Il existe de nombreux outils utiles pour vous aider à surveiller la charge du serveur, des utilitaires Linux aux services spécialisés.
Les utilitaires Linux simples affichent la consommation de mémoire actuelle pour chaque processus, la charge du processeur, l'espace disque disponible et les statistiques de trafic.
En outre, il existe des services payants et gratuits qui surveillent l'état de votre serveur 24 heures sur 24, enregistrent les défaillances de son fonctionnement ou de la disponibilité du réseau, et vérifient également les performances des applications.
Contenu
Utilitaires Linux
L'utilisation des ressources
Haut
L'un des outils les plus efficaces pour vérifier l'utilisation des ressources par les processus. L'utilitaire
topproduit un tableau simple avec la consommation actuelle des ressources, où les processus de charge les plus élevés sont indiqués en haut.
top - 14:45:52 up 29 min, 1 user, load average: 0.10, 0.09, 0.06
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 393756k used, 625844k free, 11136k buffers
Swap: 0k total, 0k used, 0k free, 316748k cached
PID %MEM VIRT SWAP RES CODE DATA SHR nFLT nDRT S PR NI %CPU COMMAND
832 1.3 32364 18m 12m 896 11m 1688 1 0 S 20 0 0.0 bash
820 0.4 89456 83m 4008 488 948 3040 12 0 S 20 0 0.0 sshd
812 0.3 49948 46m 2828 488 616 2216 0 0 S 20 0 0.0 sshd
1 0.2 24192 21m 2108 152 868 1300 23 0 S 20 0 0.0 init
400 0.1 243m 242m 1420 344 216m 1084 0 0 S 20 0 0.0 rsyslogdCertaines statistiques générales sont fournies juste avant le tableau, y compris la charge moyenne du processeur au cours de la dernière minute, 5 minutes et 15 minutes. Il montre également la consommation de mémoire, la consommation de fichiers d'échange et l'état du processus.
La liste est mise à jour en temps réel: vous pouvez l'afficher sur un deuxième moniteur et la regarder en permanence.
htop
Bien que l'utilitaire soit
topfourni avec presque toutes les distributions, une version améliorée est également disponible en téléchargement dans la plupart des référentiels htop.
Installation
htopsur Ubuntu:
apt-get install htopIci, nous voyons presque la même sortie, mais avec des couleurs différentes et une sortie plus interactive:
CPU[| 0.7%] Tasks: 21, 3 thr; 1 running
Mem[||||||||||||| 64/995MB] Load average: 0.00 0.02 0.05
Swp[ 0/0MB] Uptime: 00:37:37
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
2752 root 20 0 25660 1876 1364 R 0.0 0.2 0:00.06 htop
1 root 20 0 24192 2108 1300 S 0.0 0.2 0:00.55 /sbin/init
312 root 20 0 17224 640 444 S 0.0 0.1 0:00.04 upstart-udev-brid
314 root 20 0 21592 1360 760 S 0.0 0.1 0:00.04 /sbin/udevd --dae
394 messagebu 20 0 23808 688 436 S 0.0 0.1 0:00.01 dbus-daemon --sys
401 syslog 20 0 243M 1420 1084 S 0.0 0.1 0:00.07 rsyslogd -c5
402 syslog 20 0 243M 1420 1084 S 0.0 0.1 0:00.00 rsyslogd -c5La partie supérieure est ici plus claire et mieux organisée.
Voici quelques clés pour une meilleure utilisation
htop:
- M : trier les processus par utilisation de la mémoire
- P : trier les processus par utilisation du processeur
- ? : référence
- k : tuer les processus en cours / marqués
- F2 : réglage (ici vous pouvez sélectionner les options à afficher)
- / : recherche de processus
Un certain nombre d'autres options sont répertoriées dans l'aide et les paramètres. Il vaut la peine de commencer l'étude du programme à partir de ces deux sections.
Trafic réseau
nethogs
nethogsEst l'utilitaire le plus simple pour voir combien de trafic est sur chaque service. Sur Ubuntu, l'utilitaire est installé avec la commande suivante:
apt-get install nethogsEnsuite, il peut être démarré sans clés. Le problème est simple:
PID USER PROGRAM DEV SENT RECEIVED
3379 root /usr/sbin/sshd eth0 0.485 0.182 KB/sec
820 root sshd: root@pts/0 eth0 0.427 0.052 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.912 0.233 KB/secIl n'y a que quelques options pour modifier la sortie:
- m : basculer entre kb / s, kb, b, mb
- r : trier par trafic reçu.
- s : trier par trafic envoyé
- q : quitter
Bien qu'il s'agisse d'un utilitaire simple, il est idéal pour voir rapidement quelles applications génèrent du trafic.
IPTraf
IPTraf- une autre façon de surveiller le trafic réseau, avec de nombreuses options. Installation sur Ubuntu:
apt-get install iptrafCet utilitaire propose de choisir l'une des interfaces interactives:
???????????????????????????????????
? IP traffic monitor ?
? General interface statistics ?
? Detailed interface statistics ?
? Statistical breakdowns... ?
? LAN station monitor ?
???????????????????????????????????
? Filters... ?
???????????????????????????????????
? Configure... ?
???????????????????????????????????
? Exit ?
???????????????????????????????????Par exemple, pour afficher tout le trafic réseau, sélectionnez le premier élément de menu:
? TCP Connections (Source Host:Port) ?????????? Packets ??? Bytes Flags Iface ?
??192.241.xxx.xxx:22 > 369 82420 -PA- eth0 ?
??72.43.xxx.xxx:49488 > 381 19860 --A- eth0 ?
? ?
? ?Pour que les adresses IP soient résolues en domaines, vous devez sélectionner l'élément «Recherche DNS inversée» dans la configuration.
En plus de la visualisation du trafic par ports, il existe une option pour visualiser le trafic par service (option «Noms de service TCP / UDP»). Avec les deux options activées, la sortie ressemblera à ceci:
TCP Connections (Source Host:Port) ?????????? Packets ??? Bytes Flags Iface ?
??192.241.xxx.xxx:ssh > 151 34924 -PA- eth0 ?
??rrcs-72-43-xxx-xxx.nyc.biz.rr.co:49488 > 155 8108 --A- eth0 ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? TCP: 1 entries ???????????????????????????????????????????????? Active ??
????????????????????????????????????????????????????????????????????????????????
? UDP (72 bytes) from 192.241.xxx.xxx:43463 to 8.8.8.8:domain on eth0 ?
? UDP (66 bytes) from 192.241.xxx.xxx:53140 to 8.8.8.8:domain on eth0 ?
? UDP (135 bytes) from 8.8.8.8:domain to 192.241.xxx.xxx:41429 on eth0 ?
? UDP (119 bytes) from 8.8.8.8:domain to 192.241.xxx.xxx:43463 on eth0 ?
? UDP (110 bytes) from google-public-dns-a.googl:domain to 192.241.xxx.xxx:531 ?Il existe quelques autres interfaces que vous pouvez apprendre par vous-même.
netstat
L'utilitaire
netstatest un outil très flexible et puissant pour collecter des informations réseau.
Par défaut, il
netstatdonne une liste des sockets ouverts:
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.241.187.204:ssh ip223.hichina.com:50324 ESTABLISHED
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 5 [ ] DGRAM 6559 /dev/log
unix 3 [ ] STREAM CONNECTED 9386
unix 3 [ ] STREAM CONNECTED 9385
. . .Si ajouter une option
-a, il affichera une liste de tous les ports:
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ACC ] STREAM LISTENING 6195 @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 7762 /var/run/acpid.socket
unix 2 [ ACC ] STREAM LISTENING 6503 /var/run/dbus/system_bus_socket
. . .Indique
-tou -ufiltre les connexions TCP ou UDP, respectivement. Le drapeau -saffiche des statistiques. Pour mettre à jour constamment la sortie, vous devez exécuter la commande avec la clé -c.
Espace disque
df
L'utilitaire standard pour afficher les informations sur les partitions montées est
df. Il affiche une liste des appareils connectés et des informations sur l'espace occupé.
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/vda 31383196 1228936 28581396 5% /
udev 505152 4 505148 1% /dev
tmpfs 203920 204 203716 1% /run
none 5120 0 5120 0% /run/lock
none 509800 0 509800 0% /run/shmPar défaut, la sortie est en octets, ce qui n'est pas très pratique. Le paramètre
-hactive la sortie en mégaoctets et gigaoctets:
Filesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shmPour afficher tout l'espace sur tous les disques, ajoutez l'option
--total.
du
L'utilitaire
dfvous permet d'obtenir rapidement un aperçu général. Pour des informations plus détaillées, un programme duqui analyse le répertoire courant et tous les sous-répertoires est mieux adapté . La sortie par défaut ressemble à ceci:
4 ./.cache
8 ./.ssh
28 .Encore une fois, une sortie plus lisible est activée avec une clé
-h.
L'affichage de la taille des fichiers et des répertoires est activé par l'indicateur
-a, le total général - par les indicateurs -c(détails et montant) et -s(uniquement montant).
Versions améliorées
Les versions améliorées de df et du sont appelées pydf et ncdu et sont installées sur Ubuntu avec les commandes
apt-get install pydfet apt-get install ncdu. Ils organisent de beaux résultats en pseudo-graphiques avec des couleurs:
pydf -a
dev/vda 30G 1200M 27G 3.9 [........] /
udev 493M 4096B 493M 0.0 [........] /dev
devpts 0 0 0 - [........] /dev/pts
proc 0 0 0 - [........] /proc
tmpfs 199M 204k 199M 0.1 [........] /run
none 5120k 0 5120k 0.0 [........] /run/lock
none 498M 0 498M 0.0 [........] /run/shm
. . .ncdu
--- /root ----------------------------------------------------------------------
8.0KiB [##########] /.ssh
4.0KiB [##### ] /.cache
4.0KiB [##### ] .bashrc
4.0KiB [##### ] .profile
4.0KiB [##### ] .bash_historyIci, vous pouvez naviguer dans le système de fichiers à l'aide des touches fléchées.
Utilisation de la mémoire
gratuit
La façon la plus simple d'afficher l'utilisation actuelle de la RAM consiste à utiliser la commande
free. La sortie sans options ressemble à ceci:
total used free shared buffers cached
Mem: 12286456 11715372 571084 0 81912 6545228
-/+ buffers/cache: 5088232 7198224
Swap: 24571408 54528 24516880Le lancement à clé
-mgénère la sortie en mégaoctets.
La ligne du milieu
-/+ buffers/cachemontre la quantité de mémoire utilisée moins la somme des tampons / cache, et la quantité de mémoire libre plus la somme des tampons / cache.
Le fait est que Linux, comme la plupart des systèmes d'exploitation modernes, essaie d'utiliser le maximum de RAM disponible pour les tampons et le cache. Par conséquent, la deuxième ligne est importante, qui indique la quantité réelle de RAM potentiellement disponible pour les applications, si vous ignorez les tampons et le cache. Cet espace sera libéré automatiquement si nécessaire pour les applications.
vmstat
La commande
vmstataffiche diverses informations sur le système, notamment la mémoire, le fichier d'échange, les opérations d'E / S et la charge du processeur.
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 2828 407616 335348 5511476 0 0 26 268 41 27 28 30 42 0 0La première colonne
rindique le nombre de processus actifs, la seconde - le nombre de processus en état d'attente sans interruption.
Colonnes
siet soindiquent la quantité de mémoire lue et écrite dans le fichier d'échange, respectivement.
Le tableau suivant montre le nombre de blocs reçus ou envoyés au périphérique d'E / S de bloc (bi, bo), le nombre d'interruptions par seconde, y compris la minuterie (in), le nombre de changements de contexte par seconde (cs) et les statistiques du processeur: pourcentage de temps passé à traiter code dans l'espace utilisateur (us), pour traiter le code du noyau (sy), en état de veille (id) et en attente d'E / S (wa), ainsi que le temps "volé" de la machine virtuelle (st), c'est-à-dire lorsque le processeur virtuel attend que le processeur réel agisse lorsque l'hyperviseur entretient un autre processeur virtuel.
Le drapeau
-S Mactive la livraison en mégaoctets. L'exécution avec l'option -saffiche des statistiques générales.
Services de surveillance
Si vous avez besoin de surveiller l'état du serveur 24 heures sur 24 (mémoire, processeur, espace libre, performances, temps de réponse, etc.), vous pouvez utiliser un service de surveillance gratuit ou payant. Il existe de nombreux services de ce type, voici une petite liste par ordre alphabétique:
- Anturis
- AppDynamics
- AppNeta
- Atera
- BigPanda
- CollectD
- Datadog
- Innovations eG
- Ganglions
- Icinga (adaptation gratuite de Nagios Core)
- Instrumental
- LogicMonitor
- ManageEngine OpManager
- Monitis
- Motadata
- Nagios XI (la version gratuite s'appelle Nagios Core)
- Moniteur Navicat
- NinjaRMM
- Moniteur Op5
- OpenNMS
- Pandora FMS
- Panopta
- Moniteur réseau PRTG
- Lion de mer
- Densité du serveur
- Site24x7
- Serveur SolarWinds et Application Monitor
- Moniteur réseau Spiceworks (gratuit)
- Empiler
- WhatsUpGold
- Zabbix (moniteur système gratuit)
Certains moniteurs conviennent mieux aux petites entreprises, tandis que d'autres conviennent mieux aux grandes entreprises. Certains se spécialisent dans la surveillance des systèmes cloud. Il existe des services qui ne fonctionnent que sur des serveurs Linux. Les systèmes diffèrent par leur évolutivité, leur ensemble de fonctionnalités et leur niveau d'automatisation. Plusieurs moniteurs sont distribués en open source.
Par exemple, considérons trois services de surveillance relativement populaires.
Serveur SolarWinds et Application Monitor
L'un des moniteurs de serveur les plus avancés du marché est SolarWinds Server and Application Monitor (SAM). Bien que l'outil ne s'installe que sur Windows Server 2016+, il peut suivre n'importe quel matériel, y compris les serveurs Linux.
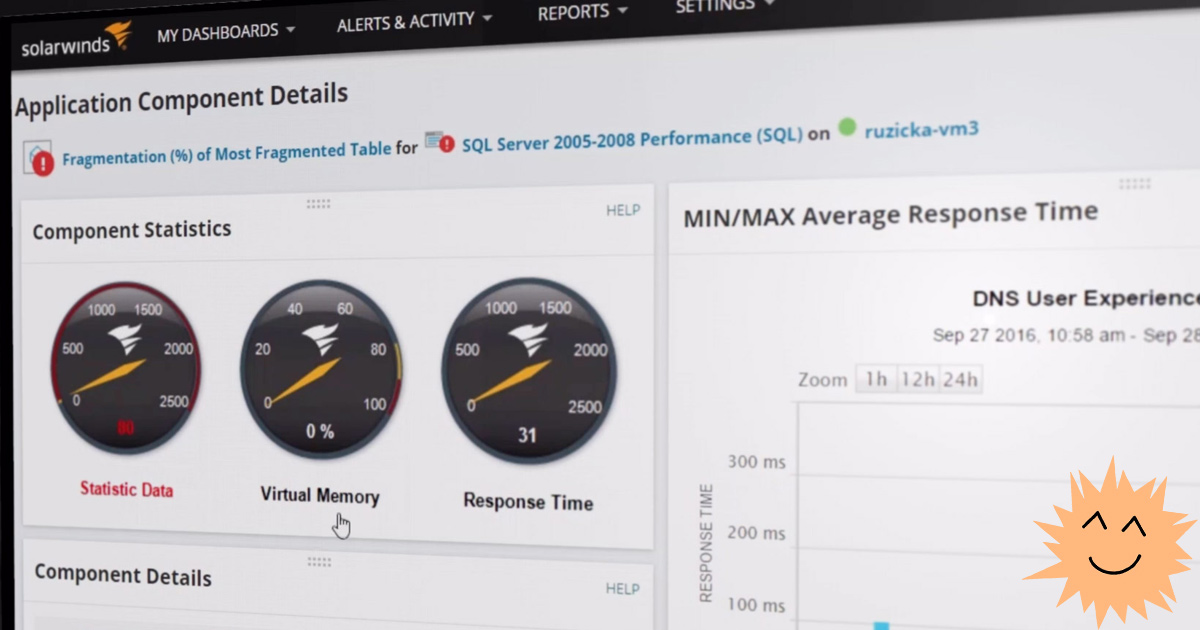
Le moniteur surveille les performances du serveur, signale les problèmes et fournit également certaines capacités de gestion: il vous permet de redémarrer le serveur, de filmer les processus et de redémarrer les services, c'est-à-dire qu'il s'agit d'un outil non seulement pour la surveillance, mais aussi pour l'administration.

Le programme est mieux adapté aux grandes entreprises. Compatibilité déclarée avec Dell PowerEdge, HP ProLiant, IBM eServer xSeries, Dell PowerEdge Blade, HP BladeSystem, Microsoft Windows Server et VMware vSphere. Dans le même temps, SAM surveille également les instances de cloud AWS et Azure.
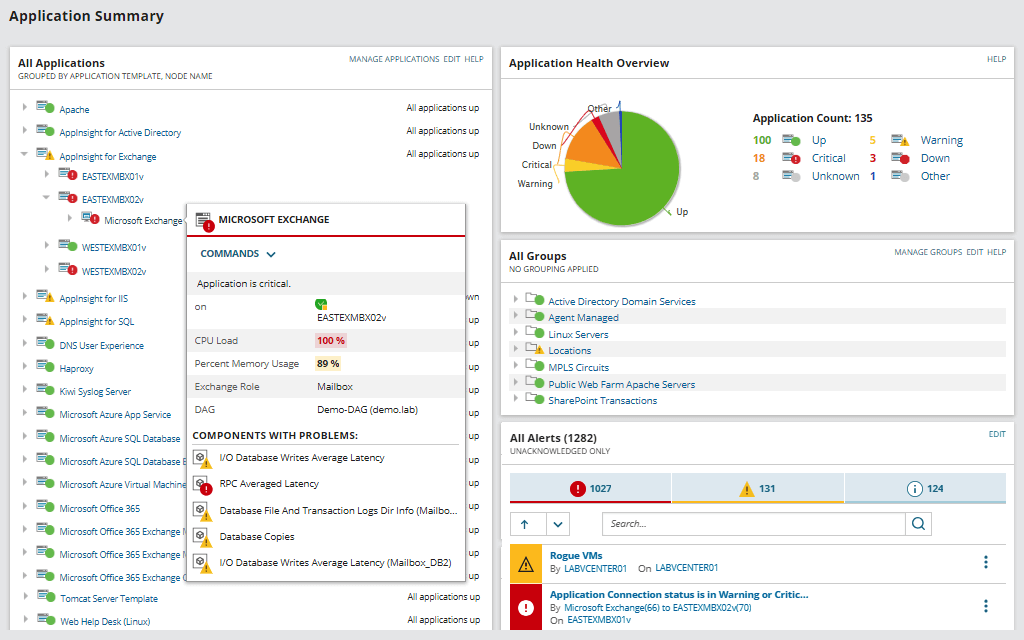
Il affiche des statistiques sur le temps de réponse, la charge du processeur, la mémoire, etc. Les performances des applications individuelles sont surveillées: la prise en charge de plus de 1200 applications différentes est intégrée. Il vérifie également la santé du matériel: utilisation du processeur, charge du disque, alimentation, état des ventilateurs, etc.
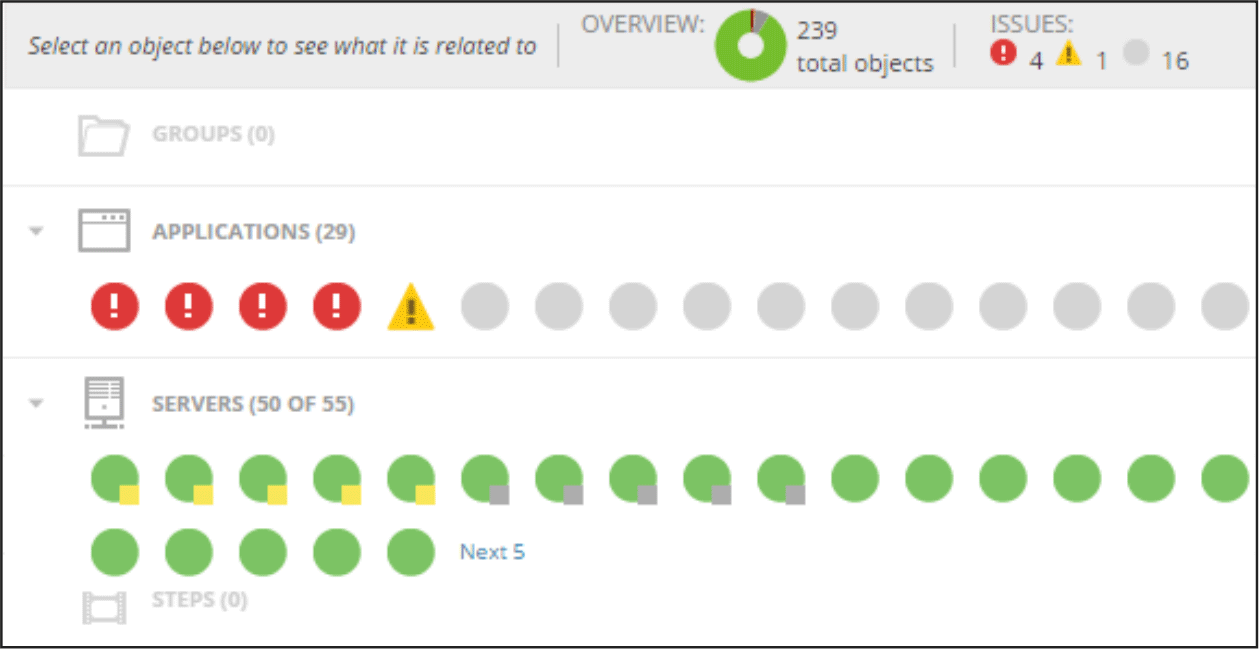
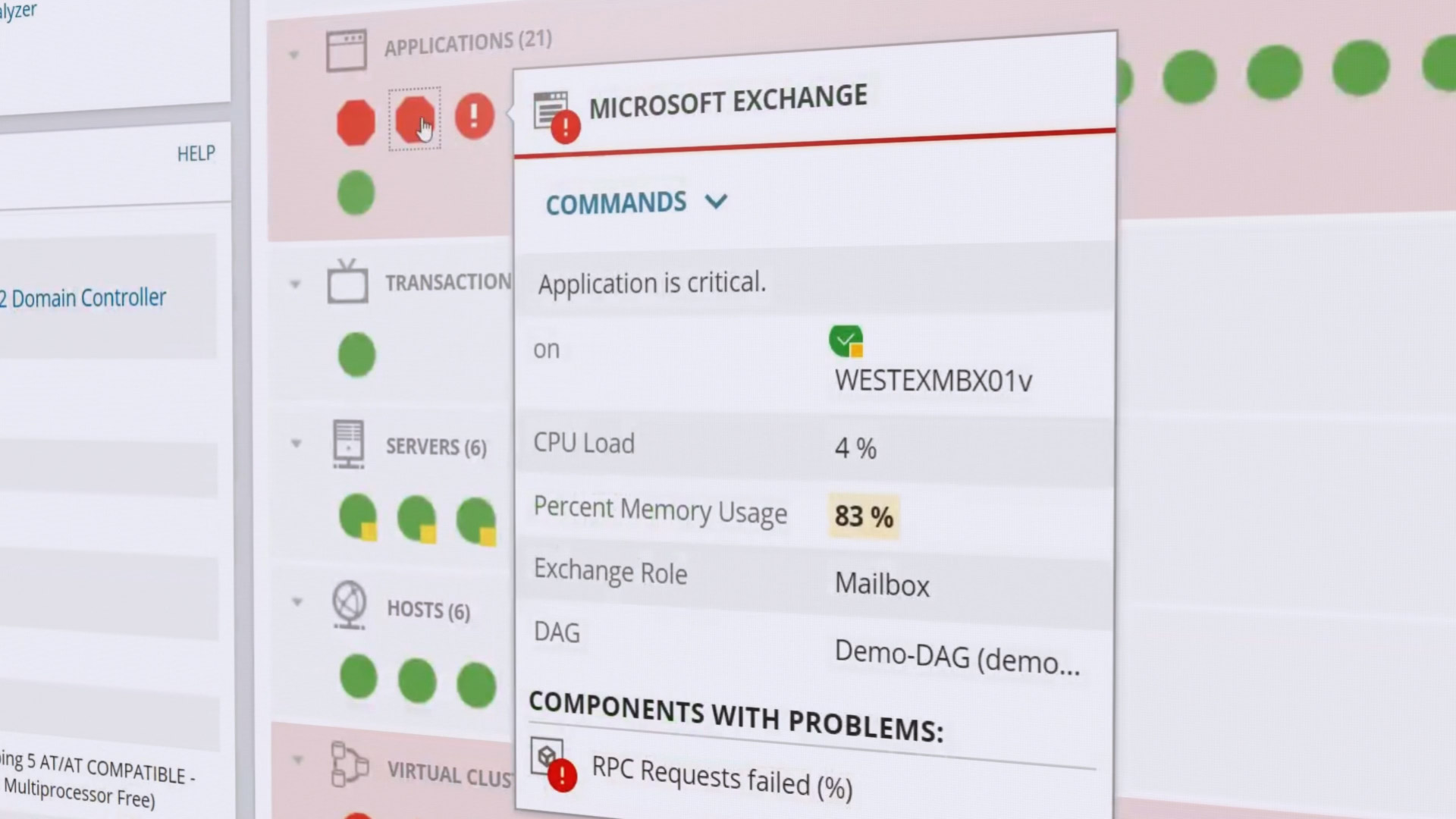
Le moniteur détecte automatiquement les nouveaux matériels et logiciels dans votre cluster, les ajoutant immédiatement au tableau de bord. Il s'agit de l'une des fonctionnalités clés de SAM, ainsi que de l'automatisation maximale - des modèles préparés pour automatiser les tâches de surveillance et de maintenance régulières, des modèles pour les rapports et les notifications.
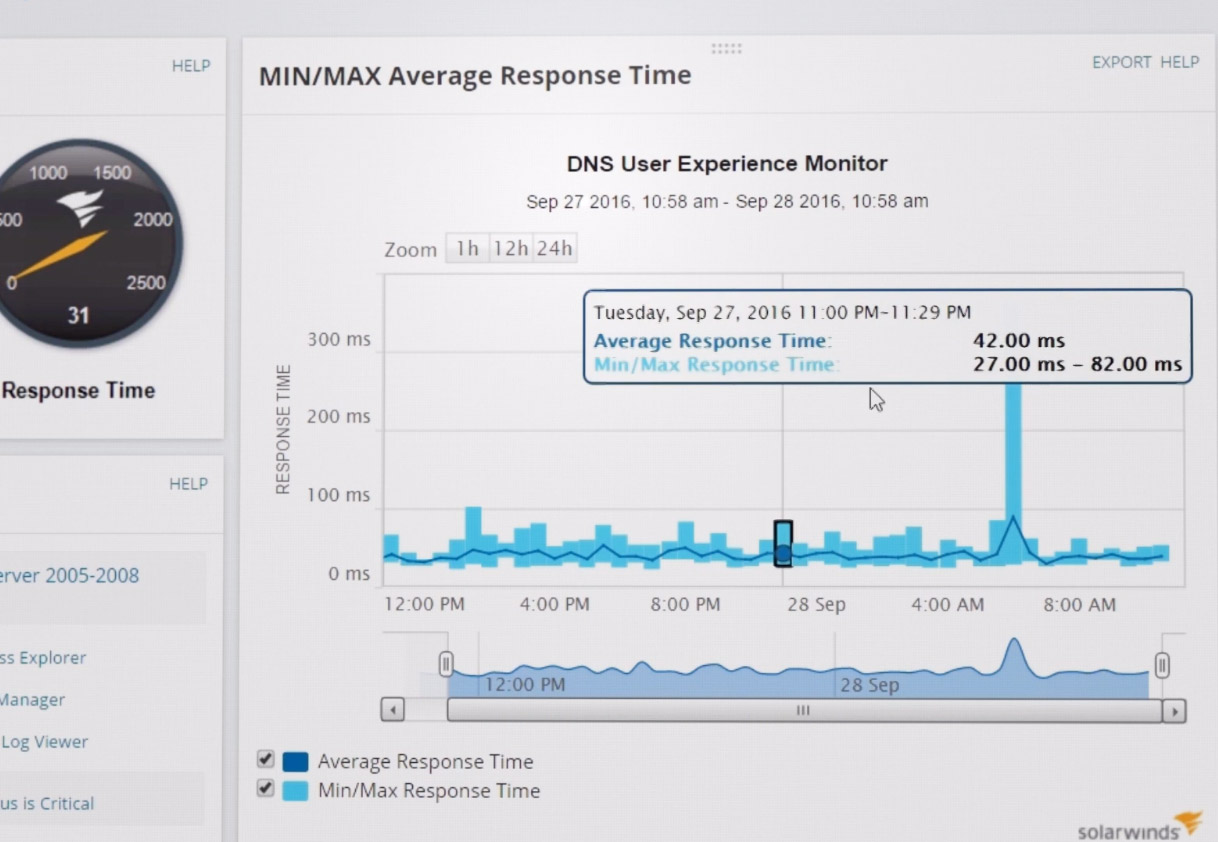
Habituellement, ces services ont une période d'essai gratuite, et le coût peut dépendre de l'ensemble des fonctionnalités utilisées. Il y a aussi une période d'essai ici, et le coût du serveur SolarWinds et du moniteur d'application commence à 1275 euros en fonctionnalités minimum.
Moniteur Navicat
Un autre exemple est Navicat Monitor , spécialisé dans la surveillance de bases de données. Il prend en charge MySQL, MariaDB, SQL Server, ainsi que les SGBD cloud tels qu'Amazon RDS, Amazon Aurora, Oracle Cloud, Google Cloud et Microsoft Azure.

Vue standard Vue
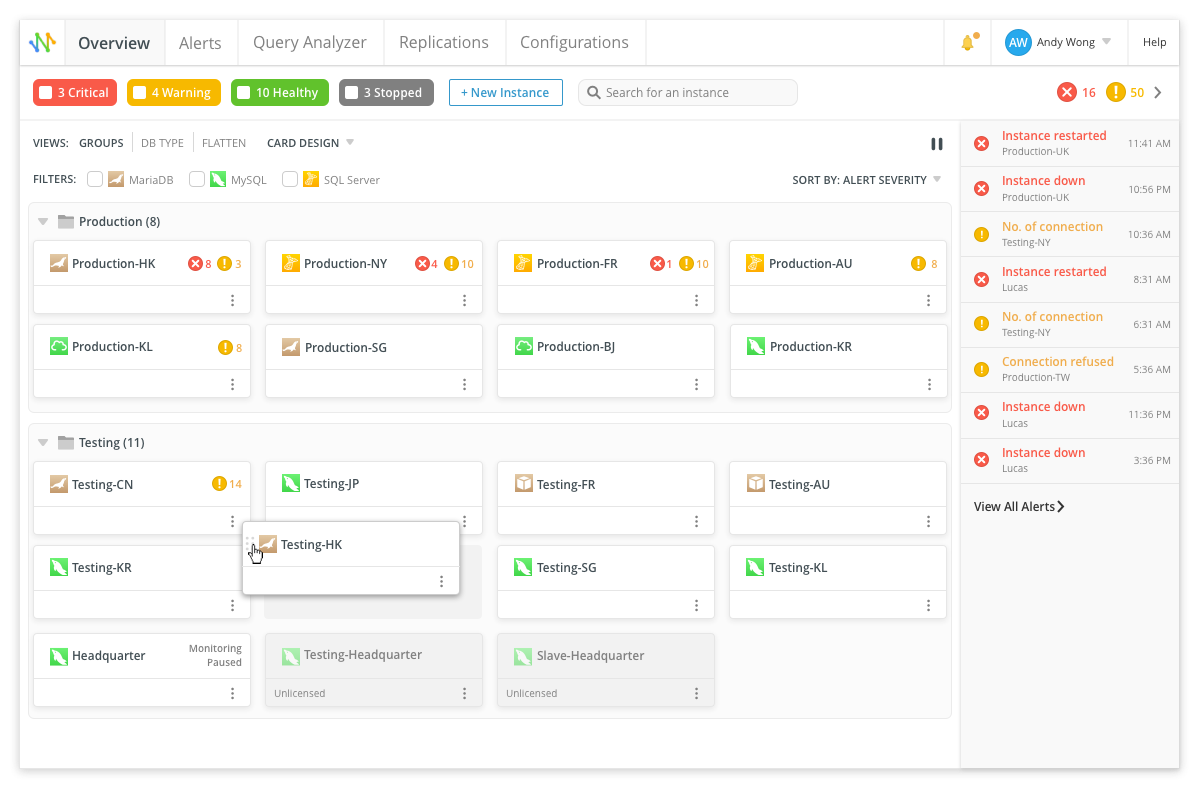
compacte Le
moniteur suit le temps d'exécution de requêtes spécifiques en les exécutant à un intervalle spécifié.

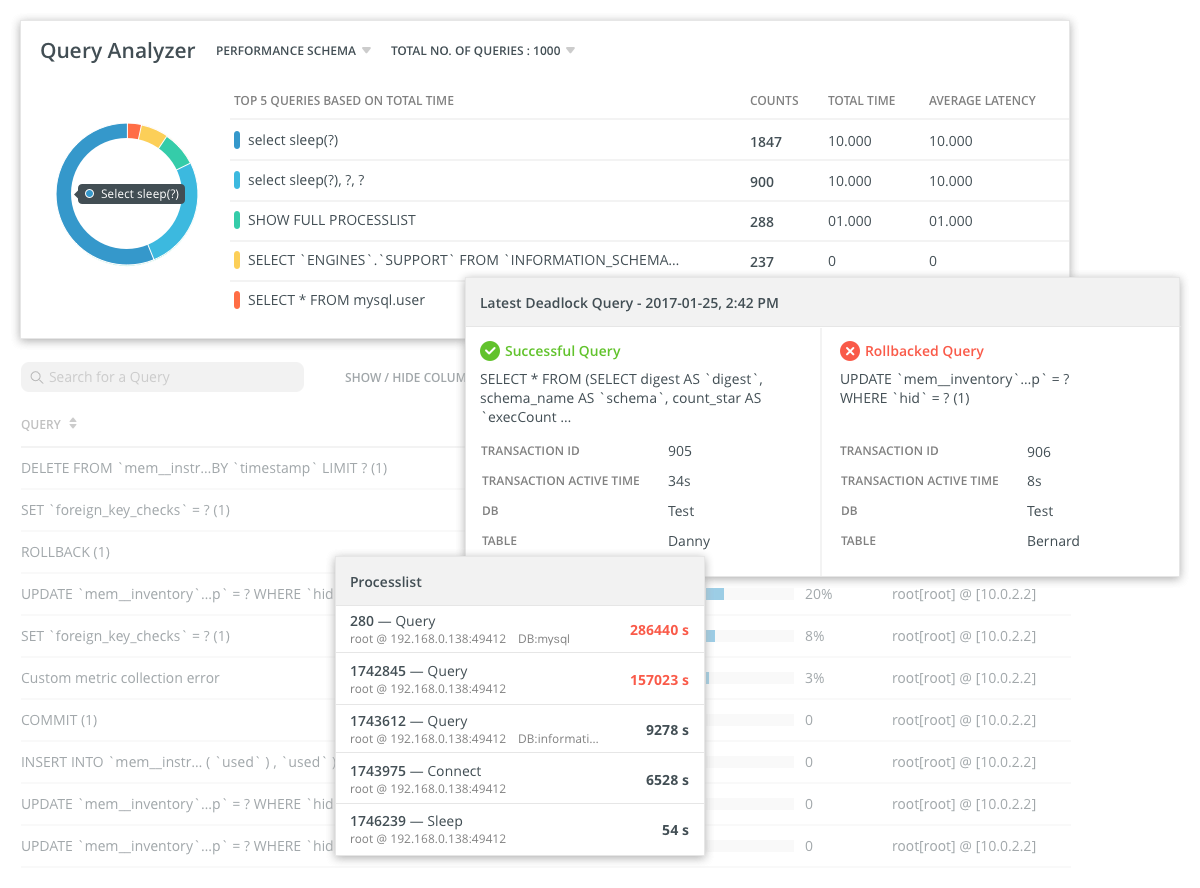
En plus des requêtes adressées à la base de données, d'autres requêtes sont régulièrement envoyées aux serveurs pour surveiller les indicateurs de performance du système d'E / S, du réseau, etc. Les statistiques sont collectées sur l'utilisation du processeur, l'utilisation de la mémoire et d'autres mesures standard.
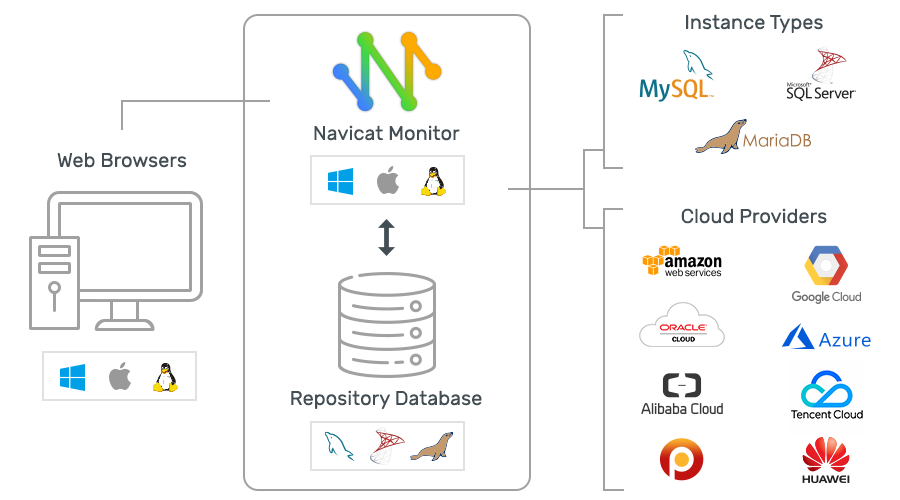
L'architecture Navicat Monitor ne fournit pas d'installation de logiciel sur les objets de surveillance
Le prix minimum pour Navicat Monitor est de 32,99 $ par jeton et par mois (un jeton correspond à la surveillance d'un serveur ou de quatre bases Azure). Il existe un essai de 14 jours entièrement fonctionnel.
Zabbix
Zabbix est un outil open source gratuit qui surveille la santé du réseau, des applications et du serveur lui-même. Livré avec des modèles prêts à l'emploi pour la surveillance des serveurs et des systèmes d'exploitation courants, notamment HP, IBM, Lenovo, Dell, les serveurs Linux, Ubuntu et Solaris. Au fil des ans, la communauté Zabbix a préparé des modèles pour divers scénarios.
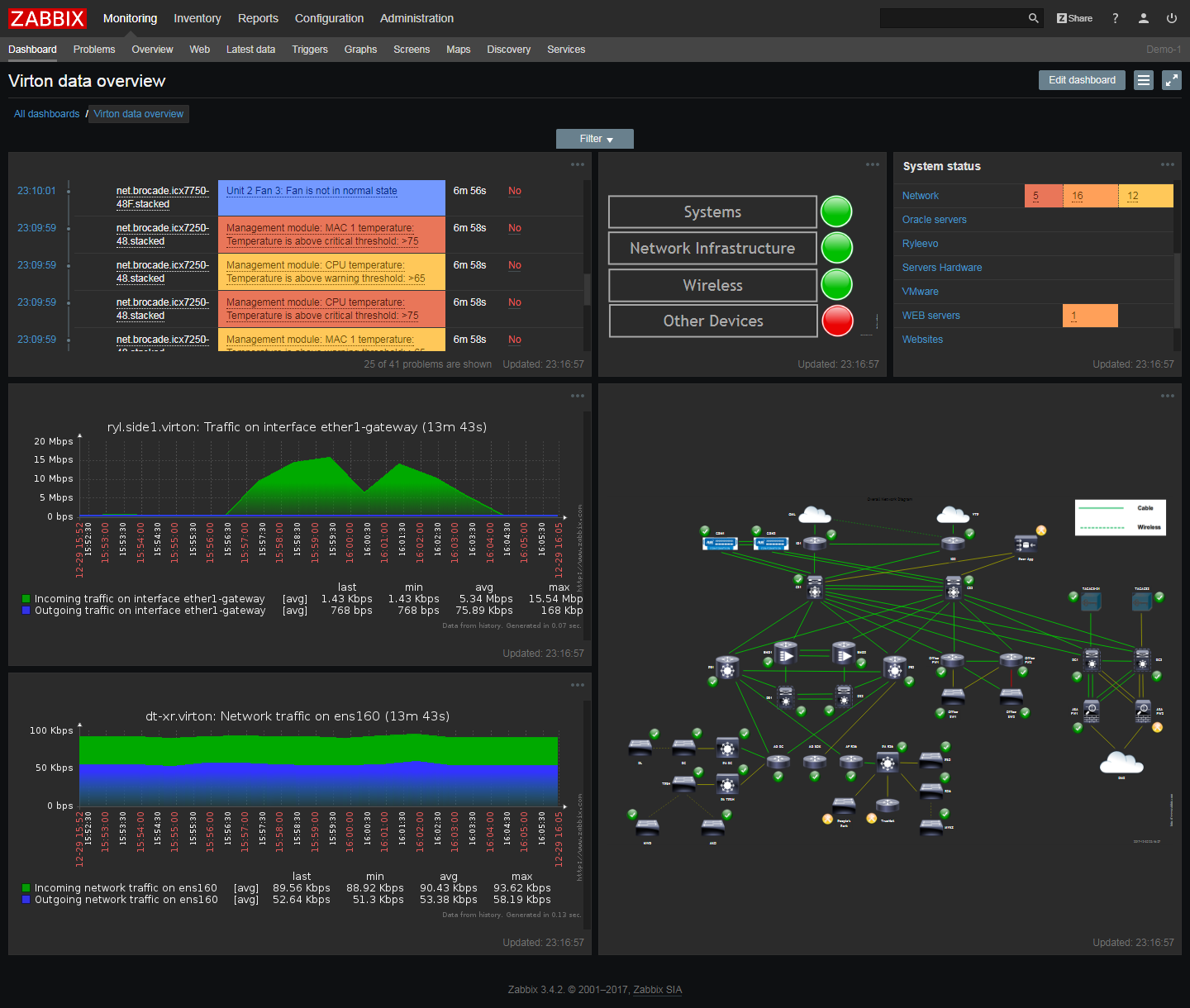
Les modules clés Zabbix surveillent la charge du processeur, l'utilisation de la mémoire, le taux d'erreur d'E / S, l'espace disque disponible, l'état du ventilateur, la température et les caractéristiques du système d'alimentation. Le module réseau vérifie le trafic, la disponibilité du réseau, le taux de perte de paquets, la qualité des connexions TCP et le débit des routeurs.
Zabbix tient à jour une liste des versions de logiciels et de micrologiciels installés pour signaler les installations de logiciels non autorisées.

L'administrateur système peut programmer des notifications dans Zabbix selon des conditions arbitraires, ainsi que modifier l'importance des notifications actives. Sur le panneau de commande, vous pouvez ajouter des utilisateurs et envoyer à chacun d'eux certains types de notifications, et les scripts d'automatisation vous permettent de démarrer automatiquement des tâches et de les affecter aux employés.
Grâce à la fonction d'accès et de gestion à distance, Zabbix peut être qualifié de bon outil d'administration de serveur.
Le seul inconvénient de ce système est que si vous avez ajouté environ 1000 serveurs ou plus pour la surveillance, alors en raison du grand nombre de messages et de procédures de cryptage, Zabbix commence à répondre lentement aux commandes, donc cet outil n'est pas très adapté aux très grandes entreprises.
Les systèmes de surveillance des serveurs diffèrent par leurs fonctionnalités ... Tout le monde ne peut pas surveiller la santé des applications individuelles, les performances du serveur et les temps de réponse. Mais ces lacunes peuvent être corrigées avec des outils supplémentaires: par exemple, des systèmes d'analyse et de surveillance des journaux.
Un serveur fiable à louer et le bon choix d'un plan tarifaire vous permettront d'être moins distrait par des notifications de surveillance désagréables - tout fonctionnera en douceur et avec un temps de disponibilité très élevé!
