
Le cloud computing pénètre de plus en plus profondément dans nos vies et il n'y a probablement pas une seule personne qui n'ait utilisé aucun service cloud au moins une fois. Cependant, ce qu'est un cloud et comment il fonctionne pour la plupart, peu de gens le savent même au niveau d'une idée. La 5G est déjà en train de devenir une réalité et l'infrastructure des télécommunications commence à passer des solutions piliers aux solutions cloud, comme lorsqu'elle passait de solutions entièrement ferreuses à des «piliers» virtualisés.
Aujourd'hui, nous allons parler du monde intérieur de l'infrastructure cloud, en particulier, nous analyserons les bases de la partie réseau.
Qu'est-ce qu'un cloud? La même virtualisation - vue de profil?
Plus qu'une question logique. Non - ce n'est pas de la virtualisation, même si ce n'était pas sans elle. Considérez deux définitions: le
cloud computing (ci-après dénommé le Cloud) est un modèle permettant de fournir un accès convivial aux ressources informatiques distribuées qui doivent être déployées et lancées à la demande avec la latence la plus faible possible et un coût minimal de la part du fournisseur de services (traduction de la définition du NIST).
Virtualisation- il s'agit de la possibilité de diviser une entité physique (par exemple, un serveur) en plusieurs entités virtuelles, augmentant ainsi l'utilisation des ressources (par exemple, vous aviez 3 serveurs chargés de 25 à 30%, après la virtualisation, 1 serveur était chargé de 80 à 90%). Naturellement, la virtualisation consomme une partie des ressources - vous devez alimenter l'hyperviseur, cependant, comme la pratique l'a montré, le jeu en vaut la chandelle. Un exemple idéal de virtualisation est VMWare, qui prépare parfaitement les machines virtuelles, ou par exemple KVM, que je préfère, mais c'est déjà une question de goût.
Nous utilisons nous-mêmes la virtualisation sans nous en rendre compte, et même les routeurs de fer utilisent déjà la virtualisation - par exemple, dans les dernières versions de JunOS, le système d'exploitation est installé en tant que machine virtuelle en plus du kit de distribution Linux en temps réel (Wind River 9). Mais la virtualisation n'est pas le cloud, mais le cloud ne peut exister sans virtualisation.
La virtualisation est l'un des éléments de base sur lesquels le cloud est construit.
Cela ne fonctionnera pas pour créer un cloud en rassemblant simplement plusieurs hyperviseurs dans un domaine L2, en ajoutant quelques playbooks yaml pour enregistrer automatiquement des vlans via certains ansible et en le remplissant de quelque chose comme un système d'orchestration pour créer automatiquement des machines virtuelles. Plus précisément, cela se révélera, mais le Frankenstein qui en résulte n'est pas le nuage dont nous avons besoin, bien qu'en tant que quelqu'un d'autre, peut-être pour quelqu'un, c'est le rêve ultime. De plus, si vous prenez le même Openstack - en fait, c'est toujours Frankenstein, mais bon, n'en parlons pas encore.
Mais je comprends que d'après la définition ci-dessus, ce que l'on peut appeler un cloud n'est pas tout à fait clair.
Par conséquent, le document du NIST (National Institute of Standards and Technology) énumère 5 caractéristiques principales qu'une infrastructure cloud devrait avoir:
Prestation de service sur demande. L'utilisateur doit avoir libre accès aux ressources informatiques qui lui sont allouées (telles que les réseaux, les disques virtuels, la mémoire, les cœurs de processeur, etc.), et ces ressources doivent être fournies automatiquement - c'est-à-dire sans intervention du fournisseur de services.
Large disponibilité de service. L'accès aux ressources doit être assuré par des mécanismes standard pour pouvoir utiliser à la fois des PC standard, des clients légers et des appareils mobiles.
Mise en commun des ressources.Les pools de ressources doivent être en mesure de fournir des ressources à plusieurs clients en même temps, en garantissant l'isolement des clients et l'absence d'influence mutuelle et de conflits pour les ressources. Les réseaux sont également inclus dans les pools, ce qui indique la possibilité d'utiliser l'adressage se chevauchant. Les piscines doivent évoluer à la demande. L'utilisation de pools vous permet de fournir le niveau nécessaire de résilience des ressources et d'abstraction des ressources physiques et virtuelles - le destinataire du service est simplement fourni avec l'ensemble des ressources demandées par lui (où ces ressources sont physiquement situées, sur combien de serveurs et de commutateurs - le client s'en fiche). Cependant, il faut tenir compte du fait que le fournisseur doit assurer une réservation transparente de ces ressources.
Adaptation rapide à diverses conditions.Les services doivent être flexibles - fourniture rapide des ressources, leur réallocation, ajout ou réduction de ressources à la demande du client, et le client doit sentir que les ressources du cloud sont infinies. Pour faciliter la compréhension, par exemple, vous ne voyez pas d'avertissement indiquant que vous avez perdu une partie de l'espace disque dans Apple iCloud en raison du fait que le disque dur du serveur est cassé et que les disques se cassent. De plus, de votre côté, les possibilités de ce service sont presque infinies - il vous faut 2 To - pas de problème, vous avez payé et reçu. De même, vous pouvez donner un exemple avec Google.Drive ou Yandex.Disk.
La capacité de mesurer le service fourni.Les systèmes cloud devraient automatiquement contrôler et optimiser les ressources consommées, tandis que ces mécanismes devraient être transparents à la fois pour l'utilisateur et le fournisseur de services. Autrement dit, vous pouvez toujours vérifier la quantité de ressources que vous et vos clients consommez.
Il convient de considérer le fait que ces exigences sont principalement des exigences pour un cloud public.Par conséquent, pour un cloud privé (c'est-à-dire un cloud lancé pour les besoins internes d'une entreprise), ces exigences peuvent être légèrement ajustées. Cependant, ils doivent encore être exécutés, sinon nous n'obtiendrons pas tous les avantages du cloud computing.
Pourquoi avons-nous besoin d'un cloud?
Cependant, toute technologie nouvelle ou existante, tout nouveau protocole est créé pour quelque chose (enfin, sauf pour RIP-ng, bien sûr). Protocole pour des raisons de protocole - personne n'en a besoin (enfin, sauf pour RIP-ng, bien sûr). Il est logique que le Cloud soit créé pour fournir une sorte de service à l'utilisateur / client. Nous connaissons tous au moins quelques services cloud, tels que Dropbox ou Google.Docs, et je pense que la plupart d'entre eux les utilisent avec succès - par exemple, cet article a été rédigé à l'aide du service cloud Google.Docs. Mais les services cloud que nous connaissons ne sont qu'une partie des capacités du cloud - plus précisément, il ne s'agit que d'un service de type SaaS. Nous pouvons fournir un service cloud de trois manières: sous forme de SaaS, PaaS ou IaaS. Le service dont vous avez besoin dépend de vos désirs et de vos capacités.
Considérons chacun dans l'ordre:
Le logiciel en tant que service (SaaS) est un modèle pour fournir un service complet à un client, par exemple, un service de messagerie comme Yandex.Mail ou Gmail. Dans un tel modèle de prestation de services, vous, en tant que client, ne faites en fait rien d'autre que d'utiliser les services - c'est-à-dire que vous n'avez pas besoin de penser à la mise en place d'un service, à sa tolérance aux pannes ou à sa réservation. L'essentiel est de ne pas compromettre votre mot de passe, le fournisseur de ce service fera le reste à votre place. Du point de vue du fournisseur de services, il est entièrement responsable de l'ensemble du service - du matériel du serveur et des systèmes d'exploitation hôtes aux paramètres de base de données et de logiciel.
Plateforme en tant que service (PaaS)- lors de l'utilisation de ce modèle, le fournisseur de services fournit au client un modèle pour le service, par exemple, prenons un serveur Web. Le fournisseur de services a fourni au client un serveur virtuel (en fait, un ensemble de ressources, telles que RAM / CPU / Stockage / Nets, etc.), et a même installé le système d'exploitation et les logiciels nécessaires sur ce serveur, mais le client configure lui-même tout cela et pour les performances du service déjà le client répond. Le fournisseur de services, comme dans le cas précédent, est responsable de l'opérabilité des équipements physiques, des hyperviseurs, de la machine virtuelle elle-même, de sa disponibilité réseau, etc., mais le service lui-même est déjà en dehors de sa zone de responsabilité.
Infrastructure en tant que service (IaaS)- cette approche est déjà plus intéressante, en fait, le fournisseur de services fournit au client une infrastructure virtualisée complète - c'est-à-dire une sorte d'ensemble (pool) de ressources, telles que les cœurs de processeur, la RAM, les réseaux, etc. Tout le reste appartient au client - ce que le client veut en faire ressources dans le pool alloué (quota) - le fournisseur n'est pas particulièrement important. Le client souhaite créer son propre vEPC ou même faire un mini opérateur et fournir des services de communication - pas de doute - faites-le. Dans un tel scénario, le fournisseur de services est responsable de la fourniture des ressources, de leur tolérance aux pannes et de leur disponibilité, ainsi que du système d'exploitation qui vous permet de combiner ces ressources dans des pools et de les fournir au client avec la possibilité d'augmenter ou de réduire les ressources à tout moment à la demande du client. Le client configure lui-même toutes les machines virtuelles et autres tinsel via le portail en libre-service et les consoles,y compris l'enregistrement des réseaux (à l'exception des réseaux externes).
Qu'est-ce qu'OpenStack?
Dans les trois options, le fournisseur de services a besoin d'un système d'exploitation qui activera l'infrastructure cloud. En fait, en SaaS, aucun département n'est responsable de l'ensemble de la pile de cette pile technologique - il y a un département qui est responsable de l'infrastructure - c'est-à-dire qu'il fournit l'IaaS à un autre département, ce département fournit le client SaaS. OpenStack est l'un des systèmes d'exploitation cloud qui vous permet de rassembler un ensemble de commutateurs, de serveurs et de systèmes de stockage en un seul pool de ressources, de diviser ce pool commun en sous-pools (locataires) et de fournir ces ressources aux clients sur le réseau.
Pile ouverteEst un système d'exploitation cloud qui vous permet de contrôler de grands pools de ressources informatiques, de stockage de données et de ressources réseau, dont le provisionnement et la gestion sont effectués via une API utilisant des mécanismes d'authentification standard.
En d'autres termes, il s'agit d'un ensemble de projets de logiciels libres conçus pour créer des services cloud (publics et privés) - c'est-à-dire un ensemble d'outils qui vous permettent de combiner le serveur et l'équipement de commutation en un seul pool de ressources, de gérer ces ressources, en fournissant le niveau de tolérance aux pannes nécessaire. ...
Au moment d'écrire ces lignes, la structure d'OpenStack ressemble à ceci:

Photo prise depuis openstack.org
Chacun des composants qui composent OpenStack remplit une fonction spécifique. Cette architecture distribuée vous permet d'inclure dans la solution l'ensemble des composants fonctionnels dont vous avez besoin. Cependant, certains des composants sont des composants racines et leur suppression entraînera une inopérabilité totale ou partielle de la solution dans son ensemble. Il est d'usage de se référer à de tels composants:
- Tableau de bord - interface graphique Web pour la gestion des services OpenStack
- Keystone est un service d'identité centralisé qui fournit des fonctionnalités d'authentification et d'autorisation pour d'autres services, ainsi que de gérer les informations d'identification et les rôles des utilisateurs.
- Neutron — , OpenStack ( VM )
- Cinder —
- Nova —
- Glance —
- Swift —
- Ceilometer — ,
- Heat —
Une liste complète de tous les projets et de leur objectif est disponible ici .
Chacun des composants OpenStack est un service qui est responsable d'une fonction spécifique et fournit une API pour gérer cette fonction et pour communiquer ce service avec d'autres services du système d'exploitation cloud afin de créer une infrastructure unifiée. Par exemple, Nova fournit une gestion des ressources de calcul et des API pour accéder à la configuration de ces ressources, Glance fournit une gestion des images et des API pour les gérer, Cinder fournit un stockage en bloc et des API pour les gérer, etc. Toutes les fonctions sont interconnectées de manière très étroite.
Cependant, si vous jugez, tous les services exécutés dans OpenStack sont finalement une sorte de machine virtuelle (ou de conteneur) connectée au réseau. La question se pose: pourquoi avons-nous besoin de tant d'éléments?
Passons en revue l'algorithme pour créer une machine virtuelle et la connecter au réseau et au stockage persistant dans Openstack.
- Lorsque vous créez une demande pour créer une machine, que ce soit une demande via Horizon (Dashboard) ou une demande via l'interface de ligne de commande, la première chose qui se produit est votre demande d'autorisation pour Keystone - pouvez-vous créer une machine, posséder ou avoir le droit d'utiliser ce réseau, en avez-vous assez? projet de quotas, etc.
- Keystone authentifie votre demande et génère un jeton d'authentification dans le message de réponse, qui sera utilisé ultérieurement. Après avoir reçu une réponse de Keystone, la requête est envoyée vers Nova (nova api).
- Nova-api , Keystone, auth-
- Keystone auth- .
- Nova-api nova-database VM nova-scheduler.
- Nova-scheduler ( ), VM , . VM nova-database.
- nova-scheduler nova-compute . Nova-compute nova-conductor (nova-conductor nova, nova-database nova-compute, nova-database ).
- Nova-conductor nova-database nova-compute.
- nova-compute glance ID . Glace Keystone .
- Nova-compute neutron . glance, neutron Keystone, database ( ), nova-compute.
- Nova-compute cinder volume. glance, cider Keystone, volume .
- Nova-compute libvirt .
En fait, une opération apparemment simple pour créer une machine virtuelle simple se transforme en un tel tourbillon d'appels API entre les éléments de la plate-forme cloud. De plus, comme vous pouvez le voir, même les services précédemment désignés se composent également de composants plus petits, entre lesquels une interaction a lieu. La création d'une machine n'est qu'une petite partie de ce que la plate-forme cloud vous offre - il existe un service responsable de l'équilibrage du trafic, un service responsable du stockage en bloc, un service responsable du DNS, un service chargé de l'approvisionnement des serveurs bare metal, etc. vous traitez vos machines virtuelles comme un troupeau de moutons (par opposition à la virtualisation). Si quelque chose arrive à votre machine dans un environnement virtuel - vous le restaurez à partir de sauvegardes, etc., les applications cloud sont construites de cette manière,pour que la machine virtuelle ne joue pas un rôle aussi important - la machine virtuelle "est morte" - peu importe - une nouvelle machine est simplement créée sur la base du modèle et, comme on dit, l'escouade n'a pas remarqué la perte d'un soldat. Naturellement, cela permet la présence de mécanismes d'orchestration - en utilisant les modèles Heat, vous pouvez facilement déployer une fonction complexe composée de dizaines de réseaux et de machines virtuelles sans aucun problème.
Il convient toujours de garder à l'esprit qu'il n'y a pas d'infrastructure cloud sans réseau - chaque élément interagit d'une manière ou d'une autre avec d'autres éléments via le réseau. De plus, le cloud dispose d'un réseau totalement non statique. Naturellement, le réseau sous-jacent est encore plus ou moins statique - de nouveaux nœuds et commutateurs ne sont pas ajoutés tous les jours, cependant, le composant de superposition peut et sera inévitablement changer constamment - de nouveaux réseaux seront ajoutés ou supprimés, de nouvelles machines virtuelles apparaissent et les anciennes meurent. Et comme vous vous en souvenez d'après la définition du cloud, donnée au tout début de l'article, les ressources doivent être allouées à l'utilisateur automatiquement et avec le moins (ou mieux sans) intervention du fournisseur de services. Autrement dit, le type de fourniture de ressources réseau,qui se présente désormais sous la forme d'un frontend sous la forme de votre compte personnel accessible via http / https et de l'ingénieur réseau de service Vasily en tant que backend - ce n'est pas un cloud, même si Vasily a huit mains.
Neutron, en tant que service réseau, fournit une API pour gérer la partie réseau de l'infrastructure cloud. Le service assure l'intégrité et la gestion de la partie réseau Openstack en fournissant une couche d'abstraction appelée Network-as-a-Service (NaaS). Autrement dit, le réseau est la même unité virtuelle mesurable que, par exemple, les cœurs virtuels de CPU ou la RAM.
Mais avant de passer à l'architecture réseau OpenStack, examinons le fonctionnement du réseau OpenStack et pourquoi le réseau est une partie importante et intégrale du cloud.
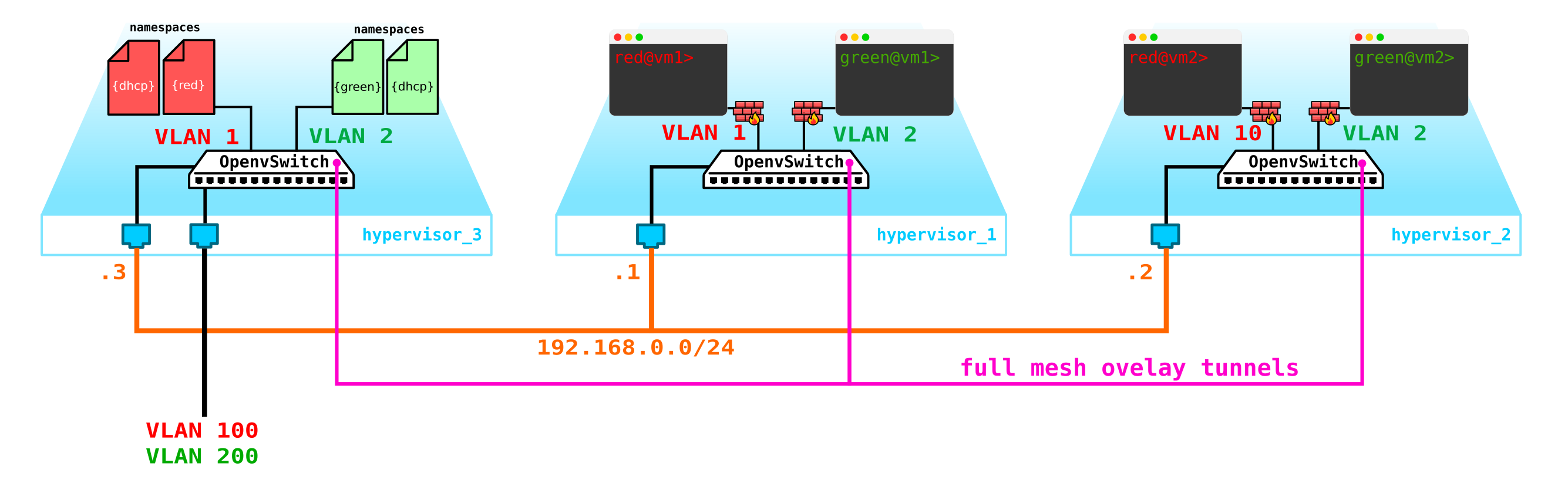
Nous avons donc deux machines virtuelles clientes RED et deux machines virtuelles clientes VERTES. Supposons que ces machines soient situées sur deux hyperviseurs comme celui-ci:
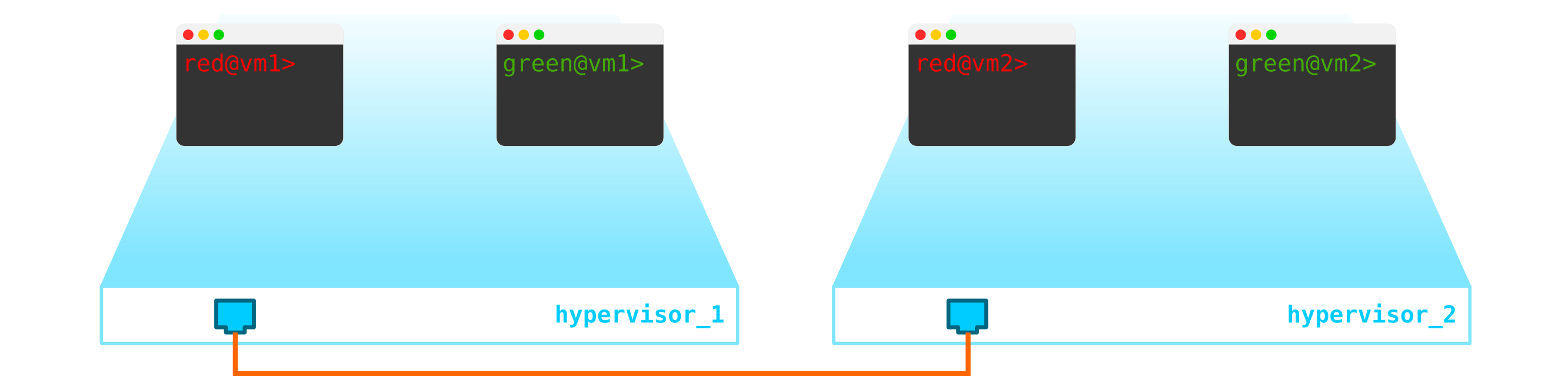
Pour le moment, il ne s'agit que de virtualisation de 4 serveurs et rien de plus, puisque jusqu'à présent, tout ce que nous avons fait est de virtualiser 4 serveurs, en les plaçant sur deux serveurs physiques. Et jusqu'à présent, ils ne sont même pas connectés au réseau.
Pour obtenir un cloud, nous devons ajouter plusieurs composants. Tout d'abord, nous virtualisons la partie réseau - nous devons connecter ces 4 machines par paires, et les clients veulent exactement la connexion L2. Vous pouvez utiliser le commutateur et configurer une jonction dans sa direction et tout gérer en utilisant le pont Linux, ou pour les utilisateurs d'openvswitch plus avancés (nous y reviendrons). Mais il peut y avoir beaucoup de réseaux, et pousser constamment L2 à travers un commutateur n'est pas la meilleure idée - donc différentes divisions, service desk, des mois d'attente pour l'exécution d'une application, des semaines de dépannage - cette approche ne fonctionne plus dans le monde moderne. Et plus vite l'entreprise s'en rend compte, plus il est facile d'avancer. Par conséquent, entre les hyperviseurs, nous sélectionnerons un réseau L3 à travers lequel nos machines virtuelles communiqueront, et déjà au-dessus de ce réseau L3, nous construirons des réseaux L2 virtuels superposés (overlay),où le trafic de nos machines virtuelles s'exécutera. GRE, Geneve ou VxLAN peuvent être utilisés comme encapsulation. Attardons-nous sur ce dernier pour l'instant, même si ce n'est pas particulièrement important.
Nous devons localiser VTEP quelque part (j'espère que tout le monde connaît la terminologie VxLAN). Puisque le réseau L3 quitte immédiatement les serveurs, rien ne nous empêche de placer VTEP sur les serveurs eux-mêmes, et OVS (OpenvSwitch) peut le faire parfaitement. En conséquence, nous avons obtenu la construction suivante: étant
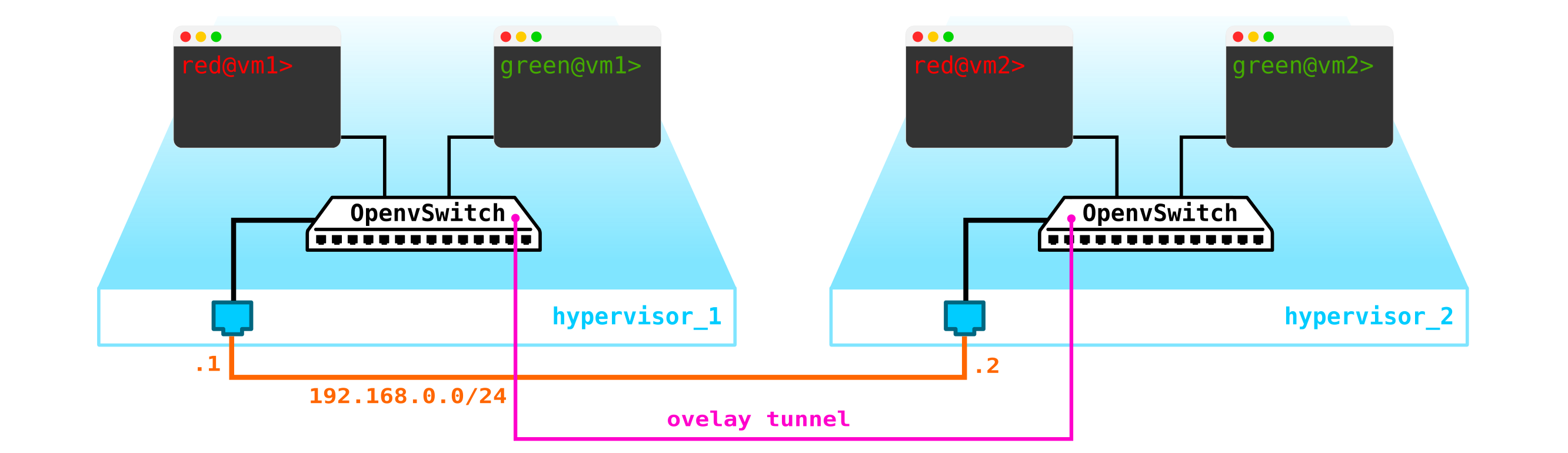
donné que le trafic entre les VM doit être divisé, les ports vers les machines virtuelles auront des numéros de vlan différents. Le numéro de balise ne joue un rôle qu'au sein d'un seul commutateur virtuel, car lors de l'encapsulation dans VxLAN, nous pouvons le supprimer sans aucun problème, car nous aurons un VNI.

Désormais, nous pouvons créer sans problème nos machines et nos réseaux virtuels.
Cependant, que se passe-t-il si le client possède une autre machine, mais se trouve sur un réseau différent? Nous avons besoin d'un enracinement entre les réseaux. Nous analyserons une option simple lorsque l'enracinement centralisé est utilisé - c'est-à-dire que le trafic est acheminé via des nœuds de réseau dédiés spéciaux (enfin, en règle générale, ils sont combinés avec des nœuds de contrôle, nous aurons donc la même chose).
Cela ne semble rien de compliqué - nous créons une interface de pont sur le nœud de contrôle, y dirigons le trafic et de là, nous l'acheminons là où nous en avons besoin. Mais le problème est que le client RED veut utiliser le réseau 10.0.0.0/24 et le client GREEN veut utiliser le réseau 10.0.0.0/24. Autrement dit, l'intersection des espaces d'adressage commence. De plus, les clients ne souhaitent pas que d'autres clients soient acheminés vers leurs réseaux internes, ce qui est logique. Pour séparer les réseaux et le trafic des données clients, nous allouerons un espace de noms distinct pour chacun d'entre eux. L'espace de noms est, en fait, une copie de la pile réseau Linux, c'est-à-dire que les clients dans l'espace de noms RED sont complètement isolés des clients de l'espace de noms VERT (enfin, le routage entre ces réseaux clients est autorisé via l'espace de noms par défaut ou déjà sur l'équipement de transport en amont).
Autrement dit, nous obtenons le schéma suivant:
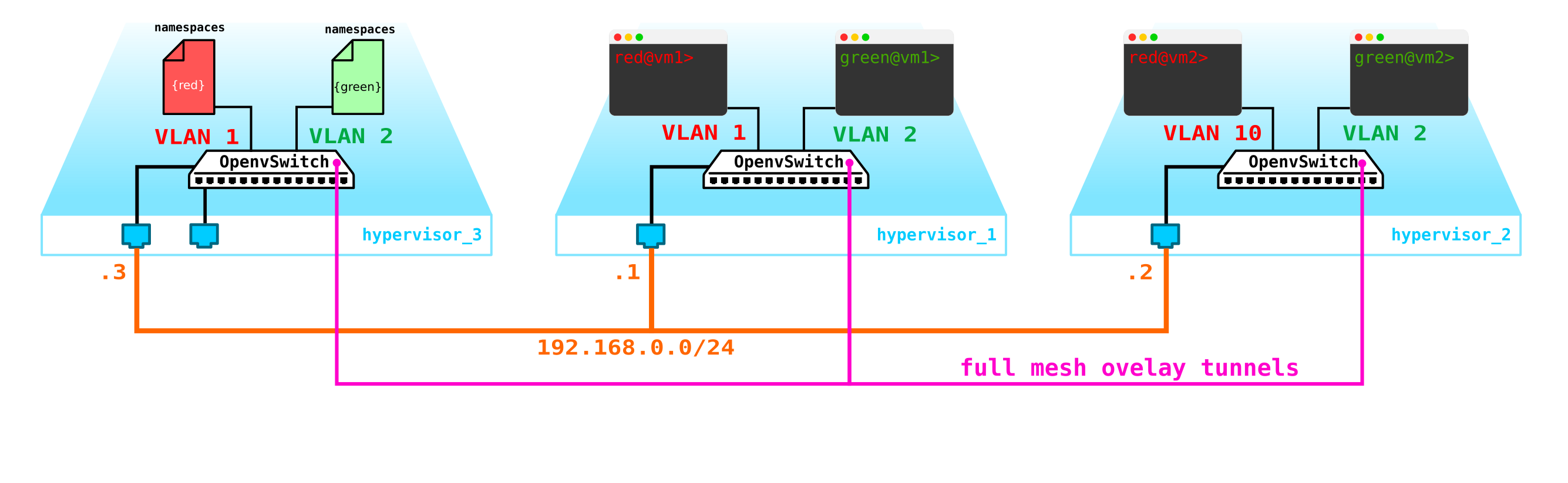
Les tunnels L2 convergent de tous les nœuds de calcul vers celui de contrôle. le nœud où se trouve l'interface L3 de ces réseaux, chacun dans un espace de noms dédié pour l'isolation.
Cependant, nous avons oublié la chose la plus importante. La machine virtuelle doit fournir un service au client, c'est-à-dire qu'elle doit avoir au moins une interface externe à travers laquelle elle peut être atteinte. Autrement dit, nous devons aller dans le monde extérieur. Il existe différentes options ici. Faisons l'option la plus simple. Ajoutons des clients sur un réseau, qui seront valides dans le réseau du fournisseur et ne chevaucheront pas d'autres réseaux. Les réseaux peuvent également se croiser et examiner différents VRF du côté du réseau du fournisseur. Ces réseaux vivront également dans l'espace de noms de chaque client. Cependant, ils iront toujours dans le monde extérieur via une interface physique (ou lien, ce qui est plus logique). Pour séparer le trafic client, le trafic sortant sera étiqueté avec une balise VLAN attribuée au client.
En conséquence, nous avons obtenu le schéma suivant:

Une question raisonnable - pourquoi ne pas créer des passerelles sur les nœuds de calcul eux-mêmes? Ce n'est pas un gros problème, de plus, lorsque vous allumez le routeur distribué (DVR), cela fonctionnera comme ça. Dans ce scénario, nous considérons l'option la plus simple avec une passerelle centralisée, qui est la valeur par défaut dans Openstack. Pour les fonctions à forte charge, ils utiliseront à la fois un routeur distribué et des technologies d'accélération telles que SR-IOV et Passthrough, mais comme on dit, c'est une histoire complètement différente. Commençons par la partie de base, puis entrons dans les détails.
En fait, notre système est déjà opérationnel, mais il y a quelques nuances:
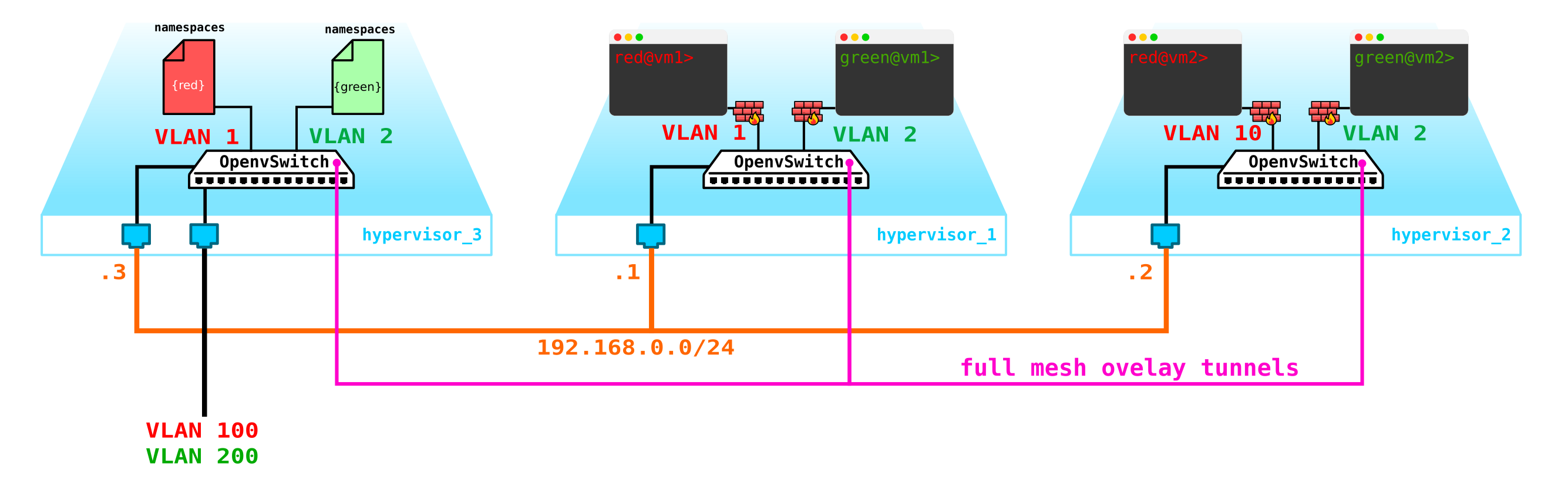
- Nous devons d'une manière ou d'une autre protéger nos machines, c'est-à-dire accrocher un filtre sur l'interface du commutateur vers le client.
- Permettez à une machine virtuelle d'obtenir automatiquement une adresse IP afin que vous n'ayez pas à la saisir à chaque fois via la console et à enregistrer l'adresse.
Commençons par protéger les machines. Pour cela, vous pouvez utiliser des iptables banals, pourquoi pas.
Autrement dit, maintenant notre topologie est devenue un peu plus compliquée:
allons plus loin. Nous devons ajouter un serveur DHCP. L'endroit le plus idéal pour l'emplacement des serveurs DHCP pour chacun des clients sera le nœud de contrôle déjà mentionné ci-dessus, où se trouvent les espaces de noms:
Cependant, il y a un petit problème. Que faire si tout redémarre et que toutes les informations de bail d'adresse DHCP disparaissent. Il est logique que de nouvelles adresses soient fournies aux machines, ce qui n'est pas très pratique. Il y a deux façons de sortir ici - soit utiliser des noms de domaine et ajouter un serveur DNS pour chaque client, puis l'adresse ne sera pas très importante pour nous (par analogie avec la partie réseau dans k8s) - mais il y a un problème avec les réseaux externes, car des adresses peuvent également y être émises via DHCP - vous devez vous synchroniser avec les serveurs DNS de la plate-forme cloud et un serveur DNS externe, ce qui, à mon avis, n'est pas très flexible, mais tout à fait possible. Ou la deuxième option consiste à utiliser des métadonnées, c'est-à-dire à enregistrer des informations sur l'adresse émise sur la machine afin que le serveur DHCP sache quelle adresse envoyer à la machine si la machine a déjà reçu une adresse. La deuxième option est plus simple et plus flexible, car elle vous permet d'enregistrer des informations supplémentaires sur la voiture.Ajoutez maintenant les métadonnées de l'agent au schéma:
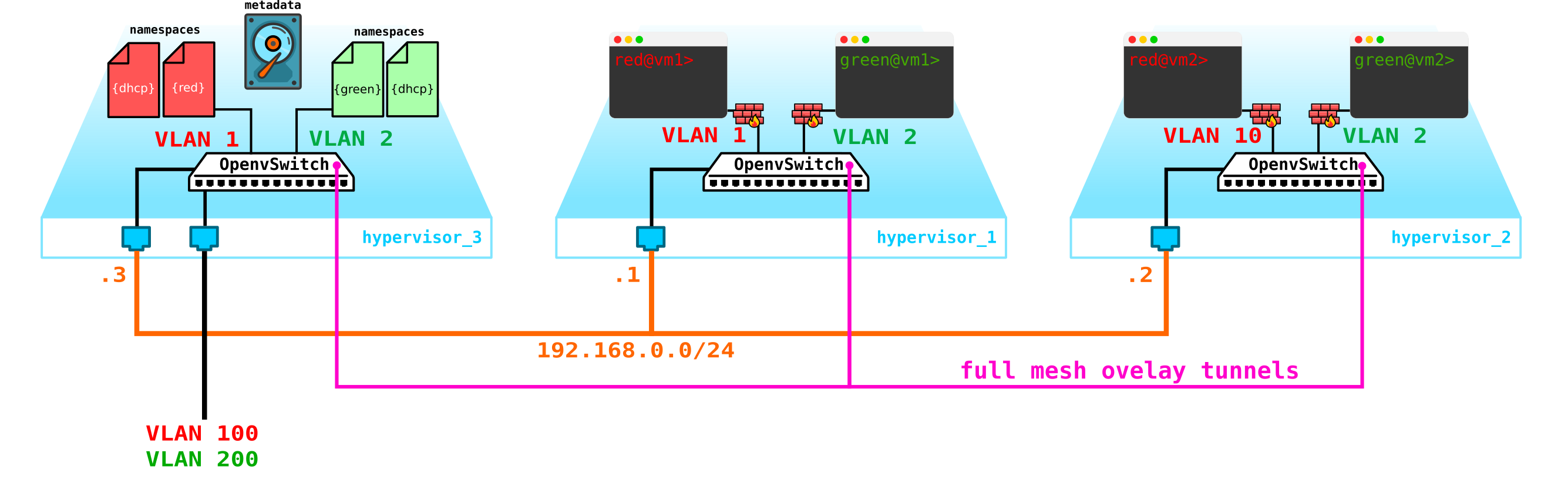
Un autre problème qui devrait également être sanctifié est la possibilité d'utiliser un réseau externe pour tous les clients, car les réseaux externes, s'ils doivent être valides dans tout le réseau, il y aura de la complexité - vous devez constamment allouer et contrôler l'allocation de ces réseaux. La possibilité d'utiliser un seul réseau externe préconfiguré pour tous les clients sera très utile lors de la création d'un cloud public. Cela facilitera le déploiement des machines, car nous n'avons pas à vérifier la base de données d'adresses et à choisir un espace d'adressage unique pour le réseau externe de chaque client. De plus, nous pouvons enregistrer un réseau externe à l'avance et au moment du déploiement, nous n'aurons qu'à associer des adresses externes aux machines clientes.
Et ici, NAT vient à la rescousse - nous permettons simplement aux clients d'accéder au monde extérieur via l'espace de noms par défaut en utilisant la traduction NAT. Eh bien, voici un petit problème. Il est bon que le serveur client agisse en tant que client et non en tant que serveur, c'est-à-dire qu'il initie plutôt qu'accepte les connexions. Mais avec nous, ce sera l'inverse. Dans ce cas, nous devons faire un NAT de destination afin que lors de la réception du trafic, le nœud de contrôle comprenne que ce trafic est destiné à la machine virtuelle A du client A, ce qui signifie que nous devons effectuer une traduction NAT d'une adresse externe, par exemple 100.1.1.1 vers une adresse interne 10.0.0.1. Dans ce cas, bien que tous les clients utilisent le même réseau, l'isolation interne est complètement préservée. Autrement dit, nous devons créer dNAT et sNAT sur le nœud de contrôle.Utilisez un seul réseau avec l'attribution d'adresses flottantes ou de réseaux externes, ou les deux à la fois, car vous souhaitez vous glisser dans le cloud. Nous n'ajouterons pas d'adresses flottantes au diagramme, mais nous laisserons les réseaux externes déjà ajoutés précédemment - chaque client a son propre réseau externe (dans le diagramme, ils sont désignés comme vlan 100 et 200 sur l'interface externe).
En conséquence, nous avons obtenu une solution intéressante et en même temps bien pensée qui a une certaine flexibilité, mais pour l'instant ne dispose pas de mécanismes de tolérance aux pannes.
Premièrement, nous n'avons qu'un seul nœud de contrôle - sa défaillance entraînera l'effondrement de tous les systèmes. Pour résoudre ce problème, vous devez créer au moins un quorum de 3 nœuds. Ajoutons ceci au diagramme:
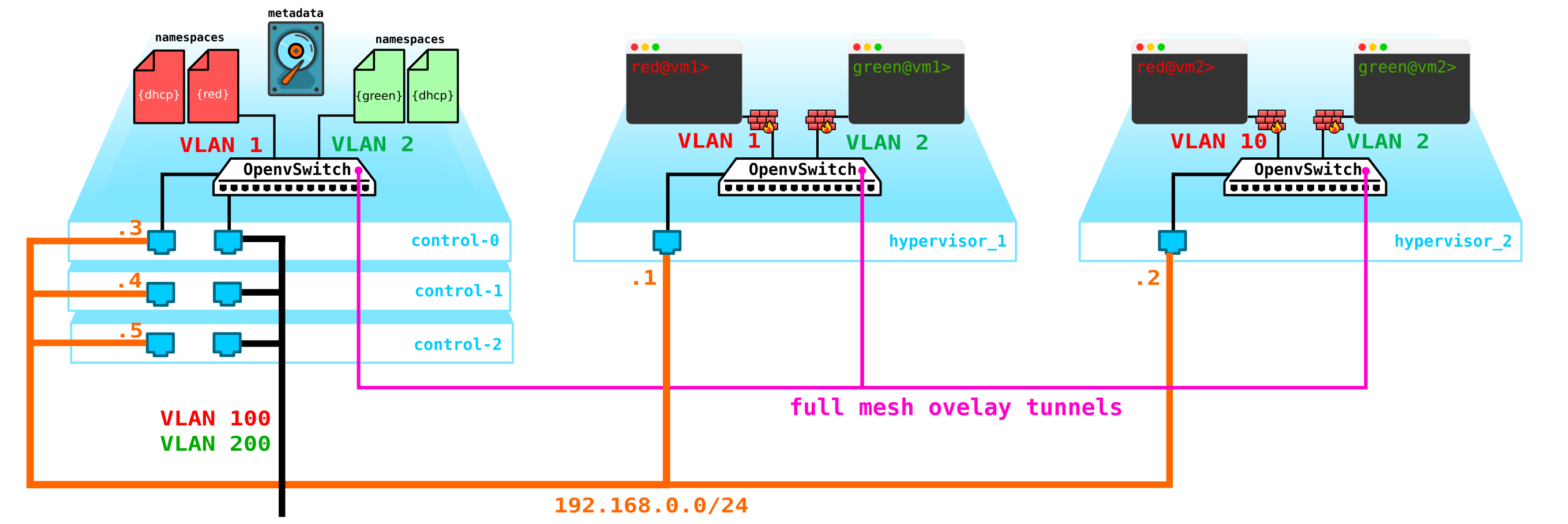
Naturellement, tous les nœuds sont synchronisés et lorsque le nœud actif se termine, un autre nœud prendra ses responsabilités.
Le problème suivant concerne les disques de machine virtuelle. Pour le moment, ils sont stockés sur les hyperviseurs eux-mêmes, et en cas de problèmes avec l'hyperviseur, nous perdons toutes les données - et la présence d'un raid n'aidera en rien si nous perdons non pas le disque, mais le serveur entier. Pour ce faire, nous devons créer un service qui servira d'interface pour un certain stockage. Le type de stockage qu'il s'agira n'est pas particulièrement important pour nous, mais il devrait protéger nos données contre les pannes du disque et du nœud, et éventuellement de toute l'armoire. Il y a plusieurs options ici - bien sûr, il y a des réseaux SAN avec Fibre Channel, mais soyons honnêtes - FC est déjà une relique du passé - un analogue de E1 dans les transports - oui, je suis d'accord, il est toujours utilisé, mais seulement là où c'est absolument impossible sans lui. Par conséquent, je ne déploierais pas volontairement le réseau FC en 2020, sachant qu'il existe d'autres alternatives plus intéressantes.Bien que chacun sienne et peut-être qu'il y aura ceux qui croient que FC avec toutes ses limitations est tout ce dont nous avons besoin - je ne discuterai pas, chacun a sa propre opinion. Cependant, la solution la plus intéressante à mon avis est l'utilisation du SDS, par exemple Ceph.
Ceph vous permet de construire une solution de stockage de vyskodostupnoe avec un tas d'options pour la redondance, puisque la parité de code (raid analogique 5 ou 6) se terminant par une réplication complète des données sur plusieurs disques à base de serveurs d'emplacement de disque et les serveurs dans les armoires et ainsi de suite.
Pour L'assemblage Ceph a besoin de 3 nœuds supplémentaires. L'interaction avec le stockage se fera également via le réseau en utilisant les services de stockage de blocs, d'objets et de fichiers. Ajoutez du stockage au schéma:
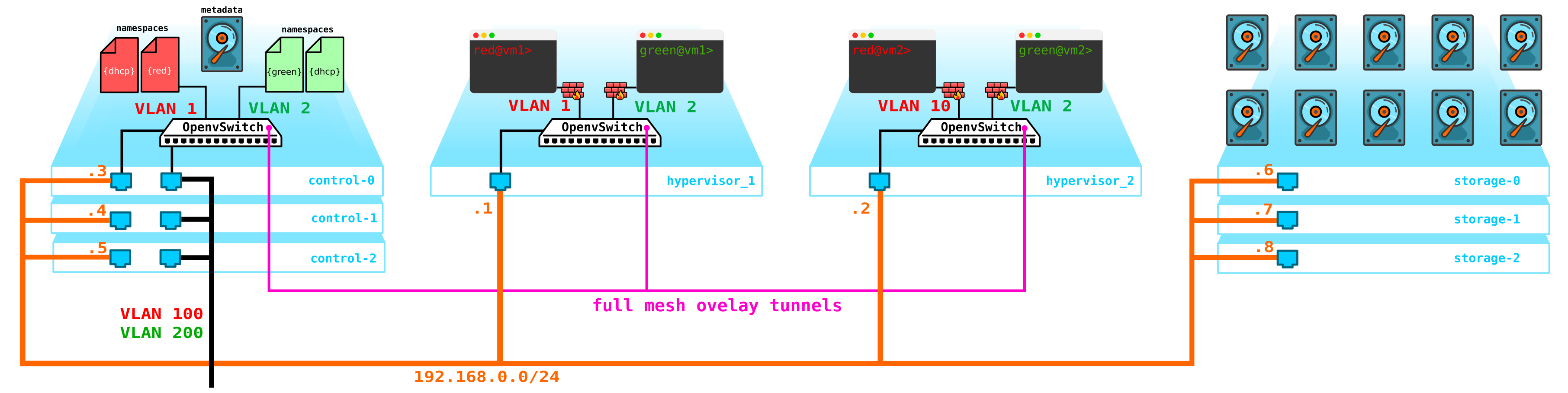
: compute — — storage+compute — ceph storage. — SDS . — — storage ( ) — CPU SDS ( , , ). compute storage.Tout cela doit être géré d'une manière ou d'une autre - nous avons besoin de quelque chose par lequel nous pouvons créer une machine, un réseau, un routeur virtuel, etc. Pour ce faire, ajoutez un service au nœud de contrôle qui fera office de tableau de bord - le client pourra se connecter à ce portail via http / https et faites tout ce dont vous avez besoin (enfin, presque).
En conséquence, nous avons maintenant un système tolérant aux pannes. Tous les éléments de cette infrastructure doivent être gérés d'une manière ou d'une autre. Il a été précédemment décrit qu'Openstack est un ensemble de projets, dont chacun fournit une fonction spécifique. Comme nous pouvons le voir, il y a plus qu'assez d'éléments qui doivent être configurés et contrôlés. Aujourd'hui, nous allons parler de la partie mise en réseau.
Architecture neutronique
Dans OpenStack, c'est Neutron qui est responsable de la connexion des ports des machines virtuelles à un réseau L2 commun, assurant le routage du trafic entre les VM situées dans différents réseaux L2, ainsi que le routage vers l'extérieur, fournissant des services tels que NAT, Floating IP, DHCP, etc. Le fonctionnement de
haut niveau du service réseau ( partie de base) peut être décrite comme suit.
Lors du démarrage de la VM, le service réseau:
- Crée un port pour cette VM (ou ces ports) et en informe le service DHCP;
- Un nouveau périphérique réseau virtuel est créé (via libvirt);
- La VM se connecte au port (ports) créé à l'étape 1;
Curieusement, mais au cœur du travail de Neutron se trouvent des mécanismes standards familiers à tous ceux qui ont déjà plongé dans Linux - espaces de noms, iptables, ponts Linux, openvswitch, conntrack, etc.
Il convient de préciser immédiatement que Neutron n'est pas un contrôleur SDN.
Neutron se compose de plusieurs composants interconnectés:
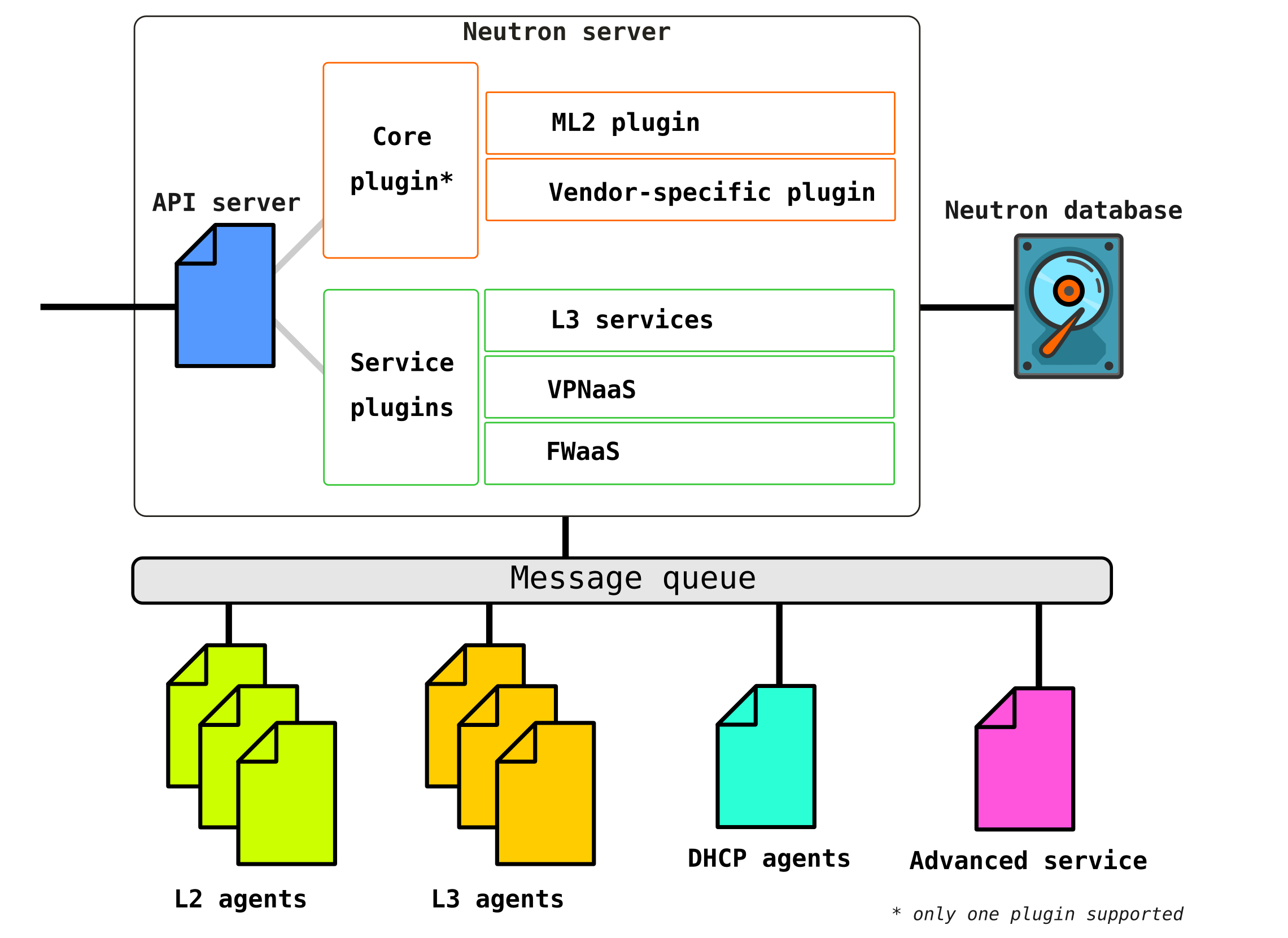
Openstack-neutron-server est un démon qui fonctionne avec les demandes des utilisateurs via une API. Ce démon ne prescrit aucune connectivité réseau, mais donne les informations nécessaires pour cela à ses plugins, qui configurent ensuite l'élément réseau requis. Les agents Neutron sur les nœuds OpenStack s'enregistrent auprès du serveur Neutron.
Neutron-server est en fait une application écrite en python, composée de deux parties:
- Service REST
- Plugin Neutron (noyau / service)
Un service REST est conçu pour recevoir des appels d'API d'autres composants (par exemple, une demande de fourniture d'informations, etc.) Les
plugins sont des composants / modules logiciels de plug-in qui sont appelés à la suite de demandes d'API - c'est-à-dire qu'un service est attribué via eux. Les plugins sont divisés en deux types - service et racine. En règle générale, le plug-in horse est principalement responsable de la gestion de l'espace d'adressage et des connexions L2 entre les machines virtuelles, et les plug-ins de service fournissent déjà des fonctionnalités supplémentaires, telles que VPN ou FW.
La liste des plugins disponibles pour aujourd'hui peut être consultée par exemple ici. Il
peut y avoir plusieurs plugins de service, mais il ne peut y avoir qu'un seul plugin horse.
Openstack-neutron-ml2Est le plugin racine standard d'Openstack. Ce plug-in a une architecture modulaire (contrairement à son prédécesseur) et configure le service réseau via les drivers qui lui sont connectés. Nous examinerons le plugin lui-même un peu plus tard, car il donne en fait la flexibilité qu'OpenStack a dans la partie réseau. Le plugin racine peut être remplacé (par exemple, Contrail Networking effectue un tel remplacement).
Service RPC (rabbitmq-server) - Un service qui fournit la gestion des files d'attente et la communication avec d'autres services OpenStack, ainsi que la communication entre les agents de service réseau.
Agents de réseau - agents situés dans chaque nœud via lequel les services réseau sont configurés.
Les agents sont de plusieurs types.
L'agent principal estAgent L2 . Ces agents s'exécutent sur chacun des hyperviseurs, y compris les nœuds de contrôle (plus précisément, sur tous les nœuds qui fournissent un service aux locataires) et leur fonction principale est de connecter des machines virtuelles à un réseau L2 commun, ainsi que de générer des alertes lorsque des événements se produisent (par exemple désactiver / activer le port).
L'agent suivant, non moins important, est l' agent L3... Par défaut, cet agent s'exécute exclusivement sur le nœud de réseau (souvent un nœud de réseau est combiné avec un nœud de contrôle) et assure le routage entre les réseaux de locataires (à la fois entre ses réseaux et les réseaux d'autres locataires, et est disponible pour le monde extérieur, fournissant des services NAT et DHCP). Cependant, lors de l'utilisation d'un DVR (routeur distribué), le besoin d'un plugin L3 apparaît également sur les nœuds de calcul.
L'agent L3 utilise des espaces de noms Linux pour fournir à chaque client un ensemble de ses propres réseaux isolés et les fonctionnalités de routeurs virtuels qui acheminent le trafic et fournissent des services de passerelle pour les réseaux de couche 2.
Base de données - une base de données d'identificateurs de réseaux, de sous-réseaux, de ports, de pools, etc.
En fait, Neutron accepte les requêtes API dès la création de toute entité réseau, authentifie la requête, et via RPC (s'il s'adresse à un plugin ou agent) ou l'API REST (s'il communique en SDN) envoie aux agents (via des plugins) les instructions nécessaires pour organiser le service demandé ...
Passons maintenant à l'installation de test (comment elle est déployée et ce qu'elle contient plus loin dans la partie pratique) et voyons où se trouve quel composant:
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$ 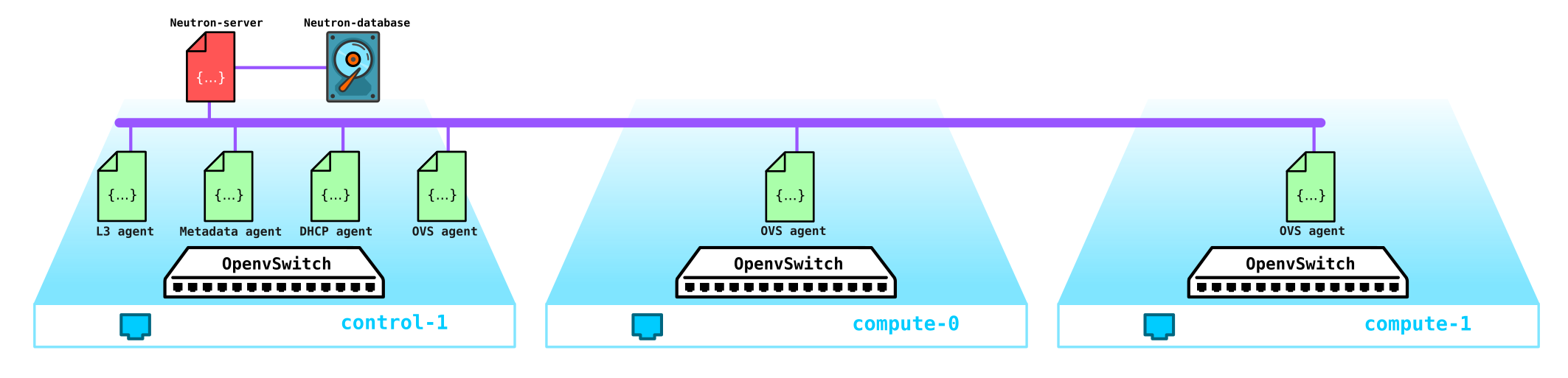
En fait, c'est toute la structure de Neutron. Maintenant, cela vaut la peine de prendre un peu de temps pour le plugin ML2.
Couche modulaire 2
Comme indiqué ci-dessus, le plugin est un plugin racine OpenStack standard et a une architecture modulaire.
Le prédécesseur du plug-in ML2 avait une structure monolithique qui ne permettait pas, par exemple, d'utiliser un mélange de plusieurs technologies dans une seule installation. Par exemple, vous ne pouvez pas utiliser à la fois openvswitch et linuxbridge en même temps - que ce soit le premier ou le second. Pour cette raison, le plugin ML2 avec son architecture a été créé.
ML2 a deux composants - deux types de pilotes: les pilotes de type et les pilotes de mécanisme.
Les pilotes de type définissent les technologies qui seront utilisées pour organiser la connectivité réseau, par exemple VxLAN, VLAN, GRE. Dans ce cas, le pilote vous permet d'utiliser différentes technologies. La technologie standard est l'encapsulation VxLAN pour les réseaux de superposition et les réseaux externes vlan.
Les pilotes de type incluent les types de réseaux suivants:
Plat - un réseau sans balisage
VLAN - un réseau balisé
Local - un type spécial de réseau pour les installations tout-en-un (de telles installations sont nécessaires soit pour les développeurs soit pour la formation)
GRE - réseau de superposition utilisant des tunnels GRE
VxLAN - réseau de superposition utilisant des tunnels VxLAN
Les pilotes de mécanisme définissent les moyens qui assurent l'organisation des technologies spécifiées dans le pilote de type - par exemple, openvswitch, sr-iov, opendaylight, OVN, etc.
En fonction de l'implémentation de ce pilote, soit des agents contrôlés par Neutron seront utilisés, soit des connexions avec un contrôleur SDN externe seront utilisées, qui prend en charge toutes les questions d'organisation des réseaux L2, de routage, etc.
Exemple Si nous utilisons ML2 avec OVS, alors sur chaque nœud de calcul est configuré avec un agent L2 qui contrôle OVS. Cependant, si nous utilisons, par exemple, OVN ou OpenDayLight, alors le contrôle OVS relève de leur juridiction - Neutron donne des commandes au contrôleur via le plugin racine, et il fait déjà ce qu'on lui a dit.
Rafraîchissons notre mémoire Open vSwitch
Pour le moment, l'un des composants clés d'OpenStack est Open vSwitch.
Lors de l'installation d'OpenStack sans aucun SDN de fournisseur supplémentaire tel que Juniper Contrail ou Nokia Nuage, OVS est le principal composant réseau du réseau cloud et, avec iptables, conntrack, les espaces de noms, vous permet d'organiser un réseau de superposition à part entière avec la multi-location. Naturellement, ce composant peut être remplacé, par exemple, lors de l'utilisation de solutions SDN propriétaires tierces (fournisseur).
OVS est un commutateur logiciel open source conçu pour être utilisé dans des environnements virtualisés en tant que transitaire de trafic virtuel.
Pour le moment, OVS a des fonctionnalités très décentes, qui incluent des technologies telles que QoS, LACP, VLAN, VxLAN, GENEVE, OpenFlow, DPDK, etc.
Remarque: à l'origine, OVS n'a pas été conçu comme un commutateur logiciel pour les fonctions de télécommunications à forte charge et a plutôt été conçu pour des fonctions informatiques moins gourmandes en bande passante telles qu'un serveur WEB ou un serveur de messagerie. Cependant, OVS est en cours de finalisation et les implémentations actuelles d'OVS ont considérablement amélioré ses performances et ses capacités, ce qui lui permet d'être utilisé par les opérateurs de télécommunications avec des fonctions très chargées, par exemple, il existe une implémentation OVS avec prise en charge de l'accélération DPDK.
Il y a trois composants OVS importants à connaître:
- Module noyau - un composant situé dans l'espace noyau qui traite le trafic en fonction des règles reçues du contrôle;
- vSwitch daemon (ovs-vswitchd) — , user space, kernel —
- Database server — , , OVS, . OVSDB SDN .
Tout cela est également accompagné d'un ensemble d'utilitaires de diagnostic et de gestion, tels que ovs-vsctl, ovs-appctl, ovs-ofctl, etc.
Actuellement, Openstack est largement utilisé par les opérateurs de télécommunications pour y migrer des fonctions réseau, telles que EPC, SBC, HLR et ainsi de suite. Certaines fonctions peuvent vivre sans problème avec OVS sous la forme dans laquelle il se trouve, mais par exemple, EPC traite le trafic des abonnés - c'est-à-dire qu'il fait passer une énorme quantité de trafic à travers lui-même (maintenant les volumes de trafic atteignent plusieurs centaines de gigabits par seconde). Naturellement, conduire un tel trafic à travers l'espace du noyau (puisque le transitaire y est localisé par défaut) n'est pas une bonne idée. Par conséquent, OVS est souvent déployé entièrement dans l'espace utilisateur à l'aide de la technologie d'accélération DPDK pour transférer le trafic de la carte réseau vers l'espace utilisateur en contournant le noyau.
Remarque: pour un cloud déployé pour les fonctions télécoms, il est possible de sortir le trafic du nœud de calcul en contournant OVS directement vers l'équipement de commutation. Les mécanismes SR-IOV et Passthrough sont utilisés à cet effet.
Comment ça marche sur une vraie mise en page?
Eh bien, passons maintenant à la partie pratique et voyons comment tout cela fonctionne dans la pratique.
Commençons par déployer une installation Openstack simple. Comme je n'ai pas un ensemble de serveurs sous la main pour des expériences, nous assemblerons la mise en page sur un serveur physique à partir de machines virtuelles. Oui, bien sûr, une telle solution ne convient pas à des fins commerciales, mais pour regarder un exemple du fonctionnement du réseau dans Openstack, une telle installation suffira aux yeux. De plus, une telle installation à des fins de formation est encore plus intéressante - car vous pouvez attraper du trafic, etc.
Comme nous n'avons besoin de voir que la partie de base, nous ne pouvons pas utiliser plusieurs réseaux, mais tout lever en utilisant seulement deux réseaux, et le deuxième réseau de cette disposition sera utilisé exclusivement pour accéder au serveur undercloud et dns. Nous n'allons pas aborder les réseaux externes pour le moment - c'est un sujet pour un grand article séparé.
Alors commençons dans l'ordre. Tout d'abord, une petite théorie. Nous installerons Openstack en utilisant TripleO (Openstack sur Openstack). L'essence de TripleO est que nous installons un tout-en-un Openstack (c'est-à-dire sur un nœud), appelé undercloud, puis utilisons les capacités de l'Openstack déployé pour installer un Openstack destiné à l'exploitation, appelé overcloud. Undercloud utilisera la capacité inhérente à gérer des serveurs physiques (bare metal) - le projet Ironic - pour provisionner des hyperviseurs qui serviront de nœuds de calcul, de contrôle et de stockage. Autrement dit, nous n'utilisons aucun outil tiers pour déployer Openstack - nous déployons Openstack avec Openstack. Plus loin dans l'installation, cela deviendra beaucoup plus clair, nous ne nous arrêterons donc pas là et continuerons.
: Openstack, . — , , . . ceph ( ) (Storage management Storage) , , QoS , . .
Remarque: puisque nous allons exécuter des machines virtuelles dans un environnement virtuel basé sur des machines virtuelles, nous devons d'abord activer la virtualisation imbriquée.
Vous pouvez vérifier si la virtualisation imbriquée est activée ou non comme ceci:
[root@hp-gen9 bormoglotx]# cat /sys/module/kvm_intel/parameters/nested N [root@hp-gen9 bormoglotx]#
Si vous voyez la lettre N, nous activons la prise en charge de la virtualisation imbriquée en fonction de n'importe quel guide que vous trouvez sur le réseau, par exemple celui-ci .
Nous devons assembler le schéma suivant à partir de machines virtuelles:

Dans mon cas, pour la connectivité des machines virtuelles qui font partie de la future installation (et j'en ai 7, mais vous pouvez vous en tirer avec 4 si vous n'avez pas beaucoup de ressources), j'ai utilisé OpenvSwitch. J'ai créé un pont ovs et y ai connecté des machines virtuelles via des groupes de ports. Pour ce faire, j'ai créé un fichier xml de la forme suivante:
[root@hp-gen9 ~]# virsh net-dumpxml ovs-network-1
<network>
<name>ovs-network-1</name>
<uuid>7a2e7de7-fc16-4e00-b1ed-4d190133af67</uuid>
<forward mode='bridge'/>
<bridge name='ovs-br1'/>
<virtualport type='openvswitch'/>
<portgroup name='trunk-1'>
<vlan trunk='yes'>
<tag id='100'/>
<tag id='101'/>
<tag id='102'/>
</vlan>
</portgroup>
<portgroup name='access-100'>
<vlan>
<tag id='100'/>
</vlan>
</portgroup>
<portgroup name='access-101'>
<vlan>
<tag id='101'/>
</vlan>
</portgroup>
</network>Trois ports du groupe sont déclarés ici - deux accès et un trunk (ce dernier était nécessaire pour un serveur DNS, mais vous pouvez vous en passer, ou le monter sur la machine hôte - c'est ce qui vous convient le mieux). Ensuite, en utilisant ce modèle, nous déclarons notre est via virsh net-define:
virsh net-define ovs-network-1.xml
virsh net-start ovs-network-1
virsh net-autostart ovs-network-1 Modifions maintenant la configuration des ports de l'hyperviseur:
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens1f0
TYPE=Ethernet
NAME=ens1f0
DEVICE=ens1f0
TYPE=OVSPort
DEVICETYPE=ovs
OVS_BRIDGE=ovs-br1
ONBOOT=yes
OVS_OPTIONS="trunk=100,101,102"
[root@hp-gen9 ~]
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ovs-br1
DEVICE=ovs-br1
DEVICETYPE=ovs
TYPE=OVSBridge
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.255.200
PREFIX=24
[root@hp-gen9 ~]# Remarque: dans ce scénario, l'adresse sur le port ovs-br1 ne sera pas disponible, car elle ne possède pas de balise vlan. Pour résoudre ce problème, exécutez la commande sudo ovs-vsctl set port ovs-br1 tag = 100. Cependant, après un redémarrage, cette balise disparaîtra (si quelqu'un sait comment la faire rester en place, je vous en serai très reconnaissant). Mais ce n'est pas si important, car nous n'aurons besoin de cette adresse que pour le moment de l'installation et ne seront pas nécessaires lorsque Openstack sera entièrement déployé.Ensuite, nous créons une voiture sous le nuage:
virt-install -n undercloud --description "undercloud" --os-type=Linux --os-variant=centos7.0 --ram=8192 --vcpus=8 --disk path=/var/lib/libvirt/images/undercloud.qcow2,bus=virtio,size=40,format=qcow2 --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=access-101 --graphics none --location /var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-2003.iso --extra-args console=ttyS0Lors de l'installation, vous définissez tous les paramètres nécessaires, tels que le nom de la machine, les mots de passe, les utilisateurs, les serveurs ntp, etc., vous pouvez immédiatement configurer les ports, mais après l'installation, il m'est plus facile d'entrer dans la machine via la console et de corriger les fichiers nécessaires. Si vous avez déjà une image prête à l'emploi, vous pouvez l'utiliser ou faire comme moi - télécharger l'image minimale de Centos 7 et l'utiliser pour installer la VM.
Après une installation réussie, vous devriez avoir une machine virtuelle sur laquelle vous pouvez installer undercloud
[root@hp-gen9 bormoglotx]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
62 undercloud runningTout d'abord, nous installons les outils nécessaires lors du processus d'installation:
sudo yum update -y
sudo yum install -y net-tools
sudo yum install -y wget
sudo yum install -y ipmitool
Installation d'Undercloud
Créez un utilisateur de pile, définissez un mot de passe, ajoutez-le à sudoer et donnez-lui la possibilité d'exécuter des commandes root via sudo sans avoir à entrer de mot de passe:
useradd stack
passwd stack
echo “stack ALL=(root) NOPASSWD:ALL” > /etc/sudoers.d/stack
chmod 0440 /etc/sudoers.d/stackMaintenant, nous spécifions le nom complet undercloud dans le fichier hosts:
vi /etc/hosts
127.0.0.1 undercloud.openstack.rnd localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6Ensuite, ajoutez les référentiels et installez les logiciels dont nous avons besoin:
sudo yum install -y https://trunk.rdoproject.org/centos7/current/python2-tripleo-repos-0.0.1-0.20200409224957.8bac392.el7.noarch.rpm
sudo -E tripleo-repos -b queens current
sudo -E tripleo-repos -b queens current ceph
sudo yum install -y python-tripleoclient
sudo yum install -y ceph-ansibleRemarque: si vous ne prévoyez pas d'installer ceph, vous n'avez pas besoin d'entrer les commandes liées à ceph. J'ai utilisé la version Queens, mais vous pouvez utiliser ce que vous voulez.Ensuite, copiez le fichier de configuration undercloud dans le répertoire de base de la pile de l'utilisateur:
cp /usr/share/instack-undercloud/undercloud.conf.sample ~/undercloud.confNous devons maintenant corriger ce fichier en l'ajustant à notre installation.
Au début du fichier, ajoutez ces lignes:
vi undercloud.conf
[DEFAULT]
undercloud_hostname = undercloud.openstack.rnd
local_ip = 192.168.255.1/24
network_gateway = 192.168.255.1
undercloud_public_host = 192.168.255.2
undercloud_admin_host = 192.168.255.3
undercloud_nameservers = 192.168.255.253
generate_service_certificate = false
local_interface = eth0
local_mtu = 1450
network_cidr = 192.168.255.0/24
masquerade = true
masquerade_network = 192.168.255.0/24
dhcp_start = 192.168.255.11
dhcp_end = 192.168.255.50
inspection_iprange = 192.168.255.51,192.168.255.100
scheduler_max_attempts = 10Alors, passez par les paramètres:
undercloud_hostname - le nom complet du serveur
undercloud doit correspondre à l'entrée du serveur DNS local_ip - l'adresse locale undercloud vers le réseau de
provizhening network_gateway - la même adresse locale, qui servira de passerelle pour l'accès au monde extérieur lors de l'installation overcloud node, correspond également à l' adresse IP locale
undercloud_public_host - adresse d'API externe, affectée de toute adresse gratuite du réseau d'approvisionnement
sous l'adresse API interne de undercloud_admin_host, affectée de n'importe quelle adresse libre du réseau d'approvisionnement
undercloud_nameservers - serveur DNS
generate_service_certificate- cette ligne est très importante dans l'exemple actuel, car si elle n'est pas définie sur false vous recevrez une erreur lors de l'installation, le problème est décrit sur l' interface
local_interface du traqueur de bogues Red Hat dans le provisionnement du réseau. Cette interface sera reconfigurée lors du déploiement de undercloud, vous devez donc avoir deux interfaces sur undercloud - une pour y accéder, la seconde pour provisionner
local_mtu - MTU. Puisque nous avons un laboratoire de test et MTU j'ai 1500 ports OVS Svicha, il faut mettre en valeur en 1450, qui auraient été encapsulés dans des packages
VxLAN network_cidr - provisioning network
masquerade - l'utilisation du NAT pour accéder au réseau externe
masquerade_network - un réseau qui va NAT -sya
dhcp_start - l'adresse de départ du pool d'adresses à partir de laquelle les adresses seront attribuées aux nœuds lors du déploiement overcloud
dhcp_end - l'adresse finale du pool d'adresses à partir de laquelle les adresses seront attribuées aux nœuds lors du déploiement overcloud
inspection_iprange - le pool d'adresses requises pour l'introspection (ne doit pas croiser le pool mentionné ci-dessus )
scheduler_max_attempts - le nombre maximum de tentatives d'installation d'overcloud (doit être supérieur ou égal au nombre de nœuds) Une
fois le fichier décrit, vous pouvez donner la commande pour déployer undercloud:
openstack undercloud install
La procédure prend 10 à 30 minutes, selon votre fer. En fin de compte, vous devriez voir une sortie comme celle-ci:
vi undercloud.conf
2020-08-13 23:13:12,668 INFO:
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and should be
secured.
#############################################################################Cette sortie indique que vous avez installé avec succès undercloud et que vous pouvez maintenant vérifier l'état de undercloud et procéder à l'installation d'overcloud.
Si vous regardez la sortie d'ifconfig, vous verrez qu'une nouvelle interface de pont est apparue
[stack@undercloud ~]$ ifconfig
br-ctlplane: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.1 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe2c:89e prefixlen 64 scopeid 0x20<link>
ether 52:54:00:2c:08:9e txqueuelen 1000 (Ethernet)
RX packets 14 bytes 1095 (1.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 20 bytes 1292 (1.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Le déploiement d'Overcloud sera désormais effectué via cette interface.
À partir de la sortie ci-dessous, on peut voir que nous avons tous les services sur un nœud:
(undercloud) [stack@undercloud ~]$ openstack host list
+--------------------------+-----------+----------+
| Host Name | Service | Zone |
+--------------------------+-----------+----------+
| undercloud.openstack.rnd | conductor | internal |
| undercloud.openstack.rnd | scheduler | internal |
| undercloud.openstack.rnd | compute | nova |
+--------------------------+-----------+----------+Voici la configuration de la partie réseau undercloud:
(undercloud) [stack@undercloud ~]$ python -m json.tool /etc/os-net-config/config.json
{
"network_config": [
{
"addresses": [
{
"ip_netmask": "192.168.255.1/24"
}
],
"members": [
{
"dns_servers": [
"192.168.255.253"
],
"mtu": 1450,
"name": "eth0",
"primary": "true",
"type": "interface"
}
],
"mtu": 1450,
"name": "br-ctlplane",
"ovs_extra": [
"br-set-external-id br-ctlplane bridge-id br-ctlplane"
],
"routes": [],
"type": "ovs_bridge"
}
]
}
(undercloud) [stack@undercloud ~]$Installation Overcloud
Pour le moment, nous n'avons que undercloud, et nous n'avons pas assez de nœuds à partir desquels l'overcloud sera construit. Par conséquent, tout d'abord, nous déploierons les machines virtuelles dont nous avons besoin. Pendant le déploiement, undercloud lui-même installera le système d'exploitation et les logiciels nécessaires sur la machine overcloud - c'est-à-dire que nous n'avons pas besoin de déployer complètement la machine, mais seulement de créer un disque (ou des disques) pour elle et de déterminer ses paramètres - c'est-à-dire que nous obtenons un serveur nu sans système d'exploitation installé dessus ...
Accédez au dossier contenant les disques de nos machines virtuelles et créez des disques de la taille requise:
cd /var/lib/libvirt/images/
qemu-img create -f qcow2 -o preallocation=metadata control-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-2.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata storage-1.qcow2 160G
qemu-img create -f qcow2 -o preallocation=metadata storage-2.qcow2 160GPuisque nous agissons à partir de la racine, nous devons changer le propriétaire de ces disques afin de ne pas avoir de problème avec les droits:
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:07 undercloud.qcow2
[root@hp-gen9 images]#
[root@hp-gen9 images]#
[root@hp-gen9 images]# chown qemu:qemu /var/lib/libvirt/images/*qcow2
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:08 undercloud.qcow2
[root@hp-gen9 images]# Remarque: si vous prévoyez d'installer ceph pour l'étudier, créez au moins 3 nœuds avec au moins deux disques, et dans le modèle indiquez que les disques virtuels vda, vdb, etc. seront utilisés.Génial, maintenant nous devons définir toutes ces machines:
virt-install --name control-1 --ram 32768 --vcpus 8 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/control-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=trunk-1 --dry-run --print-xml > /tmp/control-1.xml
virt-install --name storage-1 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-1.xml
virt-install --name storage-2 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-2.xml
virt-install --name compute-1 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-1.xml
virt-install --name compute-2 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-2.xml À la fin, il y a les commandes --print-xml> /tmp/storage-1.xml, qui crée un fichier xml avec une description de chaque machine dans le dossier / tmp /, si vous ne l'ajoutez pas, vous ne pourrez pas définir de machines virtuelles.
Nous devons maintenant définir toutes ces machines dans virsh:
virsh define --file /tmp/control-1.xml
virsh define --file /tmp/compute-1.xml
virsh define --file /tmp/compute-2.xml
virsh define --file /tmp/storage-1.xml
virsh define --file /tmp/storage-2.xml
[root@hp-gen9 ~]# virsh list --all
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
- compute-1 shut off
- compute-2 shut off
- control-1 shut off
- storage-1 shut off
- storage-2 shut off
[root@hp-gen9 ~]#Maintenant une petite nuance - tripleO utilise IPMI afin de gérer les serveurs pendant l'installation et l'introspection.
L'introspection est le processus d'inspection du matériel afin d'obtenir ses paramètres nécessaires à l'approvisionnement ultérieur des nœuds. L'introspection est effectuée en utilisant ironic - un service conçu pour fonctionner avec des serveurs bare metal.
Mais voici le problème - si les serveurs de fer IPMI ont un port séparé (ou un port partagé, mais ce n'est pas important), alors les machines virtuelles n'ont pas de tels ports. Ici, une béquille appelée vbmc vient à notre secours - un utilitaire qui vous permet d'émuler un port IPMI. Cette nuance mérite une attention particulière, en particulier pour ceux qui veulent soulever un tel laboratoire sur un hyperviseur ESXI - si, bien sûr, je ne sais pas s'il a un analogue de vbmc, vous devriez donc être intrigué par cette question avant de tout déployer.
Installez vbmc:
yum install yum install python2-virtualbmcSi votre système d'exploitation ne trouve pas le package, ajoutez le référentiel:
yum install -y https://www.rdoproject.org/repos/rdo-release.rpmMaintenant, nous configurons l'utilitaire. Tout est banal de disgrâce ici. Maintenant, il est logique qu'il n'y ait pas de serveurs dans la liste vbmc
[root@hp-gen9 ~]# vbmc list
[root@hp-gen9 ~]# Pour qu'ils apparaissent, ils doivent être déclarés manuellement de cette manière:
[root@hp-gen9 ~]# vbmc add control-1 --port 7001 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-1 --port 7002 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-2 --port 7003 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-1 --port 7004 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-2 --port 7005 --username admin --password admin
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+--------+---------+------+
| Domain name | Status | Address | Port |
+-------------+--------+---------+------+
| compute-1 | down | :: | 7004 |
| compute-2 | down | :: | 7005 |
| control-1 | down | :: | 7001 |
| storage-1 | down | :: | 7002 |
| storage-2 | down | :: | 7003 |
+-------------+--------+---------+------+
[root@hp-gen9 ~]#Je pense que la syntaxe de la commande est claire et sans explication. Cependant, pour l'instant, toutes nos sessions sont à l'état DOWN. Pour qu'ils passent à l'état UP, vous devez les activer:
[root@hp-gen9 ~]# vbmc start control-1
2020-08-14 03:15:57,826.826 13149 INFO VirtualBMC [-] Started vBMC instance for domain control-1
[root@hp-gen9 ~]# vbmc start storage-1
2020-08-14 03:15:58,316.316 13149 INFO VirtualBMC [-] Started vBMC instance for domain storage-1
[root@hp-gen9 ~]# vbmc start storage-2
2020-08-14 03:15:58,851.851 13149 INFO VirtualBMC [-] Started vBMC instance for domain storage-2
[root@hp-gen9 ~]# vbmc start compute-1
2020-08-14 03:15:59,307.307 13149 INFO VirtualBMC [-] Started vBMC instance for domain compute-1
[root@hp-gen9 ~]# vbmc start compute-2
2020-08-14 03:15:59,712.712 13149 INFO VirtualBMC [-] Started vBMC instance for domain compute-2
[root@hp-gen9 ~]#
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+---------+---------+------+
| Domain name | Status | Address | Port |
+-------------+---------+---------+------+
| compute-1 | running | :: | 7004 |
| compute-2 | running | :: | 7005 |
| control-1 | running | :: | 7001 |
| storage-1 | running | :: | 7002 |
| storage-2 | running | :: | 7003 |
+-------------+---------+---------+------+
[root@hp-gen9 ~]#Et la touche finale - vous devez corriger les règles du pare-feu (enfin, ou le désactiver complètement):
firewall-cmd --zone=public --add-port=7001/udp --permanent
firewall-cmd --zone=public --add-port=7002/udp --permanent
firewall-cmd --zone=public --add-port=7003/udp --permanent
firewall-cmd --zone=public --add-port=7004/udp --permanent
firewall-cmd --zone=public --add-port=7005/udp --permanent
firewall-cmd --reload
Passons maintenant à undercloud et vérifions que tout fonctionne. L'adresse de la machine hôte est 192.168.255.200, nous avons ajouté le package ipmitool nécessaire à undercloud lors de la préparation du déploiement:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power is off
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power on
Chassis Power Control: Up/On
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
65 control-1 runningComme vous pouvez le voir, nous avons lancé avec succès le nœud de contrôle via vbmc. Maintenant, désactivez-le et continuez:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power off
Chassis Power Control: Down/Off
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power is off
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list --all
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
- compute-1 shut off
- compute-2 shut off
- control-1 shut off
- storage-1 shut off
- storage-2 shut off
[root@hp-gen9 ~]#L'étape suivante est l'introspection des nœuds sur lesquels l'overcloud sera installé. Pour ce faire, nous devons préparer un fichier json avec une description de nos nœuds. Veuillez noter que, contrairement à l'installation sur des serveurs nus, le fichier spécifie le port sur lequel vbmc s'exécute pour chacune des machines.
[root@hp-gen9 ~]# virsh domiflist --domain control-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:20:a2:2f
- network ovs-network-1 virtio 52:54:00:3f:87:9f
[root@hp-gen9 ~]# virsh domiflist --domain compute-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:98:e9:d6
[root@hp-gen9 ~]# virsh domiflist --domain compute-2
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:6a:ea:be
[root@hp-gen9 ~]# virsh domiflist --domain storage-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:79:0b:cb
[root@hp-gen9 ~]# virsh domiflist --domain storage-2
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:a7:fe:27Remarque: il y a deux interfaces sur le nœud de contrôle, mais dans ce cas, cela n'a pas d'importance, dans cette installation, une nous suffira.Nous préparons maintenant un fichier json. Nous devons spécifier l'adresse poppy du port via lequel l'approvisionnement sera effectué, les paramètres du nœud, leur donner des noms et indiquer comment accéder à ipmi:
{
"nodes":[
{
"mac":[
"52:54:00:20:a2:2f"
],
"cpu":"8",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"control-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7001"
},
{
"mac":[
"52:54:00:79:0b:cb"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7002"
},
{
"mac":[
"52:54:00:a7:fe:27"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7003"
},
{
"mac":[
"52:54:00:98:e9:d6"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7004"
},
{
"mac":[
"52:54:00:6a:ea:be"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7005"
}
]
}Maintenant, nous devons préparer des images pour ironique. Pour ce faire, téléchargez-les via wget et installez:
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/overcloud-full.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/ironic-python-agent.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ ls -lh
total 1.9G
-rw-r--r--. 1 stack stack 447M Aug 14 10:26 ironic-python-agent.tar
-rw-r--r--. 1 stack stack 1.5G Aug 14 10:26 overcloud-full.tar
-rw-------. 1 stack stack 916 Aug 13 23:10 stackrc
-rw-r--r--. 1 stack stack 15K Aug 13 22:50 undercloud.conf
-rw-------. 1 stack stack 2.0K Aug 13 22:50 undercloud-passwords.conf
(undercloud) [stack@undercloud ~]$ mkdir images/
(undercloud) [stack@undercloud ~]$ tar -xpvf ironic-python-agent.tar -C ~/images/
ironic-python-agent.initramfs
ironic-python-agent.kernel
(undercloud) [stack@undercloud ~]$ tar -xpvf overcloud-full.tar -C ~/images/
overcloud-full.qcow2
overcloud-full.initrd
overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ ls -lh images/
total 1.9G
-rw-rw-r--. 1 stack stack 441M Aug 12 17:24 ironic-python-agent.initramfs
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:24 ironic-python-agent.kernel
-rw-r--r--. 1 stack stack 53M Aug 12 17:14 overcloud-full.initrd
-rw-r--r--. 1 stack stack 1.4G Aug 12 17:18 overcloud-full.qcow2
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:14 overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$Téléchargement d'images vers undercloud:
(undercloud) [stack@undercloud ~]$ openstack overcloud image upload --image-path ~/images/
Image "overcloud-full-vmlinuz" was uploaded.
+--------------------------------------+------------------------+-------------+---------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+------------------------+-------------+---------+--------+
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | aki | 6761064 | active |
+--------------------------------------+------------------------+-------------+---------+--------+
Image "overcloud-full-initrd" was uploaded.
+--------------------------------------+-----------------------+-------------+----------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+-----------------------+-------------+----------+--------+
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | ari | 55183045 | active |
+--------------------------------------+-----------------------+-------------+----------+--------+
Image "overcloud-full" was uploaded.
+--------------------------------------+----------------+-------------+------------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+----------------+-------------+------------+--------+
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | qcow2 | 1487475712 | active |
+--------------------------------------+----------------+-------------+------------+--------+
Image "bm-deploy-kernel" was uploaded.
+--------------------------------------+------------------+-------------+---------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+------------------+-------------+---------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | aki | 6761064 | active |
+--------------------------------------+------------------+-------------+---------+--------+
Image "bm-deploy-ramdisk" was uploaded.
+--------------------------------------+-------------------+-------------+-----------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+-------------------+-------------+-----------+--------+
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | ari | 461759376 | active |
+--------------------------------------+-------------------+-------------+-----------+--------+
(undercloud) [stack@undercloud ~]$Vérifiez que toutes les images sont chargées
(undercloud) [stack@undercloud ~]$ openstack image list
+--------------------------------------+------------------------+--------+
| ID | Name | Status |
+--------------------------------------+------------------------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | active |
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | active |
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | active |
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | active |
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | active |
+--------------------------------------+------------------------+--------+
(undercloud) [stack@undercloud ~]$Encore une touche - vous devez ajouter un serveur DNS:
(undercloud) [stack@undercloud ~]$ openstack subnet list
+--------------------------------------+-----------------+--------------------------------------+------------------+
| ID | Name | Network | Subnet |
+--------------------------------------+-----------------+--------------------------------------+------------------+
| f45dea46-4066-42aa-a3c4-6f84b8120cab | ctlplane-subnet | 6ca013dc-41c2-42d8-9d69-542afad53392 | 192.168.255.0/24 |
+--------------------------------------+-----------------+--------------------------------------+------------------+
(undercloud) [stack@undercloud ~]$ openstack subnet show f45dea46-4066-42aa-a3c4-6f84b8120cab
+-------------------+-----------------------------------------------------------+
| Field | Value |
+-------------------+-----------------------------------------------------------+
| allocation_pools | 192.168.255.11-192.168.255.50 |
| cidr | 192.168.255.0/24 |
| created_at | 2020-08-13T20:10:37Z |
| description | |
| dns_nameservers | |
| enable_dhcp | True |
| gateway_ip | 192.168.255.1 |
| host_routes | destination='169.254.169.254/32', gateway='192.168.255.1' |
| id | f45dea46-4066-42aa-a3c4-6f84b8120cab |
| ip_version | 4 |
| ipv6_address_mode | None |
| ipv6_ra_mode | None |
| name | ctlplane-subnet |
| network_id | 6ca013dc-41c2-42d8-9d69-542afad53392 |
| prefix_length | None |
| project_id | a844ccfcdb2745b198dde3e1b28c40a3 |
| revision_number | 0 |
| segment_id | None |
| service_types | |
| subnetpool_id | None |
| tags | |
| updated_at | 2020-08-13T20:10:37Z |
+-------------------+-----------------------------------------------------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ neutron subnet-update f45dea46-4066-42aa-a3c4-6f84b8120cab --dns-nameserver 192.168.255.253
neutron CLI is deprecated and will be removed in the future. Use openstack CLI instead.
Updated subnet: f45dea46-4066-42aa-a3c4-6f84b8120cab
(undercloud) [stack@undercloud ~]$Nous pouvons maintenant émettre la commande pour l'introspection:
(undercloud) [stack@undercloud ~]$ openstack overcloud node import --introspect --provide inspection.json
Started Mistral Workflow tripleo.baremetal.v1.register_or_update. Execution ID: d57456a3-d8ed-479c-9a90-dff7c752d0ec
Waiting for messages on queue 'tripleo' with no timeout.
5 node(s) successfully moved to the "manageable" state.
Successfully registered node UUID b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
Successfully registered node UUID b89a72a3-6bb7-429a-93bc-48393d225838
Successfully registered node UUID 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
Successfully registered node UUID bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
Successfully registered node UUID 766ab623-464c-423d-a529-d9afb69d1167
Waiting for introspection to finish...
Started Mistral Workflow tripleo.baremetal.v1.introspect. Execution ID: 6b4d08ae-94c3-4a10-ab63-7634ec198a79
Waiting for messages on queue 'tripleo' with no timeout.
Introspection of node b89a72a3-6bb7-429a-93bc-48393d225838 completed. Status:SUCCESS. Errors:None
Introspection of node 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e completed. Status:SUCCESS. Errors:None
Introspection of node bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 completed. Status:SUCCESS. Errors:None
Introspection of node 766ab623-464c-423d-a529-d9afb69d1167 completed. Status:SUCCESS. Errors:None
Introspection of node b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 completed. Status:SUCCESS. Errors:None
Successfully introspected 5 node(s).
Started Mistral Workflow tripleo.baremetal.v1.provide. Execution ID: f5594736-edcf-4927-a8a0-2a7bf806a59a
Waiting for messages on queue 'tripleo' with no timeout.
5 node(s) successfully moved to the "available" state.
(undercloud) [stack@undercloud ~]$Comme vous pouvez le voir sur la sortie, tout s'est terminé sans erreur. Vérifions que tous les nœuds sont disponibles:
(undercloud) [stack@undercloud ~]$ openstack baremetal node list
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| UUID | Name | Instance UUID | Power State | Provisioning State | Maintenance |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | None | power off | available | False |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | None | power off | available | False |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | None | power off | available | False |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | None | power off | available | False |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | None | power off | available | False |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
(undercloud) [stack@undercloud ~]$ Si les nœuds sont dans un état différent, généralement gérable, alors quelque chose s'est mal passé et vous devez consulter le journal pour comprendre pourquoi cela s'est produit. Gardez à l'esprit que dans ce scénario, nous utilisons la virtualisation et qu'il peut y avoir des bogues associés à l'utilisation de machines virtuelles ou de vbmc.
Ensuite, nous devons spécifier quel nœud exécutera quelle fonction, c'est-à-dire indiquer le profil avec lequel le nœud se déploiera:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | available | None | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | available | None | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | available | None | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | available | None | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | available | None | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$ openstack flavor list
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| ID | Name | RAM | Disk | Ephemeral | VCPUs | Is Public |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| 168af640-7f40-42c7-91b2-989abc5c5d8f | swift-storage | 4096 | 40 | 0 | 1 | True |
| 52148d1b-492e-48b4-b5fc-772849dd1b78 | baremetal | 4096 | 40 | 0 | 1 | True |
| 56e66542-ae60-416d-863e-0cb192d01b09 | control | 4096 | 40 | 0 | 1 | True |
| af6796e1-d0c4-4bfe-898c-532be194f7ac | block-storage | 4096 | 40 | 0 | 1 | True |
| e4d50fdd-0034-446b-b72c-9da19b16c2df | compute | 4096 | 40 | 0 | 1 | True |
| fc2e3acf-7fca-4901-9eee-4a4d6ef0265d | ceph-storage | 4096 | 40 | 0 | 1 | True |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
(undercloud) [stack@undercloud ~]$Nous indiquons le profil de chaque nœud:
openstack baremetal node set --property capabilities='profile:control,boot_option:local' b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' b89a72a3-6bb7-429a-93bc-48393d225838
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' 766ab623-464c-423d-a529-d9afb69d1167Nous vérifions que nous avons tout fait correctement:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | available | control | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | available | ceph-storage | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | available | ceph-storage | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | available | compute | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | available | compute | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$Si tout est correct, nous donnons la commande de déployer overcloud:
openstack overcloud deploy --templates --control-scale 1 --compute-scale 2 --ceph-storage-scale 2 --control-flavor control --compute-flavor compute --ceph-storage-flavor ceph-storage --libvirt-type qemuDans une vraie installation, des modèles personnalisés seront naturellement utilisés, dans notre cas cela compliquera grandement le processus, puisqu'il sera nécessaire d'expliquer chaque modification dans le modèle. Comme il a été écrit plus tôt, même une simple installation nous suffira pour voir comment cela fonctionne.
Remarque: la variable --libvirt-type qemu est requise dans ce cas, car nous utiliserons la virtualisation imbriquée. Sinon, vous n'aurez pas de machines virtuelles en cours d'exécution.
Vous avez maintenant environ une heure, ou peut-être plus (selon les capacités du matériel) et vous ne pouvez qu'espérer qu'après ce délai, vous verrez l'inscription suivante:
2020-08-14 08:39:21Z [overcloud]: CREATE_COMPLETE Stack CREATE completed successfully
Stack overcloud CREATE_COMPLETE
Host 192.168.255.21 not found in /home/stack/.ssh/known_hosts
Started Mistral Workflow tripleo.deployment.v1.get_horizon_url. Execution ID: fcb996cd-6a19-482b-b755-2ca0c08069a9
Overcloud Endpoint: http://192.168.255.21:5000/
Overcloud Horizon Dashboard URL: http://192.168.255.21:80/dashboard
Overcloud rc file: /home/stack/overcloudrc
Overcloud Deployed
(undercloud) [stack@undercloud ~]$Vous avez maintenant une version presque complète de l'openstack, sur laquelle vous pouvez étudier, faire des expériences, etc.
Vérifions que tout fonctionne bien. Dans la pile du répertoire personnel de l'utilisateur, il y a deux fichiers - un stackrc (pour gérer undercloud) et l'autre overcloudrc (pour gérer overcloud). Ces fichiers doivent être spécifiés comme source, car ils contiennent les informations requises pour l'authentification.
(undercloud) [stack@undercloud ~]$ openstack server list
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| fd7d36f4-ce87-4b9a-93b0-add2957792de | overcloud-controller-0 | ACTIVE | ctlplane=192.168.255.15 | overcloud-full | control |
| edc77778-8972-475e-a541-ff40eb944197 | overcloud-novacompute-1 | ACTIVE | ctlplane=192.168.255.26 | overcloud-full | compute |
| 5448ce01-f05f-47ca-950a-ced14892c0d4 | overcloud-cephstorage-1 | ACTIVE | ctlplane=192.168.255.34 | overcloud-full | ceph-storage |
| ce6d862f-4bdf-4ba3-b711-7217915364d7 | overcloud-novacompute-0 | ACTIVE | ctlplane=192.168.255.19 | overcloud-full | compute |
| e4507bd5-6f96-4b12-9cc0-6924709da59e | overcloud-cephstorage-0 | ACTIVE | ctlplane=192.168.255.44 | overcloud-full | ceph-storage |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ source overcloudrc
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack project list
+----------------------------------+---------+
| ID | Name |
+----------------------------------+---------+
| 4eed7d0f06544625857d51cd77c5bd4c | admin |
| ee1c68758bde41eaa9912c81dc67dad8 | service |
+----------------------------------+---------+
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$Dans mon installation, une petite touche supplémentaire est nécessaire - pour ajouter une route sur le contrôleur, car la machine avec laquelle je travaille est sur un réseau différent. Pour ce faire, allez dans control-1 sous le compte heat-admin et écrivez l'itinéraire
(undercloud) [stack@undercloud ~]$ ssh heat-admin@192.168.255.15
Last login: Fri Aug 14 09:47:40 2020 from 192.168.255.1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ip route add 10.169.0.0/16 via 192.168.255.254Eh bien, maintenant vous pouvez aller à l'horizon. Toutes les informations - adresses, nom d'utilisateur et mot de passe - se trouvent dans le fichier / home / stack / overcloudrc. Le schéma final ressemble à ceci:

Au fait, dans notre installation, les adresses des machines ont été émises via DHCP et, comme vous pouvez le voir, elles sont émises «au hasard». Vous pouvez coder en dur dans le modèle quelle adresse doit être associée à quelle machine pendant le déploiement, si vous en avez besoin.
Comment le trafic circule-t-il entre les machines virtuelles?
Dans cet article, nous examinerons trois options pour faire passer le trafic
- Deux machines sur un hyperviseur dans un réseau L2
- Deux machines sur différents hyperviseurs dans un même réseau L2
- Deux machines sur des réseaux différents (enracinement entre réseaux)
Les cas d'accès au monde extérieur via un réseau externe, utilisant des adresses flottantes, ainsi que le routage distribué, seront examinés la prochaine fois, pour l'instant nous nous concentrerons sur le trafic interne.
Pour tester, mettons ensemble le schéma suivant:
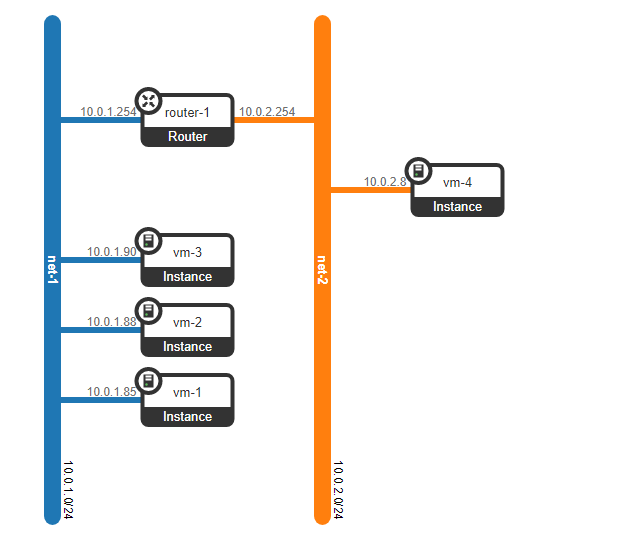
Nous avons créé 4 machines virtuelles - 3 dans un réseau L2 - net-1, et une autre dans le réseau net-2
(overcloud) [stack@undercloud ~]$ nova list --tenant 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| ID | Name | Tenant ID | Status | Task State | Power State | Networks |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| f53b37b5-2204-46cc-aef0-dba84bf970c0 | vm-1 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.85 |
| fc8b6722-0231-49b0-b2fa-041115bef34a | vm-2 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.88 |
| 3cd74455-b9b7-467a-abe3-bd6ff765c83c | vm-3 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.90 |
| 7e836338-6772-46b0-9950-f7f06dbe91a8 | vm-4 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-2=10.0.2.8 |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
(overcloud) [stack@undercloud ~]$ Voyons sur quels hyperviseurs se trouvent les machines créées:
(overcloud) [stack@undercloud ~]$ nova show f53b37b5-2204-46cc-aef0-dba84bf970c0 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-1 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000001 |(overcloud) [stack@undercloud ~]$ nova show fc8b6722-0231-49b0-b2fa-041115bef34a | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-2 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000002 |(overcloud) [stack@undercloud ~]$ nova show 3cd74455-b9b7-467a-abe3-bd6ff765c83c | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-3 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000003 |(overcloud) [stack@undercloud ~]$ nova show 7e836338-6772-46b0-9950-f7f06dbe91a8 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-4 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000004 |(overcloud) [stack @ undercloud ~] $ Les
machines vm-1 et vm-3 sont situées sur compute-0, les machines vm-2 et vm-4 sont situées sur le nœud compute-1.
De plus, un routeur virtuel a été créé pour permettre le routage entre les réseaux spécifiés:
(overcloud) [stack@undercloud ~]$ openstack router list --project 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| ID | Name | Status | State | Distributed | HA | Project |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | router-1 | ACTIVE | UP | False | False | 5e18ce8ec9594e00b155485f19895e6c |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
(overcloud) [stack@undercloud ~]$ Le routeur dispose de deux ports virtuels qui agissent comme des passerelles pour les réseaux:
(overcloud) [stack@undercloud ~]$ openstack router show 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | grep interface
| interfaces_info | [{"subnet_id": "2529ad1a-6b97-49cd-8515-cbdcbe5e3daa", "ip_address": "10.0.1.254", "port_id": "0c52b15f-8fcc-4801-bf52-7dacc72a5201"}, {"subnet_id": "335552dd-b35b-456b-9df0-5aac36a3ca13", "ip_address": "10.0.2.254", "port_id": "92fa49b5-5406-499f-ab8d-ddf28cc1a76c"}] |
(overcloud) [stack@undercloud ~]$ Mais avant de regarder comment se passe le trafic, regardons ce que nous avons pour le moment sur le nœud de contrôle (qui est également un nœud de réseau) et sur le nœud de calcul. Commençons par un nœud de calcul.
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-vsctl show
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:3 missed:3
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$Pour le moment, le nœud a trois ponts ovs - br-int, br-tun, br-ex. Entre eux, comme on peut le voir, il y a un ensemble d'interfaces. Pour faciliter la perception, nous allons mettre toutes ces interfaces sur le diagramme et voir ce qui se passe.

À partir des adresses auxquelles les tunnels VxLAN sont soulevés, vous pouvez voir qu'un tunnel est soulevé sur compute-1 (192.168.255.26), le deuxième tunnel regarde control-1 (192.168.255.15). Mais le plus intéressant est que br-ex n'a pas d'interfaces physiques, et si vous regardez quels flux sont configurés, vous pouvez voir que ce pont ne peut abandonner que du trafic pour le moment.
[heat-admin@overcloud-novacompute-0 ~]$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.19 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe6a:eabe prefixlen 64 scopeid 0x20<link>
ether 52:54:00:6a:ea:be txqueuelen 1000 (Ethernet)
RX packets 2909669 bytes 4608201000 (4.2 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1821057 bytes 349198520 (333.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-novacompute-0 ~]$ Comme vous pouvez le voir sur la sortie, l'adresse est vissée directement sur le port physique, et non sur l'interface du pont virtuel.
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-ex
cookie=0x9169eae8f7fe5bb2, duration=216686.864s, table=0, n_packets=303, n_bytes=26035, priority=2,in_port="phy-br-ex" actions=drop
cookie=0x9169eae8f7fe5bb2, duration=216686.887s, table=0, n_packets=0, n_bytes=0, priority=0 actions=NORMAL
[heat-admin@overcloud-novacompute-0 ~]$ Selon la première règle, tout ce qui provient du port phy-br-ex doit être jeté.
En fait, il n'y a nulle part d'autre pour que le trafic se rende à ce pont, sauf depuis cette interface (jonction avec br-int), et à en juger par les gouttes, le trafic BUM est déjà arrivé sur le pont.
Autrement dit, le trafic de ce nœud ne peut passer que par le tunnel VxLAN et rien d'autre. Cependant, si vous allumez le DVR, la situation changera, mais nous y reviendrons une autre fois. Lorsque vous utilisez l'isolation de réseau, par exemple en utilisant des vlans, vous n'aurez pas une interface L3 dans le 0ème vlan, mais plusieurs interfaces. Cependant, le trafic VxLAN sortira du nœud de la même manière, mais également encapsulé dans une sorte de vlan dédié.
Nous avons compris le nœud de calcul, allez au nœud de contrôle.
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl dpif/show
system@ovs-system: hit:930491 missed:825
br-ex:
br-ex 65534/1: (internal)
eth0 1/2: (system)
phy-br-ex 2/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/3: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/4: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff13 3/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.19)
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$En fait, on peut dire que tout est pareil, mais l'adresse IP n'est plus sur l'interface physique, mais sur le pont virtuel. Cela est dû au fait que ce port est un port par lequel le trafic ira vers le monde extérieur.
[heat-admin@overcloud-controller-0 ~]$ ifconfig br-ex
br-ex: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.15 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe20:a22f prefixlen 64 scopeid 0x20<link>
ether 52:54:00:20:a2:2f txqueuelen 1000 (Ethernet)
RX packets 803859 bytes 1732616116 (1.6 GiB)
RX errors 0 dropped 63 overruns 0 frame 0
TX packets 808475 bytes 121652156 (116.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
3 100 28:c0:da:00:4d:d3 35
1 0 28:c0:da:00:4d:d3 35
1 0 52:54:00:98:e9:d6 0
LOCAL 0 52:54:00:20:a2:2f 0
1 0 52:54:00:2c:08:9e 0
3 100 52:54:00:20:a2:2f 0
1 0 52:54:00:6a:ea:be 0
[heat-admin@overcloud-controller-0 ~]$ Ce port est lié au pont br-ex et comme il n'y a pas de balises vlan, ce port est un port trunk sur lequel tous les vlans sont autorisés, maintenant le trafic sort sans balise, comme indiqué par vlan-id 0 dans la sortie ci-dessus.
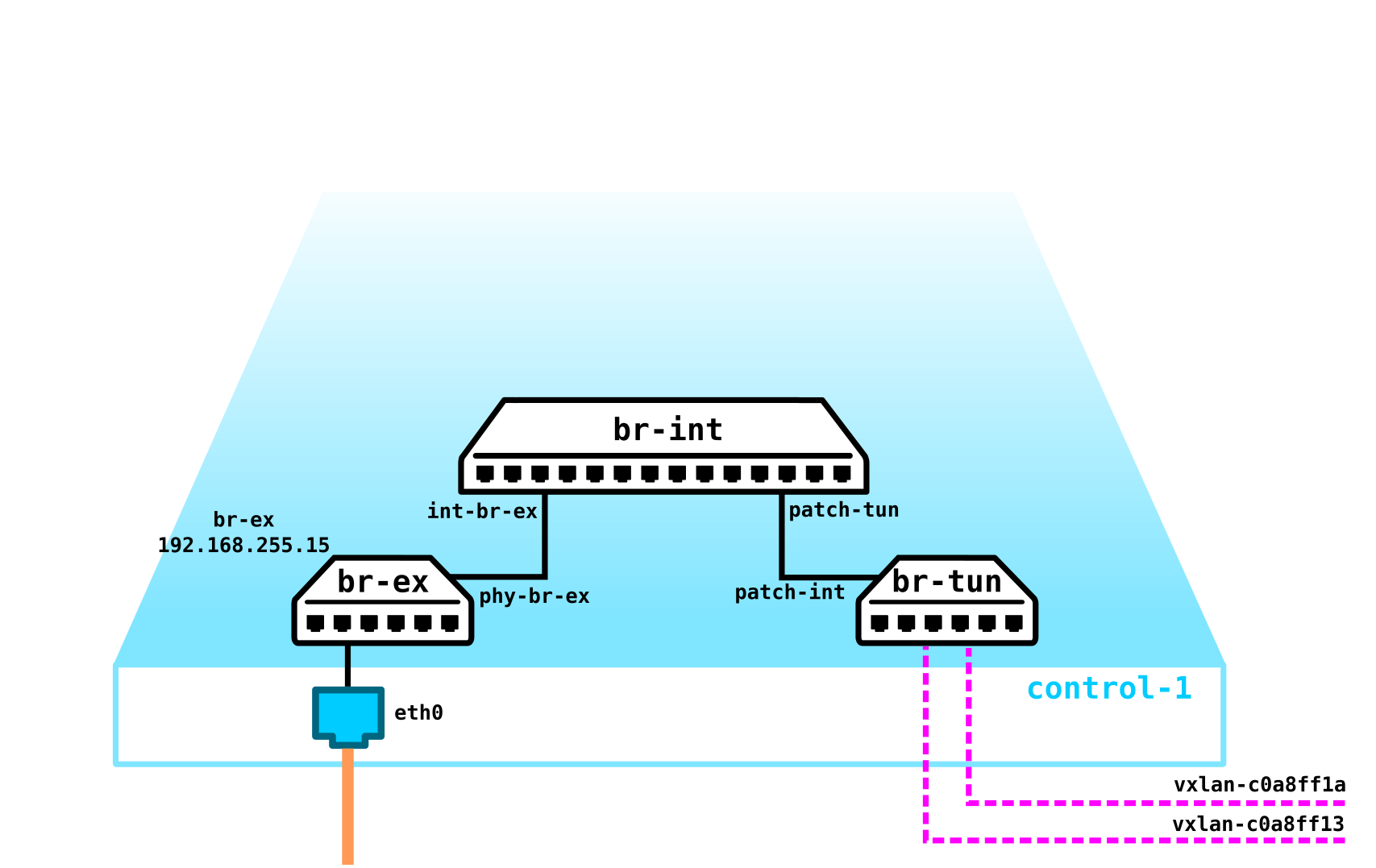
Tout le reste pour le moment est similaire au nœud de calcul - les mêmes ponts, les mêmes tunnels allant à deux nœuds de calcul.
Nous ne considérerons pas les nœuds de stockage dans cet article, mais pour comprendre il faut dire que la partie réseau de ces nœuds est banale au point de disgrâce. Dans notre cas, il n'y a qu'un seul port physique (eth0) avec une adresse IP accrochée dessus et c'est tout. Il n'y a pas de tunnels VxLAN, de ponts de tunnel, etc. - il n'y a pas du tout d'ov, car cela ne sert à rien. Lors de l'utilisation de l'isolation réseau - ce nœud aura deux interfaces (ports physiques, bauds, ou juste deux vlans - cela n'a pas d'importance - cela dépend de ce que vous voulez) - une pour la gestion, la seconde pour le trafic (écriture sur le disque VM, lecture à partir de disque, etc.).
Nous avons compris ce que nous avons sur les nœuds en l'absence de services. Maintenant, commençons 4 machines virtuelles et voyons comment le schéma décrit ci-dessus change - nous devrions avoir des ports, des routeurs virtuels, etc.
Jusqu'à présent, notre réseau ressemble à ceci:
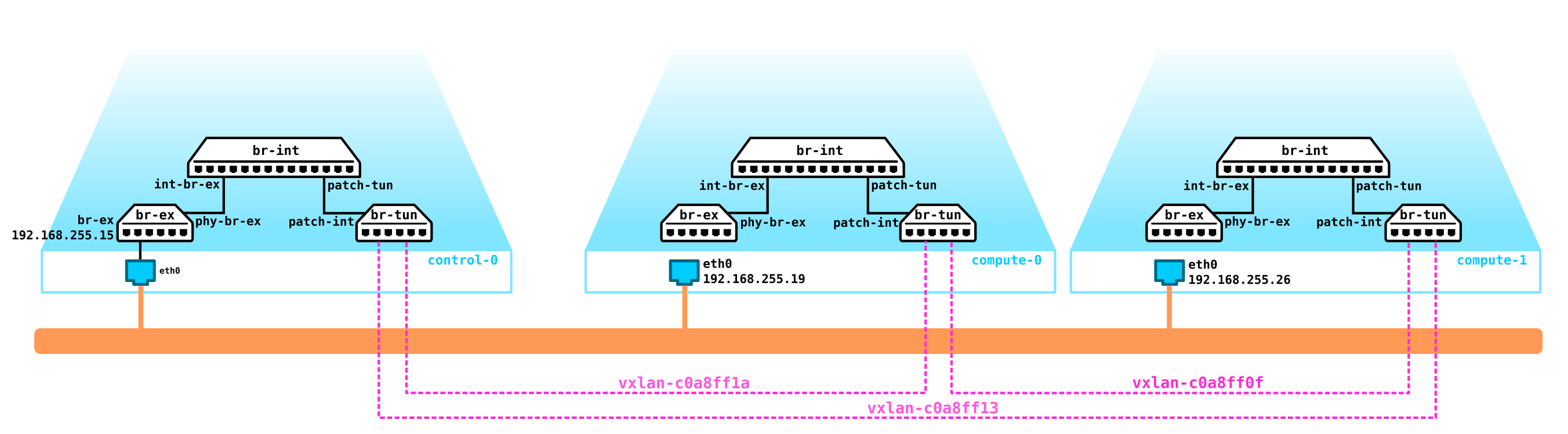
Nous avons deux machines virtuelles sur chaque ordinateur. Voyons comment tout est inclus avec compute-0.
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh list
Id Name State
----------------------------------------------------
1 instance-00000001 running
3 instance-00000003 running
[heat-admin@overcloud-novacompute-0 ~]$ La machine n'a qu'une seule interface virtuelle - tap95d96a75-a0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
Cette interface regarde le pont Linux:
[heat-admin@overcloud-novacompute-0 ~]$ sudo brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242904c92a8 no
qbr5bd37136-47 8000.5e4e05841423 no qvb5bd37136-47
tap5bd37136-47
qbr95d96a75-a0 8000.de076cb850f6 no qvb95d96a75-a0
tap95d96a75-a0
[heat-admin@overcloud-novacompute-0 ~]$ Comme vous pouvez le voir dans la sortie, il n'y a que deux interfaces dans la brigade - tap95d96a75-a0 et qvb95d96a75-a0.
Il vaut la peine deComme vous le comprenez, si nous avons un port qvb95d96a75-a0 dans la brigade, qui est une vEth paire, alors où est son homologue, qui devrait logiquement être appelé qvo95d96a75-a0. Voyons quels sont les ports sur l'OVS.
s'attarder un peu sur les types de périphériques réseau virtuels dans OpenStack: vtap - une interface virtuelle connectée à une instance (VM)
qbr - Linux bridge
qvb and qvo - vEth pair connecté à un pont Linux et Open vSwitch bridge
br-int, br-tun, br-vlan - Open vSwitch bridges
patch-, int-br-, phy-br- - Open vSwitch patch-interfaces reliant les ponts
qg, qr, ha, fg, sg - Ouvrez les ports vSwitch utilisés par les périphériques virtuels pour se connecter à OVS
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:526 missed:91
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
qvo5bd37136-47 6/6: (system)
qvo95d96a75-a0 3/5: (system)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$ Comme nous pouvons le voir, le port est en br-int. Br-int agit comme un commutateur qui termine les ports des machines virtuelles. En plus de qvo95d96a75-a0, la sortie affiche le port qvo5bd37136-47. Il s'agit du port vers la deuxième machine virtuelle. En conséquence, notre schéma ressemble maintenant à ceci: La

question qui devrait immédiatement intéresser un lecteur attentif - pourquoi le pont Linux entre le port de la machine virtuelle et le port OVS? Le fait est que les groupes de sécurité sont utilisés pour protéger la machine, qui ne sont rien de plus que des iptables. OVS ne fonctionne pas avec les iptables, donc cette "béquille" a été inventée. Cependant, il survit au sien - il est remplacé par conntrack dans les nouvelles versions.
Autrement dit, finalement, le schéma ressemble à ceci:

Deux machines sur un hyperviseur dans un réseau L2
Étant donné que ces deux machines virtuelles sont dans le même réseau L2 et sur le même hyperviseur, le trafic entre elles passera logiquement localement via br-int, puisque les deux machines seront dans le même VLAN:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000003
Interface Type Source Model MAC
-------------------------------------------------------
tap5bd37136-47 bridge qbr5bd37136-47 virtio fa:16:3e:83:ad:a4
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int
port VLAN MAC Age
6 1 fa:16:3e:83:ad:a4 0
3 1 fa:16:3e:44:98:20 0
[heat-admin@overcloud-novacompute-0 ~]$ Deux machines sur différents hyperviseurs dans le même réseau L2
Voyons maintenant comment le trafic passe entre deux machines dans le même réseau L2, mais situées sur des hyperviseurs différents. Pour être honnête, rien ne changera beaucoup, seul le trafic entre les hyperviseurs passera par le tunnel vxlan. Voyons un exemple.
Les adresses des machines virtuelles entre lesquelles nous surveillerons le trafic:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000002
Interface Type Source Model MAC
-------------------------------------------------------
tape7e23f1b-07 bridge qbre7e23f1b-07 virtio fa:16:3e:72:ad:53
[heat-admin@overcloud-novacompute-1 ~]$ Nous regardons la table de transfert dans br-int à compute-0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:72:ad:53
2 1 fa:16:3e:72:ad:53 1
[heat-admin@overcloud-novacompute-0 ~]Le trafic devrait aller au port 2 - voyons ce qu'est ce port:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$Ceci est patch-tun - c'est-à-dire l'interface avec br-tun. Voyons ce qui arrive au paquet sur br-tun:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:72:ad:53
cookie=0x8759a56536b67a8e, duration=1387.959s, table=20, n_packets=1460, n_bytes=138880, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:72:ad:53 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-novacompute-0 ~]$ Le paquet est emballé dans VxLAN et envoyé au port 2. Voyons où le port 2 mène:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:b2:d1:f8:21:96:66
2(vxlan-c0a8ff1a): addr:be:64:1f:75:78:a7
3(vxlan-c0a8ff0f): addr:76:6f:b9:3c:3f:1c
LOCAL(br-tun): addr:a2:5b:6d:4f:94:47
[heat-admin@overcloud-novacompute-0 ~]$Ceci est un tunnel vxlan sur compute-1:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl dpif/show | egrep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$Accédez à compute-1 et voyez ce qui se passe ensuite avec le package:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:44:98:20
2 1 fa:16:3e:44:98:20 1
[heat-admin@overcloud-novacompute-1 ~]$ Le Mac est dans la table de transfert br-int sur compute-1, et comme vous pouvez le voir dans la sortie ci-dessus, il est visible via le port 2, qui est les ports vers br-tun:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46Eh bien, alors nous regardons qu'il y a un mac de destination dans br-int sur compute-1:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:72:ad:53
3 1 fa:16:3e:72:ad:53 0
[heat-admin@overcloud-novacompute-1 ~]$ Autrement dit, le paquet reçu volera vers le port 3, derrière lequel la machine virtuelle instance-00000003 se trouve déjà.
La beauté du déploiement d'Openstack pour l'apprentissage sur une infrastructure virtuelle est que nous pouvons facilement attraper le trafic entre les hyperviseurs et voir ce qui lui arrive. C'est ce que nous allons faire maintenant, exécutez tcpdump sur le port vnet vers compute-0:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet3
tcpdump: listening on vnet3, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:39:04.583459 IP (tos 0x0, ttl 64, id 16868, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.39096 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 8012, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.1.88: ICMP echo request, id 5634, seq 16, length 64
04:39:04.584449 IP (tos 0x0, ttl 64, id 35181, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.speedtrace-disc > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 59124, offset 0, flags [none], proto ICMP (1), length 84)
10.0.1.88 > 10.0.1.85: ICMP echo reply, id 5634, seq 16, length 64
*****************omitted*******************La première ligne montre que le correctif avec l'adresse 10.0.1.85 va à l'adresse 10.0.1.88 (trafic ICMP), et il est enveloppé dans un paquet VxLAN avec vni 22 et le paquet va de l'hôte 192.168.255.19 (compute-0) à l'hôte 192.168.255.26 ( compute-1). Nous pouvons vérifier que le VNI correspond à celui spécifié dans les ovs.
Revenons à cette ligne actions = load: 0-> NXM_OF_VLAN_TCI [], load: 0x16-> NXM_NX_TUN_ID [], output: 2. 0x16 est un vni hexadécimal. Traduisons ce nombre dans le 10e système:
16 = 6*16^0+1*16^1 = 6+16 = 22Autrement dit, vni correspond à la réalité.
La deuxième ligne montre le trafic de retour, eh bien, cela n'a aucun sens de l'expliquer là-bas, et donc tout est clair.
Deux machines sur des réseaux différents (routage entre réseaux)
Le dernier cas pour aujourd'hui est le routage entre les réseaux au sein d'un projet à l'aide d'un routeur virtuel. Nous considérons un cas sans DVR (nous le considérerons dans un autre article), donc le routage se produit sur le nœud du réseau. Dans notre cas, le nœud de réseau n'est pas une entité distincte et est situé sur le nœud de contrôle.
Tout d'abord, voyons que le routage fonctionne:
$ ping 10.0.2.8
PING 10.0.2.8 (10.0.2.8): 56 data bytes
64 bytes from 10.0.2.8: seq=0 ttl=63 time=7.727 ms
64 bytes from 10.0.2.8: seq=1 ttl=63 time=3.832 ms
^C
--- 10.0.2.8 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 3.832/5.779/7.727 msPuisque dans ce cas le paquet doit aller à la passerelle et y être acheminé, nous devons trouver l'adresse MAC de la passerelle, pour laquelle nous regarderons la table ARP dans l'instance:
$ arp
host-10-0-1-254.openstacklocal (10.0.1.254) at fa:16:3e:c4:64:70 [ether] on eth0
host-10-0-1-1.openstacklocal (10.0.1.1) at fa:16:3e:e6:2c:5c [ether] on eth0
host-10-0-1-90.openstacklocal (10.0.1.90) at fa:16:3e:83:ad:a4 [ether] on eth0
host-10-0-1-88.openstacklocal (10.0.1.88) at fa:16:3e:72:ad:53 [ether] on eth0Voyons maintenant où le trafic doit être envoyé avec la destination (10.0.1.254) fa: 16: 3e: c4: 64: 70:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:c4:64:70
2 1 fa:16:3e:c4:64:70 0
[heat-admin@overcloud-novacompute-0 ~]$ Nous regardons où mène le port 2:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$ Tout est logique, le trafic va à br-tun. Voyons dans quel tunnel vxlan il sera enveloppé:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:c4:64:70
cookie=0x8759a56536b67a8e, duration=3514.566s, table=20, n_packets=3368, n_bytes=317072, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:c4:64:70 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:3
[heat-admin@overcloud-novacompute-0 ~]$ Le troisième port est le tunnel vxlan:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$ Qui regarde le nœud de contrôle:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ Le trafic a atteint le nœud de contrôle, nous devons donc y aller et voir comment le routage se déroulera.
Comme vous vous en souvenez, le nœud de contrôle à l'intérieur ressemblait exactement au nœud de calcul - les trois mêmes ponts, seul br-ex avait un port physique à travers lequel le nœud pouvait envoyer du trafic à l'extérieur. La création de l'instance a changé la configuration sur les nœuds de calcul - le pont Linux, les iptables et les interfaces ont été ajoutés aux nœuds. La création de réseaux et d'un routeur virtuel a également laissé sa marque sur la configuration du nœud de contrôle.
Ainsi, il est évident que l'adresse de pavot de passerelle doit être dans la table de transfert br-int sur le nœud de contrôle. Vérifions qu'il est là et où il se trouve:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:c4:64:70
5 1 fa:16:3e:c4:64:70 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ Mac est visible depuis le port qr-0c52b15f-8f. Si nous revenons à la liste des ports virtuels dans Openstack, alors ce type de port est utilisé pour connecter divers périphériques virtuels à OVS. Pour être plus précis, qr est un port vers le routeur virtuel, qui est représenté comme un espace de noms.
Voyons quels sont les espaces de noms sur le serveur:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ Jusqu'à trois exemplaires. Mais à en juger par les noms, vous pouvez deviner le but de chacun d'eux. Nous reviendrons sur les instances avec les ID 0 et 1 plus tard, maintenant nous sommes intéressés par l'espace de noms qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ip route
10.0.1.0/24 dev qr-0c52b15f-8f proto kernel scope link src 10.0.1.254
10.0.2.0/24 dev qr-92fa49b5-54 proto kernel scope link src 10.0.2.254
[heat-admin@overcloud-controller-0 ~]$ Cet espace de noms a deux espaces internes que nous avons créés précédemment. Les deux ports virtuels sont ajoutés à br-int. Vérifions l'adresse de masse du port qr-0c52b15f-8f, car le trafic, à en juger par l'adresse du pavot de destination, allait exactement vers cette interface.
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ifconfig qr-0c52b15f-8f
qr-0c52b15f-8f: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.0.1.254 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fec4:6470 prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:c4:64:70 txqueuelen 1000 (Ethernet)
RX packets 5356 bytes 427305 (417.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5195 bytes 490603 (479.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$ Autrement dit, dans ce cas, tout fonctionne selon les lois du routage standard. Étant donné que le trafic est destiné à l'hôte 10.0.2.8, il doit sortir via la deuxième interface qr-92fa49b5-54 et passer par le tunnel vxlan jusqu'au nœud de calcul:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe arp
Address HWtype HWaddress Flags Mask Iface
10.0.1.88 ether fa:16:3e:72:ad:53 C qr-0c52b15f-8f
10.0.1.90 ether fa:16:3e:83:ad:a4 C qr-0c52b15f-8f
10.0.2.8 ether fa:16:3e:6c:ad:9c C qr-92fa49b5-54
10.0.2.42 ether fa:16:3e:f5:0b:29 C qr-92fa49b5-54
10.0.1.85 ether fa:16:3e:44:98:20 C qr-0c52b15f-8f
[heat-admin@overcloud-controller-0 ~]$ Tout est logique, pas de surprises. Nous regardons d'où l'adresse coquelicot de l'hôte 10.0.2.8 dans br-int est visible:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
2 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ Comme prévu, le trafic va à br-tun, voyons dans quel tunnel le trafic va ensuite:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:6c:ad:9c
cookie=0x2ab04bf27114410e, duration=5346.829s, table=20, n_packets=5248, n_bytes=498512, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0002/0x0fff,dl_dst=fa:16:3e:6c:ad:9c actions=load:0->NXM_OF_VLAN_TCI[],load:0x63->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ Le trafic entre dans le tunnel pour calculer-1. Eh bien, sur compute-1, tout est simple - de br-tun le paquet va à br-int et de là à l'interface de la machine virtuelle:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
4 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46
[heat-admin@overcloud-novacompute-1 ~]$ Vérifions que c'est bien la bonne interface:
[heat-admin@overcloud-novacompute-1 ~]$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02429c001e1c no
qbr3210e8ec-c0 8000.ea27f45358be no qvb3210e8ec-c0
tap3210e8ec-c0
qbre7e23f1b-07 8000.b26ac0eded8a no qvbe7e23f1b-07
tape7e23f1b-07
[heat-admin@overcloud-novacompute-1 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000004
Interface Type Source Model MAC
-------------------------------------------------------
tap3210e8ec-c0 bridge qbr3210e8ec-c0 virtio fa:16:3e:6c:ad:9c
[heat-admin@overcloud-novacompute-1 ~]$En fait, nous avons parcouru tout le paquet. Je pense que vous avez remarqué que le trafic passait par différents tunnels vxlan et sortait avec différents VNI. Voyons de quel type de VNI il s'agit, puis collectons un vidage sur le port de contrôle du nœud et assurez-vous que le trafic se déroule exactement comme décrit ci-dessus.
Ainsi, le tunnel pour calculer-0 a les actions suivantes = charge: 0-> NXM_OF_VLAN_TCI [], charge: 0x16-> NXM_NX_TUN_ID [], sortie: 3. Conversion de 0x16 en notation décimale:
0x16 = 6*16^0+1*16^1 = 6+16 = 22Le tunnel pour calculer-1 a le VNI suivant: actions = charge: 0-> NXM_OF_VLAN_TCI [], charge: 0x63-> NXM_NX_TUN_ID [], sortie: 2. Conversion de 0x63 en notation décimale:
0x63 = 3*16^0+6*16^1 = 3+96 = 99Eh bien, voyons maintenant la décharge:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet4
tcpdump: listening on vnet4, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:35:18.709949 IP (tos 0x0, ttl 64, id 48650, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.41591 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.710159 IP (tos 0x0, ttl 64, id 23360, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 63, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.711292 IP (tos 0x0, ttl 64, id 43596, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.42588 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 64, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
04:35:18.711531 IP (tos 0x0, ttl 64, id 8555, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 63, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
*****************omitted*******************Le premier paquet est un paquet vxlan de l'hôte 192.168.255.19 (calcul-0) à l'hôte 192.168.255.15 (contrôle-1) avec vni 22, à l'intérieur duquel un paquet ICMP est emballé de l'hôte 10.0.1.85 à l'hôte 10.0.2.8. Comme nous l'avons calculé ci-dessus, vni correspond à ce que nous avons vu dans les sorties.
Le deuxième paquet est un paquet vxlan de l'hôte 192.168.255.15 (contrôle-1) à l'hôte 192.168.255.26 (calcul-1) avec vni 99, à l'intérieur duquel un paquet ICMP est emballé de l'hôte 10.0.1.85 à l'hôte 10.0.2.8. Comme nous l'avons calculé ci-dessus, vni correspond à ce que nous avons vu dans les sorties.
Les deux paquets suivants sont le trafic de retour de 10.0.2.8 et non de 10.0.1.85.
Autrement dit, à la fin, nous avons le schéma de nœud de contrôle suivant:

Comme tout? Nous avons oublié deux espaces de noms:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ Comme nous avons parlé de l'architecture de la plate-forme cloud, ce serait bien si les machines reçoivent automatiquement les adresses d'un serveur DHCP. Ce sont deux serveurs DHCP pour nos deux réseaux 10.0.1.0/24 et 10.0.2.0/24.
Vérifions qu'il en est bien ainsi. Cet espace de noms contient une seule adresse - 10.0.1.1 - l'adresse du serveur DHCP lui-même, et il est également inclus dans br-int:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 ifconfig
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 1 bytes 28 (28.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1 bytes 28 (28.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
tapca25a97e-64: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.0.1.1 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fee6:2c5c prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:e6:2c:5c txqueuelen 1000 (Ethernet)
RX packets 129 bytes 9372 (9.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 49 bytes 6154 (6.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Voyons si les processus contenant qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 dans leurs noms sur le nœud de contrôle:
[heat-admin@overcloud-controller-0 ~]$ ps -aux | egrep qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
root 640420 0.0 0.0 4220 348 ? Ss 11:31 0:00 dumb-init --single-child -- ip netns exec qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 /usr/sbin/dnsmasq -k --no-hosts --no-resolv --pid-file=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/pid --dhcp-hostsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/host --addn-hosts=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/addn_hosts --dhcp-optsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/opts --dhcp-leasefile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases --dhcp-match=set:ipxe,175 --local-service --bind-dynamic --dhcp-range=set:subnet-335552dd-b35b-456b-9df0-5aac36a3ca13,10.0.2.0,static,255.255.255.0,86400s --dhcp-option-force=option:mtu,1450 --dhcp-lease-max=256 --conf-file= --domain=openstacklocal
heat-ad+ 951620 0.0 0.0 112944 980 pts/0 S+ 18:50 0:00 grep -E --color=auto qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
[heat-admin@overcloud-controller-0 ~]$ Il existe un tel processus, et sur la base des informations présentées dans la sortie ci-dessus, nous pouvons, par exemple, voir ce que nous avons en loyer pour le moment:
[heat-admin@overcloud-controller-0 ~]$ cat /var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases
1597492111 fa:16:3e:6c:ad:9c 10.0.2.8 host-10-0-2-8 01:fa:16:3e:6c:ad:9c
1597491115 fa:16:3e:76:c2:11 10.0.2.1 host-10-0-2-1 *
[heat-admin@overcloud-controller-0 ~]$En conséquence, nous obtenons un tel ensemble de services sur le nœud de contrôle:

Eh bien, gardez à l'esprit - ce n'est que - 4 machines, 2 réseaux internes et un routeur virtuel ... Nous n'avons pas de réseaux externes ici maintenant, des tas de projets différents, chacun avec ses propres réseaux (se chevauchant ), et nous avons désactivé le routeur distribué, mais à la fin il n'y avait qu'un seul nœud de contrôle dans le banc de test (pour la tolérance aux pannes, il doit y avoir un quorum de trois nœuds). Il est logique que dans le commerce, tout soit "un peu" plus compliqué, mais dans cet exemple simple, nous comprenons comment cela devrait fonctionner - si vous avez 3 ou 300 espaces de noms, bien sûr, c'est important, mais du point de vue du fonctionnement de toute la structure, rien ne changera beaucoup ... mais pour l'instant ne collez pas une sorte de fournisseur SDN. Mais c'est une histoire complètement différente.
J'espère que c'était intéressant. S'il y a bien des commentaires / ajouts, ou quelque part où j'ai menti ouvertement (je suis un être humain et mon opinion sera toujours subjective) - écrivez ce qui doit être corrigé / ajouté - nous corrigerons / ajouterons tout.
En conclusion, je voudrais dire quelques mots sur la comparaison d'Openstack (à la fois vanille et fournisseur) avec une solution cloud de VMWare - trop souvent, on me pose cette question depuis quelques années et, pour être honnête, j'en ai marre, mais quand même. À mon avis, ces deux solutions sont très difficiles à comparer, mais nous pouvons dire sans équivoque qu'il y a des inconvénients dans les deux solutions, et lors du choix d'une solution, il faut peser le pour et le contre.
Si OpenStack est une solution communautaire, alors VMWare a le droit de ne faire que ce qu'il veut (lire - ce qui est rentable pour lui) et c'est logique - car c'est une entreprise commerciale qui est habituée à gagner de l'argent avec ses clients. Mais il y a un gros et gros MAIS - vous pouvez quitter OpenStack de Nokia, par exemple, et passer à une solution de, par exemple, Juniper (Contrail Cloud), mais vous pourrez difficilement quitter VMWare. Pour moi, ces deux solutions ressemblent à ceci - Openstack (fournisseur) est une simple cage dans laquelle vous êtes mis, mais vous avez la clé et vous pouvez quitter à tout moment. VMWare est une cage dorée, le propriétaire a la clé de la cage et cela vous coûtera cher.
Je ne fais campagne ni pour le premier produit ni pour le second - vous choisissez ce dont vous avez besoin. Mais si j'avais un tel choix, je choisirais les deux solutions - VMWare pour le cloud informatique (faibles charges, gestion pratique), OpenStack de certains fournisseurs (Nokia et Juniper fournissent de très belles solutions clé en main) - pour les clouds Telecom. Je n'utiliserais pas Openstack pour de l'informatique pure - c'est comme tirer sur un moineau avec un canon, mais je ne vois aucune contre-indication à son utilisation, à l'exception de la redondance. Cependant, utiliser VMWare dans les télécommunications - comment transporter des gravats sur un Ford Raptor - est beau de l'extérieur, mais le conducteur doit effectuer 10 trajets au lieu d'un.
À mon avis, le plus gros inconvénient de VMWare est sa fermeture complète - l'entreprise ne vous donnera aucune information sur son fonctionnement, par exemple, vSAN ou ce qui se trouve dans le noyau de l'hyperviseur - ce n'est tout simplement pas rentable pour cela - c'est-à-dire que vous ne deviendrez jamais un expert de VMWare - sans le support du fournisseur, vous êtes condamné (très souvent je rencontre des experts VMWare qui sont déconcertés par des questions banales). Pour moi, VMWare achète une voiture avec un capot verrouillé - oui, vous avez peut-être des spécialistes qui peuvent changer la courroie de distribution, mais seul celui qui vous a vendu cette solution peut ouvrir le capot. Personnellement, je n'aime pas les solutions dans lesquelles je ne peux pas m'intégrer. Vous direz que vous n'aurez peut-être pas à passer sous le capot. Oui, c'est possible, mais je vous regarderai lorsque vous aurez besoin d'assembler une grande fonction dans le cloud à partir de 20-30 machines virtuelles, 40-50 réseaux,dont la moitié veut aller à l'extérieur et l'autre moitié demande une accélération SR-IOV, sinon vous aurez besoin de quelques douzaines de plus de ces machines - sinon les performances ne seront pas suffisantes.
Il y a d'autres points de vue, c'est donc à vous de décider quoi choisir et, surtout, vous êtes responsable de votre choix plus tard. Ce n'est que mon avis - une personne qui a vu et touché au moins 4 produits - Nokia, Juniper, Red Hat et VMWare. Autrement dit, j'ai quelque chose à comparer.