Bonjour, Habr! Dans cet article, je vais vous montrer comment faire une analyse de fréquence de la langue Internet russe moderne et l'utiliser pour déchiffrer le texte. Peu importe, bienvenue sous la coupe!

Analyse de fréquence de la langue Internet russe
Le réseau social Vkontakte a été pris comme source à partir de laquelle vous pouvez obtenir beaucoup de texte avec une langue Internet moderne, ou pour être plus précis, ce sont des commentaires sur des publications dans diverses communautés de ce réseau. J'ai choisi le vrai football en tant que communauté . Pour analyser les commentaires, j'ai utilisé l'API Vkontakte :
def get_all_post_id():
sleep(1)
offset = 0
arr_posts_id = []
while True:
sleep(1)
r = requests.get('https://api.vk.com/method/wall.get',
params={'owner_id': group_id, 'count': 100,
'offset': offset, 'access_token': token,
'v': version})
for i in range(100):
post_id = r.json()['response']['items'][i]['id']
arr_posts_id.append(post_id)
if offset > 20000:
break
offset += 100
return arr_posts_id
def get_all_comments(arr_posts_id):
offset = 0
for post_id in arr_posts_id:
r = requests.get('https://api.vk.com/method/wall.getComments',
params={'owner_id': group_id, 'post_id': post_id,
'count': 100, 'offset': offset,
'access_token': token, 'v': version})
for i in range(100):
try:
write_txt('comments.txt', r.json()
['response']['items'][i]['text'])
except IndexError:
passLe résultat était d'environ 200 Mo de texte. Maintenant, nous comptons quel caractère apparaît combien de fois:
f = open('comments.txt')
counter = Counter(f.read().lower())
def count_letters():
count = 0
for i in range(len(arr_letters)):
count += counter[arr_letters[i]]
return count
def frequency(count):
arr_my_frequency = []
for i in range(len(arr_letters)):
frequency = counter[arr_letters[i]] / count * 100
arr_my_frequency.append(frequency)
return arr_my_frequencyLes résultats obtenus peuvent être comparés aux résultats de Wikipédia et affichés sous la forme:
1) tableau de comparaison
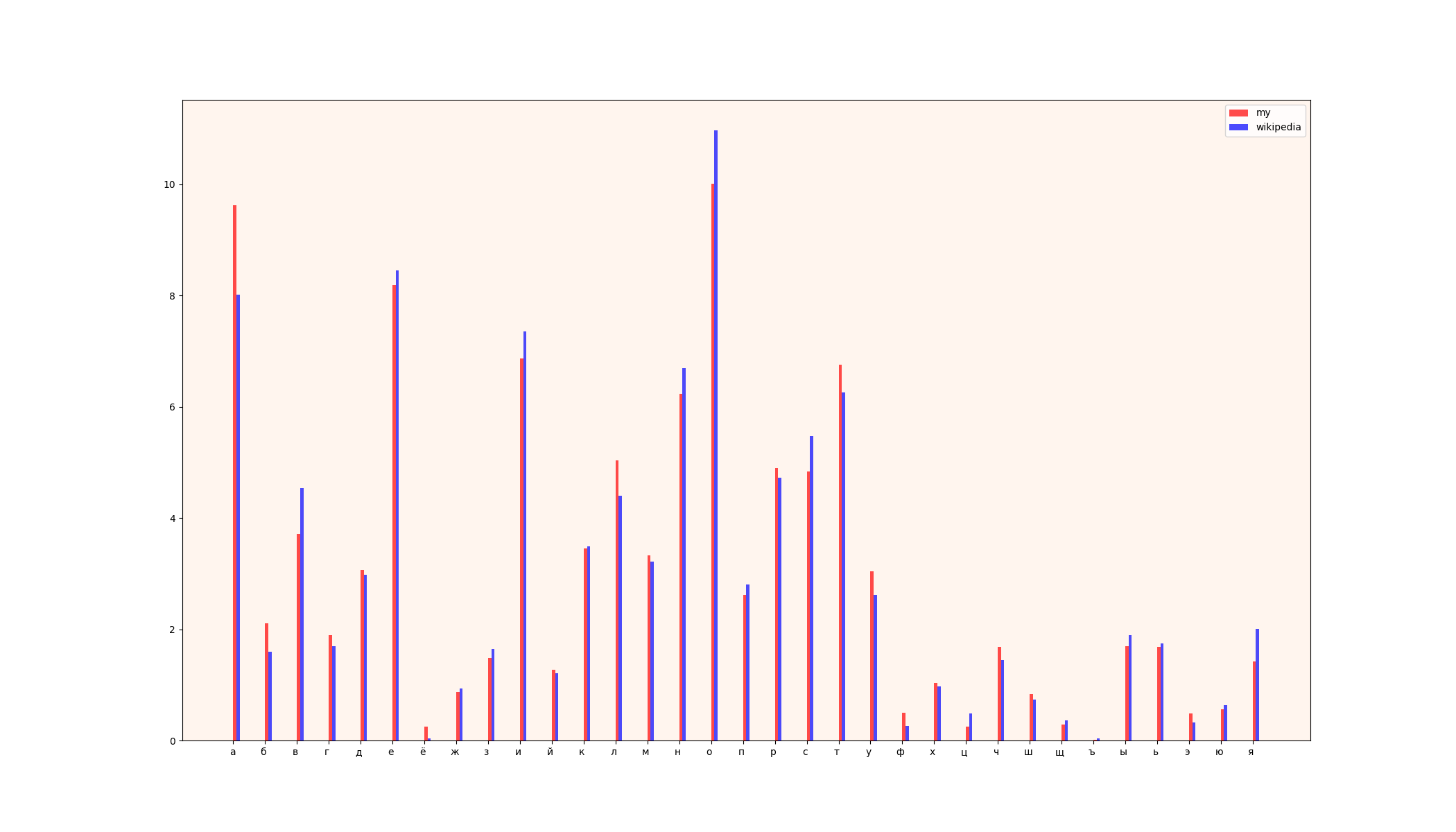
2) tableaux (à gauche - données wikipedia, à droite - mes données)
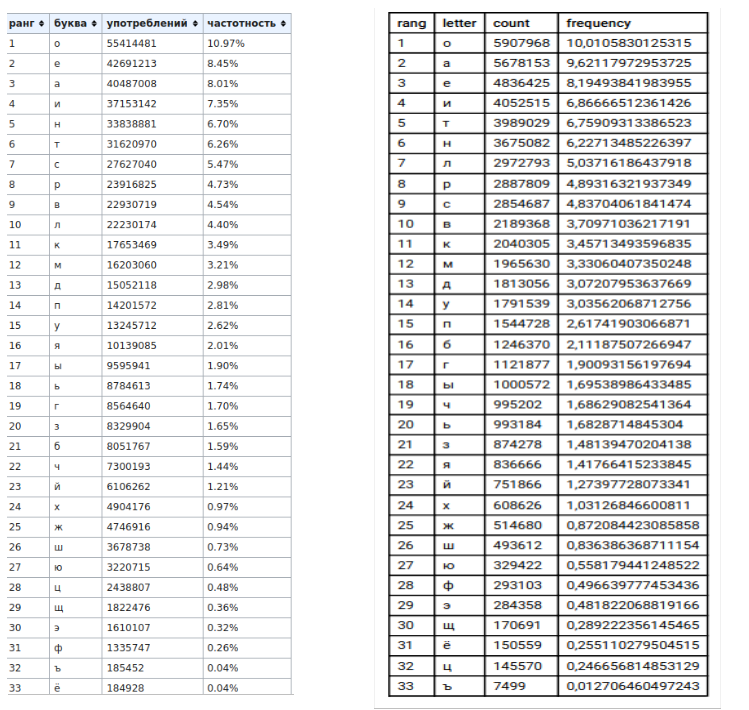
, , , «» «».
, , 2-4 :

, , , , , , , , ,
- . , — , , :
def caesar_cipher():
file = open("text.txt")
text_for_encrypt = file.read().lower().replace(',', '')
letters = ''
arr = []
step = 3
for i in text_for_encrypt:
if i == ' ':
arr.append(' ')
else:
arr.append(letters[(letters.find(i) + step) % 33])
text_for_decrypt = ''.join(arr)
return text_for_decrypt
:
def decrypt_text(text_for_decrypt, arr_decrypt_letters):
arr_encrypt_text = []
arr_encrypt_letters = [' ', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '',
'', '', '']
dictionary = dict(zip(arr_decrypt_letters, arr_encrypt_letters))
for i in text_for_decrypt:
arr_encrypt_text.append(dictionary.get(i))
text_for_decrypt = ''.join(arr_encrypt_text)
print(text_for_decrypt)
Si vous regardez le texte déchiffré, vous pouvez deviner où notre algorithme a mal tourné: combats → fait, vadio → radio, puisho → addition, submerger → les gens. Ainsi, il est possible de déchiffrer tout le texte, au moins de saisir le sens du texte. Je tiens également à noter que cette méthode sera efficace pour déchiffrer uniquement les longs textes qui ont été cryptés avec des méthodes de cryptage symétriques. Le code complet est disponible sur Github .