Récemment, des collègues de la «boutique» ont commencé indépendamment les uns des autres à me demander: comment obtenir simultanément tous les canaux Bluetooth d'un même récepteur SDR? La bande passante le permet, il y a SDR avec une bande passante de sortie de 80 MHz ou plus. Vous pouvez, bien sûr, le faire sur les FPGA, mais le temps de développement sera assez long. Je sais depuis longtemps qu'il est assez facile de faire cela sur un GPU, mais oui!
La norme Bluetooth définit la couche physique en deux versions: Classic et Low Energy. La spécification est ici . Le document est terriblement volumineux; le lire dans son intégralité est dangereux pour le cerveau. Heureusement, les grandes entreprises d'instrumentation ont les moyens de créer des documents visuels sur un sujet. Tektronix et National Instruments , par exemple. Je n'ai absolument aucune chance de rivaliser avec eux en termes de qualité de présentation du matériel. Si vous êtes intéressé, veuillez suivre les liens.
Tout ce que j'ai besoin de savoir sur la couche physique pour créer un filtre multicanal est le pas de grille de fréquence et le taux de modulation. Ils sont regroupés dans l'un des documents suivants:
, 80 79 1 , , 40 2 . 1 2 , .
, .
Bluetooth Classic Bluetooth Low Energy. , . , "" . . , .
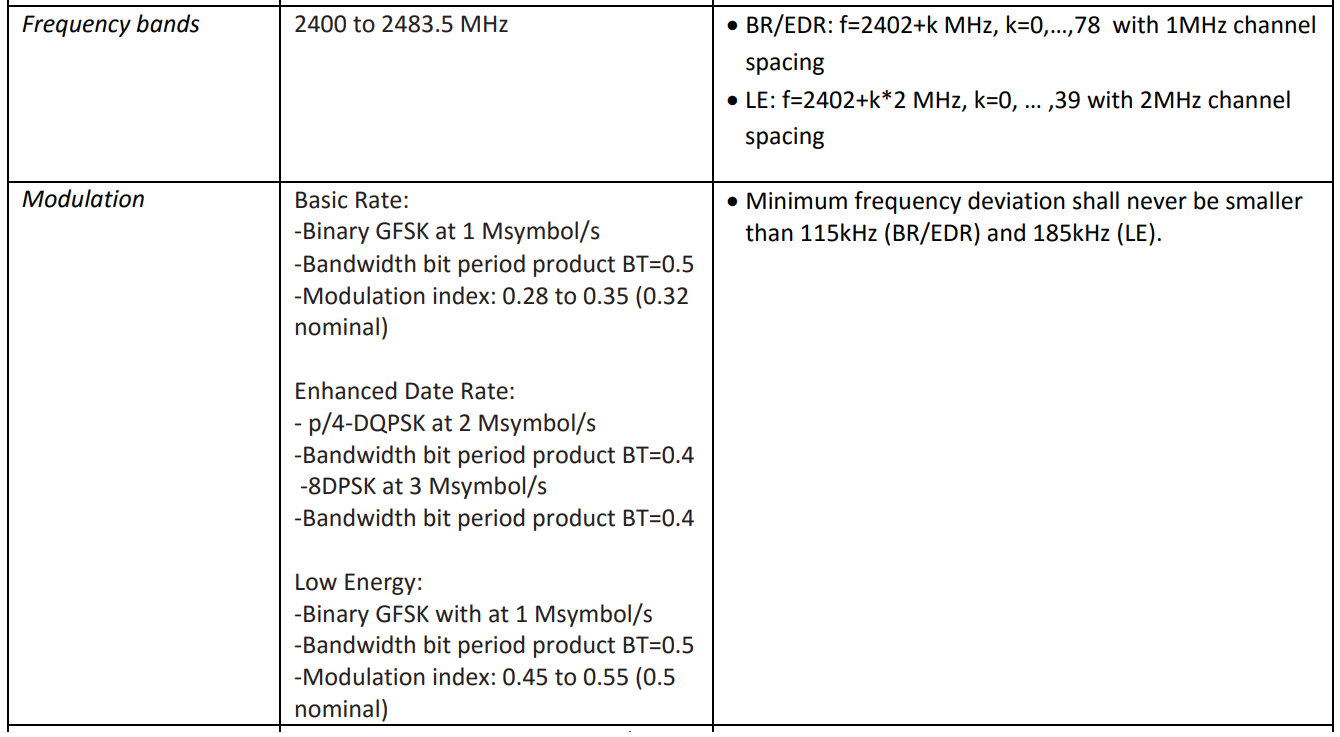
1 ( ) 500 , 480 . 2 1 240 , . . filterDesigner -header:
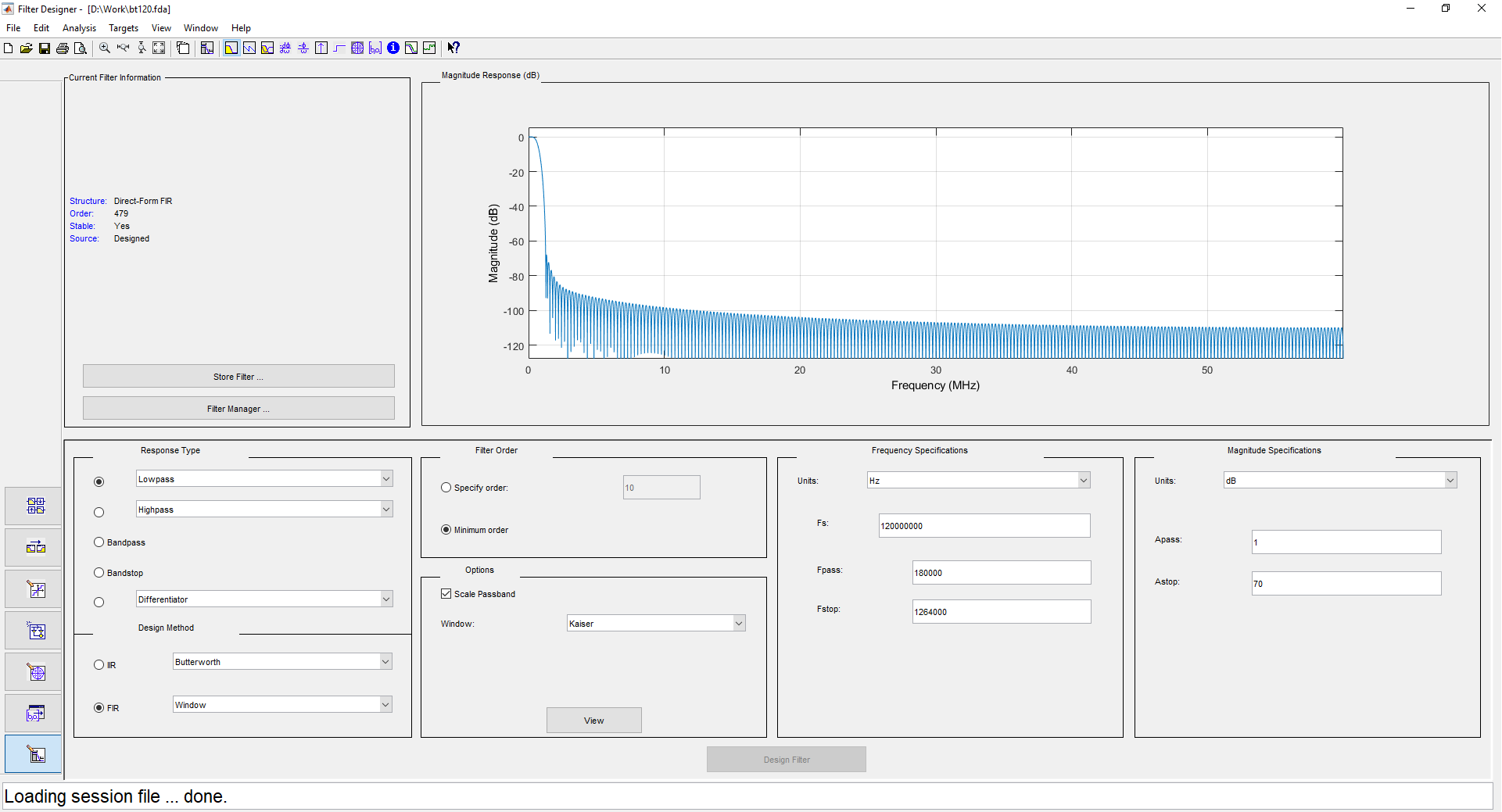
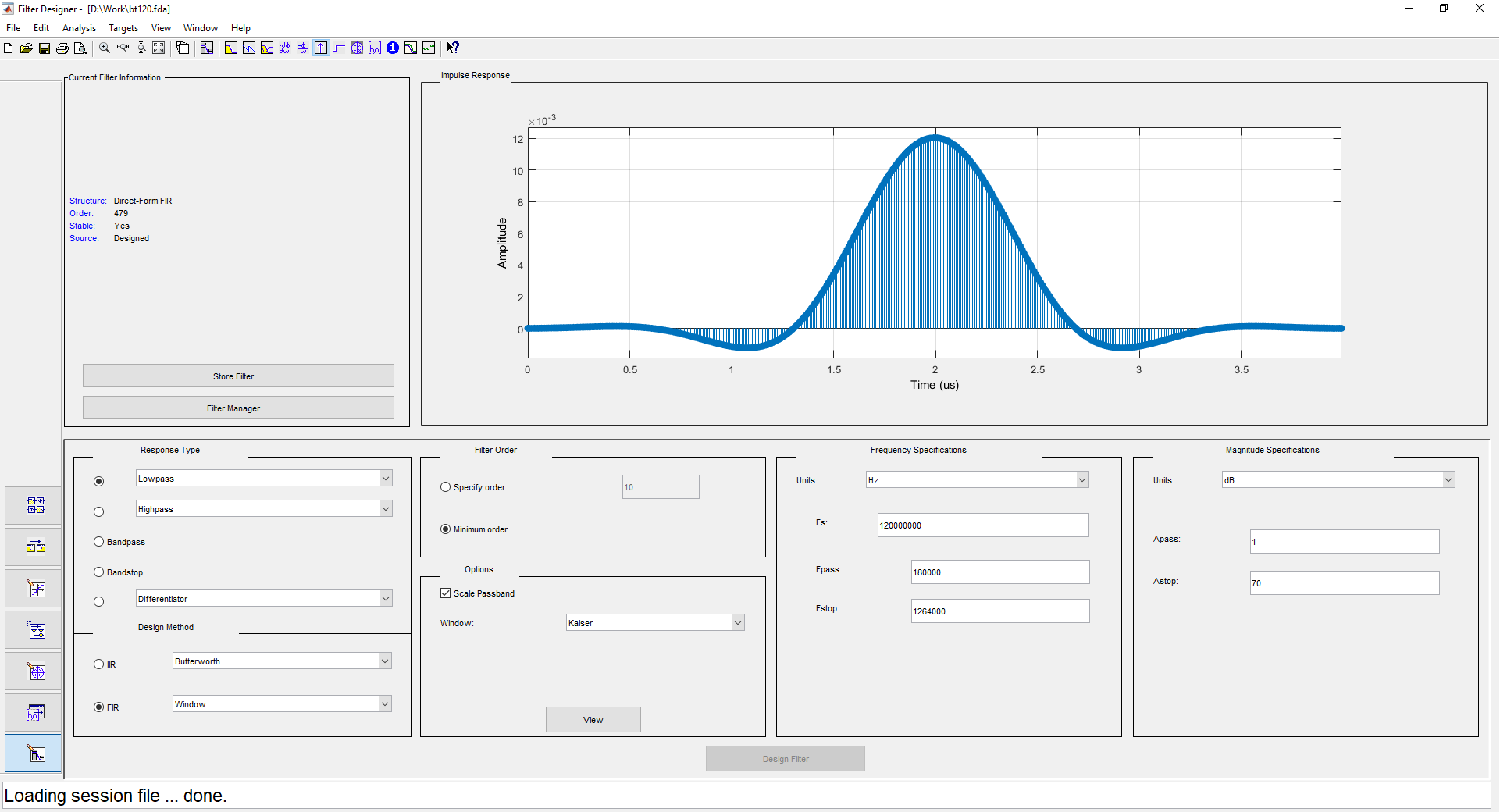
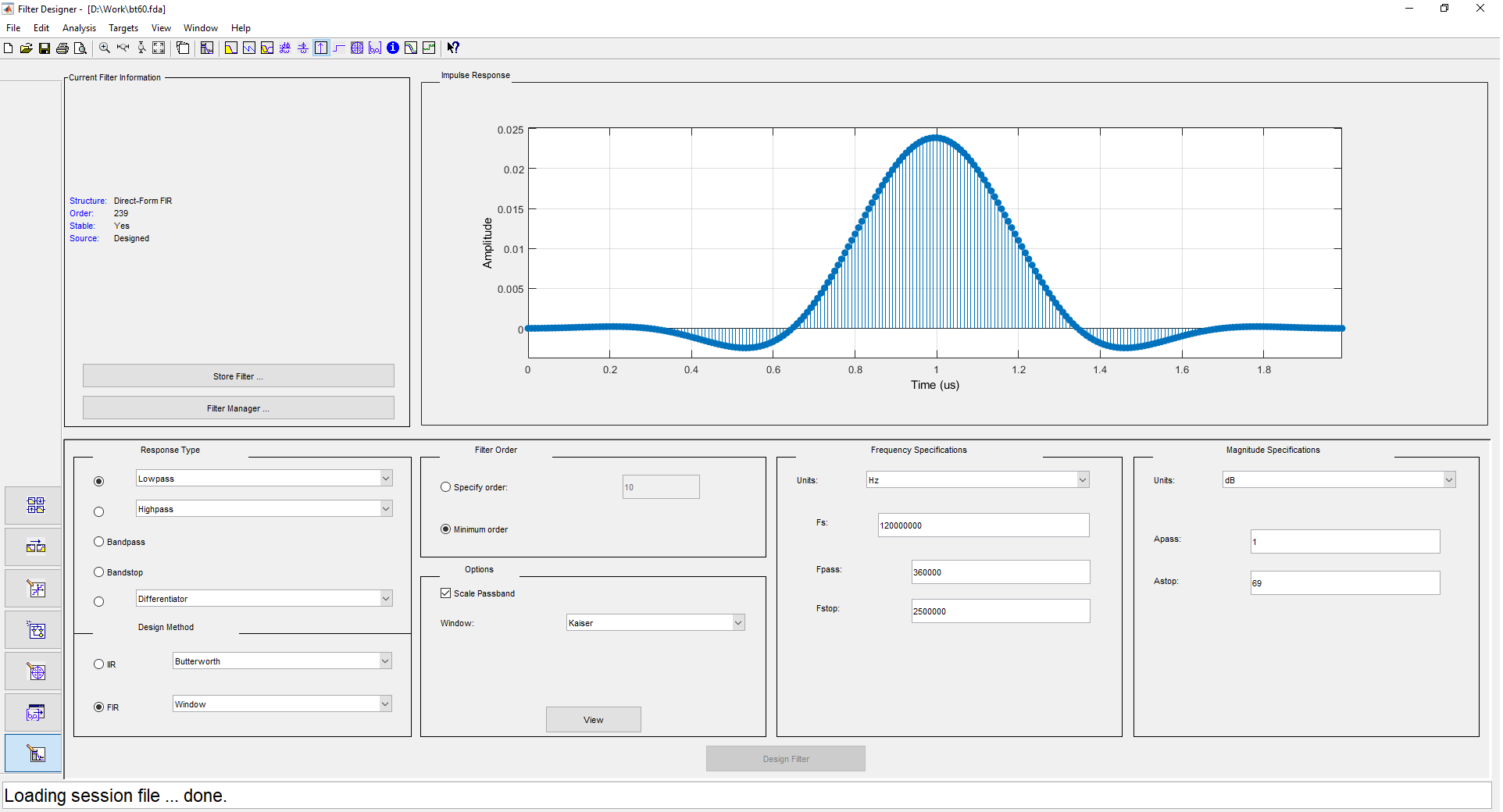
: DDC (Digital Down Converter). , . — - . .
GPU : , CUDA . Polyphase or WOLA (Weight, Overlap and Add) FFT Filterbank. . , 11 ( ), :
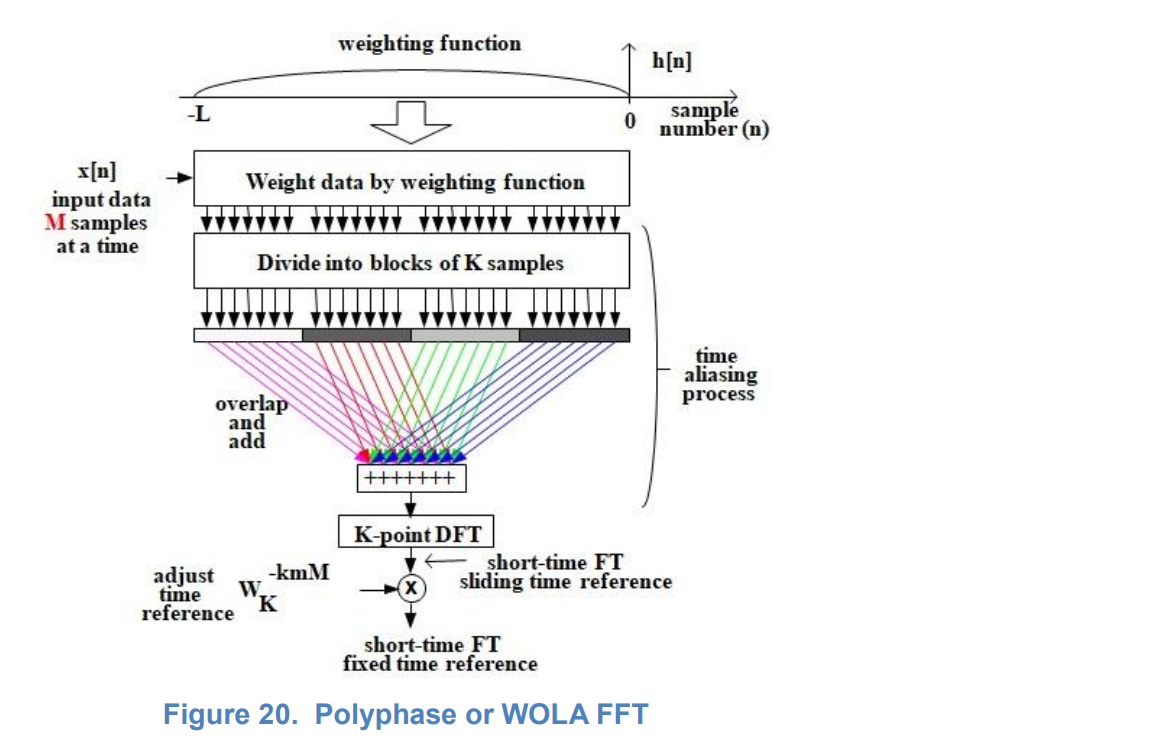
. , . , , . , . , , . . , ( ), . , . , , ,
, , .
, . " " FMC126P. . FMC AD9371 100 . .
- GPU GTX 1050. (, : , , ). .
, - . GPU. , .
, , :
__global__ void cuComplexMultiplyWindowKernel(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result) {
__shared__ cuComplex multiplicationResult[480];
multiplicationResult[threadIdx.x] = cuComplexMultiplyFloat(data[threadIdx.x + windowSize / 4 * blockIdx.x], window[threadIdx.x]);
__syncthreads();
cuComplex sum;
sum.x = sum.y = 0;
if (threadIdx.x < windowSize / 4) {
for(int i = 0; i < 4; i++) {
sum = cuComplexAdd(sum, multiplicationResult[threadIdx.x + i * windowSize / 4]);
}
result[threadIdx.x + windowSize / 4 * blockIdx.x] = sum;
}
}
cudaError_t cuComplexMultiplyWindow(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result, size_t dataSize, cudaStream_t stream) {
size_t windowStep = windowSize / 4;
cuComplexMultiplyWindowKernel<<<dataSize / windowStep - 3, windowSize, 1024, stream>>>(data, window, windowSize, result);
return cudaGetLastError();
}
, , , , .
. AD9371 2450 , .
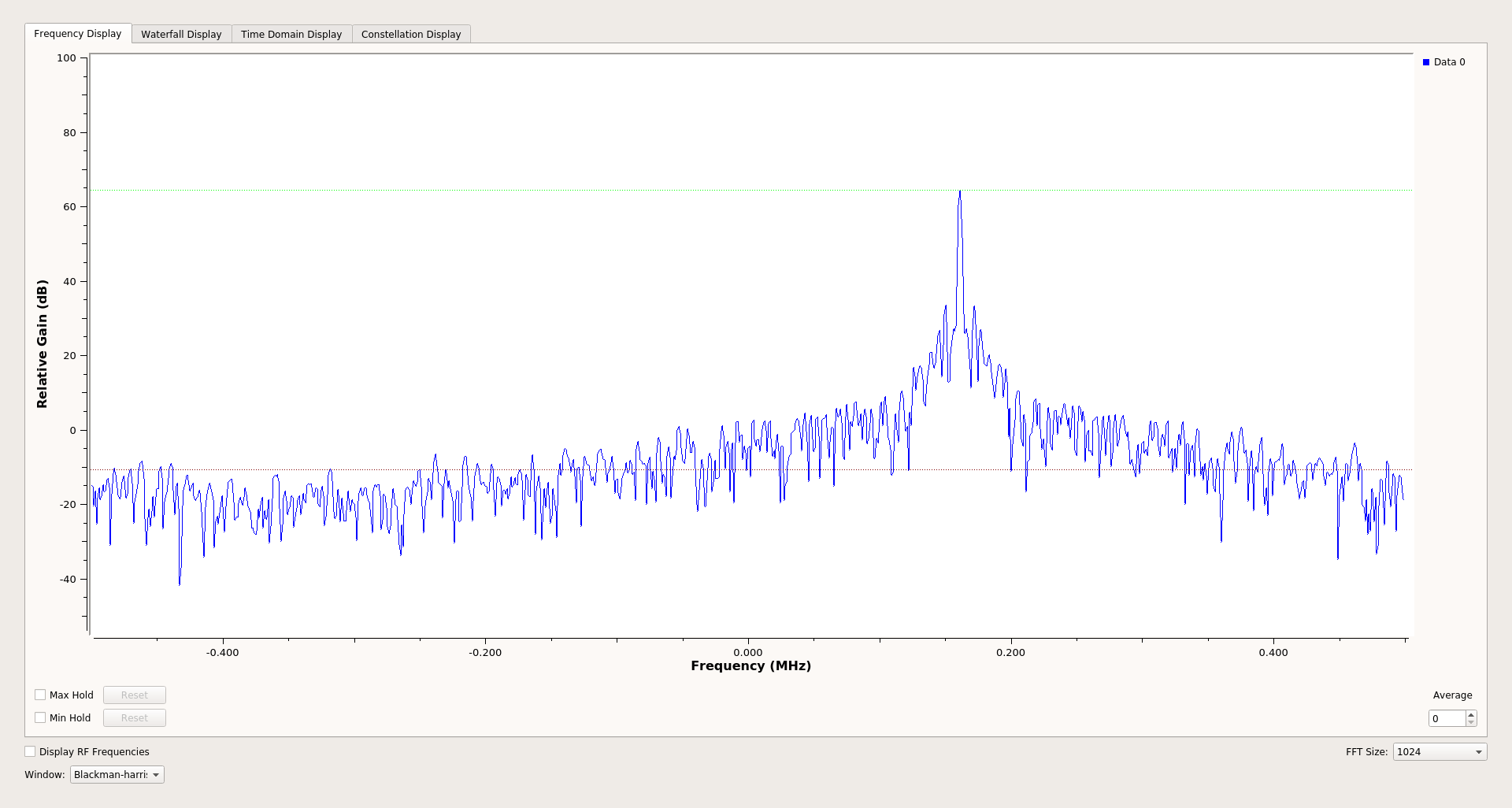
: XRTX , - .
gaudima, !