Je continue mon histoire sur la façon de se faire des amis Exchange et ELK (commencez ici ). Permettez-moi de vous rappeler que cette combinaison est capable de gérer un très grand nombre de journaux sans hésitation. Cette fois, nous allons parler de la manière de faire fonctionner Exchange avec les composants Logstash et Kibana.
Logstash dans la pile ELK est utilisé pour traiter intelligemment les journaux et les préparer pour le placement dans Elastic sous la forme de documents, sur la base desquels il est pratique de créer diverses visualisations dans Kibana.
Installation
Se compose de deux étapes:
- Installation et configuration du package OpenJDK.
- Installation et configuration du package Logstash.
Installation et configuration du
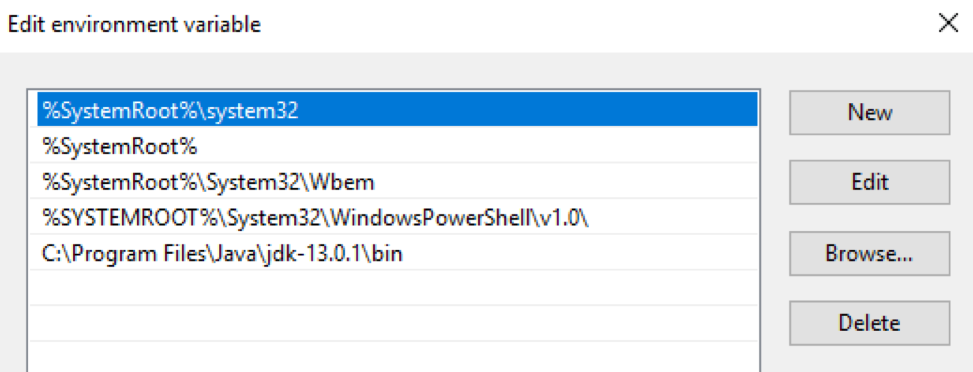
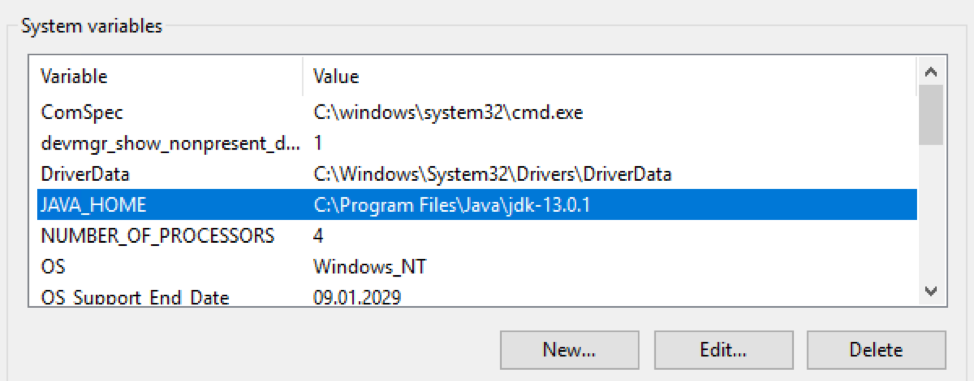
package OpenJDK Le package OpenJDK doit être téléchargé et décompressé dans un répertoire spécifique. Ensuite, le chemin vers ce répertoire doit être entré dans les variables $ env: Path et $ env: JAVA_HOME du système d'exploitation Windows:
Vérifiez la version Java:
PS C:\> java -version
openjdk version "13.0.1" 2019-10-15
OpenJDK Runtime Environment (build 13.0.1+9)
OpenJDK 64-Bit Server VM (build 13.0.1+9, mixed mode, sharing)
Installation et configuration du package Logstash
Téléchargez le fichier d'archive avec la distribution Logstash à partir d'ici . L'archive doit être décompressée à la racine du disque.
C:\Program FilesVous ne devez pas le décompresser dans un dossier , Logstash refusera de démarrer normalement. Ensuite, vous devez apporter des jvm.optionsmodifications au fichier qui sont responsables de l'allocation de RAM pour le processus Java. Je recommande de spécifier la moitié de la RAM du serveur. S'il dispose de 16 Go de RAM à bord, les clés par défaut sont:
-Xms1g
-Xmx1g
doit être remplacé par:
-Xms8g
-Xmx8g
De plus, il est conseillé de commenter la ligne
-XX:+UseConcMarkSweepGC. En savoir plus ici . L'étape suivante consiste à créer une configuration par défaut dans le fichier logstash.conf:
input {
stdin{}
}
filter {
}
output {
stdout {
codec => "rubydebug"
}
}
Avec cette configuration, Logstash lit les données de la console, les transmet à un filtre vide et les imprime à nouveau sur la console. L'application de cette configuration testera la fonctionnalité de Logstash. Pour ce faire, lançons-le de manière interactive:
PS C:\...\bin> .\logstash.bat -f .\logstash.conf
...
[2019-12-19T11:15:27,769][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2019-12-19T11:15:27,847][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2019-12-19T11:15:28,113][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
Logstash a été lancé avec succès sur le port 9600.
La dernière étape de l'installation consiste à lancer Logstash en tant que service Windows. Cela peut être fait, par exemple, en utilisant le package NSSM :
PS C:\...\bin> .\nssm.exe install logstash
Service "logstash" installed successfully!
tolérance aux pannes
Le mécanisme de files d'attente persistantes garantit la sécurité des journaux lors de la transmission depuis le serveur source.
Comment ça marche
La disposition des files d'attente lors du traitement du journal: entrée → file d'attente → filtre + sortie.
Le plugin d'entrée reçoit les données de la source de journal, les écrit dans la file d'attente et envoie une confirmation de réception des données à la source.
Les messages de la file d'attente sont traités par Logstash, passent le filtre et le plugin de sortie. Lors de la réception de la confirmation de la sortie de l'envoi d'un journal, Logstash supprime le journal traité de la file d'attente. Si Logstash s'arrête, tous les messages non traités et les messages qui n'ont pas reçu de confirmation d'envoi restent dans la file d'attente, et Logstash continuera à les traiter au prochain démarrage.
Mise en place
Régulé par des clés dans le fichier
C:\Logstash\config\logstash.yml:
queue.type: (les valeurs possibles sontpersistedetmemory (default)).path.queue: (chemin vers le dossier avec les fichiers de file d'attente, qui sont stockés dans C: \ Logstash \ queue par défaut).queue.page_capacity: (taille de page maximale de la file d'attente, la valeur par défaut est 64 Mo).queue.drain: (true / false - active / désactive l'arrêt du traitement de la file d'attente avant de désactiver Logstash. Je ne recommande pas de l'activer, car cela affectera directement la vitesse d'arrêt du serveur).queue.max_events: (nombre maximum d'événements dans la file d'attente, par défaut - 0 (illimité)).queue.max_bytes: (taille maximale de la file d'attente en octets, la valeur par défaut est 1024 Mo (1 Go)).
Si
queue.max_eventset sont configurés queue.max_bytes, les messages cesseront d'être reçus dans la file d'attente lorsque la valeur de l'un de ces paramètres est atteinte. En savoir plus sur les files d'attente persistantes ici .
Un exemple de la partie de logstash.yml responsable de la mise en place d'une file d'attente:
queue.type: persisted
queue.max_bytes: 10gb
Mise en place
La configuration de Logstash se compose généralement de trois parties, responsables des différentes phases de traitement des journaux entrants: réception (section d'entrée), analyse (section de filtre) et envoi à Elastic (section de sortie). Ci-dessous, nous examinerons de plus près chacun d'eux.
Contribution
Le flux entrant avec les journaux bruts est reçu des agents filebeat. C'est ce plugin que nous spécifions dans la section d'entrée:
input {
beats {
port => 5044
}
}
Après ce paramètre, Logstash commence à écouter sur le port 5044 et, lors de la réception des journaux, les traite en fonction des paramètres de la section filtre. Si nécessaire, vous pouvez envelopper le canal de réception des journaux de filebit en SSL. En savoir plus sur les paramètres du plugin Beats ici .
Filtre
Tous les journaux texte intéressants générés par Exchange pour le traitement sont au format csv avec des champs décrits dans le fichier journal lui-même. Pour analyser les enregistrements csv, Logstash nous propose trois plugins: dissection , csv et grok. Le premier est le plus rapide , mais il ne peut analyser que les journaux les plus simples.
Par exemple, il divisera l'enregistrement suivant en deux (en raison de la présence d'une virgule dans le champ), ce qui entraînera une analyse incorrecte du journal:
…,"MDB:GUID1, Mailbox:GUID2, Event:526545791, MessageClass:IPM.Note, CreationTime:2020-05-15T12:01:56.457Z, ClientType:MOMT, SubmissionAssistant:MailboxTransportSubmissionEmailAssistant",…
Il peut être utilisé lors de l'analyse des journaux, par exemple IIS. Dans ce cas, la section de filtre pourrait ressembler à ceci:
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
}
}
}
La configuration Logstash autorise les instructions conditionnelles , nous ne pouvons donc envoyer que les journaux au plugin dissection qui ont été étiquetés avec une balise filebeat
IIS. Dans le plugin, nous faisons correspondre les valeurs de champ avec leurs noms, supprimons le champ d'origine messagequi contenait l'entrée du journal, et nous pouvons ajouter un champ arbitraire qui contiendra, par exemple, le nom de l'application à partir de laquelle nous collectons les journaux.
Dans le cas du suivi des journaux, il est préférable d'utiliser le plugin csv, il peut traiter correctement des champs complexes:
filter {
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
}
À l'intérieur du plugin, nous faisons correspondre les valeurs de champ avec leurs noms, supprimons le champ d'origine
message(ainsi que les champs tenant-idet schema-version) qui contenaient l'entrée du journal, et nous pouvons ajouter un champ arbitraire qui contiendra, par exemple, le nom de l'application à partir de laquelle nous collectons les journaux.
A la sortie de l'étape de filtrage, nous obtiendrons des documents en première approximation, prêts à être rendus dans Kibana. Nous manquerons ce qui suit:
- Les champs numériques seront reconnus comme du texte, ce qui empêchera les opérations d'être effectuées sur eux. À savoir, les champs du
time-takenjournal IIS, ainsi que les champs de suivirecipient-countet letotal-bitesjournal. - L'horodatage standard du document contiendra l'heure de traitement du journal, pas l'heure d'enregistrement côté serveur.
- Le champ
recipient-addressressemblera à une construction unique, ce qui ne permet pas une analyse avec comptage des destinataires des lettres.
Il est maintenant temps d'ajouter un peu de magie au processus de traitement des journaux.
Conversion de champs numériques
Le plugin disséquer a une option
convert_datatypeque vous pouvez utiliser pour convertir un champ de texte au format numérique. Par exemple, comme ceci:
dissect {
…
convert_datatype => { "time-taken" => "int" }
…
}
Il convient de rappeler que cette méthode ne convient que si le champ contient définitivement une chaîne. L'option ne traite pas les valeurs nulles des champs et est renvoyée dans une exception.
Pour le suivi des journaux, il est préférable de ne pas utiliser une méthode de conversion similaire, car les champs
recipient-countet total-bitespeuvent être vides. Il est préférable d'utiliser le plugin mutate pour convertir ces champs :
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
}
Diviser l'adresse du destinataire en destinataires individuels
Cette tâche peut également être résolue à l'aide du plugin mutate:
mutate {
split => ["recipient_address", ";"]
}
Changer l'horodatage
Dans le cas des journaux de suivi, la tâche est très facilement résolue par le plugin de date , qui aidera à écrire la
timestampdate et l'heure dans le champ au format requis à partir du champ date-time:
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
Dans le cas des journaux IIS, nous devrons combiner les données de champ
dateet time, à l'aide du plugin mutate, enregistrer le fuseau horaire dont nous avons besoin et placer cet horodatage à l' timestampaide du plugin de date:
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
Production
La section de sortie est utilisée pour envoyer les journaux traités au récepteur de journaux. Dans le cas d'un envoi direct vers Elastic, le plugin elasticsearch est utilisé , qui spécifie l'adresse du serveur et le modèle du nom d'index pour envoyer le document généré:
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
Configuration finale
La configuration finale ressemblera à ceci:
input {
beats {
port => 5044
}
}
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
convert_datatype => { "time-taken" => "int" }
}
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
}
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
split => ["recipient_address", ";"]
}
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
Liens utiles:
- Comment installer OpenJDK 11 sur Windows?
- Télécharger Logstash
- Elastic utilise l'option dépréciée UseConcMarkSweepGC # 36828
- NSSM
- Files d'attente persistantes
- Plugin d'entrée Beats
- Logstash Dude, où est ma tronçonneuse? J'ai besoin de disséquer mes journaux
- Plugin de filtre Dissect
- Conditionnels
- Plug-in de filtre Mutate
- Plugin de filtre de date
- Plug-in de sortie Elasticsearch