introduction
Comme c'est souvent le cas, un architecte de base de données doit développer une base de données pour une solution spécifique.
Un vendredi soir, dans le train de retour du travail, j'ai réfléchi à la façon dont je créerais un service d'embauche d'employés dans différentes entreprises. Après tout, aucun des services existants ne vous permet de comprendre rapidement à quel point un candidat vous convient. Il n'est pas possible de créer des filtres complexes qui incluent ou excluent un ensemble de compétences, projets ou postes spécifiques. Les plus que les services offrent généralement sont des filtres par entreprise et en partie par compétence.
Dans cet article, je vais me permettre de diluer légèrement la présentation stricte du matériau en mélangeant des informations techniques avec des exemples non techniques de la vie.
Pour commencer, analysons la création d'une base de données dans MS SQL Server pour le service de recherche d'emploi.
Ce matériel peut être transféré vers un autre SGBD tel que MySQL ou PostgreSQL.
Principes de base des règles de conception
Pour concevoir un schéma de base de données, vous devez vous souvenir de 7 règles formelles et du concept même de normalisation et de dénormalisation. Ils sont à la base de toutes les règles de conception.
Décrivons plus en détail 7 règles formelles:
- relation
individuelle : 1.1) avec une connexion obligatoire:
un exemple peut être un citoyen et son passeport: tout citoyen doit avoir un passeport; un passeport pour chaque citoyen
Cette relation peut être mise en œuvre de deux manières:
1.1.1) dans une entité (tableau): Fig.1. Entité citoyenne Ici, la table Citizen est une entité citoyenne, et l'attribut PassportData (champ) contient toutes les données de passeport d'un citoyen et ne peut pas être vide (NOT NULL). 2) dans deux entités différentes (tableaux): Fig.2. Relation entre les entités Citizen et PassportData


Ici, la table Citizen est l'entité citoyenne et la table PassportData est l'entité de données du passeport du citoyen (le passeport lui-même). L'entité citoyenne contient un attribut PassportID (champ) qui fait référence à la clé primaire de la table PassportData. À son tour, l'entité de données de passeport contient l'attribut (champ) CitizenID, qui fait référence à la clé primaire CitizenID de la table Citizen. Le champ PassportID de la table des citoyens ne peut pas être vide (NON NULL). Il est également important de maintenir l'intégrité du champ CitizenID de la table PassportData pour garantir une relation un-à-un. En d'autres termes, le champ PassportID de la table Citizen et le champ CitizenID de la table PassportData doivent faire référence aux mêmes enregistrements que s'il s'agissait de la même entité (table) présentée dans la clause 1.1.1.
1.2) avec un lien optionnel:
un exemple serait une personne avec ou sans passeport pour un pays particulier. Dans le premier cas, il sera citoyen du pays en question, et dans le second, il ne le sera pas.
Cette relation peut être mise en œuvre de deux manières:
1.2.1) dans une seule entité (tableau): Fig.3. Entité Person La table Person est l'entité d'une personne et l'attribut PassportData (champ) contient toutes ses données de passeport et peut être vide (NULL). 2) en deux entités (tableaux): Fig.4. Relation entre les entités Person et PassportData

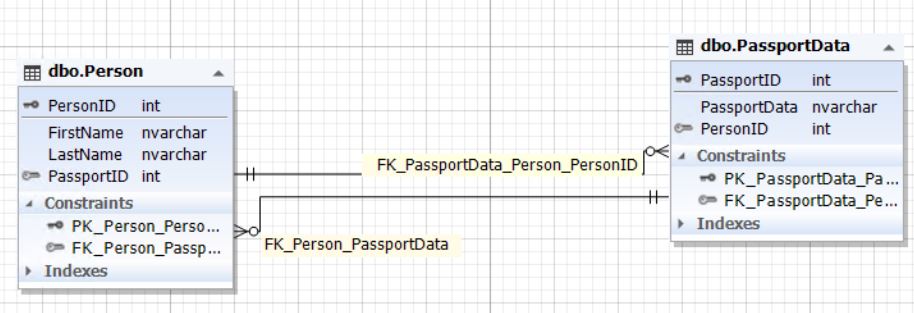
La table Person est l'entité de la personne et la table PassportData est l'entité de données du passeport de la personne (le passeport lui-même). L'entité humaine contient un attribut PassportID (champ) qui fait référence à la clé primaire de la table PassportData. À son tour, l'identité des données du passeport contient l'attribut (champ) PersonID, qui fait référence à la clé primaire PersonID de la table Person. Le champ PassportID de la table Person peut être NULL. Il est également important de maintenir l'intégrité du champ PersonID de la table PassportData. Ceci est nécessaire pour assurer une communication individuelle. Le champ PassportID de la table Person et le champ PersonID de la table PassportData doivent faire référence aux mêmes enregistrements que s'il s'agissait de la même entité (table) indiquée dans la clause 1.2.1. Ou, ces champs doivent être NULL, c'est-à-dire contenir NULL.
- :
2.1) :
. .
:
2.1.1) ():
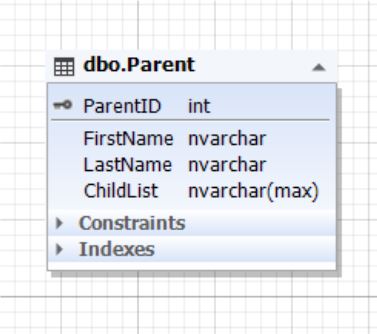
.5. Parent
Parent , () ChildList . (NOT NULL). ChildList (NoSQL) XML, JSON .
2.1.2) ():
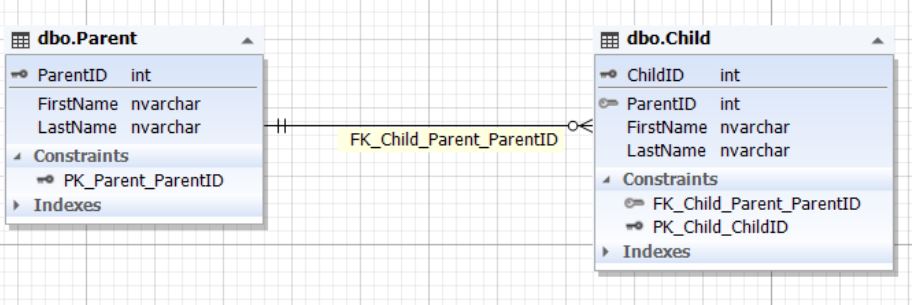
.6. Parent Child
Parent , Child — . Child ParentID, ParentID Parent. ParentID Child (NOT NULL).
2.2) :
, .
:
2.2.1) ():
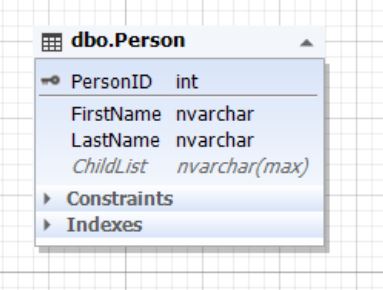
.7. Person
Parent , () ChildList . (NULL). ChildList (NoSQL) XML, JSON .
2.2.2) ():
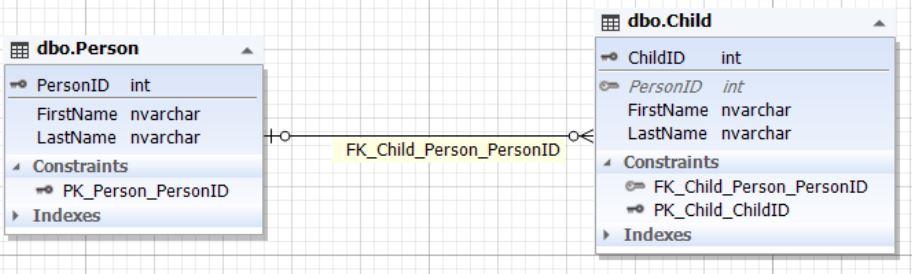
.8. Person Child
Parent , Child — . Child ParentID, ParentID Parent. ParentID Child (NULL).
2.2.3) , () () :

.9. Person
() Person () ParentID, PersonID Person (NULL).
« » .
- :
. , «» «», , . , , .
- :
: , . , .
, NoSQL, , . , 3 ():
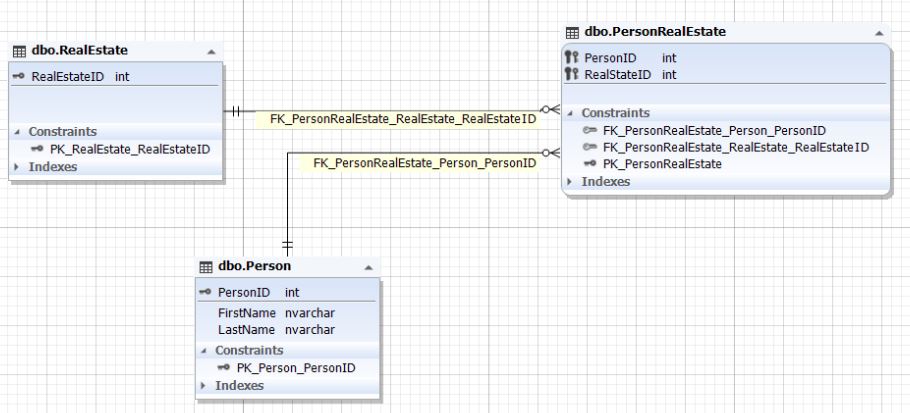
.10. Person RealEstate
Person RealEstate . () () PersonRealEstate. () PersonID RealEstateID PersonID Person RealEstateID RealEstate . , PersonRealEstate (PersonID; RealEstateID) PersonRealEstate.
. , . , 1.1.2 1.2.2.
Les relations un-à-plusieurs et plusieurs-à-un peuvent être implémentées via plus de deux entités. Pour cela, les attributs nécessaires sont ajoutés, qui font référence aux clés primaires des entités correspondantes nécessaires. Cette implémentation est similaire aux exemples décrits ci-dessus aux paragraphes 1.1.2 et 1.2.2.
Où sont les sept règles formelles?
Les voici:
- Clause 1 (Clause 1.1 et Clause 1.2) - les première et deuxième règles formelles
- Clause 2 (Clause 2.1 et Clause 2.2) - les troisième et quatrième règles formelles
- clause 3 (similaire à la clause 2) - les cinquième et sixième règles formelles
- point 4 - septième règle formelle
Dans le texte ci-dessus, ces sept règles formelles sont regroupées en quatre blocs fonctionnels.
Lorsque vous parlez de normalisation , vous devez comprendre son essence. La normalisation conduit à une diminution de la répétabilité du stockage des informations, et donc à une diminution de la possibilité d'anomalies dans les données. Cependant, la normalisation lors du fractionnement d'entités conduit à des constructions de requêtes plus complexes pour la manipulation des données (insertions, modifications, sélection et suppression).
Le processus de normalisation inverse est appelé dénormalisation . Il s'agit d'une simplification de la création de requêtes d'accès aux données en raison de l'agrégation et de l'imbrication d'entités (par exemple, comme indiqué ci-dessus dans les clauses 2.1.1 et 2.2.1 en utilisant des données incomplètement structurées (NoSQL)).
C'est tout l'intérêt des règles de conception de bases de données.
Êtes-vous sûr de comprendre la relation en sept règles formelles? Avez-vous compris et n'avez pas reconnu? Après tout, connaître et comprendre sont deux concepts complètement différents.
Je vais vous expliquer plus en détail. Posez-vous la question: pouvez-vous esquisser un modèle de base de données, bien que agrandi par entités, pour n'importe quel domaine et pour n'importe quel système d'information en quelques heures? (les subtilités et les détails peuvent être complétés en interrogeant les analystes et les représentants des clients). Si la question vous surprend et que vous pensez que cela est impossible, alors vous connaissez les sept règles formelles, mais ne les comprenez pas.
Pour une raison quelconque, de nombreuses sources ignorent le fait que ces relations n'ont pas été inventées, mais révélées. Ils existent initialement dans le monde réel à la fois entre sujets et entre sujets et objets.
De plus, cette relation peut changer, passant deun à un à un à plusieurs , plusieurs à un ou plusieurs à plusieurs . L'obligation de communication peut changer ou rester inchangée.
Permettez-moi de vous parler d'un cas où, à partir de la connaissance des sept règles formelles, j'en suis venu à comprendre ces relations.
À un moment donné, j'étais gêné par le fait qu'à l'université je connaissais ces sept règles formelles, mais dans la pratique industrielle (l'université envoie des étudiants dans différentes entreprises pour acquérir une expérience professionnelle) pendant très longtemps j'ai construit des modèles de bases pour différents domaines. J'y ai pensé et j'ai réalisé que je ne comprenais pas cette relation.
Observer les gens m'a aidé, et l'essence de la relation a été révélée dans un rêve. Je vais raconter ce rêve sous une forme simplifiée: seulement ce qui vous permet de mieux comprendre ces sept règles formelles - sans détailler tout le reste.
Le rêve était celui d'une famille avec un père, une mère et des enfants. Le père meurt dans un accident de voiture, la mère commence à boire et les enfants sont finalement emmenés à l'orphelinat. Ces enfants sont laissés sans parents pendant longtemps. Ensuite, certains enfants ont des tuteurs, il y en a plusieurs aussi.
Avez-vous retracé le type de relations entre les sujets et comment ces relations ont changé?
Regardons de plus près.
- Lorsque la famille était complète, avec plusieurs enfants, la relation entre les parents et les enfants était multiple .
- , . , , , , .
- .
- — .
- , : , ().
La relation entre mari et femme est un à un avec un lien obligatoire dans le mariage formel ou un à un avec un lien facultatif avant l'enregistrement. Il ne peut y avoir qu'une seule femme, tout comme il ne peut y avoir qu'un seul mari. Au moins en Russie. Mais dans un autre pays, la polygamie est possible, et alors la relation entre mari et femmes sera une à plusieurs , et entre les femmes et le mari - plusieurs pour un .
J'espère que vous êtes maintenant beaucoup plus près de comprendre ces sept règles formelles.
Cela vaut la peine d'être constamment pratiqué: observer les gens et identifier les relations existantes à la fois entre les sujets et entre les sujets et les objets. Ce qui précède décrit le citoyen et son passeport comme une relation individuelle avec un lien obligatoire... Dans le même temps, un exemple d'une personne et de son passeport est une relation individuelle avec un lien facultatif .
Après avoir compris les sept règles formelles, vous pouvez facilement concevoir un modèle de base de données de toute complexité pour n'importe quel système d'information.
Vous verrez également qu'il existe de nombreuses façons de mettre en œuvre une relation et que la relation elle-même peut changer. Un modèle de base de données (schéma) est un instantané des relations entre les entités à un moment donné. C'est pourquoi il est important de déterminer à la fois les entités elles-mêmes - des images d'objets du monde réel ou du domaine, et leur relation les uns avec les autres, en tenant compte des changements à venir.
Un modèle de base de données bien conçu, prenant en compte l'évolution des relations dans la réalité ou dans le domaine, n'aura pas besoin de changer pendant des années, voire des décennies. Ceci est particulièrement important pour les entrepôts de données, où les changements impliquent de réenregistrer de grandes quantités de données (de plusieurs gigaoctets à plusieurs téraoctets).
Il est important de se rappeler que les tables d'un modèle relationnel sont des relations d'entité et que les lignes (tuples) sont des instances de ces relations. Mais pour faciliter les choses, les tables sont souvent considérées comme des entités et les lignes de table sont des instances d'entité. Leur relation s'exprime à travers des relations sous forme de clés étrangères.
Conception d'un schéma de base de données pour rechercher des candidats
Après avoir couvert les bases des règles de conception de base de données dans la première partie, créons un schéma de base de données pour trouver des candidats.
Pour commencer, définissons ce qui est important pour les employés de l'entreprise qui recherchent des candidats:
- pour les RH:
1.1) l'entreprise dans laquelle le candidat a travaillé
1.2) les postes précédemment occupés par le candidat dans ces entreprises
1.3) les compétences et les capacités que le candidat a utilisées dans son travail;
ainsi que la durée de l'emploi du candidat dans chaque entreprise dans chaque poste et la durée d'utilisation de chaque compétence et capacité
- pour un spécialiste technique:
2.1) les postes occupés par le candidat dans ces entreprises;
2.2) les compétences et aptitudes utilisées par le candidat dans son travail;
2.3) les projets auxquels le candidat a participé;
ainsi que la durée de travail du candidat dans chaque poste et dans chaque projet, la durée d'utilisation de chaque compétence et capacité
Tout d'abord, identifions les entités nécessaires:
- Employé
- Compagnie
- Position (position)
- Projet
- Compétence
- Les entreprises et les employés sont comme beaucoup , car un employé peut travailler dans plusieurs entreprises et de nombreuses personnes travaillent pour l'entreprise.
- Les postes et les salariés sont liés de manière similaire: plusieurs salariés peuvent occuper un même poste à la fois au sein d'une ou plusieurs entreprises.
- , , . , — .
- : .
- , .
- .
Puisqu'il est très important d'enregistrer depuis combien de temps un employé a travaillé dans un poste particulier dans une entreprise particulière, ainsi que sur chaque projet, le schéma de notre base de données peut être le suivant: Fig.11. Schéma de base de données pour rechercher des candidats à un emploi Ici, la table JobHistory agit comme l'entité de l'historique d'emploi de chaque demandeur d'emploi. Autrement dit, il s'agit d'un CV qui introduit des relations plusieurs-à-plusieurs entre l'employé, l'entreprise, le poste et le projet de l'entité. Les projets et les compétences sont liés les uns aux autres autant que plusieurs et communiquent donc entre eux via l'entité ProjectSkill (tableau).
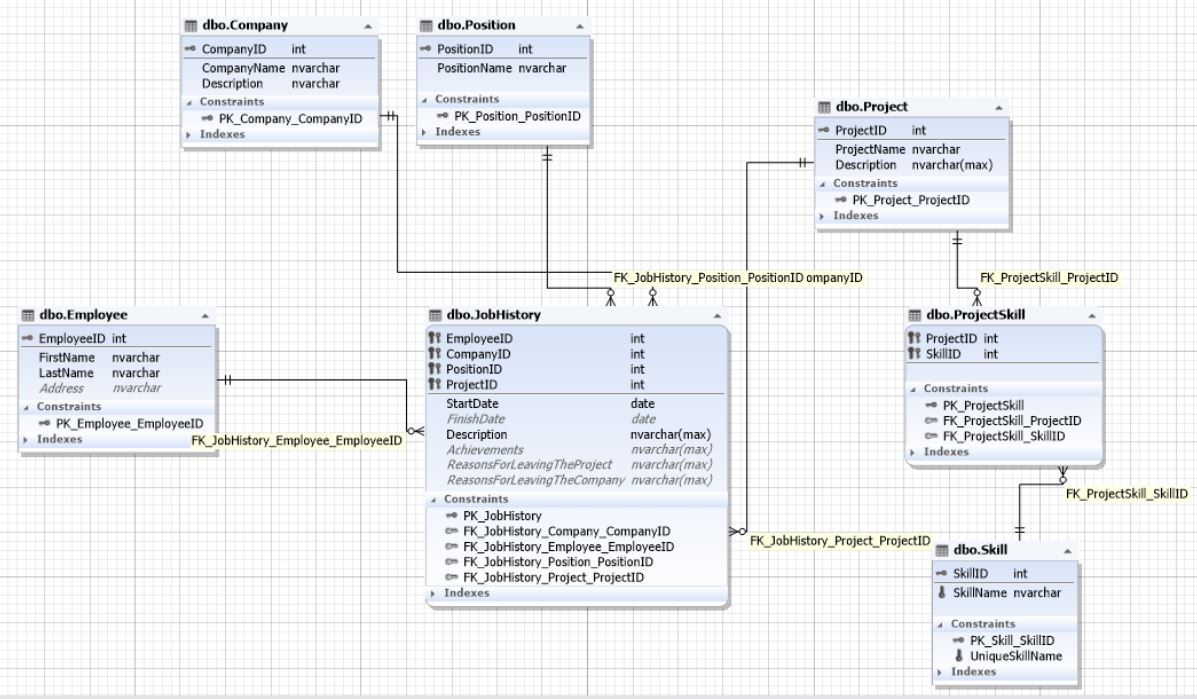
Quand on comprend la relation entre les sujets et entre les sujets et les objets - les sept règles formelles déjà mentionnées - ce schéma ou un schéma similaire peut être mis en œuvre «sur le genou»: sur une feuille de papier, en moins d'une heure. Et cela tient également compte de la fatigue après une journée de travail fructueuse.
Ici, il était possible de simplifier le schéma d'ajout de données si les «compétences» étaient intégrées dans l'entité «projets» via des données incomplètement structurées (NoSQL) sous forme de XML, JSON, ou simplement de lister les noms des compétences séparés par des points-virgules. Mais cela rendrait plus difficile l'échantillonnage par compétence et le filtrage par compétence.
Un modèle similaire est au cœur de la base de données du projet Geecko .
Comme vous pouvez le voir, il n'y a rien de compliqué dans la conception des systèmes d'information en termes de conception de bases de données. C'est juste le reflet d'objets et de sujets de la réalité, transférés aux «entités» du schéma de base de données. La relation entre ces entités est fixée à un certain moment dans le temps, en tenant compte des changements futurs.
Ce que nous retenons exactement de la réalité et la mettons dans l'essence du schéma, et les relations que nous construisons dans le modèle, dépendra de ce que nous attendons du système d'information en général, ici et à l'avenir. En d'autres termes, quelles données nous voulons recevoir à l'heure actuelle et après un certain temps dans le futur.
Un peu de paroles
Après avoir mis le modèle en service, arrêtez-vous un instant et réfléchissez: un nouveau petit monde vient d'être créé. Il a ses propres entités du monde réel et ses propres relations. Oui, c'est un monde numérique, mais il va maintenant se développer à sa manière. Il communiquera (s'intégrera) avec d'autres systèmes (mondes), également créés selon leurs propres règles. Les données circuleront dans ces systèmes comme le sang dans un organisme vivant.
Et avant de vous coucher, pensez au fait que les sept règles formelles ont toujours existé et qu'elles nous entourent partout. Ni plus ni moins, toujours sept. Toutes les relations de la vie réelle peuvent être décomposées en ces sept règles formelles. Et lorsque vous pensez ou rêvez, comment les entités sont-elles liées les unes aux autres - pas selon les sept mêmes règles formelles?
En général, je suis sûr que cette relation (sept règles formelles) a été révélée par un très bon psychothérapeute, peut-être une femme. C'était il y a très longtemps, bien avant que le concept même de technologie de l'information n'apparaisse. Et le plus intéressant est que ces relations vivent en dehors de la base de données et de l'informatique - ces derniers ne les utilisent que pour modéliser des systèmes d'information.
Mais nous nous sommes un peu écartés du sujet. Je vous exhorte seulement à aborder ce processus avec votre âme au moment de créer un nouveau système. Et puis croyez-moi, le moment de la création arrivera. Le système ainsi conçu sera le plus vivant de tous les êtres vivants du monde numérique.
Épilogue
Les diagrammes des exemples ont été implémentés à l'aide de l' outil de diagramme de base de données pour SQL Server . Cependant, DBeaver a des fonctionnalités similaires .