAPTCHA comme dernier argument des rois - si nous ne pouvions pas en quelque sorte attraper un robot rusé sur les questions précédentes, alors, probablement, il tombera sur un CAPTCHA, non?
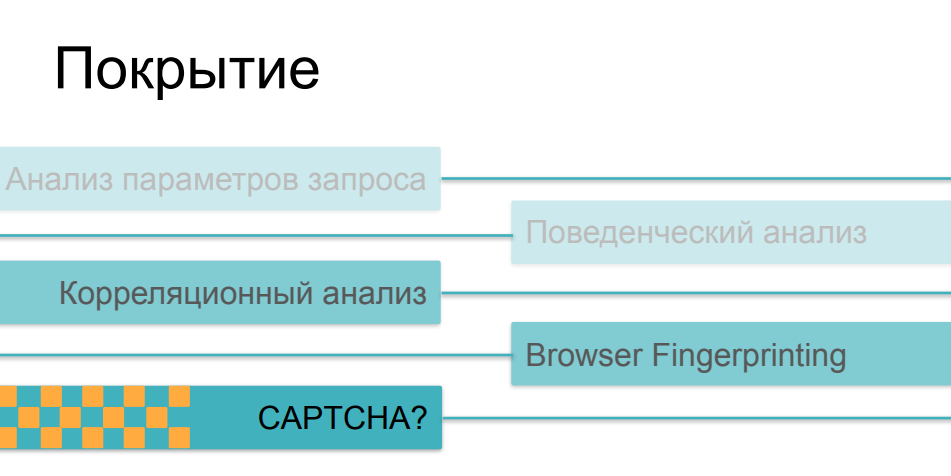
Eh bien, les choses sont un peu plus compliquées ici. Le fait est qu'à mesure que la complexité et la ruse des chèques augmentent, ils deviennent de plus en plus chers, principalement pour le client. Si l'analyse du trafic et la comparaison ultérieure des paramètres avec certaines valeurs historiques peuvent être effectuées de manière absolument non invasive, sans affecter le temps de chargement de la page et la vitesse de la ressource en ligne en principe, alors la prise d'empreintes digitales, si elle est suffisamment massive et effectue des centaines de vérifications différentes du côté du navigateur, peut affectent sérieusement la vitesse de téléchargement. Et très peu de gens aiment regarder des pages avec des chèques en train de suivre les liens.
En ce qui concerne les CAPTCHA, c'est la méthode la plus grossière et la plus invasive. C'est une chose qui peut vraiment effrayer les utilisateurs ou les acheteurs de la ressource. Personne n'aime le captcha, et ils ne s'y tournent pas à cause d'une belle vie - ils y ont recours lorsque toutes les autres options n'ont pas fonctionné. Il y a un autre paradoxe drôle ici, un problème avec une telle application de ces méthodes. Le fait est que la plupart des moyens de protection dans telle ou telle superposition utilisent toutes ces possibilités, en fonction de la difficulté du scénario d'activité du bot qu'ils ont rencontré. Si notre utilisateur a réussi à passer les analyseurs de trafic, si son comportement ne diffère pas du comportement des utilisateurs, si son empreinte digitale ressemble à un navigateur valide, il a surmonté toutes ces vérifications, puis à la fin nous lui montrons le captcha - et cela s'avère être une personne ... cela peut être très triste ...En conséquence, le captcha commence à être montré non pas aux méchants robots que nous voulons couper, mais à une part assez sérieuse d'utilisateurs - des personnes qui peuvent se fâcher et ne pas venir la prochaine fois, ne pas acheter quelque chose sur la ressource, ne pas participer à son développement ultérieur.

Compte tenu de tous ces facteurs - que devons-nous faire à la fin si le grattage nous arrivait, nous l'avons examiné et avons pu en quelque sorte évaluer son impact sur nos indicateurs commerciaux et techniques? D'une part, cela n'a aucun sens de lutter contre le grattage par définition comme avec la collecte de données publiques, de machines ou de personnes - vous avez vous-même convenu que ces données sont disponibles pour tout utilisateur qui vient d'Internet. Et résoudre le problème de la limitation du grattage «par principe» - c'est-à-dire que du fait que des robots avancés et talentueux viennent à vous, vous essayez de tous les interdire - cela signifie dépenser beaucoup de ressources en protection, soit la vôtre, soit en utilisant une solution coûteuse et très complexe , auto-hébergé ou basé sur le cloud en "mode de sécurité maximale" et, à la poursuite de chaque bot individuel, risque d'effrayer la part d'utilisateurs valides avec de telles choses,comme des vérifications javascript lourdes, comme le captcha qui apparaît à chaque troisième transition. Tout cela peut changer votre site au-delà de la reconnaissance en faveur de vos visiteurs.
Si vous souhaitez utiliser un outil de protection, alors vous devez rechercher ceux qui vous permettront de changer et trouver en quelque sorte un équilibre entre la proportion de grattoirs (du simple au complexe) que vous allez essayer de couper de l'utilisation de votre ressource et, en fait, la vitesse de votre web -Ressource. Parce que, comme nous l'avons déjà vu, certains contrôles sont effectués simplement et rapidement, tandis que certains contrôles sont difficiles et prennent du temps - et en même temps sont très visibles pour les visiteurs eux-mêmes. Par conséquent, des solutions capables d'appliquer et de varier ces contre-mesures au sein d'une plateforme commune vous permettront d'atteindre cet équilibre plus rapidement et mieux.
Eh bien, il est également très important d'utiliser ce que l'on appelle le «bon état d'esprit» dans l'étude de tous ces problèmes sur leurs propres exemples ou ceux des autres. Il ne faut pas oublier que les données publiques elles-mêmes n’ont pas besoin de protection - elles seront encore tôt ou tard vues par toutes les personnes qui le souhaitent. L'expérience utilisateur a besoin de protection: l'UX de vos clients, clients et utilisateurs, qui, contrairement aux scrapers, génèrent des revenus pour vous. Vous pouvez le conserver et l'augmenter si vous maîtrisez mieux ce domaine très intéressant.
Merci beaucoup pour votre attention!
