
Une requête exécutée en parallèle peut-elle utiliser moins de CPU et s'exécuter plus rapidement qu'une requête exécutée séquentiellement?
Oui! Pour la démonstration, j'utiliserai deux tables avec un type de colonne
integer.

Remarque - Le script TSQL sous forme de texte se trouve à la fin de l'article.
Générer des données de démonstration
Nous
#BuildIntinsérons 5000 entiers aléatoires dans la table (pour que vous ayez les mêmes valeurs que les miennes, j'utilise RAND avec seed et une boucle WHILE). Insérez 5 000 000 d'enregistrements dans la

table
#Probe.

Plan séquentiel
Écrivons maintenant une requête pour compter le nombre de correspondances de valeurs dans ces tables. Nous utilisons l'indication MAXDOP 1 pour nous assurer que la requête ne sera pas exécutée en parallèle.
Son plan d'exécution et ses statistiques sont les suivants:

Cette requête prend 891 ms et utilise 890 ms de CPU.
Plan parallèle
Maintenant, exécutons la même requête avec MAXDOP 2. La

requête prend 221 ms et utilise 436 ms de CPU. Le temps d'exécution a diminué quatre fois et l'utilisation du processeur a été divisée par deux!
Bitmap magique
La raison pour laquelle l'exécution de requêtes parallèles est beaucoup plus efficace est à cause de l'opérateur Bitmap.
Examinons de près le plan d'exécution réel de la requête parallèle:

Et comparons-le avec le plan séquentiel:

Le principe de l'opérateur Bitmap est bien documenté, donc je ne fournirai ici qu'une brève description avec des liens vers la documentation à la fin de l'article.
Joindre par hachage
La jointure par hachage se fait en deux étapes:
- Le stade de «construction» (anglais - construction). Toutes les lignes de l'une des tables sont lues et une table de hachage est créée pour les clés de jointure.
- L'étape de la «vérification» (anglais - sonde). Toutes les lignes de la deuxième table sont lues, le hachage est calculé par la même fonction de hachage en utilisant les mêmes clés de connexion et un compartiment correspondant est trouvé dans la table de hachage.
Naturellement, en raison d'éventuelles collisions de hachage, il est encore nécessaire de comparer les valeurs réelles des clés.
Note du traducteur: pour plus de détails sur le fonctionnement de la jointure par hachage, consultez l'article Visualiser et gérer la jointure par hachage par correspondance
Bitmap dans les plans séquentiels
Beaucoup de gens ne savent pas que Hash Match, même dans les requêtes séquentielles, utilise toujours un bitmap. Mais dans un tel plan, vous ne le verrez pas explicitement, car il fait partie de l'implémentation interne de l'opérateur Hash Match.
HASH JOIN au stade de la construction et de la création d'une table de hachage définit un (ou plusieurs) bits dans le bitmap. Vous pouvez ensuite utiliser le bitmap pour faire correspondre efficacement les valeurs de hachage sans avoir à accéder à la table de hachage.
Avec un plan séquentiel, un hachage est calculé pour chaque ligne de la deuxième table et vérifié par rapport au bitmap. Si les bits correspondants dans le bitmap sont définis, il peut y avoir une correspondance dans la table de hachage, donc la table de hachage est vérifiée ensuite. Inversement, si aucun des bits correspondant à la valeur de hachage n'est défini, nous pouvons être sûrs qu'il n'y a pas de correspondance dans la table de hachage, et nous pouvons immédiatement ignorer la chaîne vérifiée.
Le coût relativement faible de création d'un bitmap est compensé par le gain de temps en ne vérifiant pas les chaînes pour lesquelles il n'y a pas de correspondance exacte dans la table de hachage. Cette optimisation est souvent efficace car la vérification du bitmap est beaucoup plus rapide que la vérification de la table de hachage.
Bitmap dans des plans parallèles
Dans un plan parallèle, le bitmap est affiché comme une instruction Bitmap distincte.
Lors du passage de l'étape de construction à l'étape de vérification, le bitmap est passé à l'opérateur HASH MATCH depuis le côté de la deuxième table (sonde). Au minimum, le bitmap est passé au côté sonde avant le JOIN et l'opérateur d'échange (parallélisme).
Ici, le bitmap peut exclure les chaînes qui ne satisfont pas à la condition de jointure avant d'être passées à l'instruction d'échange.
Bien sûr, il n'y a pas d'instructions d'échange dans les plans séquentiels, donc déplacer le bitmap en dehors de HASH JOIN ne fournit aucun avantage supplémentaire par rapport au bitmap "incorporé" dans l'instruction HASH MATCH.
Dans certaines situations (mais uniquement dans un plan parallèle), l'optimiseur peut déplacer le Bitmap plus bas dans le plan du côté sonde de la connexion.
L'idée ici est que plus tôt les lignes sont filtrées, moins il faudra de temps système pour déplacer les données entre les instructions, et il peut même être possible d'éliminer certaines opérations.
En outre, l'optimiseur essaie généralement de placer des filtres simples aussi près que possible des feuilles: il est plus efficace de filtrer les lignes le plus tôt possible. Cependant, je dois mentionner que le bitmap dont nous parlons est ajouté une fois l'optimisation terminée.
La décision d'ajouter ce type (statique) de bitmap au plan après l'optimisation est prise en fonction de la sélectivité attendue du filtre (par conséquent, des statistiques précises sont importantes).
Déplacer un filtre bitmap
Revenons au concept de déplacement du filtre bitmap du côté sonde de la connexion.
Dans de nombreux cas, le filtre bitmap peut être déplacé vers une instruction Scan ou Seek. Lorsque cela se produit, le prédicat de plan ressemble à ceci:

Il s'applique à toutes les lignes qui correspondent au prédicat de recherche (pour la recherche d'index) ou à toutes les lignes pour l'analyse d'index ou l'analyse de table. Par exemple, la capture d'écran ci-dessus montre un filtre bitmap appliqué à l'analyse de table pour une table de tas.
Aller plus loin ...
Si un filtre bitmap est construit sur une seule colonne ou expression de type integer ou bigint, et est appliqué à une seule colonne de type integer ou bigint, alors l'opérateur Bitmap peut être déplacé encore plus loin sur la route, encore plus loin que les opérateurs Seek ou Scan.
Le prédicat apparaîtra toujours dans les instructions Scan ou Seek comme dans l'exemple ci-dessus, mais il sera désormais marqué avec l'attribut INROW, ce qui signifie que le filtre est déplacé vers le moteur de stockage et appliqué aux lignes lors de leur lecture.
Avec cette optimisation, les lignes sont filtrées avant que le processeur de requêtes ne voie la ligne. Seules les chaînes qui correspondent à HASH MATCH JOIN sont envoyées à partir du moteur de stockage.
Les conditions dans lesquelles cette optimisation est appliquée dépendent de la version de SQL Server. Par exemple, dans SQL Server 2005, en plus des conditions énoncées précédemment, la colonne de sonde doit être définie comme NOT NULL. Cette limitation a été assouplie dans SQL Server 2008.
Vous vous demandez peut-être comment les optimisations INROW affectent les performances. Le fait de déplacer l'opérateur aussi près que possible de Seek ou Scan sera-t-il aussi efficace que le filtrage dans le moteur de stockage? Je répondrai à cette question intéressante dans d'autres articles. Et ici, nous examinerons également MERGE JOIN et NESTED LOOP JOIN.
Autres options JOIN
Utiliser des boucles imbriquées sans index est une mauvaise idée. Nous devons analyser complètement l'un des tableaux pour chaque ligne de l'autre tableau - un total de 5 milliards de comparaisons. Cette demande prendra probablement très longtemps.
Fusionner la jointure
Ce type de jointure physique nécessite une entrée triée, donc un MERGE JOIN forcé entraîne la présence d'un tri avant lui. Le plan séquentiel ressemble à ceci:
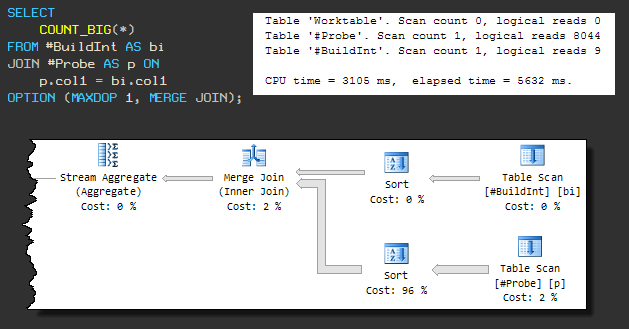
La requête utilise maintenant 3105 ms de CPU et le temps d'exécution total est de 5632 ms .
L'augmentation du temps d'exécution global est due au fait que l'une des opérations de tri utilise tempdb (même si SQL Server dispose de suffisamment de mémoire pour le tri).
La fuite dans tempdb se produit car l'algorithme d'allocation de mémoire par défaut ne pré-réserve pas suffisamment de mémoire. Tant que nous n'y prêtons pas attention, il est clair que la requête ne se terminera pas en moins de 3105 ms.
Continuons à forcer le MERGE JOIN, mais autorisons le parallélisme (MAXDOP 2):

Comme dans le HASH JOIN parallèle que nous avons vu précédemment, le filtre bitmap est situé de l'autre côté de MERGE JOIN plus près du Table Scan et est appliqué à l'aide de l'optimisation INROW.
Avec 468 ms de CPU et 240 ms de temps écoulé, un MERGE JOIN avec des tris supplémentaires est presque aussi rapide qu'un HASH JOIN parallèle ( 436 ms / 221 ms ).
Mais le parallèle MERGE JOIN a un inconvénient: il réserve 330 Ko de mémoire en fonction du nombre attendu de lignes à trier. Étant donné que ces types de bitmaps sont utilisés après l'optimisation des coûts, il n'y a pas d'ajustement à l'estimation, même si seulement 2488 lignes passent par le tri inférieur.
Une instruction Bitmap peut apparaître dans un plan avec un MERGE JOIN uniquement avec une instruction de blocage ultérieure (par exemple, Sort). L'opérateur de blocage doit recevoir toutes les valeurs requises en entrée avant de générer la première ligne à sortir. Cela garantit que le bitmap est complètement plein avant que les lignes de la table JOIN ne soient lues et vérifiées.
Il n'est pas nécessaire que l'instruction de blocage soit de l'autre côté de MERGE JOIN, mais il est important de quel côté le bitmap est utilisé.
Avec indices
Si des indices appropriés sont disponibles, la situation est différente. La distribution de nos données "aléatoires" est telle qu'un
#BuildIntindex unique peut être créé sur la table . Et la table #Probecontient des doublons, vous devez donc vous débrouiller avec un index non unique:

ce changement n'affectera pas le HASH JOIN (à la fois en série et en parallèle). HASH JOIN ne peut pas utiliser d'index, les plans et les performances restent donc les mêmes.
Fusionner la jointure
MERGE JOIN n'a plus besoin d'effectuer une opération de jointure plusieurs-à-plusieurs et ne nécessite plus d'opérateur de tri sur l'entrée.
L'absence d'un opérateur de tri bloquant signifie que Bitmap ne peut pas être utilisé.
En conséquence, nous voyons un plan séquentiel, quel que soit le paramètre MAXDOP, et les performances sont pires que le plan parallèle avant d'ajouter les index: 702 ms CPU et 704 ms temps écoulé:

Cependant, il y a une amélioration notable par rapport au plan séquentiel MERGE JOIN d'origine ( 3105 ms / 5632 ms ). Cela est dû à l'élimination du tri et à de meilleures performances de jointure un-à-plusieurs.
Jointure de boucles imbriquées
Comme vous vous en doutez, NESTED LOOP fonctionne nettement mieux. Semblable à MERGE JOIN, l'optimiseur décide de ne pas utiliser la concurrence:

c'est le plan le plus efficace à ce jour - seulement 16 ms de processeur et 16 ms de temps passé.
Bien entendu, cela suppose que les données nécessaires pour terminer la demande sont déjà en mémoire. Sinon, chaque recherche dans la table de sonde générera des E / S aléatoires.
Sur mon ordinateur portable, les performances du cache froid NESTED LOOP ont pris 78 ms de processeur et 2152 ms, temps écoulé. Dans les mêmes circonstances, MERGE JOIN a utilisé 686 ms de processeur et 1471 ms . HASH JOIN - 391 ms CPU et905 ms .
MERGE JOIN et HASH JOIN bénéficient d'E / S importantes, éventuellement séquentielles, utilisant la lecture anticipée.
Ressources additionnelles
Parallel Hash Join (Craig Freedman)
Query Execution Bitmap Filters (SQL Server Query Processing Team)
Bitmaps in Microsoft SQL Server 2000 (MSDN article)
Interpreting Execution Plans Containing Bitmap Filters (SQL Server Documentation)
Understanding Hash Joins (SQL Server Documentation)
Script de test
USE tempdb;
GO
CREATE TABLE #BuildInt
(
col1 INTEGER NOT NULL
);
GO
CREATE TABLE #Probe
(
col1 INTEGER NOT NULL
);
GO
-- Load 5,000 rows into the build table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #BuildInt
(col1)
VALUES
(CONVERT(INTEGER, RAND(1) * 2147483647));
WHILE @I < 5000
BEGIN
INSERT #BuildInt
(col1)
VALUES
(RAND() * 2147483647);
SET @I += 1;
END;
-- Load 5,000,000 rows into the probe table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND(2) * 2147483647));
BEGIN TRANSACTION;
WHILE @I < 5000000
BEGIN
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND() * 2147483647));
SET @I += 1;
IF @I % 25 = 0
BEGIN
COMMIT TRANSACTION;
BEGIN TRANSACTION;
END;
END;
COMMIT TRANSACTION;
GO
-- Demos
SET STATISTICS XML OFF;
SET STATISTICS IO, TIME ON;
-- Serial
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1);
-- Parallel
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 2);
SET STATISTICS IO, TIME OFF;
-- Indexes
CREATE UNIQUE CLUSTERED INDEX cuq ON #BuildInt (col1);
CREATE CLUSTERED INDEX cx ON #Probe (col1);
-- Vary the query hints to explore plan shapes
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1, MERGE JOIN);
GO
DROP TABLE #BuildInt, #Probe;
Lire la suite: