
De plus en plus souvent, les demandes suivantes sont reçues des clients: «Nous le voulons comme Amazon RDS, mais moins cher»; "Nous le voulons comme RDS, mais partout, dans n'importe quelle infrastructure." Pour implémenter une telle solution gérée sur Kubernetes, nous avons examiné l'état actuel des opérateurs les plus populaires pour PostgreSQL (Stolon, opérateurs de Crunchy Data et Zalando) et avons fait notre choix.
Cet article est notre expérience à la fois d'un point de vue théorique (revue des solutions) et d'un point de vue pratique (ce qui a été choisi et ce qui en a résulté). Mais d'abord, déterminons quelles sont les exigences générales pour un remplacement potentiel de RDS ...
Qu'est-ce que RDS
Lorsque les gens parlent de RDS, d'après notre expérience, ils parlent d'un service de SGBD géré qui:
- facilement personnalisable;
- a la capacité de travailler avec des instantanés et d'en récupérer (de préférence avec le support PITR );
- vous permet de créer des topologies maître-esclave;
- a une riche liste d'extensions;
- fournit l'audit et la gestion des utilisateurs / accès.
De manière générale, les approches de mise en œuvre de la tâche peuvent être très différentes, mais le chemin avec Ansible conditionnel n'est pas proche de nous. (Une conclusion similaire a été tirée par les collègues de 2GIS suite à leur tentative de créer un «outil pour déployer rapidement un cluster de basculement basé sur Postgres».) Les
opérateurs sont l'approche généralement acceptée pour résoudre de tels problèmes dans l'écosystème Kubernetes. Plus de détails à leur sujet concernant les bases de données exécutées dans Kubernetes ont déjà été fournis par le département technique de Flant,distiller, dans l' un de ses rapports .
NB : Pour créer rapidement des opérateurs simples, nous vous recommandons de prêter attention à notre utilitaire d' opérateur shell open source . En l'utilisant, vous pouvez le faire sans connaissance de Go, mais de manière plus familière aux administrateurs système: en Bash, Python, etc.
Il existe plusieurs opérateurs K8 populaires pour PostgreSQL:
- Stolon;
- Opérateur PostgreSQL Crunchy Data;
- Opérateur Zalando Postgres.
Regardons-les de plus près.
Selection d'operateur
En plus des fonctionnalités importantes déjà mentionnées ci-dessus, nous - en tant qu'ingénieurs des opérations d'infrastructure de Kubernetes - attendions également ce qui suit des opérateurs:
- déployer à partir de Git et de ressources personnalisées ;
- support anti-affinité des gousses;
- installer l'affinité de nœud ou le sélecteur de nœud;
- fixer les tolérances;
- disponibilité des opportunités de réglage;
- des technologies compréhensibles et même des commandes.
Sans entrer dans les détails sur chacun des points (demandez dans les commentaires si vous avez des questions à leur sujet après avoir lu l'article entier), je note en général que ces paramètres sont nécessaires pour une description plus détaillée de la spécialisation des nœuds de cluster afin de les commander pour des applications spécifiques. De cette façon, nous pouvons atteindre l'équilibre optimal entre performance et coût.
Maintenant, pour les opérateurs PostgreSQL eux-mêmes.
1. Stolon
Stolon de la société italienne Sorint.lab dans le rapport déjà mentionné était considéré comme une sorte de référence parmi les opérateurs de SGBD. C'est un projet assez ancien: sa première sortie publique a eu lieu en novembre 2015 (!), Et le référentiel GitHub compte près de 3000 étoiles et plus de 40 contributeurs.
En effet, Stolon est un bel exemple d'architecture bien pensée:
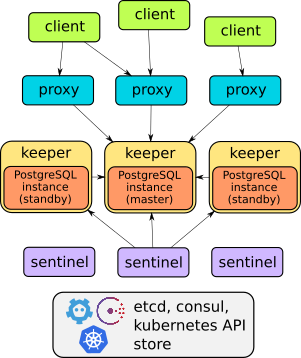
Les détails de l'appareil de cet opérateur se trouvent dans le rapport ou la documentation du projet . En général, il suffit de dire qu'il peut faire tout ce qui est décrit: basculement, proxies pour un accès client transparent, sauvegardes ... De plus, les proxies fournissent un accès via un service de point final - contrairement aux deux autres solutions considérées plus base).
Cependant, Stolon n'a pas de ressources personnalisées , c'est pourquoi il ne peut pas être déployé de manière à créer facilement et rapidement - "comme des petits pains" - des instances de SGBD dans Kubernetes. La gestion est effectuée via l'utilitaire
stolonctl, le déploiement - via le Helm-chart, et les paramètres utilisateur sont définis dans ConfigMap.
D'une part, il s'avère que l'opérateur n'est pas vraiment un opérateur (après tout, il n'utilise pas CRD). Mais d'un autre côté, c'est un système flexible qui vous permet de personnaliser les ressources dans K8 comme vous le souhaitez.
Pour résumer, pour nous personnellement, il ne nous a pas semblé optimal de créer un graphique distinct pour chaque base de données. Par conséquent, nous avons commencé à chercher des alternatives.
2. Opérateur PostgreSQL Crunchy Data
L'opérateur de Crunchy Data , une jeune startup américaine, ressemblait à une alternative logique. Son histoire publique commence avec la première version en mars 2017, depuis lors, le référentiel GitHub a reçu un peu moins de 1300 étoiles et plus de 50 contributeurs. La dernière version de septembre a été testée pour fonctionner avec Kubernetes 1.15-1.18, OpenShift 3.11+ et 4.4+, GKE et VMware Enterprise PKS 1.3+.
L'architecture de l'opérateur Crunchy Data PostgreSQL répond également aux exigences énoncées: la
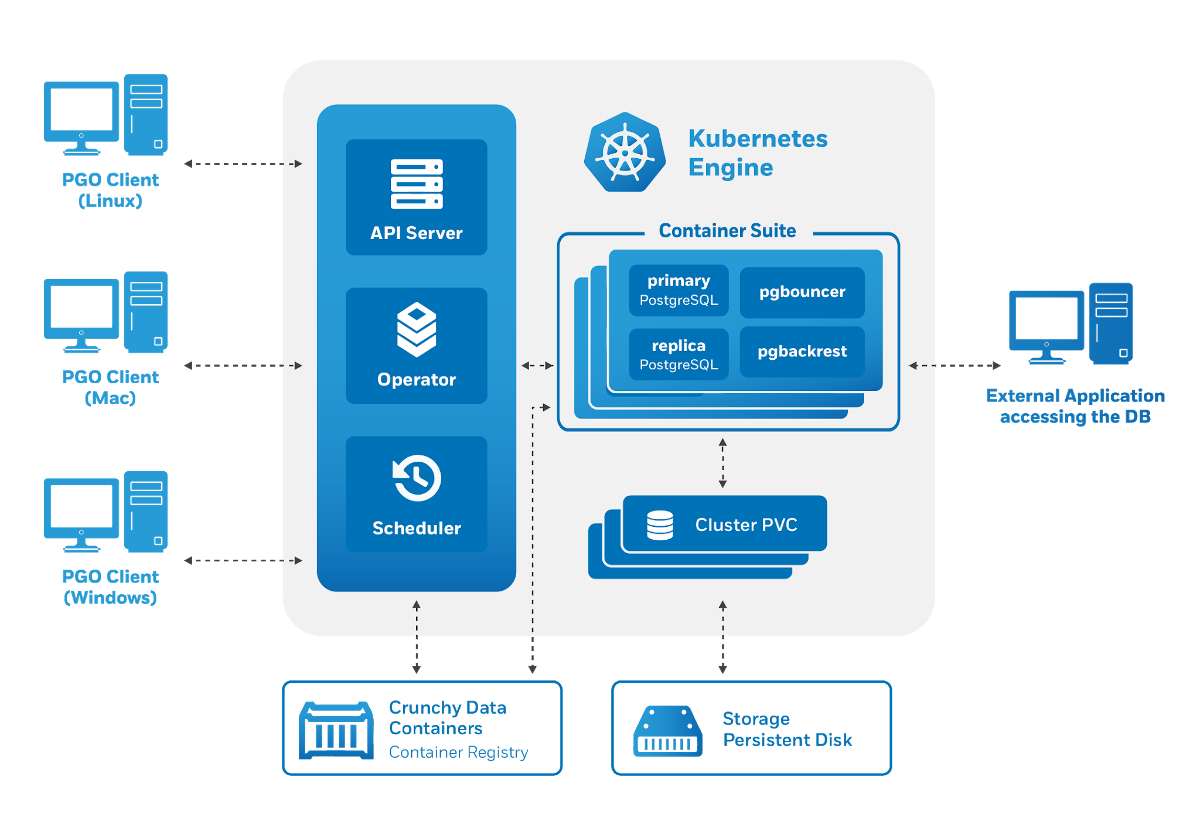
gestion est effectuée via un utilitaire
pgo, mais elle génère à son tour des ressources personnalisées pour Kubernetes. Par conséquent, l'opérateur nous a plu en tant qu'utilisateurs potentiels:
- il y a contrôle via CRD;
- gestion pratique des utilisateurs (également via CRD);
- intégration avec d'autres composants de Crunchy Data Container Suite - une collection spécialisée d'images de conteneurs pour PostgreSQL et des utilitaires pour travailler avec (y compris pgBackRest, pgAudit, extensions contrib, etc.).
Cependant, les tentatives de commencer à utiliser l'opérateur de Crunchy Data ont révélé plusieurs problèmes:
- Il n'y avait aucune possibilité de tolérance - seul nodeSelector est fourni.
- Les pods que nous avons créés faisaient partie du déploiement, même si nous avons déployé une application avec état. Contrairement aux StatefulSets, les déploiements ne peuvent pas créer de disques.
Le dernier inconvénient conduit à des moments amusants: dans l'environnement de test, il était possible d'exécuter 3 répliques avec un disque de stockage local , à la suite de quoi l'opérateur a signalé que 3 répliques fonctionnaient (bien que ce ne soit pas le cas).
Une autre caractéristique de cet opérateur est son intégration prête à l'emploi avec divers systèmes auxiliaires. Par exemple, il est facile d'installer pgAdmin et pgBounce, et la documentation couvre les pré-configurés Grafana et Prometheus. La récente version 4.5.0-beta1 note séparément l'amélioration de l'intégration avec le projet pgMonitor , grâce à laquelle l'opérateur offre une visualisation visuelle des métriques pour PgSQL prête à l'emploi.
Cependant, l'étrange choix des ressources Kubernetes générées nous a conduit à trouver une autre solution.
3. Opérateur Zalando Postgres
Nous connaissons les produits Zalando depuis longtemps: nous avons de l'expérience avec Zalenium et, bien sûr, nous avons essayé Patroni - leur solution HA populaire pour PostgreSQL. L'un de ses auteurs, Aleksey Klyukin, a parlé de l'approche de l'entreprise pour la création de Postgres Operator le mardi n ° 5 de Postgres , et nous l'avons aimé.
Il s'agit de la solution la plus récente évoquée dans l'article: la première version a eu lieu en août 2018. Cependant, même avec un petit nombre de versions formelles, le projet a parcouru un long chemin, dépassant déjà la popularité de la solution de Crunchy Data avec plus de 1300 étoiles sur GitHub et le nombre maximum de contributeurs (70+).
Sous le capot de cet opérateur, des solutions éprouvées par le temps sont utilisées:
- Patroni et Spilo pour le contrôle,
- WAL-E - pour les sauvegardes,
- PgBouncer - comme pool de connexion.
Voici comment l'architecture de l'opérateur de Zalando est présentée:
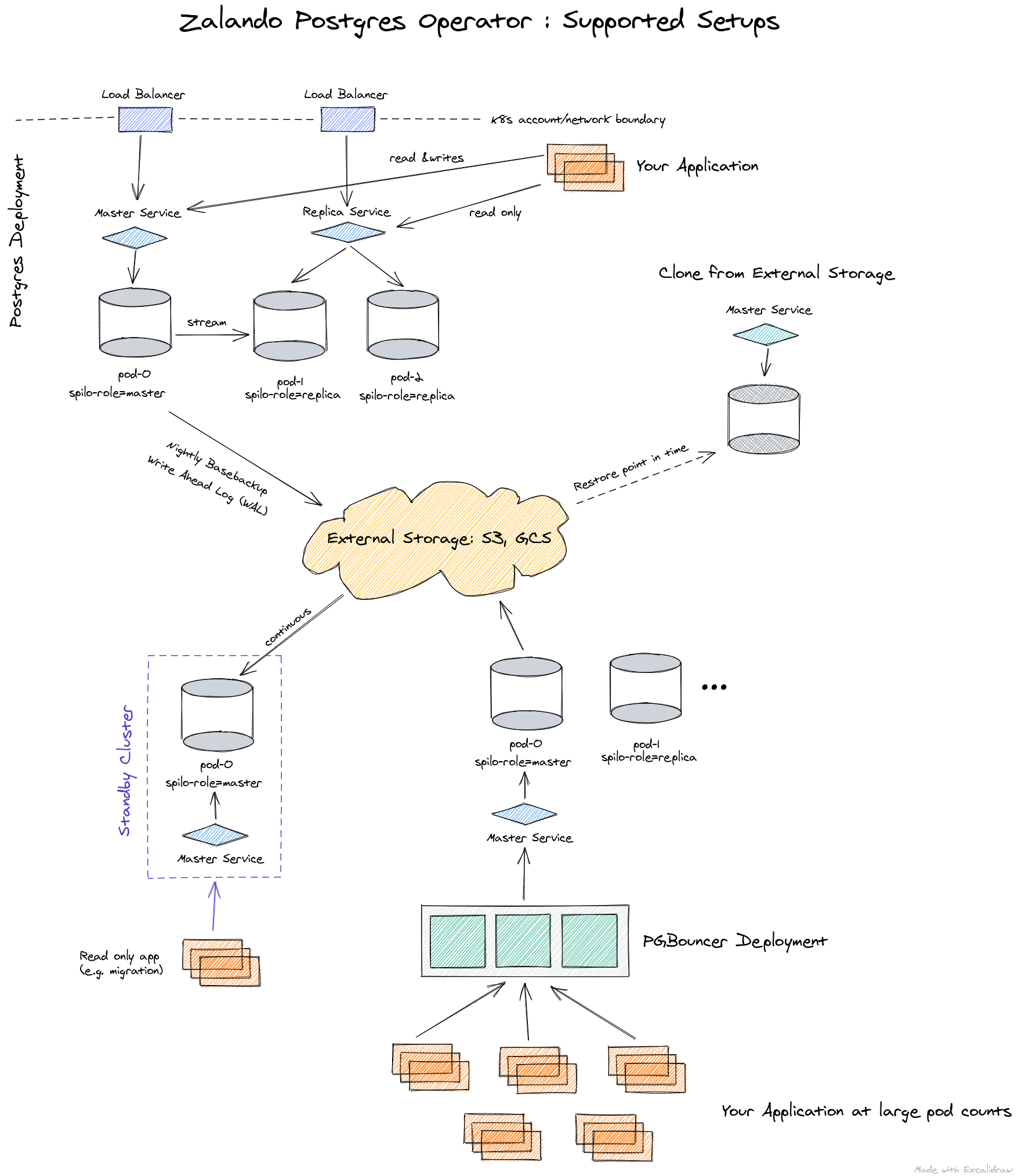
l'opérateur est entièrement géré via des ressources personnalisées, crée automatiquement un StatefulSet à partir de conteneurs, qui peut ensuite être personnalisé en ajoutant divers side-cars aux pods. Tout cela est un plus non négligeable par rapport à l'opérateur de Crunchy Data.
Comme c'est la solution de Zalando que nous avons choisie parmi les 3 options envisagées, une description plus détaillée de ses capacités sera présentée ci-dessous, immédiatement avec la pratique de l'application.
Pratiquez avec l'opérateur Postgres de Zalando
Le déploiement d'un opérateur est très simple: il suffit de télécharger la version actuelle depuis GitHub et d'appliquer les fichiers YAML à partir du répertoire manifestes . Vous pouvez également utiliser OperatorHub .
Après l'installation, vous devez vous soucier de la configuration des stockages pour les journaux et les sauvegardes . Cela se fait via ConfigMap
postgres-operatordans l'espace de noms où vous avez installé l'instruction. Une fois les référentiels configurés, vous pouvez déployer votre premier cluster PostgreSQL.
Par exemple, notre déploiement standard ressemble à ceci:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
Ce manifeste déploie un cluster de 3 instances avec un side-car sous la forme de postgres_exporter , à partir duquel nous prélevons des métriques d'application. Comme vous pouvez le voir, tout est très simple, et si vous le souhaitez, vous pouvez créer littéralement un nombre illimité de clusters.
Il convient de prêter attention au panneau d'administration Web - postgres-operator-ui . Il est livré avec l'opérateur et vous permet de créer et de supprimer des clusters, ainsi que de travailler avec des sauvegardes effectuées par l'opérateur. Gestion des sauvegardes de
listes de cluster PostgreSQL Une autre fonctionnalité intéressante est la prise en charge de l' API Teams . Ce mécanisme crée automatiquement des rôles dans PostgreSQL
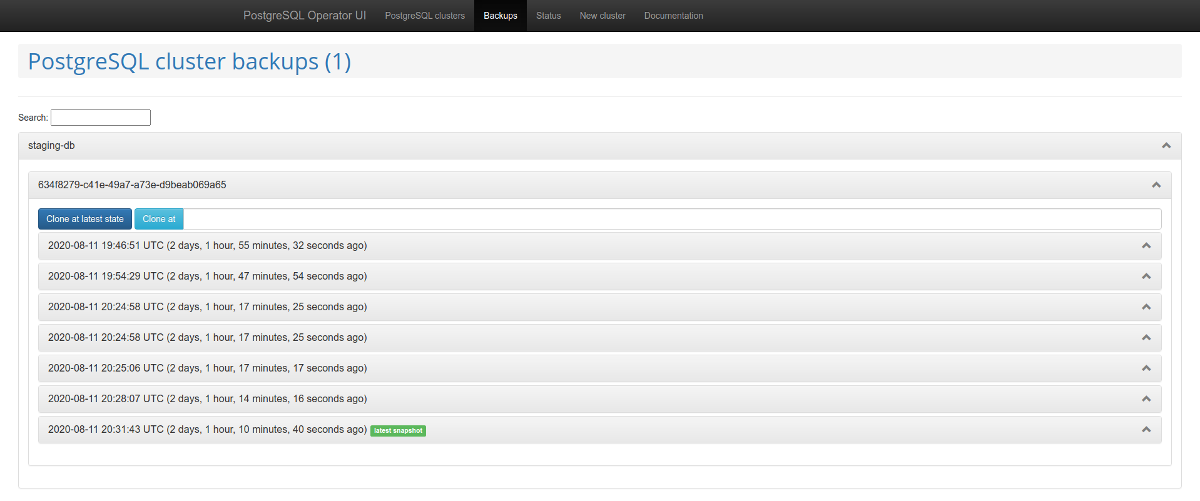
basé sur la liste résultante de noms d'utilisateur. Après cela, l'API vous permet de renvoyer une liste d'utilisateurs pour lesquels des rôles sont automatiquement créés.
Problèmes et solutions
Cependant, l'utilisation de l'opérateur a rapidement révélé plusieurs inconvénients importants:
- manque de support pour nodeSelector;
- incapacité à désactiver les sauvegardes;
- lors de l'utilisation de la fonction de création de base de données, les privilèges par défaut n'apparaissent pas;
- périodiquement, il n'y a pas assez de documentation ou elle est périmée.
Heureusement, nombre d’entre eux peuvent être résolus. Commençons par la fin - problèmes de documentation .
Très probablement, vous constaterez qu'il n'est pas toujours clair comment enregistrer une sauvegarde et comment connecter un compartiment de sauvegarde à l'interface utilisateur de l'opérateur. La documentation en parle au passage, mais la vraie description se trouve dans le PR :
- vous devez faire un secret;
-
pod_environment_secret_nameCRD ConfigMap ( , ).
Cependant, il s'est avéré que cela est actuellement impossible. C'est pourquoi nous avons créé notre propre version de l'opérateur avec quelques développements tiers supplémentaires. Voir ci-dessous pour plus de détails.
Si vous transmettez les paramètres de sauvegarde à l'opérateur, à savoir les
wal_s3_bucketclés d'accès dans AWS S3, il sauvegardera tout : non seulement les bases en production, mais également la mise en scène. Cela ne nous convenait pas.
Dans la description des paramètres à Spilo, qui est le wrapper Docker de base pour PgSQL lors de l'utilisation de l'opérateur, il s'est avéré que vous pouvez passer le paramètre
WAL_S3_BUCKETvide, désactivant ainsi les sauvegardes. De plus, à notre grande joie, un PR prêt à l'emploi a été trouvé , que nous avons immédiatement accepté dans notre fourchette. Il suffit maintenant d'ajouter simplement le enableWALArchiving: falsecluster PostgreSQL à la ressource.
Oui, il y avait une opportunité de le faire différemment en exécutant 2 opérateurs: un pour le staging (sans sauvegardes), et le second pour la production. Mais ainsi nous avons pu nous en tirer avec un.
Ok, nous avons appris comment transférer l'accès de S3 aux bases de données et les sauvegardes ont commencé à entrer dans le stockage. Comment faire fonctionner les pages de sauvegarde dans l'interface utilisateur de l'opérateur?

Dans l'interface utilisateur de l'opérateur, vous devez ajouter 3 variables:
-
SPILO_S3_BACKUP_BUCKET -
AWS_ACCESS_KEY_ID -
AWS_SECRET_ACCESS_KEY
Après cela, la gestion des sauvegardes deviendra disponible, ce qui dans notre cas simplifiera le travail avec la staging, vous permettant de livrer des tranches de la production là-bas sans scripts supplémentaires.
Un autre avantage a été appelé le travail avec l'API Teams et les larges possibilités de création de bases de données et de rôles à l'aide d'outils d'opérateur. Cependant, les rôles créés n'avaient pas de droits par défaut . Par conséquent, un utilisateur disposant des droits de lecture ne pouvait pas lire les nouvelles tables.
Pourquoi donc? Malgré le fait que le code contient les codes nécessaires
GRANT, ils ne sont pas toujours utilisés. Il existe 2 méthodes: syncPreparedDatabaseset syncDatabases. B syncPreparedDatabases- malgré le fait qu'il preparedDatabases y ait une condition dans la section defaultRolesetdefaultUserspour créer des rôles, les droits par défaut ne sont pas appliqués. Nous sommes en train de préparer un correctif afin que ces droits soient automatiquement appliqués.
Et le dernier moment des améliorations qui nous intéressent est un correctif qui ajoute Node Affinity au StatefulSet créé. Nos clients préfèrent souvent réduire les coûts en utilisant des instances ponctuelles, et ils ne devraient clairement pas héberger de services de base de données. Ce problème pourrait être résolu par des tolérances, mais la présence de Node Affinity donne beaucoup de confiance.
Qu'est-il arrivé?
Suite à la résolution des problèmes ci-dessus, nous avons transféré Postgres Operator de Zalando dans notre référentiel , où il est construit avec ces correctifs utiles. Et pour des raisons de commodité, nous avons également assemblé une image Docker .
Liste PR fourchue:
- créer une image légère et sécurisée pour l'opérateur dans Docker ;
- désactiver les sauvegardes ;
- mise à jour des versions de ressources pour les versions actuelles de k8s ;
- implémentation de Node Affinity .
Ce sera formidable si la communauté supporte ces PR pour qu'ils se retrouvent en amont avec la prochaine version de l'opérateur (1.6).
Prime! Histoire de réussite de la migration de production
Si vous utilisez Patroni, la production en direct peut être migrée vers l'opérateur avec un temps d'arrêt minimal.
Spilo vous permet de créer des clusters de secours via des stockages S3 avec Wal-E , lorsque le journal binaire PgSQL est d'abord enregistré sur S3, puis téléchargé par la réplique. Mais que faire si vous n'avez pas Wal-E dans votre ancienne infrastructure? La solution à ce problème a déjà été proposée sur Habré.
La réplication logique PostgreSQL vient à la rescousse. Cependant, nous n'entrerons pas dans les détails sur la façon de créer des publications et des abonnements, car ... notre plan a échoué.
Le fait est que la base de données contenait plusieurs tables chargées avec des millions de lignes, qui, de plus, étaient constamment réapprovisionnées et supprimées. Abonnement simple avec
copy_data, lorsqu'une nouvelle réplique copie tout le contenu du maître, elle ne suit tout simplement pas le maître. La copie du contenu a fonctionné pendant une semaine, mais n'a jamais rattrapé le maître. En conséquence, un article de collègues d'Avito a aidé à résoudre le problème : vous pouvez transférer des données en utilisant pg_dump. Je décrirai notre version (légèrement modifiée) de cet algorithme.
L'idée est que vous pouvez créer un abonnement hors ligne lié à un emplacement de réplication spécifique, puis fixer le numéro de transaction. Il y avait des répliques pour le travail de production. Ceci est important car le réplica aidera à créer un vidage cohérent et continuera à recevoir les modifications du maître.
Dans les commandes suivantes décrivant le processus de migration, les notations d'hôte suivantes seront utilisées:
- maître - serveur source;
- replica1 - réplique en streaming sur l'ancienne production;
- replica2 est une nouvelle réplique logique.
Plan de migration
1. Dans l'assistant, créez un abonnement à toutes les tables du schéma de
publicbase de données dbname:
psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
2. Créons un emplacement de réplication sur le maître:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
3. Arrêtez la réplication sur l'ancien réplica:
psql -h replica1 -c "select pg_wal_replay_pause();"
4. Obtenez le numéro de transaction du maître:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
5. Videz l'ancienne réplique. Nous allons le faire dans plusieurs threads, ce qui aidera à accélérer le processus:
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
6. Téléchargez le vidage sur le nouveau serveur:
pg_restore -h replica2 -F d -j 8 -d dbname dump/
7. Après avoir téléchargé le vidage, vous pouvez démarrer la réplication sur le réplica en continu:
psql -h replica1 -c "select pg_wal_replay_resume();"
7. Créons un abonnement sur une nouvelle réplique logique:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
8. Obtenez des
oidabonnements:
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
9. Disons qu'il a été reçu
oid=1000. Appliquons le numéro de transaction à l'abonnement:
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
10. Commençons la réplication:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
11. Vérifiez l'état de l'abonnement, la réplication devrait fonctionner:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
12. Une fois la réplication démarrée et les bases de données synchronisées, vous pouvez basculer.
13. Après avoir désactivé la réplication, vous devez corriger les séquences. Ceci est bien documenté dans un article sur wiki.postgresql.org .
Grâce à ce plan, le basculement s'est effectué avec des retards minimes.
Conclusion
Les opérateurs Kubernetes vous permettent de simplifier diverses activités en les réduisant à la création de ressources K8. Cependant, après avoir réalisé une automatisation remarquable avec leur aide, il convient de rappeler que cela peut également apporter un certain nombre de nuances inattendues, alors choisissez judicieusement vos opérateurs.
Après avoir passé en revue les trois opérateurs Kubernetes les plus populaires pour PostgreSQL, nous avons opté pour un projet de Zalando. Et nous avons dû surmonter certaines difficultés avec lui, mais le résultat était vraiment heureux, nous prévoyons donc d'étendre cette expérience à d'autres installations PgSQL. Si vous avez de l'expérience dans l'utilisation de solutions similaires, nous serons heureux de voir les détails dans les commentaires!
PS
Lisez aussi sur notre blog: