Nous devons maintenant apprendre à décrire la logique qui fonctionnera sur les données reçues et émettre un verdict sur le fonctionnement de notre règle dans une situation donnée. C'est à cette section de la règle et à ses fonctionnalités que cet article est consacré. La description de la section logique de détection est la partie la plus importante de la syntaxe, dont la connaissance est nécessaire pour comprendre les règles existantes et écrire les vôtres.
Dans la prochaine publication, nous nous attarderons sur la description des méta-informations (attributs de nature informative ou infrastructurelle, comme une description ou un identifiant) et des collections de règles. Suivez nos publications!
Description de la logique de détection (attribut de détection)
Les conditions de déclenchement des règles sont définies dans l'attribut de détection . Ses sous-champs décrivent la partie technique principale de la règle. Il est important de noter qu'une règle ne peut avoir qu'une seule partie descriptive et plusieurs sources de journaux et de détection. Puisque la section de détection décrit le critère de déclenchement basé sur les données de la section sources, ces deux sections ont un 1 à 1.
En général, le contenu du champ de détection se compose de deux parties logiques:
- une description des hypothèses sur les champs d'événement (ID de recherche),
- la relation logique entre ces descriptions ( délai et expression dans le champ condition ).

La description des hypothèses sur le contenu des champs d'événement se fait en spécifiant des identificateurs de recherche. Un tel identifiant peut être un (comme ici ) ou il peut y en avoir plusieurs (comme ici ).
La deuxième partie peut être de trois types:
- la condition habituelle,
- une condition avec une expression agrégée (comme dans l'exemple ci-dessus),
- condition avec le mot-clé near .
La syntaxe des éléments de chaque partie est décrite dans la section correspondante de cet article.
ID de recherche
Un identificateur de recherche est une paire clé-valeur, où la clé est le nom de l'identificateur de recherche et la valeur est une liste ou un dictionnaire (c'est-à-dire un tableau associatif). Par analogie avec les langages de programmation - liste ou carte. Le format de spécification des listes et des dictionnaires est défini par le standard YAML, que vous pouvez trouver ici . Il est à noter que le format de règle Sigma ne corrige pas les noms des identificateurs de recherche, mais le plus souvent, vous pouvez trouver des variantes avec la sélection de mots.
Il existe des exigences générales qui s'appliquent à la fois aux éléments de liste et aux éléments de dictionnaire:
- Toutes les valeurs sont traitées comme des chaînes insensibles à la casse, c'est-à-dire qu'il n'y a aucune différence entre les majuscules et les minuscules.
- (wildcards) ‘*’ ‘?’. ‘*’ — ( ), ‘?’ — ( ).
- ‘\’, ‘\*’. , : ‘\\*’. .
- , .
- ‘ .
Liste des valeurs Identifiant de recherche Les
listes de valeurs contiennent des chaînes qui sont recherchées tout au long du message d'événement. Les éléments de la liste sont combinés avec un OU logique.
detection:
keywords:
- EVILSERVICE
- svchost.exe -n evil
condition: keywords

Exemples de règles contenant des identifiants de recherche sous forme de liste de valeurs:
- rules / web / web_apache_segfault.yml (la liste peut contenir un élément)
- règles / windows / powershell / powershell_clear_powershell_history.yml
- rules / linux / lnx_shell_susp_log_entries.yml
Identifiant de recherche dans le dictionnaire
Les dictionnaires sont constitués d'un ensemble de paires clé-valeur, où la clé est le nom du champ de l'événement, et la valeur peut être une chaîne, un entier ou une liste de l'un de ces types (les listes de chaînes ou de nombres sont combinées avec un OU logique). Les ensembles de dictionnaires sont combinés par un ET logique
Schéma général:
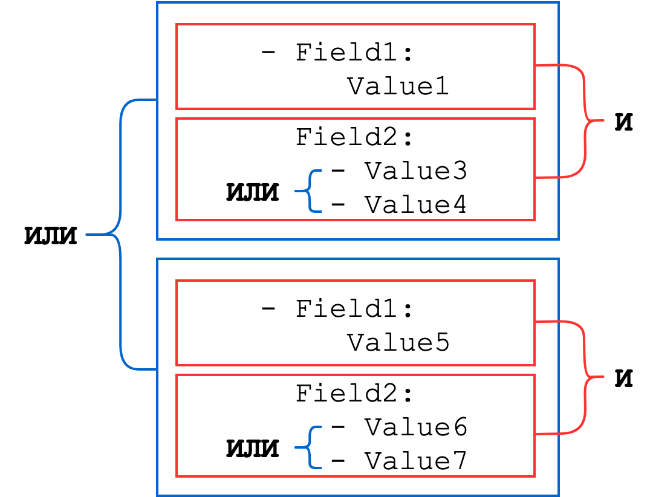
Considérons plusieurs exemples.
Exemple 1. Règles de règle de détection de nettoyage du journal des événements
/ windows / builtin / win_susp_security_eventlog_cleared.yml
Cette règle sera déclenchée si l'événement remplit la condition:
EventID = 517 OU EventID = 1102
Dans la règle, cela ressemble à ceci:
detection:
selection:
EventID:
- 517
- 1102
condition: selection Ici, la sélection est le nom du seul identifiant de recherche, et le reste des sous-champs est sa valeur, et cette valeur est de type "dictionnaire". Dans ce dictionnaire, EventID est une clé et les nombres 517 et 1102 forment une liste qui est la valeur de cette clé de dictionnaire.
Exemple 2. Une demande de ticket suspecte, probablement Kerberoasting
rules / windows / builtin / win_susp_rc4_kerberos.yml
Cette règle sera déclenchée si l'événement remplit la condition:
EventID = 4679 AND TicketOptions = 0x40810000 AND TicketEncryption = 0x17 AND ServiceName ne se termine pas par un signe '$'
Dans la règle, cela ressemble à ceci:
detection:
selection:
EventID: 4769
TicketOptions: '0x40810000'
TicketEncryption: '0x17'
reduction:
- ServiceName: '*$'
condition: selection and not reduction Valeurs de champ spéciales
Deux valeurs de champ spéciales peuvent être utilisées:
- Une valeur vide spécifiée par deux guillemets simples ''
- La valeur nulle spécifiée par le mot clé null
Remarque: une valeur non vide ne peut pas être spécifiée via la construction non nulle
L'application de ces valeurs dépend du système SIEM cible. Pour décrire la condition non nulle, vous devez créer un identifiant de recherche distinct avec une valeur vide et en tirer la négation de la condition (le champ de condition, il est décrit à la fin de l'article). Considérez d'autres exemples de règles qui utilisent la description d'un champ vide.
Exemple 3. Lancement suspect d'un flux distant
rules / windows / sysmon / sysmon_password_dumper_lsass.yml
La règle spécifiée sera déclenchée si l'événement remplit la condition:
EventID = 8 AND TargetImage = 'C: \ Windows \ System32 \ lsass.exe' ET StartModule est un champ vide
Dans la règle, cela ressemble à ceci:
detection:
selection:
EventID: 8
TargetImage: 'C:\Windows\System32\lsass.exe'
StartModule: null
condition: selection Exemple 4. Ecriture d'un fichier exécutable dans un autre flux de fichiers NTFS
rules / windows / sysmon / sysmon_ads_executable.yml
La règle considérée est un exemple de la désignation correcte d'une valeur non vide. Cette règle sera déclenchée si l'événement remplit la condition:
EventID = 15 AND I
mphash != '00000000000000000000000000000000' Imphash
Dans la règle, cela ressemble à ceci:
detection:
selection:
EventID: 15
filter:
Imphash:
- '00000000000000000000000000000000'
- null
condition: selection and not filter Comme mentionné ci-dessus, la négation doit maintenant être placée dans la condition (le champ de condition), et non dans les identificateurs de recherche.
Modificateurs de valeur
L'interprétation des valeurs de champ dans une règle peut être modifiée à l'aide de modificateurs. Les modificateurs sont ajoutés après le nom du champ, chaque modificateur est précédé d'une barre verticale (tuyau) - «|». Ils peuvent être chaînés pour construire des chaînes (pipelines) de modificateurs:

La valeur du champ est modifiée en fonction de l'ordre des modificateurs dans la chaîne. Les modificateurs peuvent être de deux types: les modificateurs de transformation et de type.
Les modificateurs de transformation sont ceux qui convertissent la valeur de champ d'origine en une autre valeur ou transforment la logique de traitement des listes de valeurs dans les identificateurs de recherche. Un exemple du premier type est les modificateurs Base64, et le second est le modificateur all . Tous les modificateurs seront discutés plus en détail plus tard.
Jetons un coup d'œil à chacun des modificateurs de transformation. Pour plus de clarté, nous montrerons schématiquement comment exactement tel ou tel modificateur change la valeur initiale.
commence avec
Le modificateur startswith est utilisé pour faire correspondre le début d'une chaîne avec la valeur souhaitée.

Exemples d'utilisation:
- rules / windows / builtin / win_ad_replication_non_machine_account.yml
- rules / windows / process_creation / win_apt_winnti_mal_hk_jan20.yml
- règles / windows / powershell / powershell_downgrade_attack.yml
se termine par
Le modificateur endswith est utilisé pour faire correspondre la fin d'une chaîne avec une valeur de recherche.

Exemples d'utilisation:
- rules / windows / process_creation / win_local_system_owner_account_discovery.yml
- rules / windows / sysmon / sysmon_minidumwritedump_lsass.yml
- rules / windows / process_creation / win_susp_odbcconf.yml
contient
Le modificateur contains vérifie l'occurrence d'une sous-chaîne dans la valeur du champ. En fait, ce modificateur convertit la valeur du champ comme suit:

Autrement dit, si nous considérons les résultats de l'application des modificateurs considérés, vous pouvez écrire la formule suivante:
beginwith + endswith = contient des
exemples:
- règles / windows / process_creation / win_hack_bloodhound.yml
- règles / windows / process_creation / win_mimikatz_command_line.yml
- rules / windows / sysmon / sysmon_webshell_creation_detect.yml
tout
Habituellement, les éléments de feuille sont combinés avec un OU logique. Le modificateur all change OU logique en ET logique. Autrement dit, tous les éléments de la liste doivent être présents. Voyons comment les conditions changeraient dans le schéma général, qui se trouvait au début de la section:
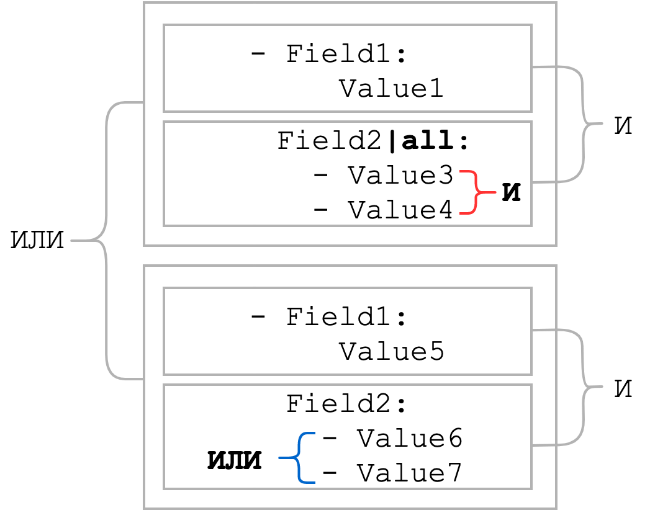
comme vous pouvez le voir, lorsque le modificateur all a été appliqué, la connexion logique entre les éléments de la liste est devenue AND. Habituellement, le modificateur all est utilisé conjointement avec le modificateur contient. Un tel lien peut servir de substitut au modèle avec des métacaractères génériques au cas où l'ordre des parties statiques serait inconnu.
Exemples d'utilisation du modificateur all :
- rules / windows / builtin / win_meterpreter_or_cobaltstrike_getsystem_service_installation.yml
- rules / windows / powershell / powershell_suspicious_profile_create.yml
- règles / windows / powershell / powershell_suspicious_download.yml
base64
Ce modificateur est appliqué lorsque la valeur du champ est encodée en Base64 , et pour plus de clarté, nous écrivons le texte encodé dans la règle, et non la chaîne Base64 résultante.

Ce modificateur suppose une correspondance exacte du champ avec la chaîne codée. Il est généralement plus utile d'identifier les signes d'activité suspecte dans les données d'origine que de rechercher une correspondance exacte avec le résultat encodé. Par conséquent, il n'y a pas encore d'exemples d'utilisation du modificateur base64 .
décalage base64
En raison de la nature du codage Base64, vous ne pouvez pas utiliser un pipeline à partir de base64 et contient pour rechercher une sous-chaîne codée . Le modificateur base64offset a été créé dans ce but précis . Il est utilisé lorsqu'une chaîne est encodée en Base64 et que nous voulons trouver une sous-chaîne de la chaîne encodée. De plus, les caractères qui entourent la sous-chaîne souhaitée sont inconnus à l'avance et le décalage de la sous-chaîne par rapport au début de la chaîne est inconnu. Vous pouvez clairement voir ce qui est en jeu ici.
Presque toujours, ce modificateur est utilisé avec le modificateur contient :

Exemples d'utilisation:
- rules / windows / process_creation / win_encoded_frombase64string.yml
- règles / windows / process_creation / win_encoded_iex.yml
Important! Les trois modificateurs de transformation de codage suivants sont utilisés uniquement avec les modificateurs Base64.
utf16le ou large
Les modificateurs utf16le et wide sont des synonymes. Ils transforment la valeur de chaîne du champ en encodage UTF-16LE, c'est-à-dire
“123” -> 0x31 0x00 0x32 0x00 0x33 0x00.

utf16be
Le modificateur utf16be convertit la valeur de chaîne du champ en UTF-16BE, c'est-à-dire
“123” -> 0x00 0x31 0x00 0x32 0x00 0x33.

utf16
Le modificateur utf16 ajoute une marque d'ordre d'octet (BOM) et code une chaîne en UTF-16, c'est-à-dire
“123” -> 0xFF 0xFE 0x31 0x00 0x32 0x00 0x33 0x00.

Il n'y a actuellement qu'un seul modificateur de type - re .
ré
Ce modificateur de type interprète la valeur du champ comme un modèle d'expression régulière. Jusqu'à présent, il n'est pris en charge que par le convertisseur en requête Elasticsearch, il n'apparaît donc pratiquement pas dans les règles publiques.
Exemples d'utilisation:
- règles / windows / process_creation / win_invoke_obfuscation_obfuscated_iex_commandline.yml
- rules / windows / builtin / win_invoke_obfuscation_obfuscated_iex_services.yml
- rules / windows / builtin / win_mal_creddumper.yml
Intervalle de temps (attribut de période)
De plus, la logique de détection peut être affinée en spécifiant l'intervalle de temps pendant lequel les identificateurs de recherche doivent apparaître. Les abréviations standard sont utilisées pour désigner les unités de temps:
15s (15 )
30m (30 )
12h (12 )
7d (7 )
3M (3 ) Exemples d'utilisation:
- règles / linux / modsecurity / modsec_mulitple_blocks.yml
- rules-unsupported / net_possible_dns_rebinding.yml
- rules / windows / builtin / win_rare_service_installs.yml
Description des conditions de déclenchement de règle (attribut de condition)
Selon la documentation officielle Sigma, la partie de la règle qui contient la condition de déclenchement est la plus complexe et changera avec le temps. Les expressions suivantes sont actuellement disponibles.
Opérations logiques ET, OU
Ils sont indiqués par les mots - clés et et ou, respectivement. Ces expressions sont les principaux éléments de la construction d'une relation logique entre les identificateurs de recherche.
detection:
keywords1:
- EVILSERVICE
- svchost.exe -n evil
keywords2:
- SERVICEEVIL
- svchost.exe -n live
condition: keywords1 or keywords2 Exemples d'utilisation:
Une des valeurs d'ID de recherche / toutes les valeurs d'ID de recherche (1 / toutes les valeurs d'ID de recherche)
Identique au cas précédent, si l'ID de recherche
- 1 - OU logique parmi les alternatives,
- tout - logique ET parmi les alternatives.
Par défaut
condition: keywords, cela signifie que les valeurs répertoriées dans l'identificateur de mots-clés sont OU logiques, c'est-à-dire que cela revient à écrire condition: 1 of keywords. Si nous voulons que les valeurs soient combinées avec un ET logique, nous devons écrire condition: all of keywords.
Exemples d'utilisation:
L'un des ID de recherche / tous les ID de recherche (1 / tous)
OU logique (1 d'entre eux) ou ET logique (tous) parmi tous les ID de recherche donnés. Par défaut, les ID de recherche sont liés par un ET logique s'ils sont des éléments d'un dictionnaire, ou un OU logique s'ils sont des éléments d'une liste. Pour changer ces relations, cette structure a été créée. Ainsi, la condition, condition: 1 d'entre eux, signifie qu'au moins un des identifiants de recherche doit apparaître dans l'événement.
Exemples d'utilisation:
- règles / windows / process_creation / win_hack_bloodhound.yml
- règles / windows / powershell / powershell_psattack.yml
- rules / cloud / aws_ec2_download_userdata.yml
Un des ID de recherche correspondant au modèle de nom / tous les ID de recherche correspondant au modèle de nom (1 / tous les identificateurs de recherche-modèle)
Identique au paragraphe précédent, mais la sélection est limitée aux identifiants de recherche dont les noms correspondent au modèle. Ces modèles sont construits en utilisant le caractère générique * (n'importe quel nombre de caractères) à une position spécifique dans le modèle de nom.
La syntaxe est la suivante:
condition: 1 of selection*
condition: all of selection* Exemples d'utilisation:
- rules / windows / builtin / win_user_added_to_local_administrators.yml
- rules / windows / process_creation / win_susp_eventlog_clear.yml
- rules / cloud / aws_iam_backdoor_users_keys.yml
Négation logique
Les négatifs logiques sont construits à l'aide du mot-clé not . Comme indiqué ci-dessus, l'expression «non vide» doit être spécifiée dans le champ de condition et non dans la description de l'identificateur de recherche. L'exemple suivant montre clairement la version correcte de la description de l'expression "la valeur du champ n'est pas vide".

Exemples d'utilisation:
- rules / windows / sysmon / sysmon_malware_backconnect_ports.yml
- règles / windows / process_creation / win_apt_gallium.yml
Tuyau
La barre verticale (ou tube) indique que le résultat de l'expression sera passé à une fonction d'agrégation, dont le résultat est susceptible d'être comparé à une certaine valeur.
Schéma général:
_ | _
condition: selection | count(category) by dst_ip > 30 Exemples d'utilisation:
- rules / windows / builtin / win_susp_failed_logons_single_source.yml
- rules / windows / autre / win_rare_schtask_creation.yml
- rules / network / net_high_dns_requests_rate.yml
Parenthèses
Les parenthèses sont utilisées pour spécifier une sous-expression. Cela peut être utile pour spécifier l'ordre dans lequel une expression logique est évaluée ou pour nier un prédicat contenant plusieurs expressions. Ils ont la priorité la plus élevée pour l'opération.
condition: selection and (keywords1 or keywords2)
condition: selection and not (filter1 or filter2) Exemple d'utilisation:
Expressions de fonction d'agrégation
Les expressions d'agrégation (ou expressions de fonction d'agrégation) sont utilisées pour quantifier les événements qui se sont produits.
Schéma d'expression d'agrégation:

toutes les fonctions d'agrégation, à l'exception de count, nécessitent un nom de champ comme paramètre. La fonction de comptage compte tous les événements correspondants si aucun nom de champ n'est spécifié. Si un nom de champ est spécifié, la fonction compte différentes valeurs dans ce champ. Par exemple, l'expression suivante compte le nombre de ports différents auxquels les connexions ont été établies à partir d'une adresse IP, et si ce nombre dépasse 10, la règle est déclenchée:
condition: selection | count(dst_port) by src_ip > 10 Exemples d'utilisation:
- rules / linux / lnx_susp_failed_logons_single_source.yml
- rules / windows / autre / win_rare_schtask_creation.yml
- rules / network / net_susp_network_scan.yml
Expression agrégée à proximité
Le mot-clé near est utilisé pour générer une demande (si cette fonctionnalité est prise en charge par le système cible et le backend) qui reconnaît l'occurrence de tous les ID de recherche spécifiés dans un intervalle de temps spécifié après avoir trouvé le premier ID.
Schéma général:
near search-id-1 [ [ and search-id-2 | and not search-id-3 ] ... ]
exemple de syntaxe:
timeframe: 30s
condition: selector | near dllload1 and dllload2 and not exclusion Les mêmes règles s'appliquent à l'expression de recherche qui suit le mot à proximité que pour l'expression de recherche qui apparaît avant la barre verticale, que nous avons détaillé ci-dessus.
Exemples d'utilisation:
- rules / windows / sysmon / sysmon_mimikatz_inmemory_detection.yml
- rules / windows / builtin / win_susp_samr_pwset.yml
La priorité par défaut des opérations est:
- (expression)
- X du motif de recherche
- ne pas
- Et
- Ou
- |
Ainsi, les parenthèses ont la priorité la plus élevée et le tube la plus basse.
Remarque: si plusieurs champs de condition sont spécifiés, la valeur finale est obtenue en appliquant un OU logique à toutes les valeurs d'expression.
Dans cet article, nous avons décrit la logique de détection. Suivez nos articles, dans le prochain article, nous examinerons les champs restants de la règle. La plupart d'entre eux sont de nature informationnelle ou infrastructurelle. En plus des champs contenant des méta-informations, attardons-nous sur une telle caractéristique de la composition des règles, appelée collections de règles. Pour les personnes peu familiarisées avec les subtilités du langage YAML, la prise en compte de cet aspect de la syntaxe sera utile lors de la lecture des étrangers et de l'écriture de leurs propres règles.
Auteur : Anton Kutepov, spécialiste du département des services experts et du développement des technologies positives (PT Expert Security Center)