Par conséquent, à l'intérieur de chaque processus séparé, il n'y a pas de problèmes "étranges" traditionnels avec l'exécution de code parallèle, les verrous, les conditions de course , ... Et le développement du SGBD lui-même est agréable et simple.
Mais la même simplicité impose une limitation importante. Puisqu'il n'y a qu'un seul thread de travail dans le processus, il ne peut pas utiliser plus d'un cœur de processeur pour exécuter une requête , ce qui signifie que la vitesse du serveur dépend directement de la fréquence et de l'architecture d'un cœur distinct.
À notre époque de la fin de la «course du mégahertz» et des systèmes multicœurs et multiprocesseurs victorieux, un tel comportement est un luxe et un gaspillage inadmissibles. Par conséquent, à partir de PostgreSQL 9.6, lors du traitement d'une requête, certaines opérations peuvent être effectuées par plusieurs processus simultanément.
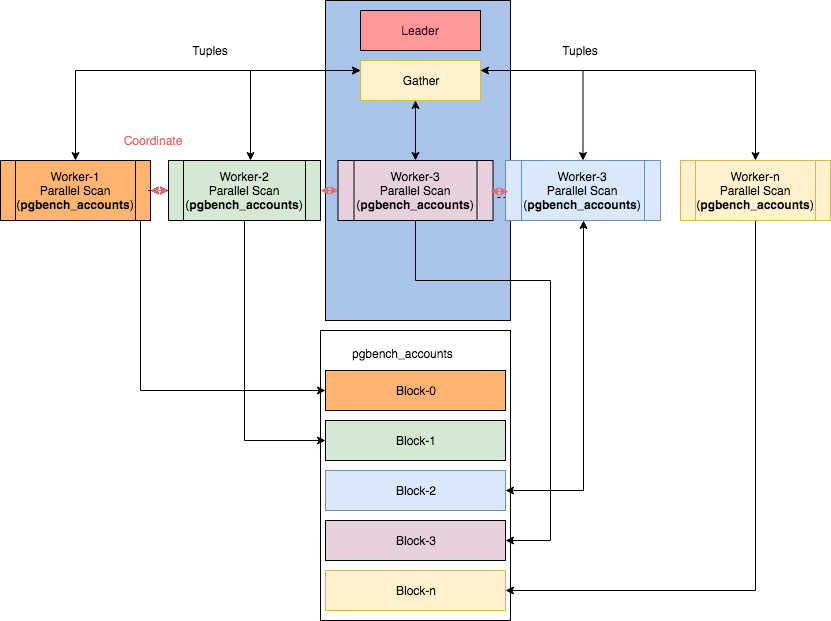
Quelques nœuds parallèles peuvent être trouvés dans l'article "Parallelism in PostgreSQL" d'Ibrar Ahmed, d'où provient cette image.Cependant, dans ce cas, il devient… non trivial de lire les plans.
En bref, la chronologie de la mise en œuvre de l'exécution parallèle des opérations du plan ressemble à ceci:
- 9.6 - Fonctionnalité de base: Seq Scan , Join, Aggregate
- 10 - Analyse d'index (pour btree), analyse de tas bitmap, jointure de hachage, jointure de fusion, analyse de sous-requête
- 11 - opérations de groupe : Hash Join avec table de hachage partagée, Append (UNION)
- 12 - Statistiques de base par travailleur sur les nœuds de plan
- 13 - Statistiques détaillées par travailleur
Par conséquent, si vous utilisez l'une des dernières versions de PostgreSQL, les chances de la voir dans le plan sont
Parallel ...très élevées. Et avec lui, ils viennent et ...
Bizarreries au fil du temps
Prenons un plan de PostgreSQL 9.6 :
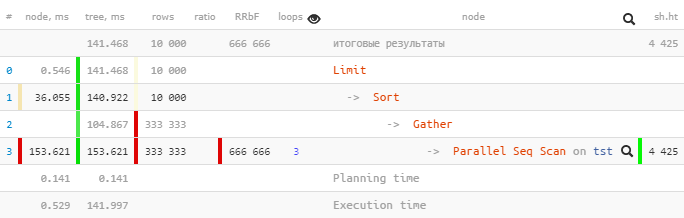
[regardez explic.tensor.ru]
Un seul a été
Parallel Seq Scanexécuté 153,621 ms dans un sous-arbre, et Gatheravec tous les sous-nœuds - seulement 104,867 ms.
Comment? Le temps total "à l'étage" est-il devenu moins important? ..
Jetons un coup d'œil au
Gather-node plus en détail:
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425Workers Launched: 2nous dit qu'en plus du processus principal en bas de l'arbre, 2 autres processus supplémentaires ont été impliqués - un total de 3. Par conséquent, tout ce qui s'est passé à l'intérieur du Gathersous-arbre est la créativité totale des 3 processus à la fois.
Voyons maintenant ce qu'il y a dedans
Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425Ah!
loops=3Est un résumé des 3 processus. Et, en moyenne, chaque cycle de ce type a duré 51,207 ms. Autrement dit, au total, il a fallu au serveur des 51.207 x 3 = 153.621millisecondes de temps processeur pour traiter ce nœud . Autrement dit, si nous voulons comprendre «ce que faisait le serveur», c'est ce nombre qui nous aidera à comprendre.
Notez que pour comprendre le temps d' exécution "réel" , vous devez diviser le temps total par le nombre de travailleurs, c'est-à-dire [actual time] x [loops] / [Workers Launched].
Dans notre exemple, chaque worker n'a donc effectué qu'un seul cycle à travers le nœud
153.621 / 3 = 51.207. Et oui, maintenant il n'y a rien d'étrange que le seul Gatherdans le processus de tête ait été achevé en «pour ainsi dire, en moins de temps».
Total: regardez le temps total (pour tous les processus) sur le nœud pour comprendre le type de charge avec lequel votre serveur était occupé et pour optimiser quelle partie de la requête vaut la peine de passer du temps.
En ce sens, le comportement de la même explic.depesz.com , montrant le temps "réel moyen" à la fois, semble moins utile à des fins de débogage:
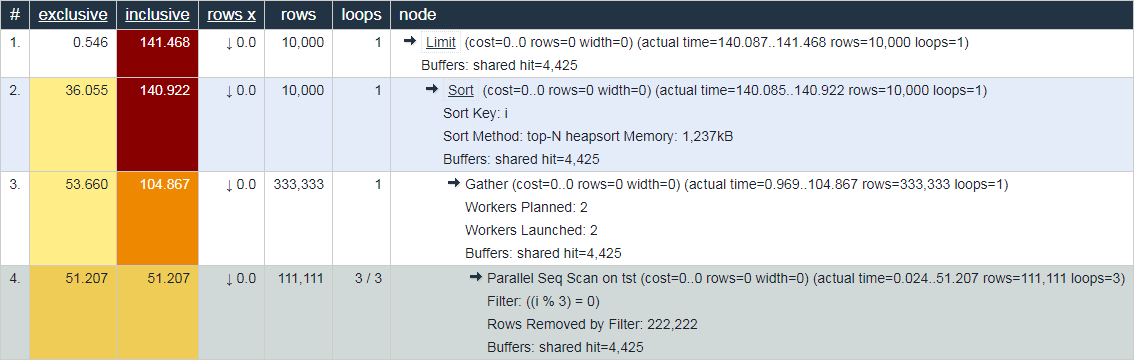
Vous n'êtes pas d'accord? Bienvenue aux commentaires!
Gather Merge perd tout
Maintenant, exécutons la même requête pour les versions de PostgreSQL 10 :
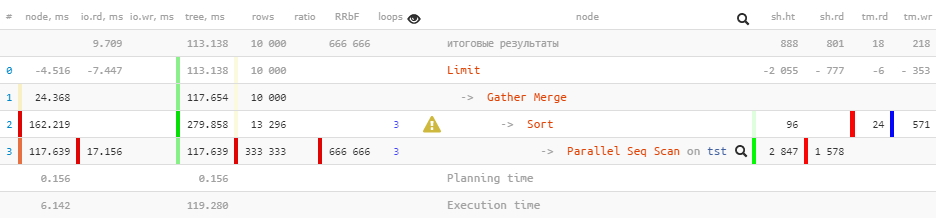
[regardez expliquer.tensor.ru]
Notez que nous avons
Gathermaintenant un nœud au lieu d'un nœud dans le plan Gather Merge. Voici ce que dit le manuel à ce sujet :
Lorsqu'un nœud est au-dessus de la partie parallèle du planGather Merge, au lieu deGather, cela signifie que tous les processus exécutant des parties du plan parallèle produisent des tuples dans l'ordre trié et que le processus principal effectue une fusion préservant l'ordre. Le nœudGather, par contre, reçoit des tuples des processus subordonnés dans un ordre arbitraire qui lui convient, violant l'ordre de tri qui pourrait exister.
Mais tout ne va pas bien dans le royaume danois:
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156Lors de la transmission des attributs
Bufferset I/O Timingsde l'arborescence, certaines des données ont été perdues prématurément . Nous pouvons estimer la taille de cette perte à environ 2/3 , qui sont formées par des processus auxiliaires.
Hélas, dans le plan lui-même, il n'y a nulle part pour obtenir ces informations - d'où les "moins" sur le nœud sus-jacent. Et si vous regardez l'évolution ultérieure de ce plan dans PostgreSQL 12 , cela ne change pas fondamentalement, sauf que certaines statistiques sont ajoutées pour chaque worker sur le
Sortnœud:
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 msTotal: ne faites pas confiance aux données du nœud ci-dessus
Gather Merge.