
Le matériel est arrivé sur le site plusieurs mois avant le pic des ventes. Le service de maintenance sait bien entendu comment et quoi mettre en place sur les serveurs pour les introduire dans l'environnement de production. Mais nous devions automatiser cela et éliminer le facteur humain. De plus, les serveurs ont été remplacés avant la migration d'un ensemble de systèmes SAP critiques pour l'entreprise.
La mise en service de nouveaux serveurs était étroitement liée à un délai. Et le déplacer mettrait en péril à la fois l'expédition du milliard de cadeaux et la migration des systèmes. Même une équipe composée du Père Noël et du Père Noël ne pouvait pas changer la date - le système SAP pour la gestion des entrepôts ne peut être transféré qu'une fois par an. Du 31 décembre au 1er janvier, les immenses entrepôts du détaillant, un total de 20 terrains de football, arrêtent leur travail pendant 15 heures. Et c'est la seule période pendant laquelle le système se déplace. Nous n'avions pas le droit de nous tromper en entrant dans les serveurs.
Laissez-moi vous expliquer tout de suite: mon histoire reflète le type d'outils et de processus de gestion de configuration que notre équipe utilise.
Le complexe de gestion de configuration se compose de plusieurs niveaux. L'élément clé est le système CMS. Dans l'exploitation industrielle, l'absence d'un des niveaux conduirait inévitablement à des miracles désagréables.
Gestion de l'installation du système d'exploitation
Le premier niveau est un système de gestion de l'installation des systèmes d'exploitation sur des serveurs physiques et virtuels. Il crée des configurations OS de base, éliminant le facteur humain.
Avec l'aide de ce système, nous avons reçu un standard et adapté à d'autres instances d'automatisation de serveurs avec OS. Lorsqu'ils ont été castés, ils ont reçu un ensemble minimal d'utilisateurs locaux et de clés SSH publiques, ainsi qu'une configuration de système d'exploitation cohérente. Nous pouvions être assurés de gérer les serveurs via le CMS et étions sûrs qu'il n'y avait pas de surprises «en dessous», au niveau du système d'exploitation.
La cible maximale du système de gestion de l'installation est de configurer automatiquement les serveurs du niveau BIOS / micrologiciel au système d'exploitation. Tout dépend du matériel et des tâches de configuration. Pour des équipements différents, pensez à l' API REDFISH... Si tout le matériel provient d'un seul fournisseur, il est souvent plus pratique d'utiliser des outils de gestion prêts à l'emploi (par exemple, HP ILO Amplifier, DELL OpenManage, etc.).
Pour installer le système d'exploitation sur des serveurs physiques, nous avons utilisé le célèbre Cobbler, qui définit un ensemble de profils d'installation coordonnés avec le service de maintenance. Lors de l'ajout d'un nouveau serveur à l'infrastructure, l'ingénieur lierait l'adresse MAC du serveur au profil requis dans Cobbler. Lors du premier démarrage sur le réseau, le serveur a reçu une adresse temporaire et un nouveau système d'exploitation. Ensuite, il a été transféré vers l'adressage VLAN / IP cible et a continué à y travailler. Oui, la modification des VLAN prend du temps et nécessite une coordination, mais elle offre une protection supplémentaire contre l'installation accidentelle du serveur dans un environnement de production.
Nous avons créé des serveurs virtuels basés sur des modèles préparés à l'aide de HashiCorp Packer. La raison était la même: pour éviter d'éventuelles erreurs humaines lors de l'installation du système d'exploitation. Mais, contrairement aux serveurs physiques, Packer vous permet de ne pas utiliser PXE, le démarrage réseau et le changement de VLAN. Cela a facilité et facilité la création de serveurs virtuels.
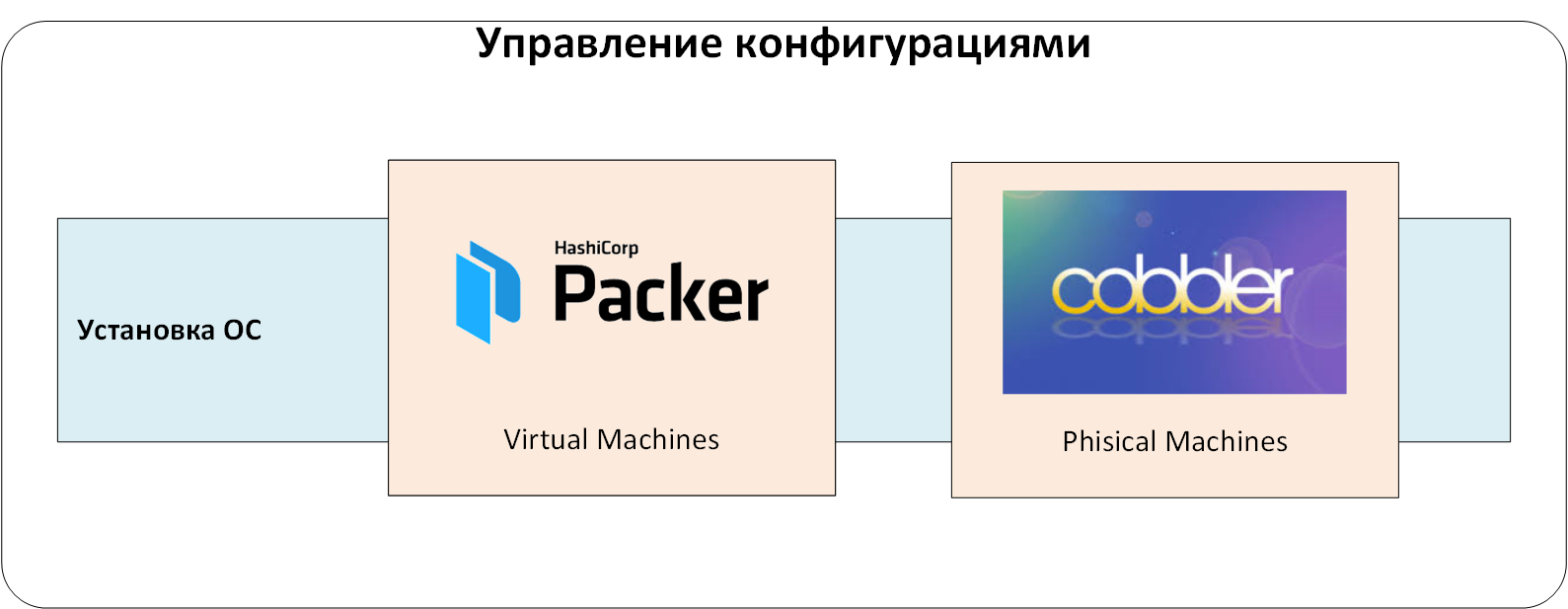
Figure: 1. Gestion de l'installation des systèmes d'exploitation.
Gestion secrète
Tout système de gestion de configuration contient des données qui doivent être cachées aux utilisateurs ordinaires, mais qui sont nécessaires pour préparer les systèmes. Ce sont les mots de passe des utilisateurs locaux et des comptes de service, des clés de certificat, divers jetons API, etc. Ils sont généralement appelés «secrets».
Si, dès le début, il n'est pas déterminé où et comment stocker ces secrets, alors, en fonction de la gravité des exigences du SI, les méthodes de stockage suivantes sont probables:
- directement dans le code de gestion de la configuration ou dans les fichiers du référentiel;
- dans des outils de gestion de configuration spécialisés (par exemple, Ansible Vault);
- dans les systèmes CI / CD (Jenkins / TeamCity / GitLab /, etc.) ou dans les systèmes de gestion de configuration (Ansible Tower / Ansible AWX);
- aussi les secrets peuvent être transférés au "contrôle manuel". Par exemple, ils sont disposés dans un endroit convenu, puis ils sont utilisés par les systèmes de gestion de configuration;
- diverses combinaisons de ce qui précède.
Chaque méthode a ses propres inconvénients. Le principal est l'absence de politiques d'accès aux secrets: il est impossible ou difficile de déterminer qui peut utiliser certains secrets. Un autre inconvénient est l'absence d'audit d'accès et d'un cycle de vie complet. Comment remplacer rapidement, par exemple, une clé publique, qui est écrite dans le code et dans un certain nombre de systèmes associés?
Nous avons utilisé le coffre-fort centralisé HashiCorp. Cela nous a permis de:
- gardez les secrets en sécurité. Ils sont chiffrés, et même si quelqu'un accède à la base de données Vault (par exemple, en la restaurant à partir d'une sauvegarde), il ne pourra pas lire les secrets qui y sont stockés;
- . «» ;
- . Vault;
- « » . , , . .
- , ;
- , , ..
Passons maintenant au système central d'authentification et d'autorisation. Vous pourriez vous en passer, mais administrer des utilisateurs dans de nombreux systèmes connexes est trop simple. Nous avons configuré l'authentification et l'autorisation via le service LDAP. Sinon, le même coffre-fort devrait émettre et conserver en permanence des enregistrements de jetons d'authentification pour les utilisateurs. Et la suppression et l'ajout d'utilisateurs se transformeraient en une quête "Ai-je créé / supprimé ce UZ partout?"
Nous ajoutons un niveau supplémentaire à notre système: gestion des secrets et authentification / autorisation centralisée:
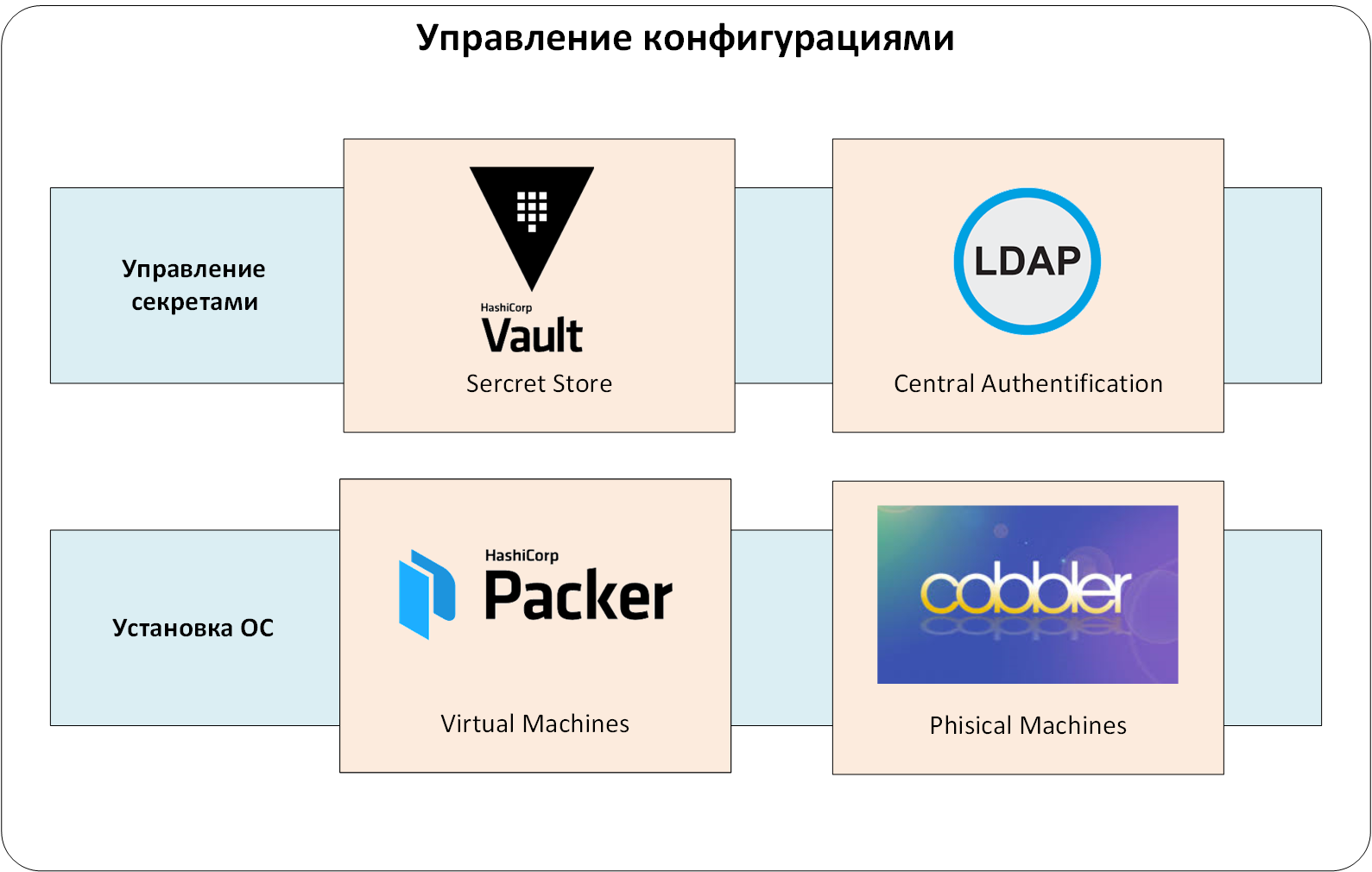
Figure: 2. Gestion des secrets.
Gestion de la configuration
Nous sommes arrivés au cœur - au système CMS. Dans notre cas, il s'agit d'un groupe d'Ansible et de Red Hat Ansible AWX.
Chef, Puppet, SaltStack peut agir à la place d'Ansible. Nous avons choisi Ansible pour plusieurs critères.
- Tout d'abord, c'est la polyvalence. L'ensemble de modules prêts à l'emploi pour le contrôle est impressionnant . Et si vous n'en avez pas assez, vous pouvez effectuer une recherche sur GitHub et Galaxy.
- Deuxièmement, il n'est pas nécessaire d'installer et de maintenir des agents sur des équipements contrôlés, de prouver qu'ils n'interfèrent pas avec la charge et de confirmer l'absence de "signets".
- Troisièmement, Ansible a une faible barrière à l'entrée. Un ingénieur compétent rédigera un manuel de travail littéralement le premier jour de travail avec le produit.
Mais Ansible à lui seul ne nous suffisait pas dans un environnement industriel. Sinon, il y aurait de nombreux problèmes avec la restriction de l'accès et l'audit des actions des administrateurs. Comment différencier l'accès? Après tout, chaque division devait gérer (lire - exécuter le playbook Ansible) «son» ensemble de serveurs. Comment puis-je autoriser uniquement des employés spécifiques à exécuter des playbooks Ansible spécifiques? Ou comment savoir qui a lancé un playbook sans exécuter de nombreux KM locaux sur les serveurs et le matériel Ansible?
Red Hat Ansible Tower , ou son projet open source Ansible AWX en amont, résout la part du lion de ces problèmes . Par conséquent, nous l'avons préféré pour le client.
Et une touche de plus au portrait de notre système CMS. Le playbook Ansible doit être stocké dans des systèmes de gestion de référentiel de code. Nous avons ce GitLab CE .
Ainsi, les configurations elles-mêmes sont gérées par un bundle d'Ansible / Ansible AWX / GitLab (voir Fig. 3). Bien sûr, AWX / GitLab est intégré à un système d'authentification unifié et le playbook Ansible est intégré à HashiCorp Vault. Les configurations n'entrent dans l'environnement de production que via Ansible AWX, dans lequel toutes les «règles du jeu» sont définies: qui et quoi peut configurer, où obtenir le code de gestion de la configuration pour le CMS, etc.
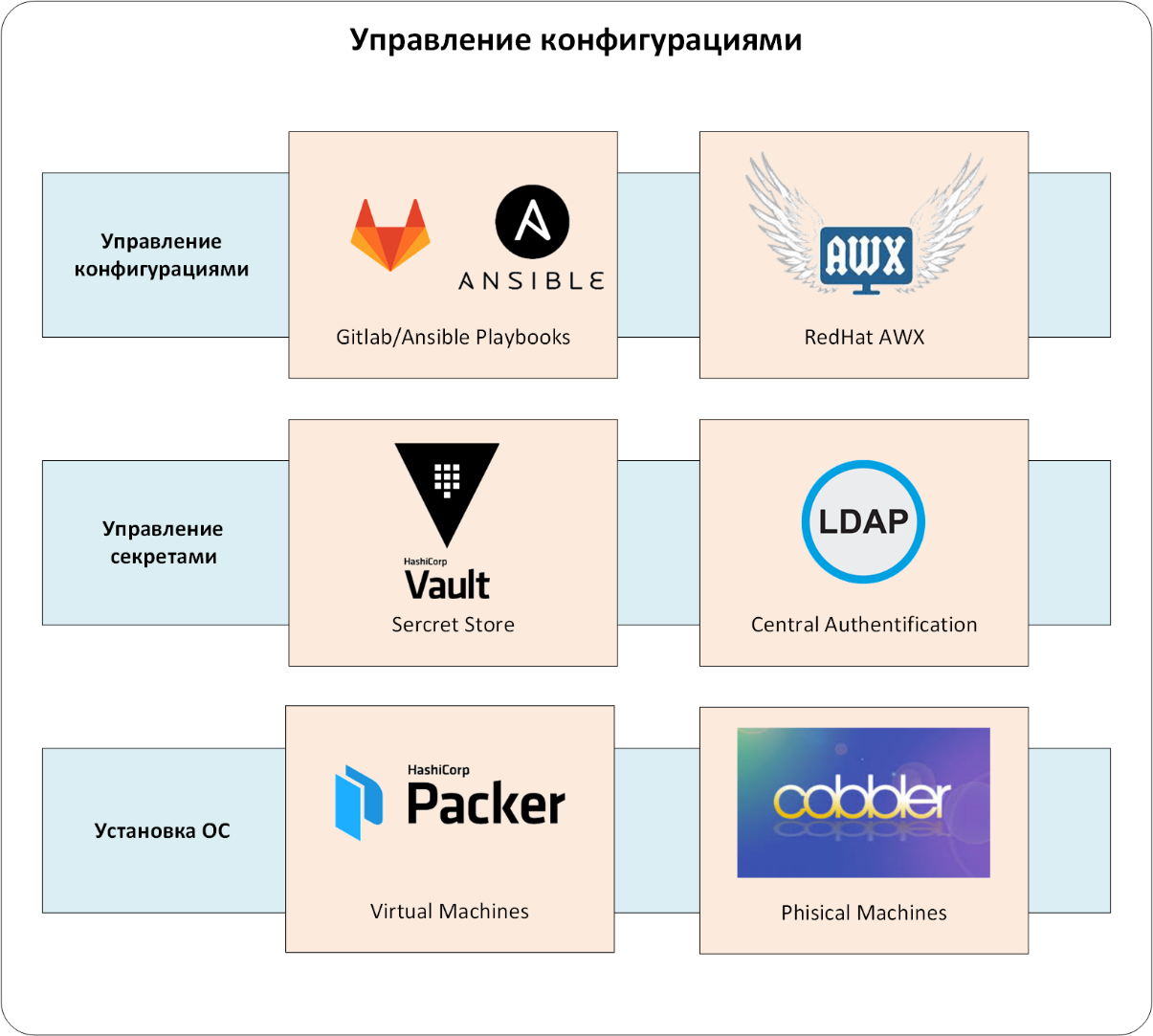
Figure: 3. Gestion de la configuration.
Gestion des tests
Notre configuration est présentée sous forme de code. Par conséquent, nous sommes obligés de jouer selon les mêmes règles que les développeurs de logiciels. Nous devions organiser les processus de développement, les tests continus, la livraison et l'application du code de configuration aux serveurs de production.
Si cela n'était pas fait immédiatement, les rôles écrits pour la configuration cesseraient d'être conservés et modifiés ou cesseraient de fonctionner en production. Le remède à cette douleur est connu et cela a porté ses fruits dans ce projet:
- chaque rôle est couvert par des tests unitaires;
- les tests sont exécutés automatiquement chaque fois qu'il y a un changement dans le code de gestion de la configuration;
- les modifications du code de gestion de la configuration n'entrent dans l'environnement de production qu'après avoir réussi tous les tests et la révision du code.
Le développement de code et la gestion de la configuration sont plus calmes et plus prévisibles. Pour organiser des tests continus, nous avons utilisé la boîte à outils GitLab CI / CD et nous avons utilisé Ansible Molecule comme cadre pour organiser les tests .
Pour toute modification du code de gestion de la configuration, GitLab CI / CD appelle Molecule:
- il vérifie la syntaxe du code,
- soulève le conteneur Docker,
- applique le code modifié au conteneur généré,
- vérifie le rôle pour l'idempotence et exécute des tests pour ce code (la granularité ici est au niveau du rôle ansible, voir Fig. 4).
Nous avons fourni des configurations à l'environnement de production à l'aide d'Ansible AWX. Les ingénieurs opérationnels ont appliqué les changements de configuration via des modèles prédéfinis. AWX a indépendamment "demandé" la dernière version du code à la branche principale de GitLab chaque fois qu'il était utilisé. De cette façon, nous avons exclu l'utilisation de code non testé ou obsolète dans l'environnement de production. Naturellement, le code n'est entré dans la branche principale qu'après avoir été testé, examiné et approuvé.
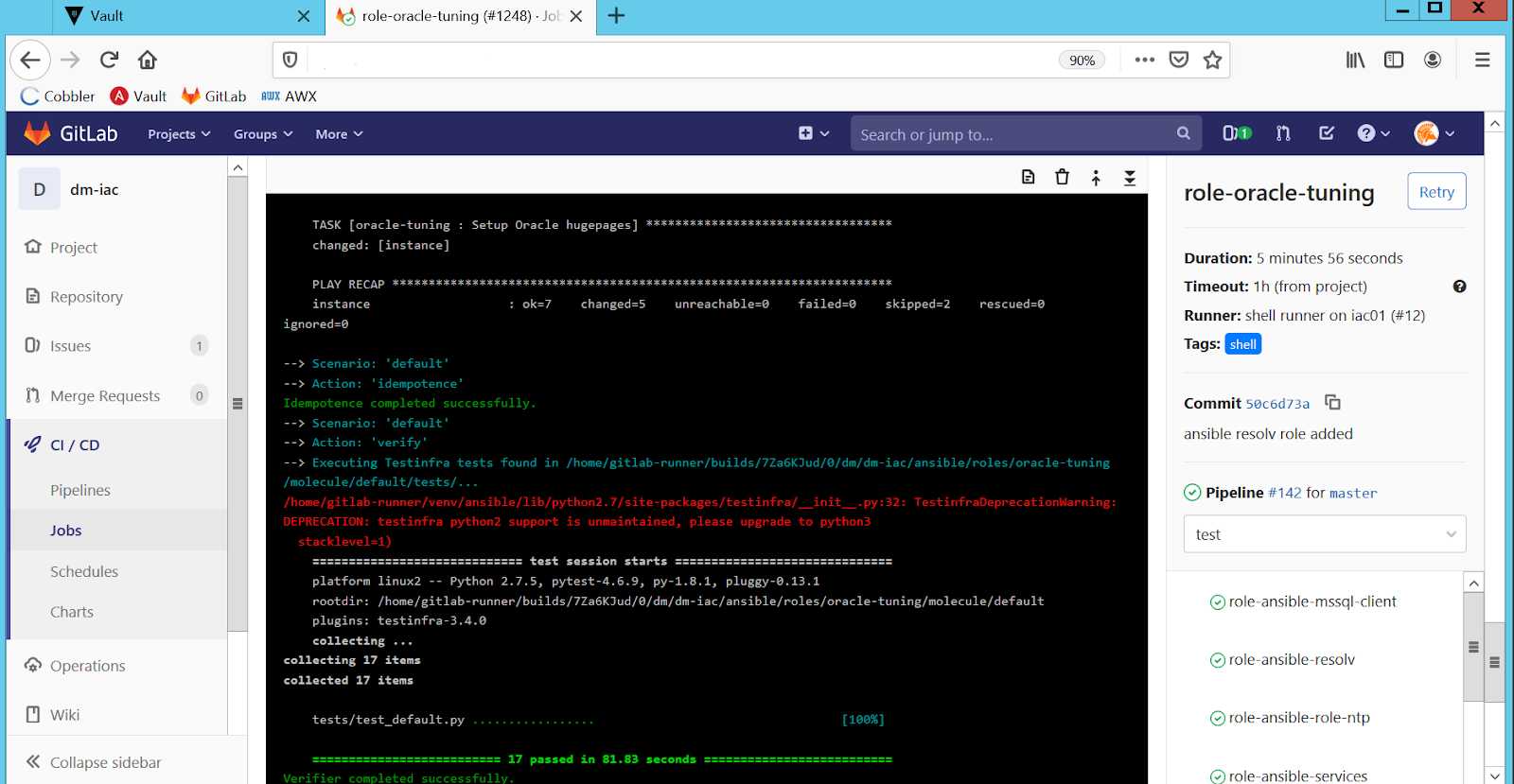
Figure: 4. Test automatique des rôles dans GitLab CI / CD.
Il existe également un problème lié au fonctionnement des systèmes de production. Dans la vraie vie, il est très difficile de faire des changements de configuration via le seul code CMS. Des situations anormales surviennent lorsqu'un ingénieur doit changer la configuration «ici et maintenant» sans attendre l'édition du code, les tests, l'approbation, etc.
En conséquence, en raison de changements manuels, des écarts de configuration apparaissent sur le même type d'équipement (par exemple, sur les nœuds du cluster HA configuration différente des paramètres sysctl). Ou la configuration réelle sur le matériel est différente de celle spécifiée dans le code CMS.
Par conséquent, en plus des tests continus, nous vérifions les environnements de production pour les écarts de configuration. Nous avons choisi l'option la plus simple: exécuter le code de configuration du CMS en mode «dry run», c'est-à-dire sans appliquer de modifications, mais avec notification de toutes les divergences entre la configuration prévue et réelle. Nous l'avons implémenté en exécutant périodiquement tous les playbooks Ansible avec l'option «--check» sur les serveurs de production. Ansible AWX, comme toujours, est responsable du lancement et de la pertinence du playbook (voir Fig.5):
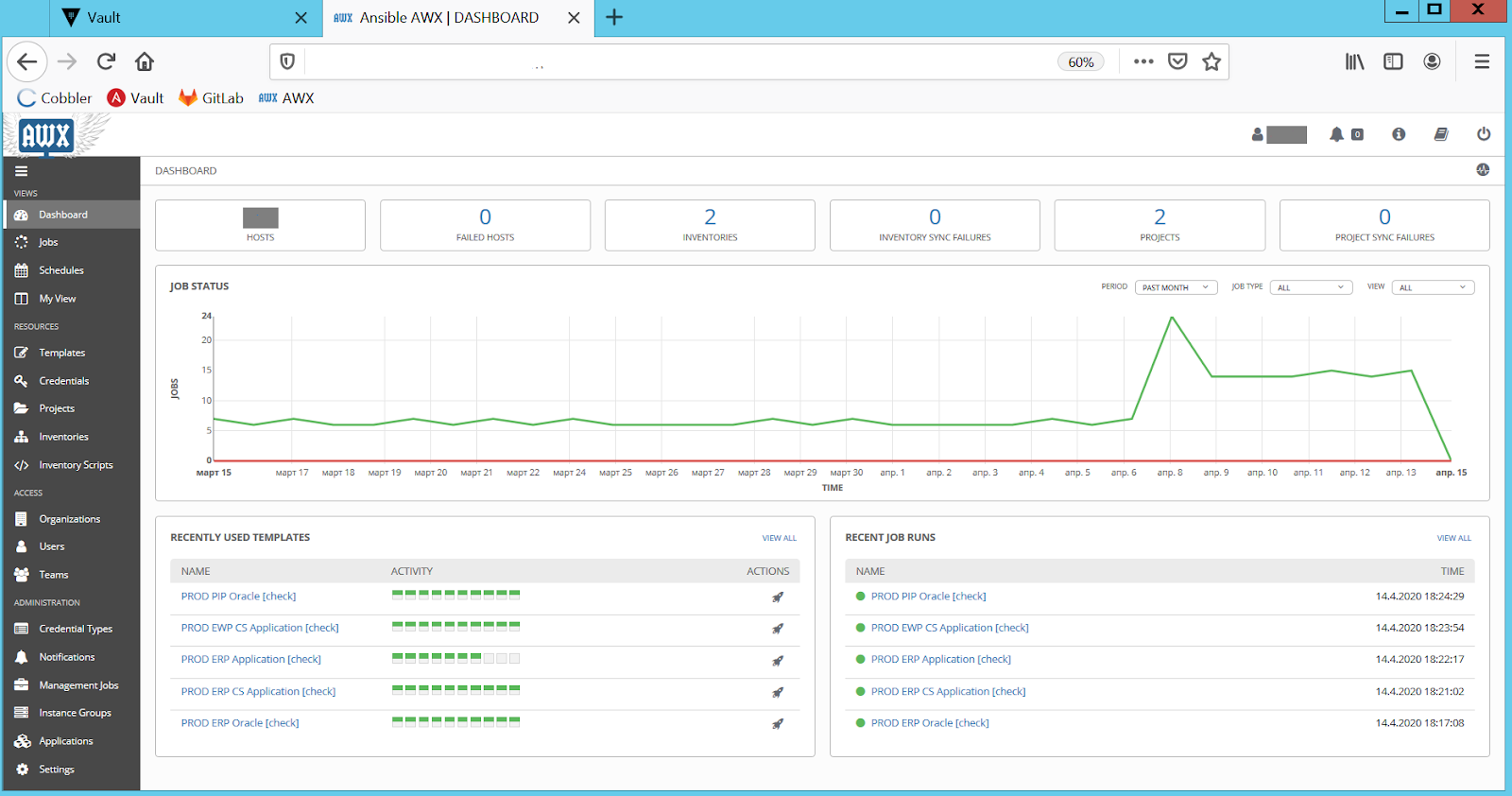
Figure: 5. Vérifie les différences de configuration dans Ansible AWX.
Après les vérifications, AWX envoie un rapport d'anomalie aux administrateurs. Ils étudient la configuration du problème, puis le résolvent via le playbook ajusté. De cette façon, nous maintenons la configuration dans l'environnement de production et le CMS est toujours à jour et synchronisé. Cela élimine les "miracles" désagréables lorsque le code CMS est appliqué sur des serveurs "de production".
Nous avons maintenant une couche de test importante constituée d'Ansible AWX / GitLab / Molecule (Figure 6).
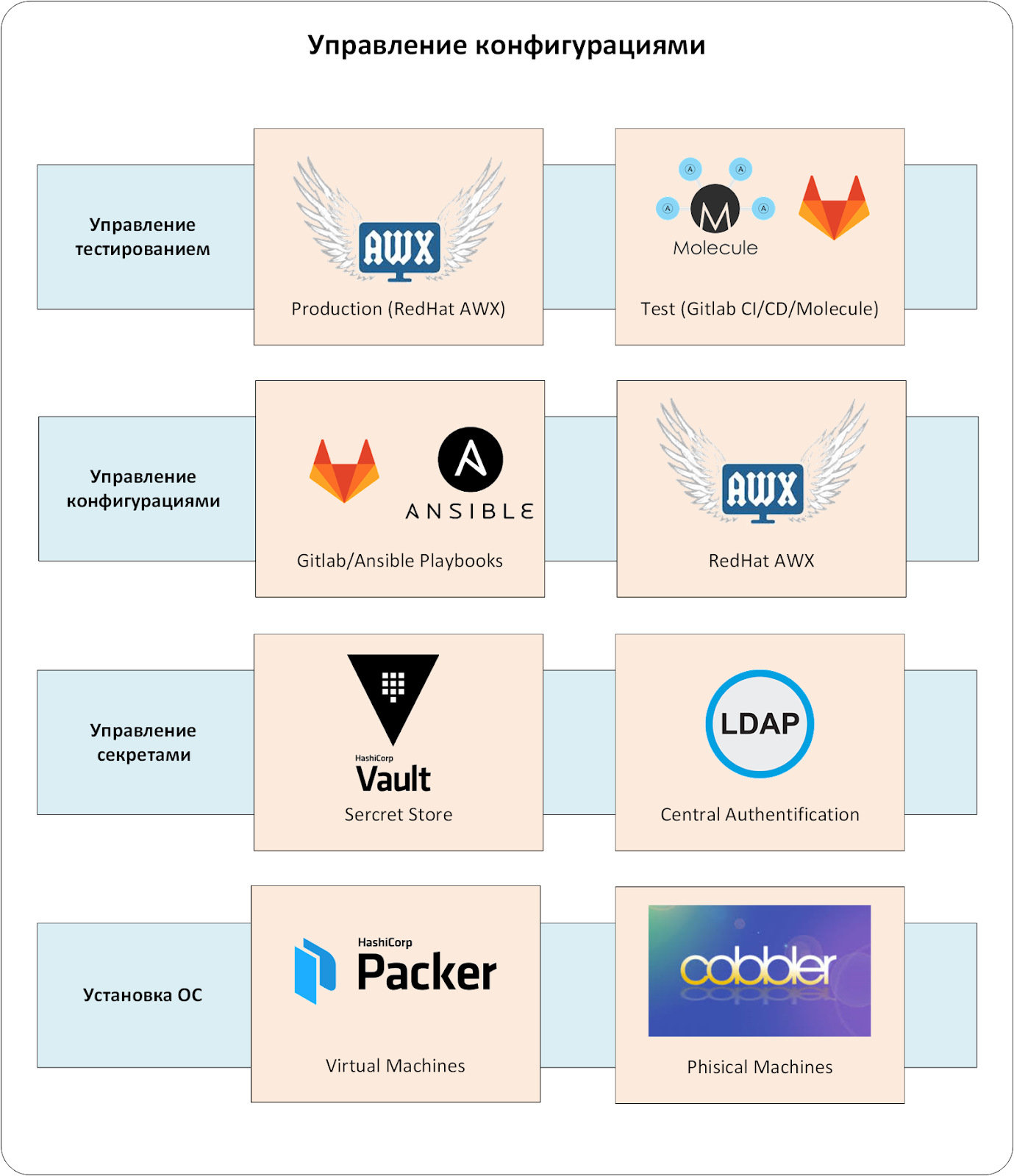
Figure: 6. Gestion des tests.
Dur? Je ne discute pas. Mais un tel complexe de gestion de configuration est devenu une réponse globale à de nombreuses questions liées à l'automatisation de la configuration des serveurs. Désormais, le revendeur a toujours une configuration strictement définie pour les serveurs standard. CMS, contrairement à un ingénieur, n'oubliera pas d'ajouter les paramètres nécessaires, de créer des utilisateurs et d'effectuer des dizaines ou des centaines de paramètres requis.
Il n'y a pas de «connaissance secrète» dans les paramètres des serveurs et des environnements aujourd'hui. Toutes les fonctionnalités nécessaires sont reflétées dans le playbook. Fini la créativité et les instructions vagues: « mettez-le comme un Oracle classique, mais là, vous devez enregistrer quelques paramètres sysctl et ajouter des utilisateurs avec l'UID requis. Demandez aux gars de l'opération, ils savent . "
La capacité de détecter les écarts dans les configurations et de les corriger à l'avance donne la tranquillité d'esprit. Sans CMS, cela semble généralement différent. Les problèmes s'accumulent jusqu'au jour où ils sont "tournés" en production. Puis un débriefing est effectué, les configurations sont vérifiées et corrigées. Et le cycle se répète à nouveau
Et bien sûr, nous avons accéléré le lancement des serveurs en production de quelques jours à quelques heures.
Eh bien, le soir du Nouvel An même, lorsque les enfants déballaient joyeusement des cadeaux et que les adultes faisaient des vœux pendant que le carillon sonnait, nos ingénieurs ont migré le système SAP vers de nouveaux serveurs. Même le Père Noël dira que les meilleurs miracles sont bien préparés.
PS Notre équipe est souvent confrontée au fait que les clients souhaitent résoudre le plus facilement possible le problème de la gestion des configurations. Idéalement, comme par magie - avec un seul outil. Mais dans la vie, tout est plus compliqué (oui, encore une fois, les balles d'argent n'ont pas été livrées): il faut créer tout un processus à l'aide d'outils pratiques pour l'équipe du client.
Auteur: Sergey Artemov, architecte du département DevOps-solutions de Jet Infosystems