
Les SGBD à cet égard fonctionnent selon les mêmes principes - " ils ont dit de creuser et je creuse ". Votre demande peut non seulement ralentir les processus voisins, occupant constamment les ressources du processeur, mais aussi «supprimer» entièrement la base de données entière, «consommant» toute la mémoire disponible. Par conséquent, la protection contre la récursivité infinie est de la responsabilité du développeur lui-même.
Dans PostgreSQL, la possibilité d'utiliser des requêtes récursives via est
WITH RECURSIVEapparue depuis des temps immémoriaux dans la version 8.4, mais vous pouvez toujours rencontrer régulièrement des requêtes potentiellement vulnérables "sans défense". Comment se sauver de ce genre de problèmes?
N'écrivez pas de requêtes récursives
Et écrivez non récursif. Respectueusement vôtre K.O.En fait, PostgreSQL fournit une assez grande quantité de fonctionnalités que vous pouvez utiliser pour éviter la récursivité.
Utilisez une approche fondamentalement différente de la tâche
Parfois, vous pouvez simplement regarder le problème "de l'autre côté". J'ai donné un exemple d'une telle situation dans l'article "SQL HowTo: 1000 and one way of aggregation" - multiplication d'un ensemble de nombres sans utiliser de fonctions d'agrégation personnalisées:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY --
i DESC
LIMIT 1;Une telle demande peut être remplacée par une variante d'experts en mathématiques:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;Utilisez generate_series au lieu de boucles
Disons que nous sommes confrontés à la tâche de générer tous les préfixes possibles pour une chaîne
'abcdefgh':
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T;Exactement, avez-vous besoin de la récursivité ici? .. Si vous utilisez
LATERALet generate_series, alors même les CTE ne sont pas nécessaires:
SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;Changer la structure de la base de données
Par exemple, vous avez un tableau des messages du forum avec des liens vers qui a répondu, ou un fil sur un réseau social :
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to);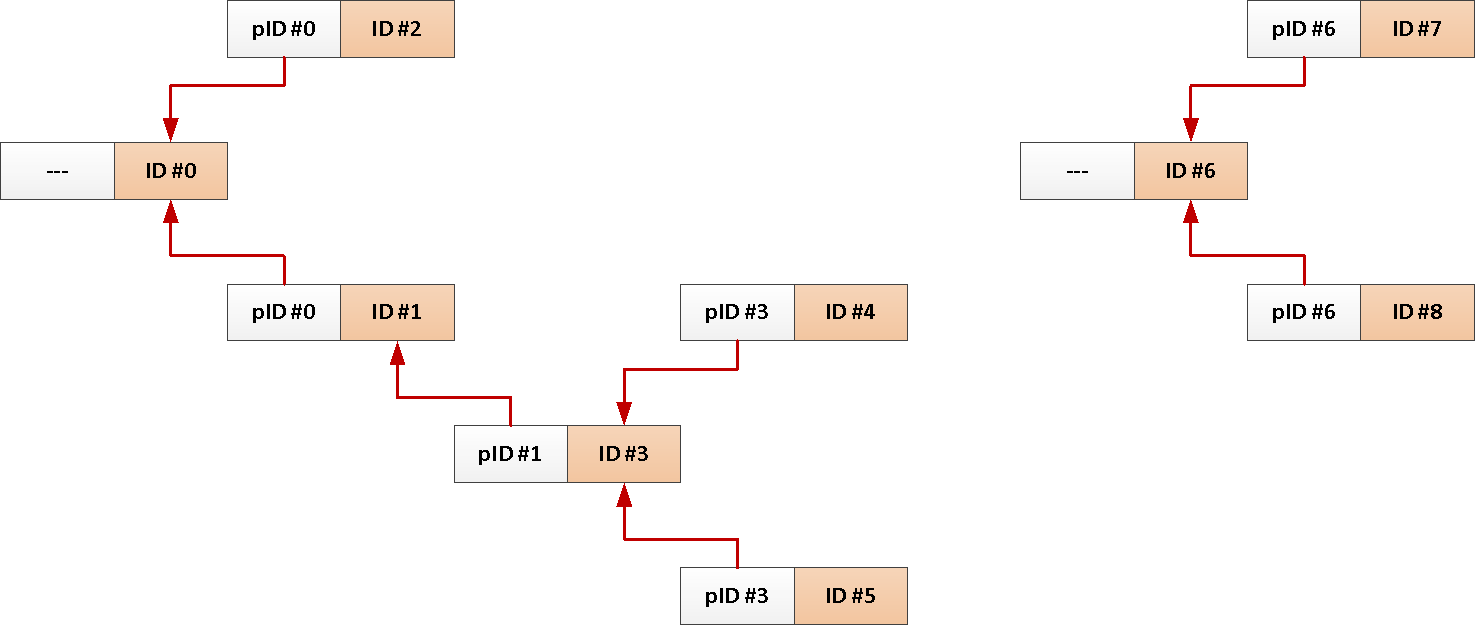
Eh bien, une demande typique de téléchargement de tous les messages sur un sujet ressemble à ceci:
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;Mais puisque nous avons toujours besoin de tout le sujet du message racine, pourquoi ne pas ajouter automatiquement son identifiant à chaque message ?
--
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
--
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id --
ELSE ( -- ,
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins();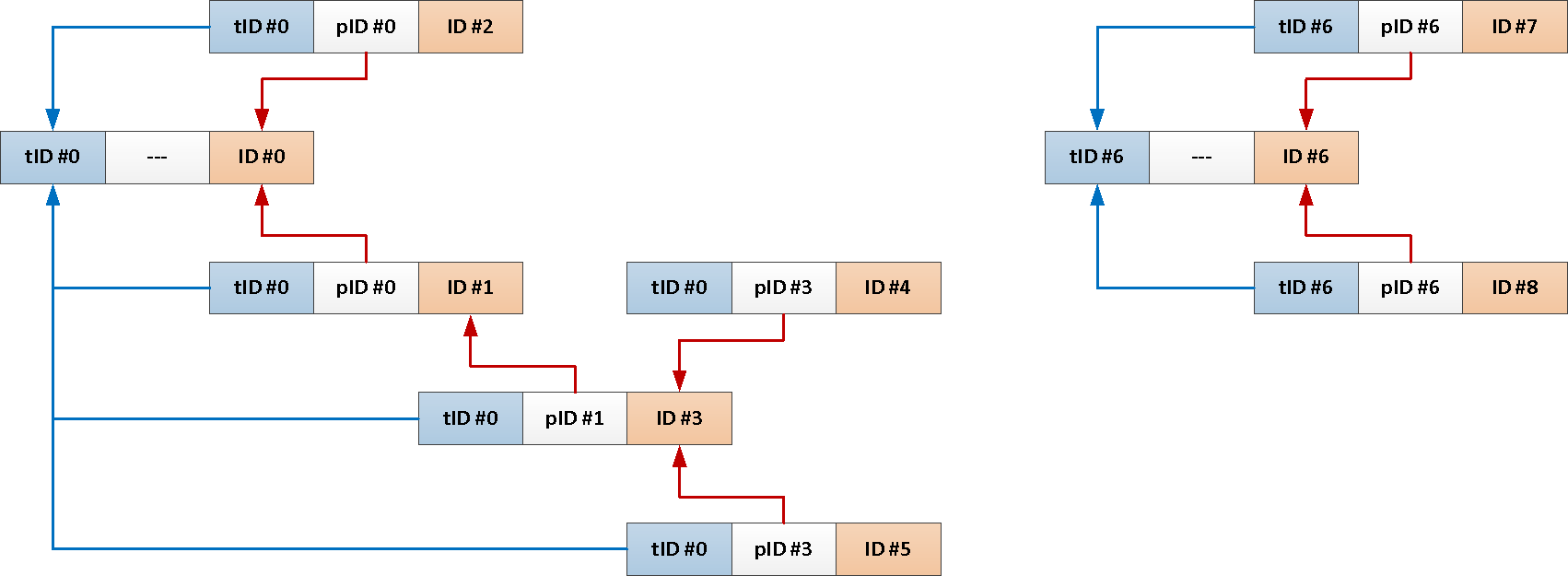
Maintenant, toute notre requête récursive peut être réduite à ceci:
SELECT
*
FROM
message
WHERE
theme_id = $1;Utiliser des "contraintes" appliquées
Si nous ne sommes pas en mesure de modifier la structure de la base de données pour une raison quelconque, voyons sur quoi nous pouvons nous appuyer pour que même la présence d'une erreur dans les données ne conduise pas à une récursivité infinie.
Compteur de "profondeur" de récursivité
Nous augmentons simplement le compteur de un à chaque étape de la récursivité jusqu'à ce que la limite soit atteinte, ce que nous considérons comme manifestement inadéquat:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 --
)Pro: Quand nous essayons de boucler, nous ne ferons toujours pas plus que la limite spécifiée d'itérations "profondes".
Contra: Il n'y a aucune garantie que nous ne traiterons pas à nouveau le même enregistrement - par exemple, à des profondeurs de 15 et 25, puis il y aura tous les +10. Et personne n'a rien promis de "largeur".
Formellement, une telle récursivité ne sera pas infinie, mais si à chaque pas le nombre d'enregistrements augmente de façon exponentielle, on sait tous bien comment ça se termine ...

Gardien du «chemin»
Un par un, nous ajoutons tous les identificateurs d'objet que nous avons rencontrés le long du chemin de récursivité dans un tableau, qui est un "chemin" unique vers celui-ci:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) --
)Pro: S'il y a une boucle dans les données, nous ne traiterons absolument pas le même enregistrement encore et encore dans le même chemin.
Contra: Mais en même temps, nous pouvons contourner, littéralement, tous les enregistrements sans répéter.
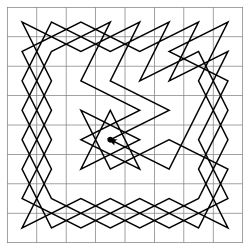
Limitation de la longueur du chemin
Pour éviter la situation de récursion "errant" à une profondeur incompréhensible, nous pouvons combiner les deux méthodes précédentes. Ou, si nous ne voulons pas prendre en charge les champs inutiles, complétez la condition de continuation de récursivité avec une estimation de la longueur du chemin:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) AND
array_length(T.path, 1) < 10
)Choisissez la méthode à votre goût!